12-15 std::optional
在第 9.4 课——检测和处理错误中,我们讨论了函数遇到自身无法合理处理的错误的情况。例如,考虑一个计算并返回值的函数:
int doIntDivision(int x, int y)
{
return x / y;
}
如果调用者传入的值在语义上无效(例如y = 0),则此函数无法计算返回值(因为除以 0 在数学上是未定义的)。在这种情况下我们该怎么办?由于计算结果的函数不应产生副作用,因此此函数本身无法合理地解决错误。在这种情况下,通常的做法是让函数检测到错误,然后将错误返回给调用者,由调用者以某种适合程序的方式进行处理。
在之前链接的课程中,我们介绍了让函数向调用者返回错误的两种不同方法:
- 将返回值为 void 的函数改为返回布尔值(表示成功或失败)。
- 让返回值的函数返回一个哨兵值(一个特殊值,它不属于该函数可以返回的可能值集合),以指示错误。
例如,如果用户为以下函数参数x传入一个语义无效的参数,则该函数reciprocal()会返回一个值0.0(否则永远不会发生) :
#include <iostream>
// The reciprocal of x is 1/x, returns 0.0 if x=0
double reciprocal(double x)
{
if (x == 0.0) // if x is semantically invalid
return 0.0; // return 0.0 as a sentinel to indicate an error occurred
return 1.0 / x;
}
void testReciprocal(double d)
{
double result { reciprocal(d) };
std::cout << "The reciprocal of " << d << " is ";
if (result != 0.0)
std::cout << result << '\n';
else
std::cout << "undefined\n";
}
int main()
{
testReciprocal(5.0);
testReciprocal(-4.0);
testReciprocal(0.0);
return 0;
}

虽然这是一个相当有吸引力的解决方案,但也存在一些潜在的缺点:
- 程序员必须知道函数使用哪个哨兵值来指示错误(并且对于使用此方法返回错误的每个函数,此值可能不同)。
- 同一函数的不同版本可能使用不同的哨兵值。
- 对于所有可能的哨兵值都是有效返回值的函数,此方法无效。
考虑doIntDivision()上面的函数。如果用户传入一个值0作为参数,它会返回什么值?我们不能使用0,因为0除以任何数都会得到0。事实上,我们无法返回任何自然界中不存在的值。
那我们该怎么办?
首先,我们可以选择一些(希望是)不常见的返回值作为哨兵值,并用它来指示错误:
#include <limits> // for std::numeric_limits
// returns std::numeric_limits<int>::lowest() on failure
int doIntDivision(int x, int y)
{
if (y == 0)
return std::numeric_limits<int>::lowest();
return x / y;
}

std::numeric_limits<T>::lowest()是一个返回类型为 T 的最大负值的函数。它是我们在第 9.5 课中介绍的 std::numeric_limits<T>::max() 函数(返回 T 类型的最大正值)的对应函数——std::cin 和处理无效输入。
在上面的示例中,如果doIntDivision()无法继续,我们将返回std::numeric_limits<int>::lowest(),该返回值将为负的整数值返回给调用者,以表明函数失败。
虽然这种方法大部分情况下有效,但它有两个缺点:
- 每次调用这个函数时,我们都需要检查返回值是否相等,以
std::numeric_limits<int>::lowest()确定是否失败。这既冗长又麻烦。 - 这是一个半谓词问题的例子:如果用户调用某个函数
doIntDivision(std::numeric_limits<int>::lowest(), 1),返回的结果std::numeric_limits<int>::lowest()将无法明确判断函数是成功还是失败。这是否会造成问题取决于函数的实际使用方式,但这无疑是我们需要关注的另一个问题,也是程序中可能出现错误的另一种途径。
其次,我们可以放弃使用返回值来返回错误,而改用其他机制(例如异常)。然而,异常处理本身也会带来一些复杂性和性能开销,可能并不合适或理想。对于这类场景来说,这可能有点过度设计了。
第三,我们可以放弃返回单个值,而是返回两个值:一个值(类型为 bool)指示函数是否成功,另一个值(类型为所需的返回值)保存实际的返回值(如果函数成功)或不确定的值(如果函数失败)。这可能是所有方案中最好的。
在 C++17 之前,选择后一种方案需要自行实现。虽然 C++ 提供了多种实现方式,但任何自行编写的方法都不可避免地会导致不一致和错误。
返回std::optional
C++17 引入了 std::optional,这是一个实现了可选值的类模板类型。也就是说,std::optional<T> 可以有一个 T 类型的值,也可以没有。我们可以用它来实现上面的第三个选项:
#include <iostream>
#include <optional> // for std::optional (C++17)
// Our function now optionally returns an int value
std::optional<int> doIntDivision(int x, int y)
{
if (y == 0)
return {}; // or return std::nullopt
return x / y;
}
int main()
{
std::optional<int> result1 { doIntDivision(20, 5) };
if (result1) // if the function returned a value
std::cout << "Result 1: " << *result1 << '\n'; // get the value
else
std::cout << "Result 1: failed\n";
std::optional<int> result2 { doIntDivision(5, 0) };
if (result2)
std::cout << "Result 2: " << *result2 << '\n';
else
std::cout << "Result 2: failed\n";
return 0;
}
打印出来的内容:

使用起来std::optional非常简单。我们可以构造一个std::optional<T>带值或不带值的元素:
std::optional<int> o1 { 5 }; // initialize with a value
std::optional<int> o2 {}; // initialize with no value
std::optional<int> o3 { std::nullopt }; // initialize with no value
要判断 std::optional 是否有值,我们可以选择以下方法之一:
if (o1.has_value()) // call has_value() to check if o1 has a value
if (o2) // use implicit conversion to bool to check if o2 has a value
要从 std::optional 中获取值,我们可以选择以下方法之一:
std::cout << *o1; // dereference to get value stored in o1 (undefined behavior if o1 does not have a value)
std::cout << o2.value(); // call value() to get value stored in o2 (throws std::bad_optional_access exception if o2 does not have a value)
std::cout << o3.value_or(42); // call value_or() to get value stored in o3 (or value `42` if o3 doesn't have a value)

请注意,它std::optional的使用语法与指针基本相同:
| Behavior | Pointer | std::optional |
|---|---|---|
| Hold no value | initialize/assign {} or std::nullptr | initialize/assign {} or std::nullopt |
| Hold a value | initialize/assign an address | initialize/assign a value |
| Check if has value | implicit conversion to bool | implicit conversion to bool or has_value() |
| Get value | dereference | dereference or value() |
然而,从语义上讲,指针和 astd::optional却截然不同。
- 指针具有引用语义,这意味着它指向另一个对象,赋值操作复制的是指针本身,而不是对象。如果我们按地址返回指针,指针会被复制回调用者,而不是指针指向的对象。这意味着我们不能按地址返回局部对象,因为我们会将该对象的地址复制回调用者,然后该对象会被销毁,导致返回的指针悬空。
std::optional具有值语义,这意味着它实际上包含其值,赋值操作会复制该值。如果我们按值返回一个std::optional,则std::optional(包括其包含的值)将被复制回调用者。这意味着我们可以使用std::optional.
考虑到这一点,让我们来看看示例是如何工作的。doIntDivision()现在,我们的函数返回的是一个 std::optional<int>而不是一个 int 。在函数体内部,如果检测到错误,我们返回 {},这隐式地返回一个不包含值的 std::optional。如果检测到值,我们返回该值,这隐式地返回一个包含该值的 std::optional。
在函数内部main(),我们使用隐式转换为布尔值来检查返回的std::optional是否有值。如果有值,我们就解引用该std::optional对象来获取值。如果没有值,我们就执行错误处理。就是这样!
返回 std::optional 的优点和缺点
返回 std::optional值有很多好处:
- 使用
std::optional有效的文档说明函数可能返回值也可能不返回值。 - 我们不必记住哪个值会被作为哨兵返回。
- 它的使用语法
std::optional简单易懂。
返回std::optional确实存在一些缺点:
- 我们必须先确保数组
std::optional包含值才能获取值。如果我们解引用一个std::optional不包含值的数组,就会出现未定义行为。 std::optional没有提供将函数失败原因信息传递回去的方法。- 除非你的函数需要返回有关其失败原因的额外信息(以便更好地理解失败原因,或区分不同类型的失败),否则
std::optional对于可能返回值或失败的函数来说,这是一个极好的选择。
最佳实践
对于可能失败的函数,返回一个std::optional(而不是哨兵值),除非你的函数需要返回有关其失败原因的额外信息。
相关内容
std::expected(C++23 中引入)旨在处理函数可能返回预期值或意外错误代码的情况。有关更多信息,请参阅std::expected参考文档。
将 std::optional 用作可选函数参数
在第12.11 课——按地址传递(第二部分)中,我们讨论了如何使用按地址传递来允许函数接受“可选”参数(也就是说,调用者可以传入一个空值nullptr来表示“无参数”,也可以传入一个对象)。然而,这种方法的一个缺点是,非空参数必须是左值(这样才能将其地址传递给函数)。
顾名思义,std::optional 函数提供了一种接受可选参数(仅用作输入参数)的替代方法。例如:
#include <iostream>
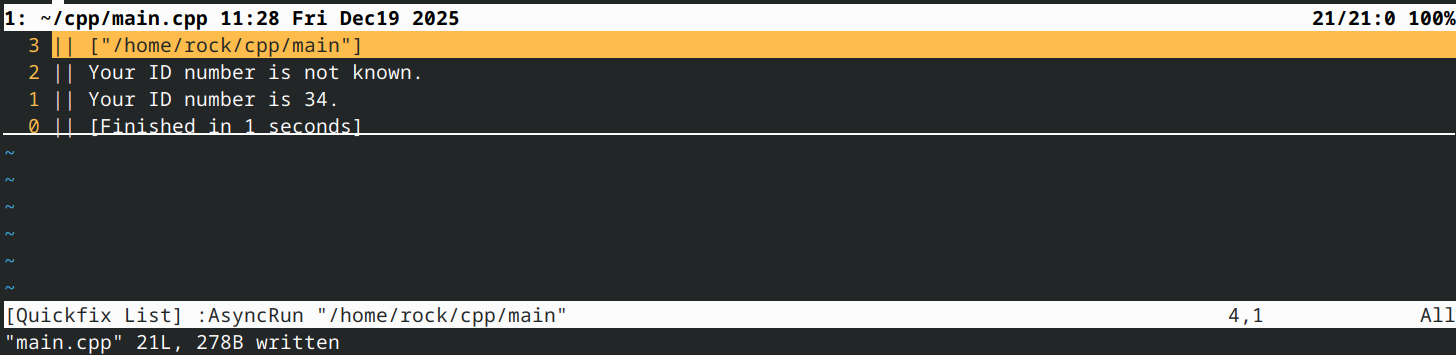
void printIDNumber(const int *id=nullptr)
{
if (id)
std::cout << "Your ID number is " << *id << ".\n";
else
std::cout << "Your ID number is not known.\n";
}
int main()
{
printIDNumber(); // we don't know the user's ID yet
int userid { 34 };
printIDNumber(&userid); // we know the user's ID now
return 0;
}
你可以这样做:
#include <iostream>
#include <optional>
void printIDNumber(std::optional<const int> id = std::nullopt)
{
if (id)
std::cout << "Your ID number is " << *id << ".\n";
else
std::cout << "Your ID number is not known.\n";
}
int main()
{
printIDNumber(); // we don't know the user's ID yet
int userid { 34 };
printIDNumber(userid); // we know the user's ID now
printIDNumber(62); // we can also pass an rvalue
return 0;
}

这种方法有两个优点:
- 它有效地说明了该参数是可选的。
- 我们可以传入一个右值(因为
std::optional会创建一个副本)。
然而,由于 std::optional 会复制其参数,当参数T是复制成本很高的类型(例如 std::string)时,就会出现问题。对于普通的函数参数,我们通过将参数设为 const lvalue reference 来解决这个问题,这样就不会进行复制。遗憾的是,从 C++23 开始, std::optional 不再支持引用。
因此,我们建议仅在通常按值传递std::optionalconst T*。
适合高级读者
虽然
std::optional它不直接支持引用,但你可以使用std::reference_wrapper(我们将在第17.5 课——通过std::reference_wrapper创建引用数组中std::reference_wrapper介绍)来模拟引用。让我们看看使用std::string和std::reference_wrapper后上面的程序会是什么样子:
#include <functional> // for std::reference_wrapper
#include <iostream>
#include <optional>
#include <string>
struct Employee
{
std::string name{}; // expensive to copy
int id;
};
void printEmployeeID(std::optional<std::reference_wrapper<Employee>> e=std::nullopt)
{
if (e)
std::cout << "Your ID number is " << e->get().id << ".\n";
else
std::cout << "Your ID number is not known.\n";
}
int main()
{
printEmployeeID(); // we don't know the Employee yet
Employee e { "James", 34 };
printEmployeeID(e); // we know the Employee's ID now
return 0;
}

为了进行比较,这里给出指针版本:
#include <iostream>
#include <string>
struct Employee
{
std::string name{}; // expensive to copy
int id;
};
void printEmployeeID(const Employee* e=nullptr)
{
if (e)
std::cout << "Your ID number is " << e->id << ".\n";
else
std::cout << "Your ID number is not known.\n";
}
int main()
{
printEmployeeID(); // we don't know the Employee yet
Employee e { "James", 34 };
printEmployeeID(&e); // we know the Employee's ID now
return 0;
}
这两个程序几乎完全相同。我们认为前者并不比后者更易读或更易维护,因此没有必要为了它而在程序中引入两种额外的类型。

在许多情况下,函数重载提供了一种更优的解决方案:
#include <iostream>
#include <string>
struct Employee
{
std::string name{}; // expensive to copy
int id;
};
void printEmployeeID()
{
std::cout << "Your ID number is not known.\n";
}
void printEmployeeID(const Employee& e)
{
std::cout << "Your ID number is " << e.id << ".\n";
}
int main()
{
printEmployeeID(); // we don't know the Employee yet
Employee e { "James", 34 };
printEmployeeID(e); // we know the Employee's ID now
printEmployeeID( { "Dave", 62 } ); // we can even pass rvalues
return 0;
}
最佳实践
建议std::optional使用可选的返回类型。
对于可选函数参数,应尽可能使用函数重载。否则,当T通常按值传递时,请使用std::Optional<T>作为可选参数。当T复制成本较高时,也应优先使用const T*。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号