
Prompt Engineering - Google白皮书
引言
在使用大语言模型(LLM)时,我们通过文本或图片形式的 prompt 输入,指导模型输出目标明确的内容。虽然人人都可以写 prompt,但高效的 prompt 往往较复杂。
LLM 的输出效果受多方面影响,包括:所用模型、训练数据、模型配置、词语选择、语气风格、结构设计、上下文信息。
一个设计不良的 prompt 会大大限制模型的能力发挥。
Prompt Engineering
LLM 是基于顺序文本预测下一个 token 的语言模型。其原理是:
将输入文本转为 token,根据已有 token 预测下一个 token,不断循环,逐步生成完整内容。
因此,编写 prompt 的关键在于设定正确的 token 顺序,引导模型做出准确预测。
高质量 prompt 通常具备良好的:
- 长度控制
- 语言风格
- 结构安排
- 与任务之间的契合度
可用于多种任务:
- 文本总结
- 问答
- 文本分类
- 翻译(语言/代码)
- 代码生成与解释
LLM 输出配置
选择具体模型后,需要根据任务设置适当的输出参数,以获得最佳效果。
1. Output Length(输出长度)
- 长输出 = 更多计算 + 响应慢 + 成本高
- 缩短长度不会提升简洁度,只是提前终止生成
- 若需控制长度,应从 prompt 设计着手,使其简要
2. 采样控制参数
LLM 预测下一个 token 时会基于概率分布,输出受以下参数控制:
| 参数 | 简要说明 | 精准定义 |
|---|---|---|
| Temperature | 控制输出确定性 | 调整 logits 缩放,影响 softmax 分布形状 |
| Top-K | 限定选择前 K 个 token | 只从概率最高的 K 个 token 中采样 |
| Top-P | 限定累计概率 ≥ P 的集合 | 从累计概率达到 P 的 token 集合中采样(又称 nucleus sampling) |
Temperature(取值范围:0 ~ 1)
- 低值(如 0)→ 更确定性(确定选择最高概率 token),分布陡峭
- 高值(如 0.8)→ 更多样化或意外结果
- 0 值 = greedy decoding(但仍可能因 tie-break 机制而变化)
Top-K
- 控制选择前 K 个高概率 token
- K 大 → 输出更丰富
- K 小 → 更真实但不稳定,K=1 等同 greedy decoding
Top-P
- 控制选择累计概率超过 P 的 token 子集
- 比 Top-K 更灵活,根据上下文动态调整候选集大小
推荐参数设置(按需求场景)
说明:在极端设置某一参数(如
temperature = 0、top-k=1、top-p=0)时,其他参数将失去调参意义。以下是根据不同需求推荐的组合设置:
| 场景 | Temperature | Top-P | Top-K | 特点说明 |
|---|---|---|---|---|
| 通用设置 | 0.2 |
0.95 |
30 |
内容连贯、有一定创造性但不突兀,适合大多数任务 |
| 高创造性场景 | 0.9 |
0.99 |
40 |
输出更具多样性与灵感,适合写作、创意构思等开放性任务 |
| 低创造性场景 | 0.1 |
0.9 |
20 |
更稳定,逻辑性强,适合技术、规约类内容生成 |
| 唯一正确答案 | 0 |
忽略 | 忽略 | 完全确定性,始终选最高概率 token,适合数学计算、事实问答等场景 |
⚠️ Warning:
Repetition Loop Bug
- 你可能遇到过大模型像“卡住”一样,不断重复生成相同内容的情况,这通常是由于 Temperature / Top-P / Top-K 设置不当造成的。
- 低 Temperature 情况下,模型过于确定,严格选择高概率词,容易回溯自身生成内容,形成循环;
- 高 Temperature 情况下,模型输出过于随机,也可能偶然回到先前状态,导致重复;
- 这类循环会持续,直到输出窗口被填满。
✅ 解决方法:
- 调整 Temperature / Top-P / Top-K,找到确定性与多样性的平衡;
- 或者在 prompt 中 限定输出长度,避免生成过长内容触发重复。
prompting 技巧
zero shot
这是最简单的prompt,即只提供任务的描述,不给示例。模型完全依赖预训练知识理解任务。
Table 1. 零样本提示示例(电影评论情感分类)
| 任务名称 | 目标 | 模型 |
|---|---|---|
| 1_1_movie_classification | 将电影评论分类为POSITIVE、NEUTRAL或NEGATIVE | gemini-pro |
| temperature | Token限制 | Top-K | Top-P |
|---|---|---|---|
| 0.1 | 5 | N/A | 1 |
| Prompt |
|---|
| Classify movie reviews as POSITIVE, NEUTRAL or NEGATIVE. Review: "Her" is a disturbing study revealing the direction humanity is headed if AI is allowed to keep evolving, unchecked. I wish there were more movies like this masterpiece. Sentiment: |
| Output |
|---|
| POSITIVE |
| 说明 |
|---|
| 零样本提示(Zero-Shot Prompting):未提供示例,直接通过指令引导模型分类。若零样本效果不佳,可通过添加1个或多个示例(单样本/少样本提示)优化。 |
one-shot & few-shot
one-shot prompt: 提供一个示例,按照示例模仿输出。
few-shot prompt: 提供多个示例,可以提高模型模仿输出方式的几率。
披萨订单解析示例(解析披萨订单为JSON)
| 任务名称 | 目标 | 模型 |
|---|---|---|
| 1_4_pizza_order_parsing | 将披萨订单解析为 JSON | gemini-pro |
| temperature | Token限制 | Top-K | Top-P |
|---|---|---|---|
| 0.1 | 250 | N/A | 1 |
| Prompt |
|---|
| 将顾客的披萨订单解析为有效的 JSON: 示例: 我想要一个小号披萨,配料有奶酪、番茄酱和意大利辣香肠。 JSON 响应: json { "size": "small", "type": "normal", "ingredients": [["cheese", "tomato sauce", "peperoni"]] } 示例: 我可以要一个大号披萨,配料有番茄酱、罗勒和马苏里拉奶酪吗? JSON 响应: Json { "size": "large", "type": "normal", "ingredients": [["tomato sauce", "bazel", "mozzarella"]] } 现在,我想要一个大号披萨,一半是奶酪和马苏里拉奶酪。另一半是番茄酱、火腿和菠萝。 JSON 响应: |
| Output |
|---|
| Json { "size": "large", "type": "half-half", "ingredients": [["cheese", "mozzarella"], ["tomato sauce", "ham", "pineapple"]] } |
| 说明 |
|---|
| 通过提供示例,模型能够理解披萨订单的结构,并将其转换为标准化的JSON格式。 |
System, Contextual, and Role Prompting
- System prompting: 模型的目的,比如翻译语言分类评论。
你是一个学术研究助手,需要回答用户提出的问题,并用简洁、客观的语言列出依据。如果用户请求引用,请提供参考资料。
- Contextual prompting: 当前对话的详细细节和背景信息,让模型回答有所根据。
用户输入历史:
Q: “如何在 Python 中创建一个列表?”
A: “你可以使用方括号,如 list = [1, 2, 3]。”
当前输入:
Q: “那如何向列表中添加元素?”
→ 模型理解用户在继续上一个话题,生成相关回答。
- Role prompting: 分配模型明确的角色,模型回复及相关知识行为与角色一致。
你是一名资深医生,专门回答关于心血管健康的问题。请根据临床知识,为用户提供详细的解答,并说明每条建议的依据。
🧾 三者对比总结表格
| 特性/提示类型 | System Prompting | Contextual Prompting | Role Prompting |
|---|---|---|---|
| 作用阶段 | 初始化或会话启动阶段 | 与用户输入实时绑定 | 通常在开头设定,影响整体回答风格 |
| 是否动态变化 | ❌ 一般固定 | ✅ 根据输入实时变化 | ❌ 一般固定 |
| 内容形式 | 规则、行为设定 | 上下文、对话历史、任务说明 | 模拟身份、任务角色 |
| 典型用途 | 设定模型语气、格式、行为规范 | 理解任务细节、实现上下文连续性 | 构建专业助手、专家系统 |
| 适合任务 | 聊天机器人、统一输出、风格控制 | 问答、多轮对话、代码生成 | 医疗、法律、教育、客服、面试等领域角色扮演 |
🧩 组合使用建议
- ✅ System + Role Prompting:构建统一风格的专家型助手(如医生+礼貌语气)
- ✅ System + Contextual Prompting:构建多轮对话系统(如Customer Support)
- ✅ All Three:打造专业、有语境、有行为规范的高质量智能体
Step-back prompting (先退一步)
输入提问者期望的回答方向、约束条件或目标场景的背景知识,引导模型在特定的框架下针对性输出答案的提示策略。理清思路,设定思维框架,是问题从通常问题变为明确问题。
在回答这个问题之前,请先思考相关的物理原理和日常生活中的例子,再给出清晰的解释。
prompt 示例:
问题:为什么苹果从树上掉下来?
请先思考:
- 涉及哪些自然现象?
- 有没有类似的例子?
- 哪些物理定律可以解释?
然后再回答这个问题。
期望效果:
思考:
苹果从树上掉落是因为重力的作用。重力是地球吸引物体向其中心的力。这个现象在我们的日常生活中很常见,比如球从高处落地、雨滴从天上落下等。这个过程主要可以通过牛顿的万有引力定律来解释。
回答:
苹果之所以会掉下来,是因为地球的重力在作用。根据牛顿的引力定律,地球对所有物体都有吸引力,导致苹果从树上被吸引向地面。
Chain of Thought(CoT)
通过输出中间推理过程,提升LLMs的逻辑能力。
#不使用CoT
prompt:当我3岁时,我的伙伴年龄是我的三倍,现在我20岁,那么他现在多少岁?
output: 63 岁
# 使用CoT(结合zore-shot)
prompt:当我3岁时,我的伙伴年龄是我的三倍,现在我20岁,那么他现在多少岁?让我们一步步思考这个问题。
output:
1. 我们先假设我现在的年龄是x
2. 当我3岁时,我的年龄是3岁
3. 我伙伴那时的年龄是我的3倍,这意味着我伙伴9岁
4. 现在,我20岁,这意味着我的年龄增长了20-3=17岁。
5. 当我3岁时我的伙伴9岁,我的年龄增长17岁,我的伙伴也一定增长了17岁。
6. 所以我的伙伴 9+17=26岁
# 使用CoT(结合one-shot)
prompt:
Q:当我伙伴2岁时,我的年龄是他的两倍,现在我40岁,那么他现在多少岁?让我们一步步思考这个问题。
A:当我伙伴2岁,我2*2=4岁,这里的年龄区别是我的年龄要年长2岁。现在我40岁,所以我的伙伴是40-2=38岁。答案是38岁。
Q:当我3岁时,我的伙伴年龄是我的三倍,现在我20岁,那么他现在多少岁?让我们一步步思考这个问题。
output:
当我3岁时,我的伙伴3*3=9岁,这里的年龄区别是我的伙伴要年长6岁,现在我20岁,所以我的伙伴是20+6=26岁。答案是26岁。
Self-consistency
生成多个思考路径,并统计答案的共识性,选取最可信的输出。是Cot的改进版本.
所需步骤:
-
- 多次采样模型回答,使用同一个prompt,使用高temperature(0.7-1.0),鼓励不同的思考路径。
-
- 提取每个reasoning最终输出的答案。
-
- 统计最常见的答案,选择出现频率最高的答案,作为最终可欣输出。
# 简单数学推理(Lot)
prompt:
Q:mary有5个苹果,她给john2个后又买了4个,现在mary有多少个苹果?请一步步进行思考。
output1:Mary 有 5, 给 2 → 3, 买 4 → 7
output2:5 - 2 = 3, 3 + 4 = 7
output3: 5 - 2 = 3, forgot to add 4 → 3
output4:5 - 2 = 3, 3 + 4 = 7
output5:5 apples, gave 2 → 3, bought 4 → 3 - wrong logic → 3
#统计 7出现3词,2出现2次,最终选择7
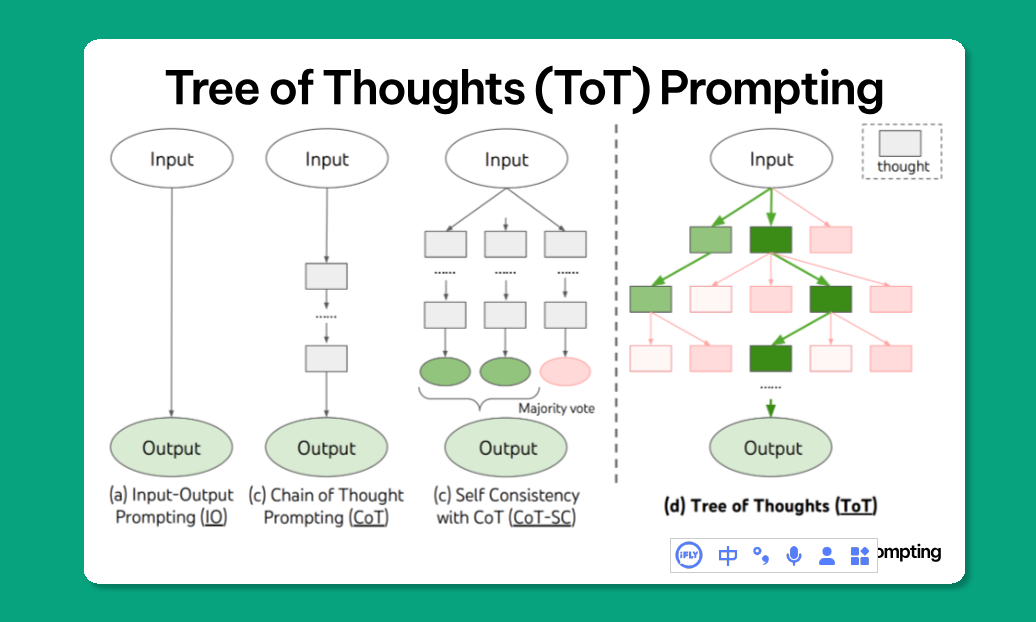
Tree of Thoughts (ToT)
将LLMs输出组织成一个思维树,每个节点代表一种“思路”或中间“推理步骤”。
语言模型生成和评估思维的能力与搜索算法(例如广度优先搜索和深度优先搜索)相结合,从而能够通过前瞻和回溯对思维进行系统性探索。也就是给出一个思维逻辑图prompt,让模型对所有思维链进行评估得到叶子节点
[起点]
├── 假设 A: 小明赢小红
│ ├── 小刚输了
│ ├── 再假设小红赢小刚 → 小明输了(矛盾)
│ └── 结论:假设 A 不成立
├── 假设 B: 小红赢小刚
│ ├── 小明输了
│ ├── 再假设小明赢小红 → 矛盾(小明不能赢)
│ └── 结论:小刚不能输给小红
└── 假设 C: 小刚赢小红
├── 推理 1……
ReAct(Reason + Act)
结合 推理(Reasoning) 和 行动(Acting),让语言模型在回答前多步搜索、分析、推断,类似人类“查资料+思考”的过程。
示例代码(基于 LangChain)
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.llms import VertexAI
prompt = "How many kids do the band members of Metallica have?"
llm = VertexAI(temperature=0.1) # 使用 VertexAI 大模型
tools = load_tools(["serpapi"], llm=llm) # serpapi 工具用于实时搜索引擎
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
) # 零样本提示 + ReAct 推理机制
agent.run(prompt)
模型推理过程(带 reasoning & action)
> Entering new AgentExecutor chain...
Metallica has 4 members.
Action: Search
Action Input: How many kids does James Hetfield have?
Observation: three children
Thought: 1/4 Metallica band members have 3 children
Action: Search
Action Input: How many kids does Lars Ulrich have?
Observation: 3
Thought: 2/4 Metallica band members have 6 children
Action: Search
Action Input: How many kids does Kirk Hammett have?
Observation: Hammett has been married to his second wife Lani since 1998. They have two sons, Angel and Vincenzo.
Thought: 3/4 Metallica band members have 8 children
Action: Search
Action Input: How many kids does Robert Trujillo have?
Observation: 2
Thought: 4/4 Metallica band members have 10 children
Final Answer: 10
Automatic Prompt Engineering(自动化提示词优化)
自动化生成与评估 prompt,有助于发现最优的提示模板,提升任务表现。
步骤:
- 使用 LLM 生成多个 prompt(提示模板)
- 对多个 prompt 输出结果,使用自动评估指标进行打分比较
→ 可用 BLEU 或 ROUGE
BLEU(Bilingual Evaluation Understudy)
评估翻译/文本生成的精确度
- 对比模型输出与参考答案中的 n-gram 重叠
- 引入 Brevity Penalty(长度惩罚) 防止输出太短
BLEU = BP × exp(Σ w_n * log p_n)
p_n:第 n 阶 n-gram 的匹配精度
w_n:各阶权重(一般均匀分配)
BP:Brevity Penalty,长度惩罚项
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)
用于摘要、问答等场景,衡量信息覆盖能力
| 名称 | 含义描述 |
|---|---|
| ROUGE-N | n-gram 重叠率(n=1,2 最常见) |
| ROUGE-L | 最长公共子序列(LCS)匹配 |
| ROUGE-W | 加权 LCS(考虑词间距离) |
| ROUGE-S | 跳跃式 bigram(Skip-bigram)匹配 |
- 可用于计算:召回率 Recall、精确率 Precision 和 F1 分数
Code prompting
如果你会编程,那么这个代码提示词没什么好讲的,你只需要明白你想干什么就行。
多模态提示词依靠多种输入格式来引导大型语言模型。
- Prompts for writing code
- Prompts for explaining code
- Prompts for translating code
- Prompts for debugging and reviewing code

 浙公网安备 33010602011771号
浙公网安备 33010602011771号