
llama benchmarks
Introduction
Here we re-evaluate llama2 benchmarks to prove its performence.
datasets
In this blog, we'll test the following datasets shown in the images.
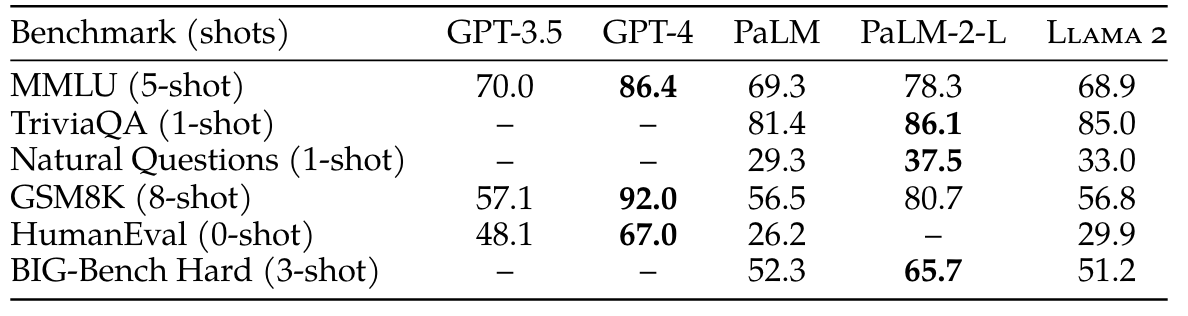
The 1st picture is the benchmarks for llma2-70B in llama2 paper.
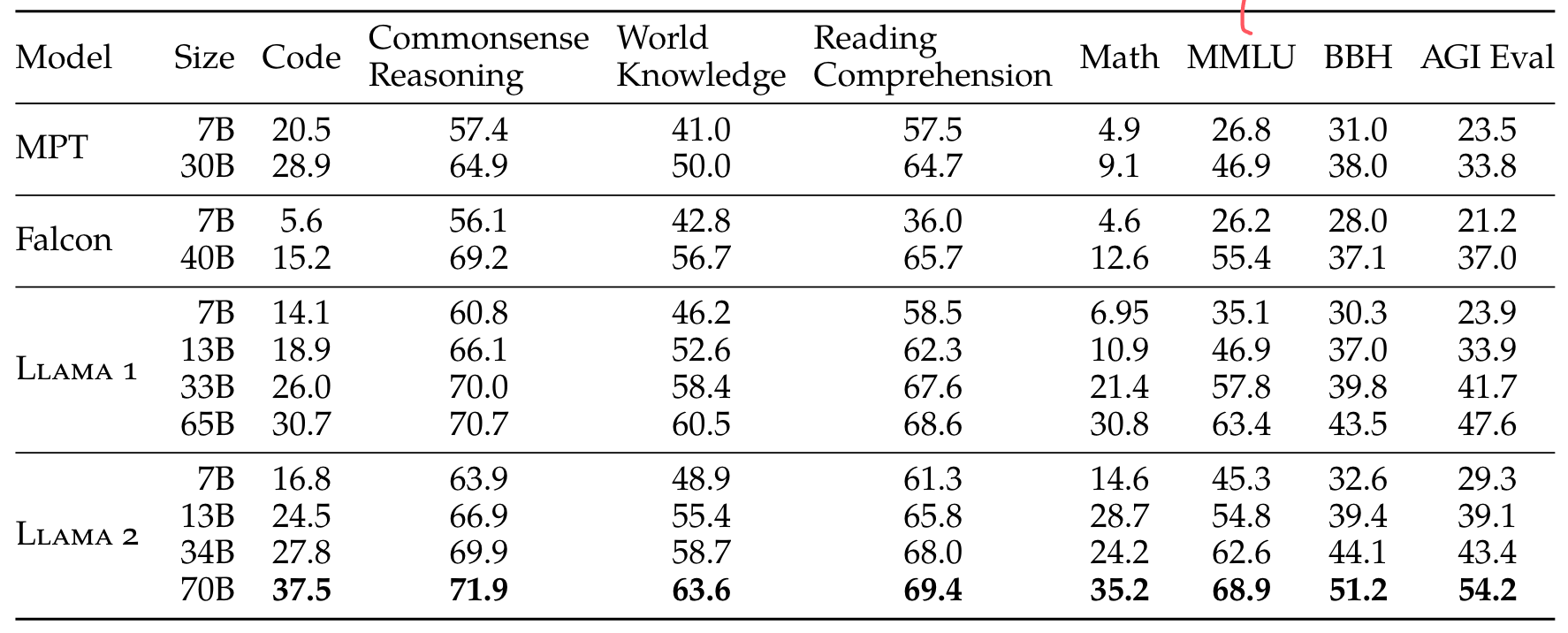
from here you can find the dataset
- Code. We report the average pass@1 scores of our models on HumanEval (Chen et al., 2021) and MBPP (Austin et al., 2021).
- Commonsense Reasoning. We report the average of PIQA (Bisk et al., 2020), SIQA (Sap et al., 2019), HellaSwag (Zellers et al., 2019a), WinoGrande (Sakaguchi et al., 2021), ARC easy and challenge (Clark et al., 2018), OpenBookQA (Mihaylov et al., 2018), and CommonsenseQA (Talmor et al., 2018). We report 7-shot results for CommonSenseQA and 0-shot results for all other benchmarks.
- World Knowledge. We evaluate the 5-shot performance on NaturalQuestions (Kwiatkowski et al., 2019) and TriviaQA (Joshi et al., 2017) and report the average.
- Reading Comprehension. For reading comprehension, we report the 0-shot average on SQuAD (Rajpurkar et al., 2018), QuAC (Choi et al., 2018), and BoolQ (Clark et al., 2019).
- MATH. We report the average of the GSM8K (8 shot) (Cobbe et al., 2021) and MATH (4 shot) (Hendrycks et al., 2021) benchmarks at top 1.
mmlu: address
TriviaQA: huggingface address1 | huggingface address2 | github official code
GSM8K: huggingface address
HumanEval: huggingface address
BIG-Bench Hard(bbh): huggingface address
Hella-Swag: huggingface address
NQ(natural question): github address huggingface address
MBPP: huggingface address
PIQA: huggingface address
SIQA: huggingface address
ARC: huggingface address
WinoGrande: huggingface address
OpenBookQA: huggingface address
CommonsenseQA: huggingface address
SQuAD: huggingface address SQuADv2
QuAC: huggingface address
BooIQ: huggingface address
indicator
model conversion
here we convert the official llama model into HF style
7B has been converted. here
for 13B:
click to view the command
# /home/ludaze/Docker/Llama/llama
cd llama-13-7b
mkdir 13B
mv ./* ./13B
cp ../tokenizer.model ../tokenizer_checklist.chk .
cd ..
python convert_llama_weights_to_hf.py --input_dir llama-2-13b --model_size 13B --output_dir models_hf/13B
for 70B
click to view the command
# /home/ludaze/Docker/Llama/llama
cd llama-2-70b
mkdir 70B
mv ./checklist.chk consolidated.00.pth consolidated.01.pth consolidated.02.pth consolidated.03.pth consolidated.04.pth consolidated.05.pth consolidated.06.pth consolidated.07.pth params.json ./70B
cp ../tokenizer.model ../tokenizer_checklist.chk .
cd ..
python convert_llama_weights_to_hf.py --input_dir llama-2-70b --model_size 70B --output_dir models_hf/70B
convert mixtral into HF format
use lm-evaluation-harness
lm-evaluation-harness is a benchmark plateform for multiple style model and datasets.
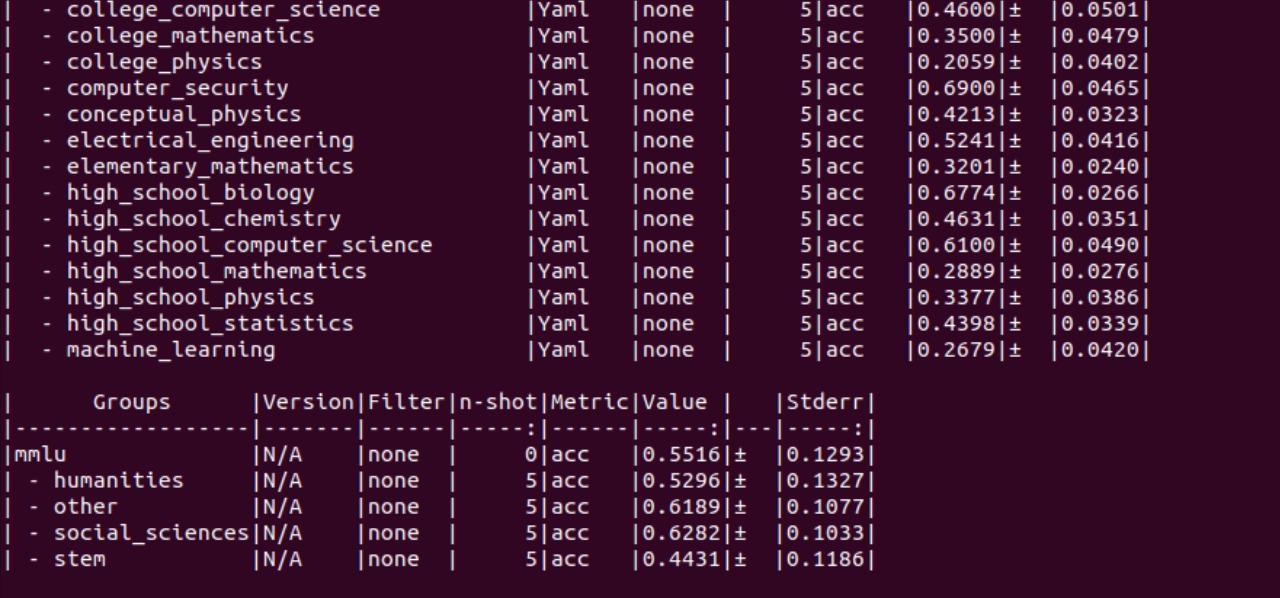
mmlu(5-shot)
environment lm_evaluation python=3.10
signle gup
click to view command
lm_eval --model hf \
--model_args pretrained=../llama/models_hf/7B \
--tasks mmlu \
--device cuda:1 \
--batch_size 8
# 5-shot
lm_eval --model hf \
--model_args pretrained=../llama/models_hf/7B \
--tasks mmlu \
--num_fewshot 5 \
--device cuda:1 \
--batch_size 8
multiple GPUS
click to view the command
# this command doesn't work
accelerate launch -m lm_eval --model hf \
--model_args pretrained=../llama/models_hf/7B \
--tasks mmlu \
--num_fewshot 5 \
--batch_size 32
# use llm, but just can work on some tasks
lm_eval --model vllm \
--model_args pretrained=../llama/models_hf/70B,tensor_parallel_size=4,dtype=auto,gpu_memory_utilization=0.8,data_parallel_size=2 \
--tasks mmlu \
--num_fewshot 5 \
--batch_size auto
# use lm_eval and set parallelize=True
lm_eval --model hf --model_args pretrained=../llama/models_hf/70B,parallelize=True \
--tasks mmlu \
--num_fewshot 5 \
--batch_size 4
0-shot
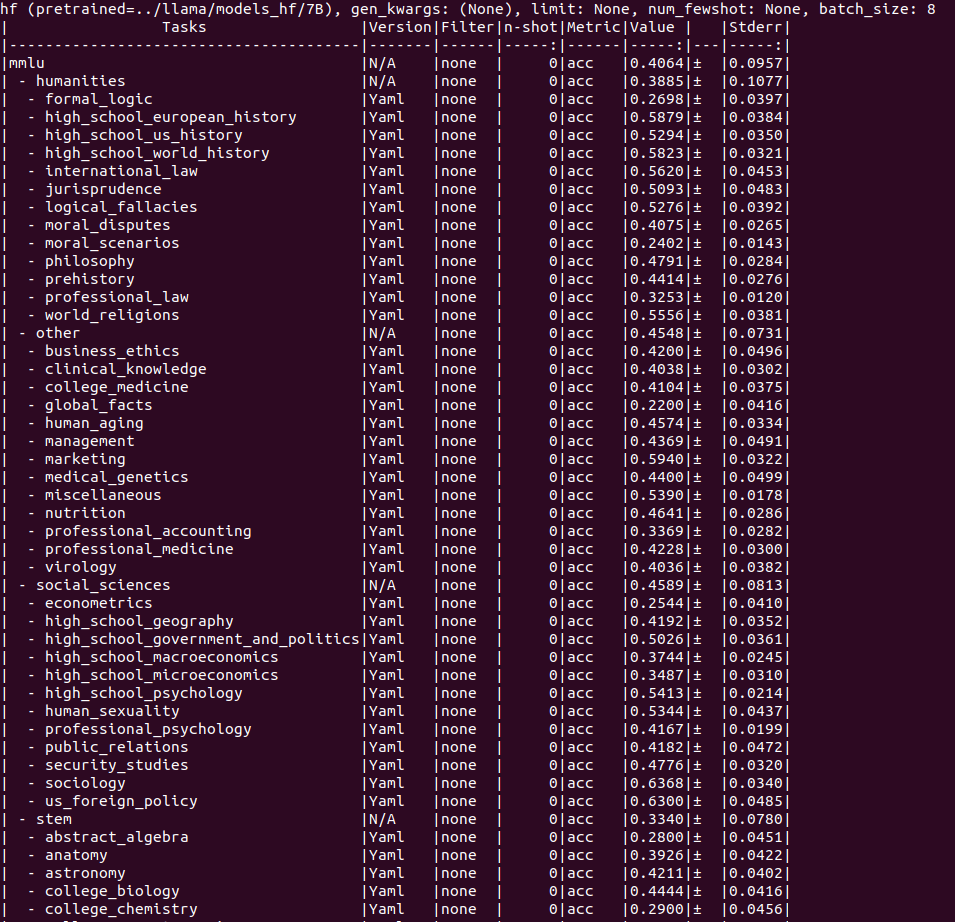
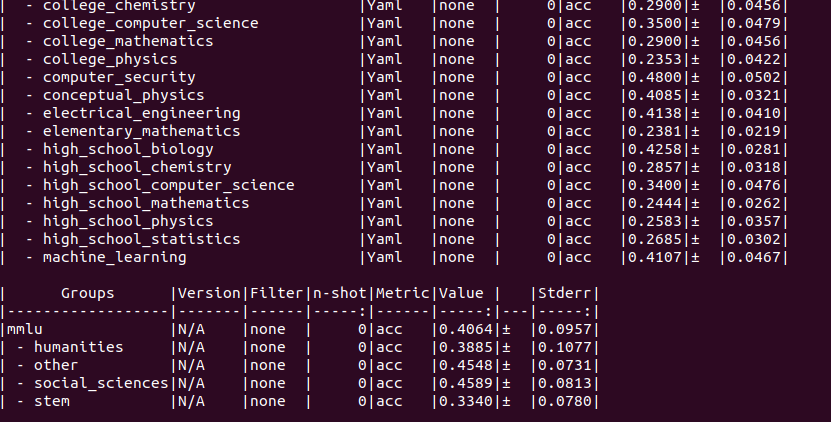
5-shot
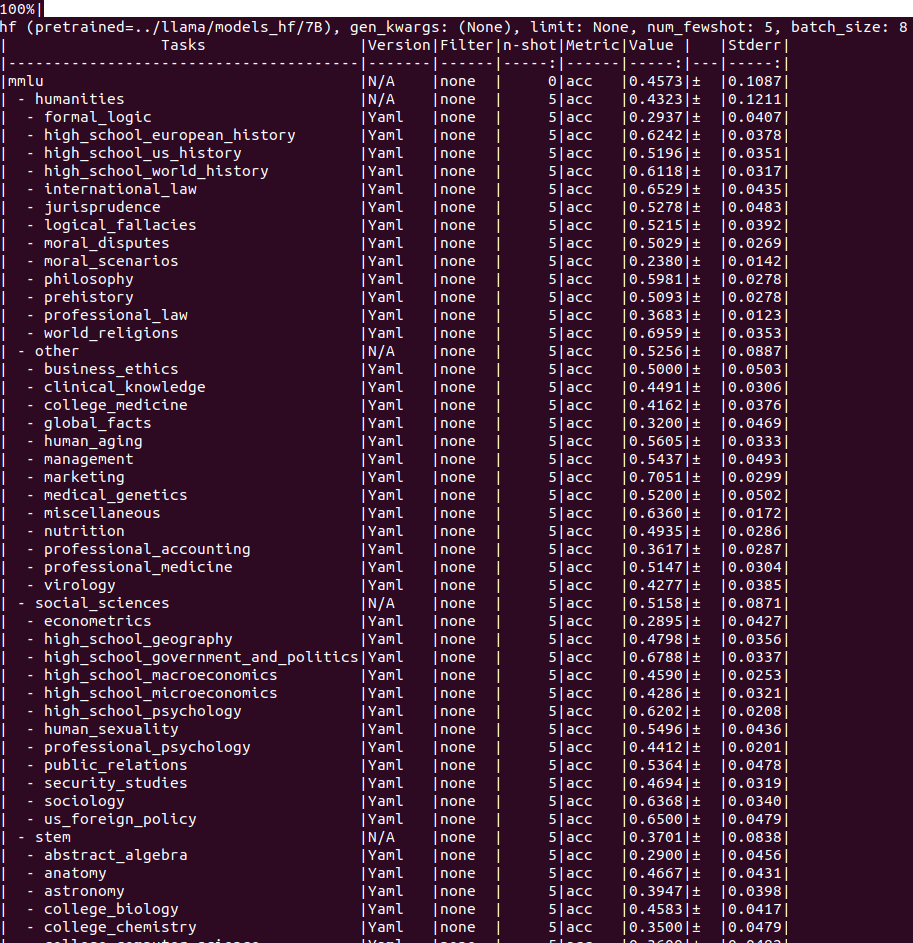
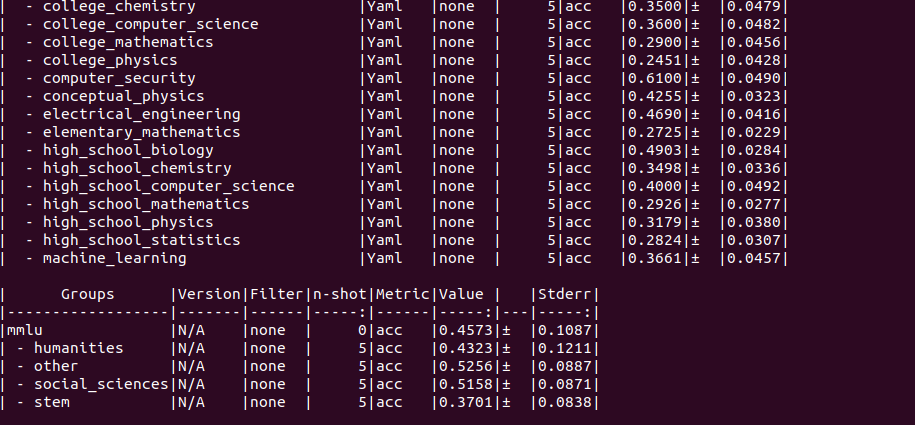
13B(5-shot)

triviaqa(1-shot)
single gup
click to view command
lm_eval --model hf \
--model_args pretrained=../llama/models_hf/7B \
--tasks triviaqa \
--num_fewshot 1 \
--device cuda:2 \
--batch_size 8

1-shot(f1)

1-shot(perplexity)

0-shot(acc) 7B

1-shot (acc) 7B

1-shot(acc) 13B

1-shot 13B
click to view the code
lm_eval --model vllm \
--model_args pretrained=../llama/models_hf/13B,tensor_parallel_size=1,dtype=auto,gpu_memory_utilization=0.99,data_parallel_size=1 \
--tasks triviaqa \
--num_fewshot 1 \
--device cuda:0 \
--batch_size auto

5-shot(13B)

gsm8k(8-shot)
single gup
click to view command
lm_eval --model hf \
--model_args pretrained=../llama/models_hf/7B \
--tasks gsm8k \
--num_fewshot 8 \
--device cuda:3 \
--batch_size 8

13B(8-shot)
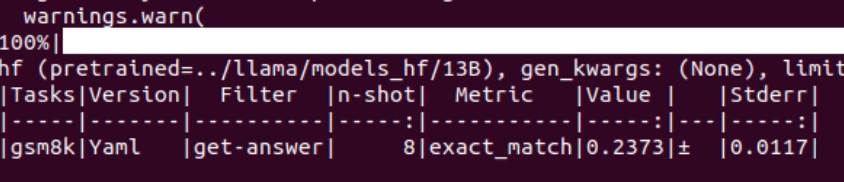
bigbench
click to view the code
lm_eval --model hf \
--model_args pretrained=../llama/models_hf/7B \
--tasks bigbench \
--num_fewshot 3 \
--device cuda:0 \
--batch_size 8
bbh(3-shot)
click to view the code
lm_eval --model hf \
--model_args pretrained=../llama/models_hf/7B \
--tasks bbh \
--num_fewshot 3 \
--device cuda:0 \
--batch_size 8
7B exact-match
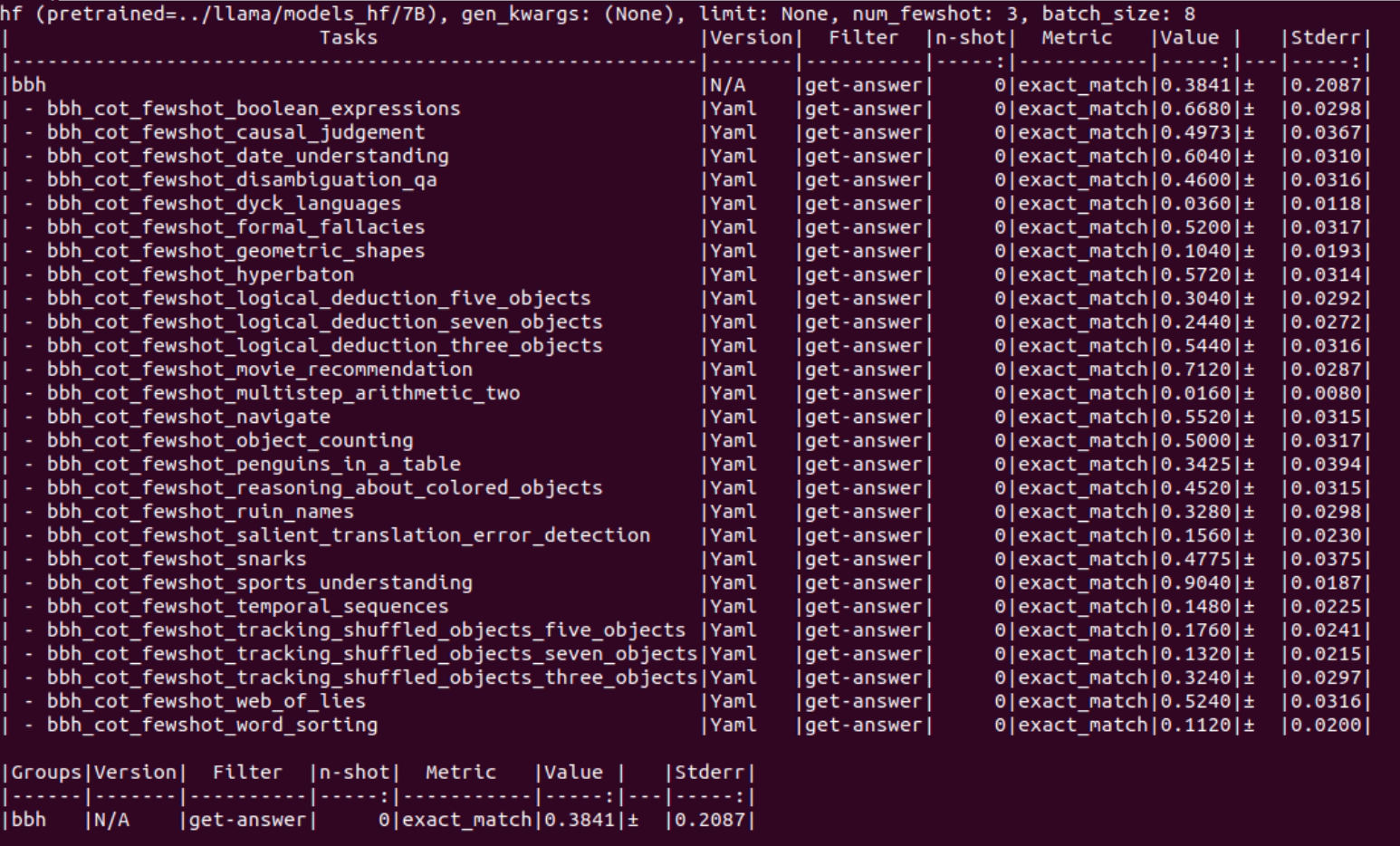
70B
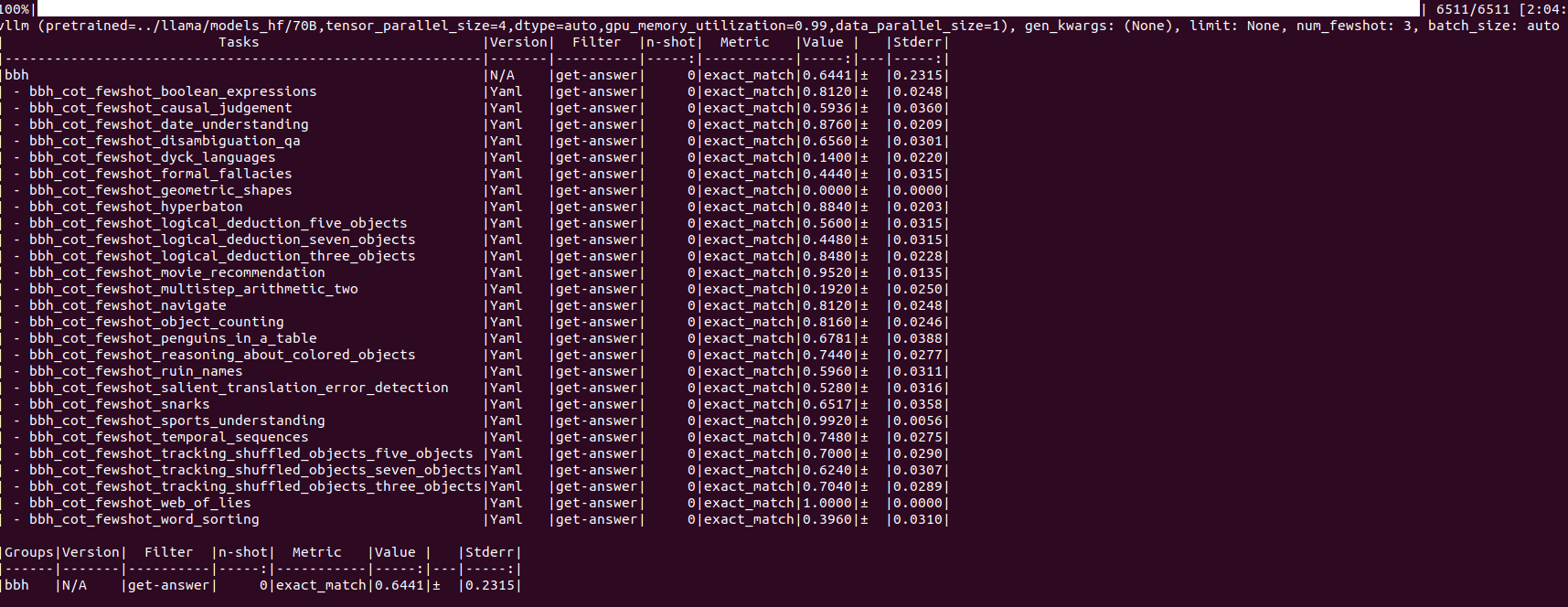
here may be a problem, paprameter shown 3-shot, but the table shown 0-shot.?
mistral-7B
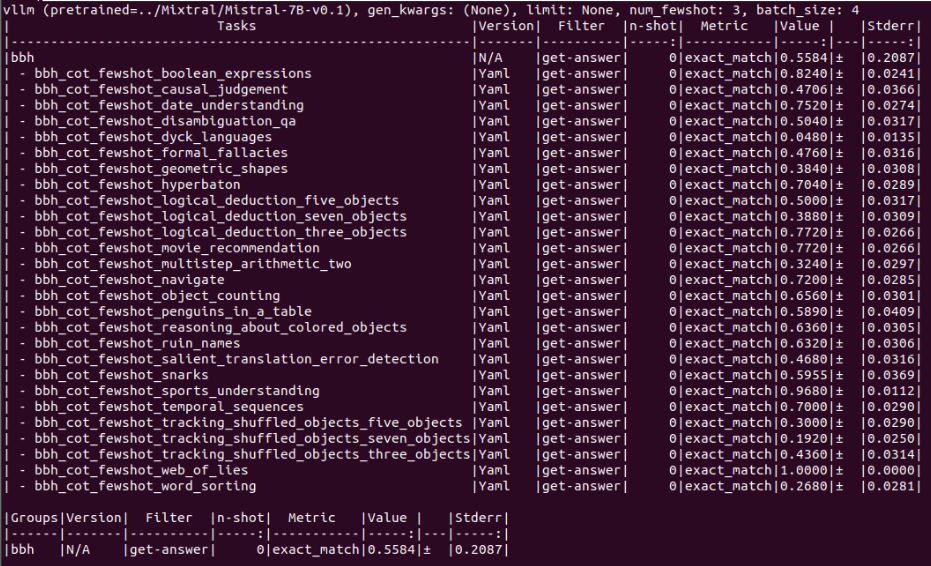
piqa
70B

siqa
70B

hellaswag
command for 4 tasks
click to view the command
#7B
lm_eval --model hf \
--model_args pretrained=../llama/models_hf/7B \
--tasks hellaswag,openbookqa,arc_easy,winogrande \
--num_fewshot 0 \
--device cuda:1 \
--batch_size 8
#13B
lm_eval --model hf \
--model_args pretrained=../llama/models_hf/13B \
--tasks hellaswag,openbookqa,arc_easy,winogrande \
--num_fewshot 0 \
--device cuda:2 \
--batch_size 8
#70B
lm_eval --model vllm \
--model_args pretrained=../llama/models_hf/70B,tensor_parallel_size=4,dtype=auto,gpu_memory_utilization=0.99,data_parallel_size=1 \
--tasks hellaswag,openbookqa,arc_easy,winogrande \
--num_fewshot 0 \
--batch_size auto
70B

opencompass 7B
python run.py --models hf_llama_7b --datasets hellaswag_clean_ppl

openbookqa
7B
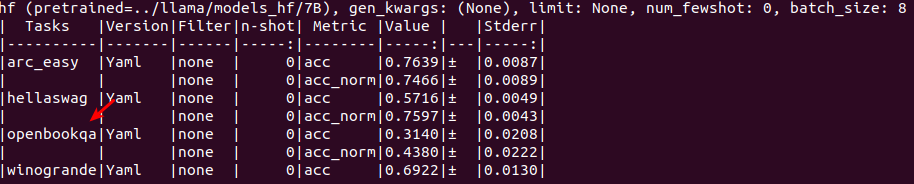
70B

arc_easy
7B
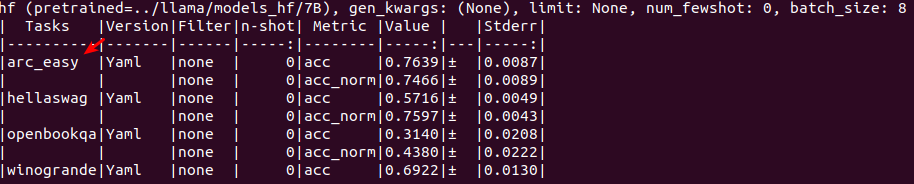
70B

winogrande
7B
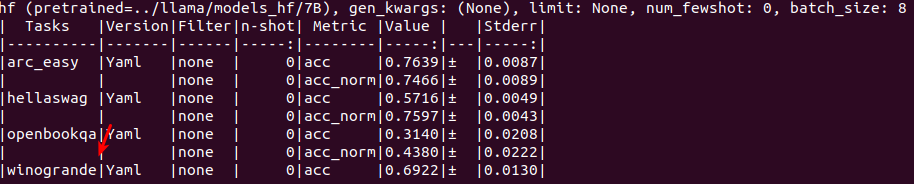
70B

anli
7B
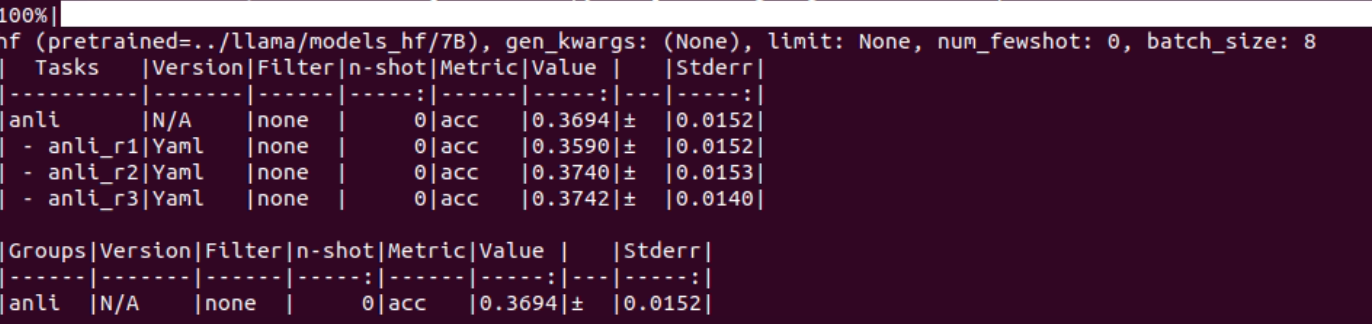
squad2
7B
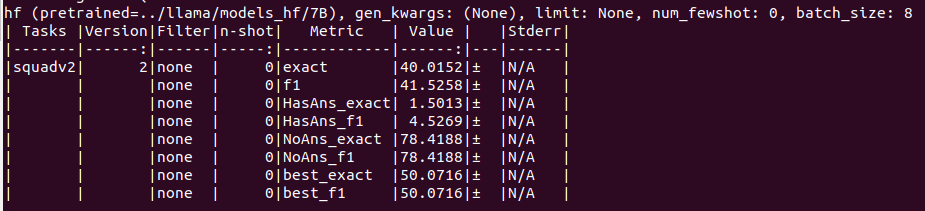
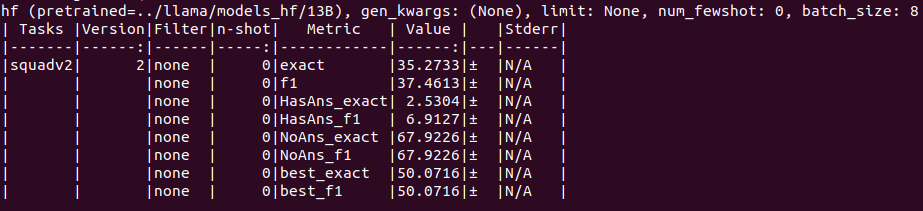
13B
others
click to view the code
lm_eval --model hf \
--model_args pretrained=../llama/models_hf/7B \
--tasks anli,arithmetic,asdiv,babi,belebele,blimp,cmmlu \
--num_fewshot 5 \
--device cuda:1 \
--batch_size 8

 浙公网安备 33010602011771号
浙公网安备 33010602011771号