
MT bench
MT bench
1 introduction
We create MT-bench, a benchmark consisting of 80 high-quality multi-turn questions. MT-bench is designed to test multi-turn conversation and instruction-following ability, covering common use cases and focusing on challenging questions to differentiate models. We identify 8 common categories of user prompts to guide its construction: writing, roleplay, extraction, reasoning, math, coding, knowledge I (STEM), and knowledge II (humanities/social science). For each category, we then manually designed 10 multi-turn questions. Table 1 lists several sample questions.
note: the introduction is from the paper
2 question categeries

3 how does it evaluation
We propose 3 LLM-as-a-judge variations. They can be implemented independently or in combination:
• Pairwise comparison. An LLM judge is presented with a question and two answers, and tasked to determine which one is better or declare a tie. The prompt used is given in Figure 5 (Appendix).
• Single answer grading. Alternatively, an LLM judge is asked to directly assign a score to a single answer. The prompt used for this scenario is in Figure 6 (Appendix).
• Reference-guided grading. In certain cases, it may be beneficial to provide a reference solution if applicable. An example prompt we use for grading math problems is in Figure 8 (Appendix).
note: To view the prompts, please view the paper in Appendix.
4 what's the indicator
We define the agreement between two types of judges as the probability of randomly selected individuals (but not identical) of each type agreeing on a randomly selected question. See more explanation in Appendix D.3. Average win rate is the average of win rates against all other players. These metrics can be computed with or without including tie votes.
note: win or out is based on the human's annotation.
use FastChat
click to view the code
# env mt_bench
git clone https://github.com/lm-sys/FastChat.git
cd FastChat
pip install -e ".[model_worker,llm_judge]"
python gen_judgment.py --model-list gpt-3.5-turbo gpt-4 --parallel 2
python show_result.py --model-list gpt-3.5-turbo gpt-4
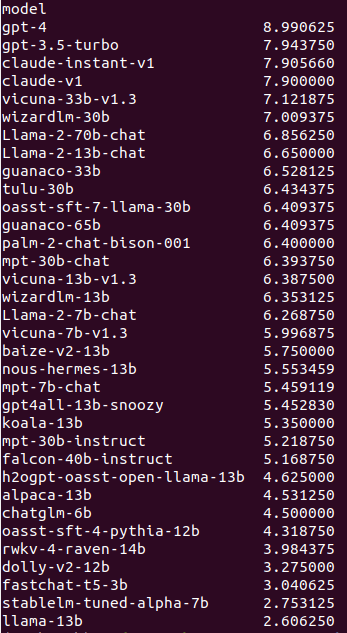
mixtral

 浙公网安备 33010602011771号
浙公网安备 33010602011771号