17-8 C 风格数组衰变
C语言风格数组传递难题
C语言的设计者曾面临一个难题。请看以下简单程序:
#include <iostream>
void print(int val)
{
std::cout << val;
}
int main()
{
int x { 5 };
print(x);
return 0;
}
当调用 print(x) 时,参数 x 的值(5)会被复制到参数 val 中。在函数体内,val 的值(5)会被打印到控制台。由于 x 的复制成本很低,这里不会出现问题。
现在考虑以下类似的程序,它使用一个包含 1000 个元素的 C 风格 int 数组,而不是单个 int:
#include <iostream>
void printElementZero(int arr[1000])
{
std::cout << arr[0]; // print the value of the first element
}
int main()
{
int x[1000] { 5 }; // define an array with 1000 elements, x[0] is initialized to 5
printElementZero(x);
return 0;
}

该程序同样会编译并向控制台输出预期值(5)。
虽然本例代码与前例相似,但其运行机制可能与预期略有不同(下文将解释原因)。这源于C语言设计者为应对两大挑战而提出的解决方案。
首先,每次函数调用时复制1000个元素的数组代价高昂(若元素类型复制成本更高则更为显著),因此我们需要规避这种情况。但如何实现?C语言不支持引用机制,因此无法通过引用传递避免函数参数的复制。
其次,我们需要编写单一函数来处理不同长度的数组参数。理想情况下,上文示例中的printElementZero()函数应能接受任意长度的数组参数(因元素0存在性有保障)。我们不希望为每种可能的数组长度都编写独立函数。但如何实现?C语言既没有指定“任意长度”数组的语法,也不支持模板,更无法将特定长度的数组转换为其他长度(这可能涉及代价高昂的复制操作)。
C语言设计者提出了一个巧妙的解决方案(C++为兼容性原因继承了该方案),同时解决了这两个问题:
#include <iostream>
void printElementZero(int arr[1000]) // doesn't make a copy
{
std::cout << arr[0]; // print the value of the first element
}
int main()
{
int x[7] { 5 }; // define an array with 7 elements
printElementZero(x); // somehow works!
return 0;
}

不知何故,上述示例将一个7元素数组传递给一个期望接收1000元素数组的函数,且未进行任何复制操作。本节课我们将探究其工作原理。
同时我们将分析C语言设计者选择的解决方案为何存在风险,且不适用于现代C++环境。
但首先,我们需要探讨两个子主题。
数组到指针的转换(数组衰变)
在大多数情况下,当C风格数组用于表达式时,该数组会被隐式转换为指向元素类型的指针,并初始化为第一个元素(索引为0)的地址。这种现象俗称数组衰变array decay(或简称为衰变decay)。
以下程序可说明此现象:
#include <iomanip> // for std::boolalpha
#include <iostream>
int main()
{
int arr[5]{ 9, 7, 5, 3, 1 }; // our array has elements of type int
// First, let's prove that arr decays into an int* pointer
auto ptr{ arr }; // evaluation causes arr to decay, type deduction should deduce type int*
std::cout << std::boolalpha << (typeid(ptr) == typeid(int*)) << '\n'; // Prints true if the type of ptr is int*
// Now let's prove that the pointer holds the address of the first element of the array
std::cout << std::boolalpha << (&arr[0] == ptr) << '\n';
return 0;
}
在作者的机器上,这段代码输出如下:

数组衰变成的指针并无特殊之处,它只是一个普通指针,存储着数组首元素的地址。
同样地,常量数组(如 const int arr[5])会衰变为常量指针(const int*)。
提示:
在 C++ 中,存在几种常见情况会导致 C 风格数组不发生衰变:
- 作为sizeof()或typeid()的参数时
- 使用&运算符取数组地址时
- 作为类型的成员传递时
- 通过引用传递时
由于C风格数组在大多数情况下会衰变为指针,人们常误以为数组就是指针。事实并非如此:数组对象是一系列元素的序列,而指针对象仅持有地址。
数组与衰变数组的类型信息存在差异。在上例中,数组 arr 的类型为 int[5],而衰变数组的类型为 int。值得注意的是,数组类型 int[5] 包含长度信息,而衰变数组指针类型 int 则不包含。
关键要点:
衰变数组指针无法知晓其所指向数组的长度。“衰变”一词正表明了长度类型信息的丢失。
对C风格数组进行下标操作时,实际上是对衰减后的指针应用了[]运算符
由于C风格数组在求值时会衰减为指针,因此当对C风格数组进行下标操作时,下标操作实际上是在衰减后的数组指针上进行:
#include <iostream>
int main()
{
const int arr[] { 9, 7, 5, 3, 1 };
std::cout << arr[2]; // subscript decayed array to get element 2, prints 5
return 0;
}

我们也可以直接对指针使用operator[]运算符。如果该指针存储着第一个元素的地址,结果将完全相同:
#include <iostream>
int main()
{
const int arr[] { 9, 7, 5, 3, 1 };
const int* ptr{ arr }; // arr decays into a pointer
std::cout << ptr[2]; // subscript ptr to get element 2, prints 5
return 0;
}

我们稍后将探讨这种写法在何种情况下更为便捷,并在下一节课17.9——指针运算与下标操作中深入剖析其工作原理(同时说明当指针指向非首元素地址时会发生什么)。
数组衰变解决了我们传递C风格数组的问题
数组衰变同时解决了本节开头遇到的两个难题。
当将C风格数组作为参数传递时,数组会衰变为指针,而传递给函数的正是持有数组首元素地址的指针。因此虽然看似按值传递了C风格数组,实际却是按地址传递!这正是避免复制C风格数组参数的关键机制。
核心要点:
C风格数组始终按地址传递,即使表面看似按值传递。
现在考虑两个元素类型相同但长度不同的数组(例如 int[5] 和 int[7])。它们是互不相容的不同类型。然而它们都会衰变为相同的指针类型(例如 int*)。其衰变后的版本可以互换使用!通过舍弃长度信息,我们得以在不引发类型不匹配的情况下传递不同长度的数组。
关键洞见:
两个元素类型相同但长度不同的C风格数组,会衰变为相同的指针类型。
以下示例将说明两点:
- 我们可以将不同长度的数组传递给同一个函数(因为两者都衰变为相同的指针类型)。
- 接收数组的函数参数可以是数组元素类型的(const)指针。
#include <iostream>
void printElementZero(const int* arr) // pass by const address
{
std::cout << arr[0];
}
int main()
{
const int prime[] { 2, 3, 5, 7, 11 };
const int squares[] { 1, 4, 9, 25, 36, 49, 64, 81 };
printElementZero(prime); // prime decays to an const int* pointer
printElementZero(squares); // squares decays to an const int* pointer
return 0;
}
这个示例运行正常,并输出:

在 main() 函数中,当我们调用 printElementZero(prime) 时,prime 数组会从 const int[5] 类型的数组衰变为 const int* 类型的指针,该指针持有 prime 数组第一个元素的地址。同样地,当调用 printElementZero(squares) 时,squares 数组会从 const int[8] 类型的数组衰变为 const int* 类型的指针,该指针持有 squares 数组第一个元素的地址。这些 const int* 类型的指针才是实际传递给函数的参数。
由于传递的是 const int* 类型的指针,printElementZero() 函数必须采用相同指针类型(const int*)的参数。
函数内部通过下标操作访问指针指向的数组元素。
由于C风格数组采用地址传递,函数可直接操作传入数组(而非副本),并能修改其元素。因此若函数无意修改数组元素,建议将参数声明为const类型。
C风格数组函数参数语法
将函数参数声明为 int* arr 的问题在于,无法明确表明 arr 应指向值数组而非单个整数。因此在传递 C 风格数组时,更推荐使用替代声明形式 int arr[]。
#include <iostream>
void printElementZero(const int arr[]) // treated the same as const int*
{
std::cout << arr[0];
}
int main()
{
const int prime[] { 2, 3, 5, 7, 11 };
const int squares[] { 1, 4, 9, 25, 36, 49, 64, 81 };
printElementZero(prime); // prime decays to a pointer
printElementZero(squares); // squares decays to a pointer
return 0;
}

该程序的行为与前一个完全相同,因为编译器会将函数参数 const int arr[] 解释为 const int*。但这种写法的好处在于向调用方明确传达:arr 预期是衰变后的 C 风格数组,而非指向单个值的指针。请注意方括号内无需指定长度信息(因实际不会使用)。若提供长度参数,将被忽略。
最佳实践:
函数参数若需接收C风格数组类型,应采用数组语法(如int arr[]),而非指针语法(如int *arr)。
此语法的不利之处在于难以直观体现 arr 的衰变特性(而指针语法则清晰可见),因此需格外注意避免执行可能导致衰变数组行为异常的操作(部分情况将在后续说明)。
数组衰变的问题
尽管数组衰变是确保不同长度的C风格数组能传递给函数而不产生昂贵副本的巧妙解决方案,但数组长度信息的丢失容易导致多种错误。
首先,sizeof()函数对数组和衰变数组返回的值不同:
#include <iostream>
void printArraySize(int arr[])
{
std::cout << sizeof(arr) << '\n'; // prints 4 (assuming 32-bit addresses)
}
int main()
{
int arr[]{ 3, 2, 1 };
std::cout << sizeof(arr) << '\n'; // prints 12 (assuming 4 byte ints)
printArraySize(arr);
return 0;
}


这意味着对C风格数组使用sizeof()可能存在风险,因为必须确保仅在能够访问实际数组对象时使用该操作符,而非已衰变的数组或指针。
在前一课(17.7节——C风格数组简介)中,我们提到sizeof(arr)/sizeof(*arr)曾作为获取C风格数组大小的临时解决方案。这种技巧存在风险:若 arr 已衰变,sizeof(arr) 将返回指针大小而非数组大小,导致数组长度计算错误,极可能引发程序故障。
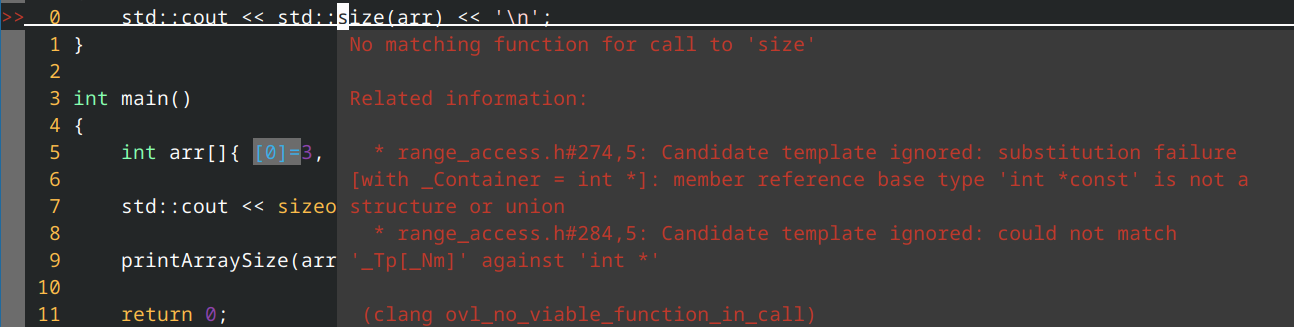
值得庆幸的是,C++17 引入的替代方案 std::size()(以及 C++20 的 std::ssize())在接收指针值时会报错:
#include <iostream>
int printArrayLength(int arr[])
{
std::cout << std::size(arr) << '\n'; // compile error: std::size() won't work on a pointer
}
int main()
{
int arr[]{ 3, 2, 1 };
std::cout << std::size(arr) << '\n'; // prints 3
printArrayLength(arr);
return 0;
}

其次,或许最为关键的是,数组衰变会使重构(将冗长函数拆解为更短、更模块化的函数)变得困难。在非衰变数组环境下正常运行的代码,一旦使用衰变数组,可能无法编译(更糟的是,可能悄无声息地出现故障)。
第三,缺少长度信息会引发若干编程难题。缺乏长度信息使得数组长度的合理性检查变得困难。用户可能轻易传入长度不足的数组(甚至指向单个值的指针),当使用无效索引进行下标访问时,将导致未定义行为。
#include <iostream>
void printElement2(int arr[])
{
// How do we ensure that arr has at least three elements?
std::cout << arr[2] << '\n';
}
int main()
{
int a[]{ 3, 2, 1 };
printElement2(a); // ok
int b[]{ 7, 6 };
printElement2(b); // compiles but produces undefined behavior
int c{ 9 };
printElement2(&c); // compiles but produces undefined behavior
return 0;
}

没有数组长度也会在遍历数组时带来挑战——我们如何知道何时到达数组末尾?
虽然存在解决这些问题的方案,但这些方案会同时增加程序的复杂性和脆弱性。
解决数组长度问题
历史上,程序员通过两种方法来解决数组长度信息缺失的问题。
首先,我们可以将数组和数组长度作为独立参数传递:
#include <cassert>
#include <iostream>
void printElement2(const int arr[], int length)
{
assert(length > 2 && "printElement2: Array too short"); // can't static_assert on length
std::cout << arr[2] << '\n';
}
int main()
{
constexpr int a[]{ 3, 2, 1 };
printElement2(a, static_cast<int>(std::size(a))); // ok
constexpr int b[]{ 7, 6 };
printElement2(b, static_cast<int>(std::size(b))); // will trigger assert
return 0;
}

然而,这仍然存在若干问题:
- 调用方需要确保数组与数组长度配对正确——若传递了错误的长度值,函数仍会失效。
- 若使用std::size()或返回std::size_t类型的函数,可能存在符号转换问题。
- 运行时断言仅在运行时触发。若测试路径未能覆盖所有函数调用场景,则存在向客户交付程序的风险——当用户执行未明确测试的操作时,程序可能触发断言。在现代C++中,我们希望使用static_assert对constexpr数组进行编译时长度验证,但目前尚无简便实现方式(因函数参数无法成为constexpr,即使在constexpr或consteval函数中亦然!)。
- 此方法仅适用于显式函数调用。若调用隐式(例如将数组作为操作数调用运算符),则无法传递长度参数。
其次,若存在语义上无效的元素值(例如-1的测试分数),可改用该值标记数组末尾。这样便能通过统计数组起始点至该终止元素间的元素数量来计算数组长度,也可通过从起始点迭代至终止元素的方式遍历数组。此方法的优势在于即使隐式函数调用也能正常工作。
关键洞见:
C 风格字符串(即 C 风格数组)使用空终止符标记字符串末尾,因此即使数组类型衰变后仍可遍历。
但该方法也存在若干问题:
- 若终止元素不存在,遍历将直接越界至数组末尾,导致未定义行为。
- 遍历数组的函数需对终止元素进行特殊处理(例如C风格字符串打印函数需避免输出终止元素)。
- 实际数组长度与语义有效元素数量存在不匹配。若使用错误长度,可能导致语义无效的终止元素被“处理”。
- 此方法仅在存在语义无效值时有效,而这种情况通常并不存在。
在多数情况下应避免使用C风格数组
由于其非标准的传递语义(采用按地址传递而非按值传递)以及数组衰变导致长度信息丢失的风险,C风格数组已普遍失宠。我们建议尽可能避免使用它们。
最佳实践:
在可行的情况下避免使用C风格数组。
- 对于只读字符串(字符串字面量符号常量和字符串参数),优先使用std::string_view。
- 对于可修改字符串,优先使用std::string。
- 对于非全局constexpr数组,优先使用std::array。
- 对于非constexpr数组,优先使用std::vector。
全局 constexpr 数组仍可使用 C 风格数组,具体将在后续讨论。
补充说明...:
C++ 中数组可通过引用传递,此时数组参数在函数调用时不会衰变(但数组引用在求值时仍会衰变)。然而开发者容易忘记保持这种一致性,一个遗漏的引用就会导致参数衰变。此外,数组引用参数必须具有固定长度,这意味着函数只能处理特定长度的数组。若需处理不同长度的数组,则必须使用函数模板。但若为“修复”C风格数组而同时采用这两种方案,不如直接使用std::array!
那么在现代C++中,C风格数组何时会被使用?
在现代C++中,C风格数组通常用于两种情况:
用于存储常量表达式全局(或常量表达式静态局部)程序数据。由于此类数组可在程序任意位置直接访问,无需传递数组参数,从而避免了衰变相关问题。其定义语法比 std::array 更简洁,更重要的是,此类数组的索引操作不会像标准库容器类那样出现符号转换问题。
作为函数或类的参数,用于直接处理非constexpr C风格字符串参数(而非强制转换为std::string_view)。此类场景存在两种可能动因:首先,将非constexpr C风格字符串转换为std::string_view需遍历字符串以确定其长度。若函数位于性能关键代码段且无需长度(例如函数本就会遍历字符串),则避免转换可能更有效。其次,若函数(或类)调用的其他函数期望接收 C 风格字符串,仅为后续转换而先转换为 std::string_view 可能并非最优方案(除非另有理由需要 std::string_view)。
测验时间
问题 #1
什么是数组衰变,它为何构成问题?
显示解答
当评估C风格数组时,在大多数上下文中它会被隐式转换为指向数组元素类型的指针。
衰减数组会丢失其长度信息,这使得与长度相关的错误更容易引入程序。
问题 #2
为何C风格字符串(即C风格数组)使用空终止符?
显示解答
当C风格数组被传递给函数时,它会衰变并丢失其长度信息。如果C风格字符串没有空终止符,函数将无法确定字符串的长度。
问题 #3
附加题:为何C风格字符串采用空终止符,而非要求函数接收衰变后的C风格字符串及显式长度信息?
显示解答
这个问题可能有许多答案,但以下是一些可能的解释:
其操作体验将极其糟糕,因为我们将面临大量额外参数和魔数(例如 printString(“Hello”, 5))。
字符串与指定长度极易出现不匹配。字符串长度本质上是字符串本身的恒定属性。若依赖用户维护此恒定性,必然导致错误(例如 printString(“Hello”, 6))。
附加题 #2:即使C++想强制传递显式长度信息,为何无法实现?
显示提示
提示:考虑使用 std::cout 打印字符串的情况。
显示解答
只有显式调用函数时,才能同时传递C风格字符串和显式长度信息。若函数被隐式调用,则无法传递长度信息。
考虑如下语句:std::cout << cstr。二元运算符<<仅能接受两个操作数:std::cout和cstr。无法传递代表长度信息的额外参数。而空终止符方法则不存在此问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号