web性能优化之--合理使用http缓存和localStorage做资源缓存
一、前言
开始先扯点别的:
估计很多前端er的同学应该遇到过:在旧项目中添加新的功能模块、或者修改一些静态文件时候,当代码部署到线上之后,需求方验收OK,此时你送了一口气,当你准备开始得意于自己的masterpiece时候,突然需求方跑来和你说,很多用户反应还是没有看到新的效果,或者某个图片还是旧的。。。。what? 估计你第一反应就是,肯定是可恶的缓存搞的鬼。我遇到这样几种情况;
1、在某个旧项目中,我们的静态资源部署主要是在每次更新的时候自动添加版本号的形式,比如在后面加上版本?v=时间戳,按理来说,发布代码之后,用户应该拉取的是最新的资源,但是事与愿违,就是有的浏览器直接忽略后面的版本号,获取旧的资源;处理办法一般是:再在静态资源后面继续加一个版本号再发布一次。这样就OK了。虽然是OK了,但这就引发了一个前端代码部署问题,看这里:《大公司里怎样开发和部署前端代码》。
2、在某个Hybrid开发中,客户端吊起一个webview,如果这个资源是用户经常访问的且这个文件经常变动(例如直播中的某次抢红包等特效)的,需要后台在配置这链接必须每次加上一个最新的版本号,不然大概率会有用户访问旧的页面。但是这个还不一定够,之前就遇到过,修改看版本还是不行,明明就是缓存问题,但是你却无能为力,你总不能要求用户去清缓存吧?后面硬让运维清了cdn才有效果,坑得不行。
3、某个新项目中采用非覆盖式的文件模式,即使每次有变动之后,静态资源就会更换不同的hash名,这样就可以避免用户访问到旧的资源了。这也是现在比较流行的方案。
上面讲的都是本地缓存带来的困扰,但是正是因为浏览器这种缓存策略,提高了web的性能,也节约了很多开销。
用户主动触发的页面刷新行为(比如刷新按钮、右键刷新、F5等),会导致浏览器放弃本地缓存,使用协商缓存(304缓存)。
下面讲讲http缓存策略。
二、浏览器缓存
三、http缓存策略
1、常见http报头
Accept: text/html,image/* #浏览器可以接收的类型 Accept-Encoding: gzip,compress #浏览器可以接收压缩编码类型 Accept-Language: en-us,zh-cn #浏览器可以接收的语言和国家类型 Host: www.lks.cn:80 #浏览器请求的主机和端口 If-Modified-Since: Tue, 11 Jul 2000 18:23:51 GMT #某个页面缓存时间 Referer: http://www.qq.com/ #请求来自于哪个页面 User-Agent: Mozilla/4.0 compatible; MSIE 5.5; Windows NT 5.0 #浏览器相关信息 Cookie: #浏览器暂存服务器发送的信息 Connection: close1.0/Keep-Alive1.1 #HTTP请求的版本的特点 Date: Tue, 11 Jul 2000 18:23:51GMT #请求网站的时间 Allow:GET #请求的方法 GET 常见的还有POST Keep-Alive:5 #连接的时间;5 Connection:keep-alive #是否是长连接 Cache-Control:max-age=600 #缓存的最长时间 600s
2、设置强缓存
Cache-Control: 缓存控制策略,值可能有public/private max-age=xxxx/no-store/no-cache。public/private定义文件是否允许中继缓存(比如CDN)对其缓存,private仅允许浏览器缓存文件而不允许中继缓存存储文件,public都允许。max-age=xxxx/no-store/no-cache定义文件的缓存时长,max-age定义文件在指定的时间内无需去服务端检查是否有更新,单位是秒;no-store简单粗暴,禁止任何中继缓存和浏览器存储任何响应;no-cache指定浏览器每次都要去服务端检查文件是否有更新。
Expires: 文件的绝对过期时间,在过期前,再次请求同一文件不会和服务端交互,而是直接从缓存里取。Expires属性的行为受Cache-Control属性影响,当响应头里同时又Cache-Control属性,且Cache-Control属性的值有max-age时,max-age优先级大于Expires,会重写Expires的值。Expires因为使用绝对时间,所以它的缺点是需要客户端和服务端保持时间同步,它的优点是在文件过期前和服务端完全没有交互,对于追求性能极致的网站有很大的诱惑力。且Expires属性是http1.0定义的,对于不支持http1.1的浏览器来说很宝贵。Cache-Control 的选择更多,设置更细致,如果同时存在的话,优先级高于 Expires。
一般的:
HTTP 信息头中包含Cache-Control:no-cache,pragma:no-cache,或Cache-Control:max-age=0 等告诉浏览器不用缓存的请求
需要根据Cookie,认证信息等决定输入内容的动态请求是不能被缓存的
经过HTTPS安全加密的请求(有人也经过测试发现,ie 其实在头部加入 Cache-Control:max-age 信息,firefox 在头部加入 Cache-Control:Public 之后,能够对HTTPS的资源进行缓存)
HTTP 响应头中不包含 Last-Modified/Etag,也不包含 Cache-Control/Expires 的请求无法被缓存
3、设置协商缓存
3.1、 request中的:
If-Modify-Since: 请求头中带的浏览器缓存里保存的上次响应时保存的文件最后修改时间
If-None-Match: 请求头中带的浏览器缓存里保存的上次响应时保存的文件ETag
3.2、response中的:
Last-Modified: 资源的最后修改时间,注意是文件的修改时间不是创建时间
Etag: 即Entity Tag,标识一个文件特定版本的字符串,可能是基于文件内容的哈希值或者是其它指纹码,不同服务器实现方式不同
3.3、检查更新的途径有多种,第一种是根据文件修改时间,request带If-Modify-Since即上次response中的Last-Modified,去服务端校验文件是否更新;二是根据文件的ETag,request带If-None-Match即上次response中的Etag,去服务端校验文件是否更新。我知道你一定会问request中f-Modify-Since和If-None-Match都有的话,是满足一个服务端就返回304吗?答案是否定的,需要两者都满足才会返回304。主要是基于以下几个原因:
a、Last-Modified 标注的最后修改时间只能精确到秒,服务器都是精确到毫秒级别的。如果有些资源在一秒之内被多次修改的话,他就不能准确标注文件的新鲜度了;
b、如果某些资源会被定期生成,当内容没有变化,但 Last-Modified 却改变了,导致文件没使用缓存;
c、有可能存在服务器没有准确获取资源修改时间,或者与代理服务器时间不一致的情形。
4、 get请求和post请求
4.1get:
请求可被缓存;
请求保留在浏览器历史记录中
请求可被收藏为书签
请求不应在处理敏感数据时使用
请求有长度限制
请求只应当用于取回数据
4.2post:
请求不会被缓存
请求不会保留在浏览器历史记录中
不能被收藏为书签
请求对数据长度没有要求
所以要想在客户端做HTTP的缓存一定要注意使用GET请求!
5、维护
5.1、如果后端是有专人写的话,缓存设置就需要他们配合,事实上,现在有专门的运维童鞋去维护这些,包括一些cdn的设置;
5.2、http缓存毕竟是web性能优化之一,也是前端er需要了解掌握的基础知识之一。
三、localStorage资源缓存
之前为了长时间缓存一些资源或者状态有使用过localStorage,前段时间看微信公众号的文章时候,微信把生成页面的js都缓存到localStorage中,这算是一个比较新的缓存控制“黑科技”。
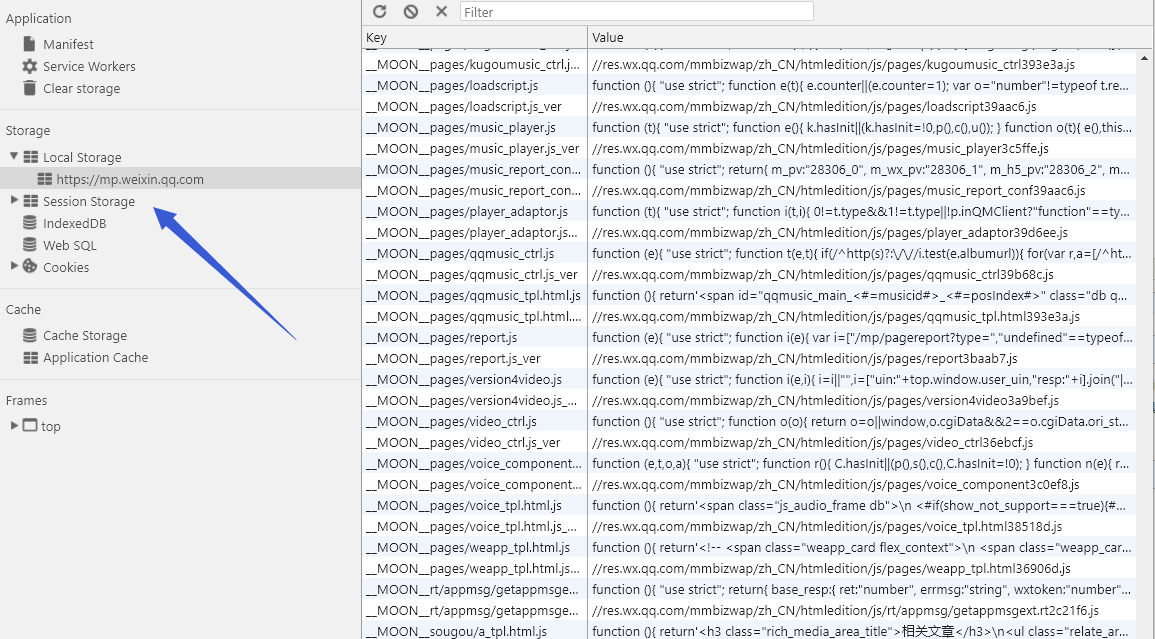
1、在快速迭代版本过程中,我们有时候只修改了某个js中的几行代码,却需要用户下载整个js文件,这在重视流量的移动端显得非常浪费,mt独创的增强更新算法实现了修改多少代码就只下载修改代码的功能,为用户和公司节省大量流量
2、localstorage里面存储的上个版本的js内容和版本号,当本次版本号和上次版本号不一致的时候,mt拼接出增量文件url去拉取增量文件,并和上个版本的js内容合并生成新版本内容。整个方案得核心在于增量文件得计算和合并
localStrorage虽有有永久缓存大量数据的功能,但是要实现这个方案,还需考虑几个问题:
1、版本更新机制
2、搭建更新代码的脚手架--微信自己开发的moon.js
2、存在xss安全隐患,毕竟客户端的代码可以任意修改。
1、兼容性不太好,不支持LS的浏览器比例仍然很大;
2、静态资源采用LS缓存存在安全隐患;
3、非首屏的css可以用LS缓存,首屏如果要考虑SEO,不能使用LS;
4、执行速度,读取后使用eval或创建<script>标签的时间会比浏览器直接加载慢。
5、版本控制,需要自己写一套版本控制机制。
6、localStorage以页面的域名划分,而常见的静态资源都以资源本身的域名来缓存,意味着如果你的应用有多个等价域名,它们之间的localStorage不互通,会造成缓存多份浪费。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号