
humaneval benchmark
use code-eval
command
git clone https://github.com/abacaj/code-eval.git
cd code-eval
conda create -n human_eval python=3.10
conda activate human_eval
pip install -r requirements.txt
python eval_llama.py
evaluate_functional_correctness ./results/llama/eval.jsonl
the result
7B llama2
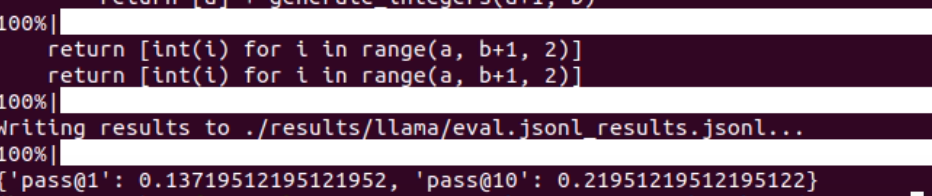
13B llama2

mistral7B

mixtral?


 浙公网安备 33010602011771号
浙公网安备 33010602011771号