
llama-recipes fine-tuning-1
bash code
cd /home/ludaze/Docker/Llama/llama conda activate llama_etuning git clone https://github.com/facebookresearch/llama.git wget https://raw.githubusercontent.com/huggingface/transformers/main/src/transformers/models/llama/convert_llama_weights_to_hf.py pip install git+https://github.com/huggingface/transformers pip install accelerate pip install sentencepiece cd llama-2-7b mkdir 7B mv ./checklist.chk consolidated.00.pth params.json ./7B cp ../tokenizer.model ../tokenizer_checklist.chk . pip install protobuf python convert_llama_weights_to_hf.py --input_dir llama-2-7b --model_size 7B --output_dir models_hf/7B
# use llama-recipes to fine tuning,
cd .. # return to Llama folder
git clone https://github.com/facebookresearch/llama-recipes.git
cd llama-recipes
pip install -r requirements.txt
test code before fine tuning
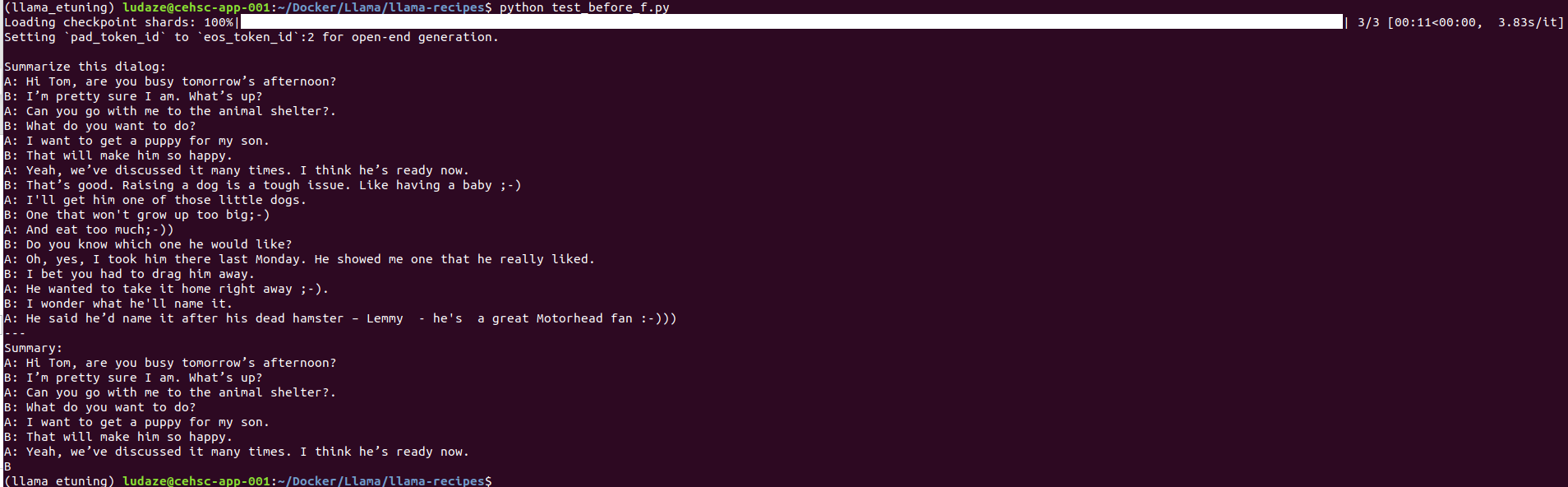
import torch from transformers import LlamaForCausalLM, LlamaTokenizer model_id="../llama/models_hf/7B" tokenizer = LlamaTokenizer.from_pretrained(model_id) model =LlamaForCausalLM.from_pretrained(model_id, load_in_8bit=True, device_map='auto', torch_dtype=torch.float16) eval_prompt = """ Summarize this dialog: A: Hi Tom, are you busy tomorrow’s afternoon? B: I’m pretty sure I am. What’s up? A: Can you go with me to the animal shelter?. B: What do you want to do? A: I want to get a puppy for my son. B: That will make him so happy. A: Yeah, we’ve discussed it many times. I think he’s ready now. B: That’s good. Raising a dog is a tough issue. Like having a baby ;-) A: I'll get him one of those little dogs. B: One that won't grow up too big;-) A: And eat too much;-)) B: Do you know which one he would like? A: Oh, yes, I took him there last Monday. He showed me one that he really liked. B: I bet you had to drag him away. A: He wanted to take it home right away ;-). B: I wonder what he'll name it. A: He said he’d name it after his dead hamster – Lemmy - he's a great Motorhead fan :-))) --- Summary: """ model_input = tokenizer(eval_prompt, return_tensors="pt").to("cuda") model.eval() with torch.no_grad(): print(tokenizer.decode(model.generate(**model_input, max_new_tokens=100)[0], skip_special_tokens=True))
test result before fine-tuning
start to fine-tuning
export CUDA_VISIBLE_DEVICES=0
# single GPU
python -m llama_recipes.finetuning --use_peft --peft_method lora --quantization --model_name ../llama/models_hf/7B --output_dir ../llama/PEFT/model
# multiple GPUs
torchrun --nnodes 1 --nproc_per_node 1 examples/finetuning.py --enable_fsdp --use_peft --peft_method lora --model_name ../llama/models_hf/7B --fsdp_config.pure_bf16 --output_dir ../llama/PEFT/model
single GPU fine-tuning screens
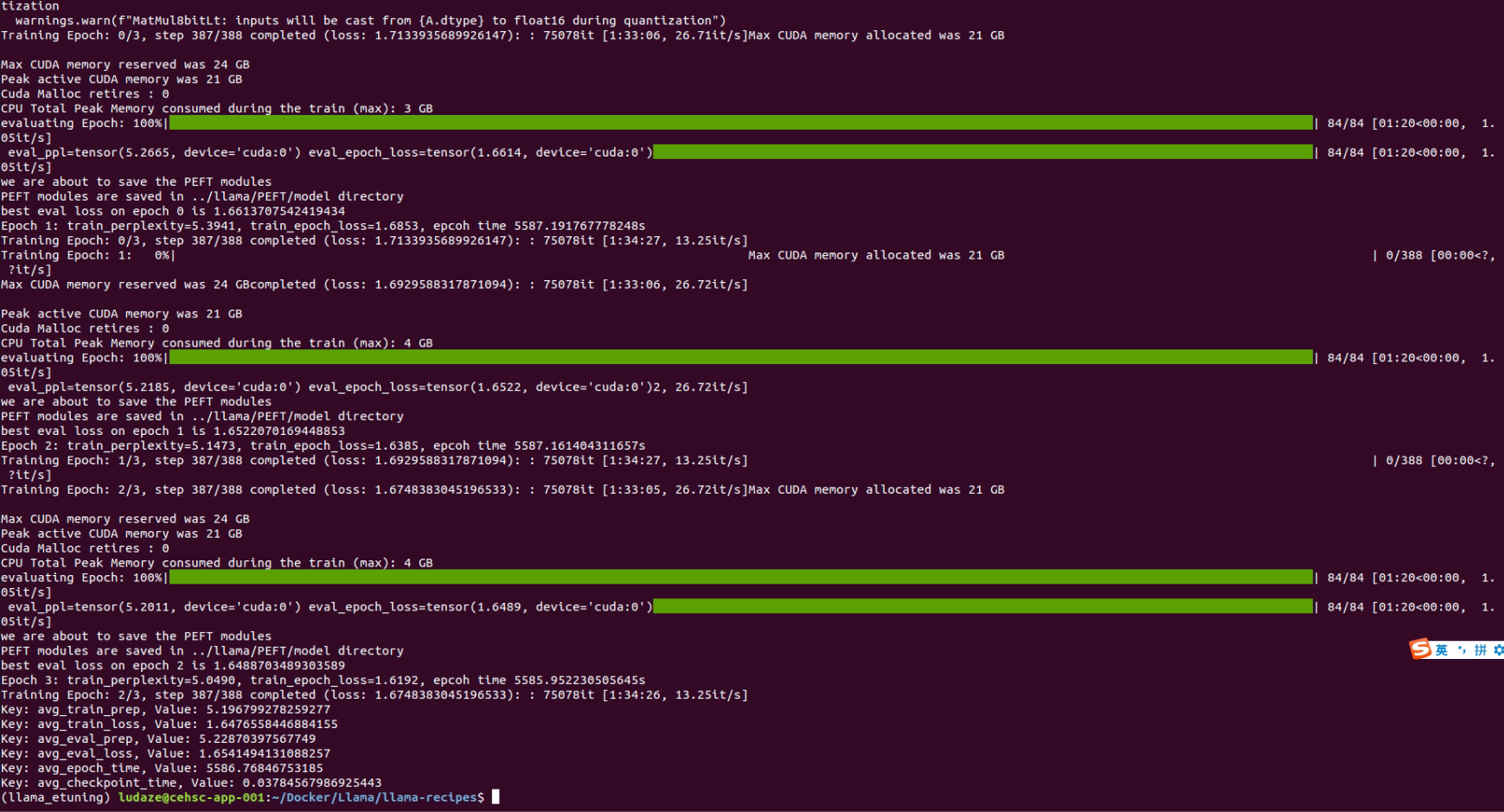
test after fine-tuning
code
import torch from transformers import LlamaForCausalLM, LlamaTokenizer from peft import PeftModel, PeftConfig model_id="../llama/models_hf/7B" tokenizer = LlamaTokenizer.from_pretrained(model_id) model =LlamaForCausalLM.from_pretrained(model_id, load_in_8bit=True, device_map='auto', torch_dtype=torch.float16) model = PeftModel.from_pretrained(model, "../llama/PEFT/model") eval_prompt = """ Summarize this dialog: A: Hi Tom, are you busy tomorrow’s afternoon? B: I’m pretty sure I am. What’s up? A: Can you go with me to the animal shelter?. B: What do you want to do? A: I want to get a puppy for my son. B: That will make him so happy. A: Yeah, we’ve discussed it many times. I think he’s ready now. B: That’s good. Raising a dog is a tough issue. Like having a baby ;-) A: I'll get him one of those little dogs. B: One that won't grow up too big;-) A: And eat too much;-)) B: Do you know which one he would like? A: Oh, yes, I took him there last Monday. He showed me one that he really liked. B: I bet you had to drag him away. A: He wanted to take it home right away ;-). B: I wonder what he'll name it. A: He said he’d name it after his dead hamster – Lemmy - he's a great Motorhead fan :-))) --- Summary: """ model_input = tokenizer(eval_prompt, return_tensors="pt").to("cuda") model.eval() with torch.no_grad(): print(tokenizer.decode(model.generate(**model_input, max_new_tokens=100)[0], skip_special_tokens=True))
screenshot

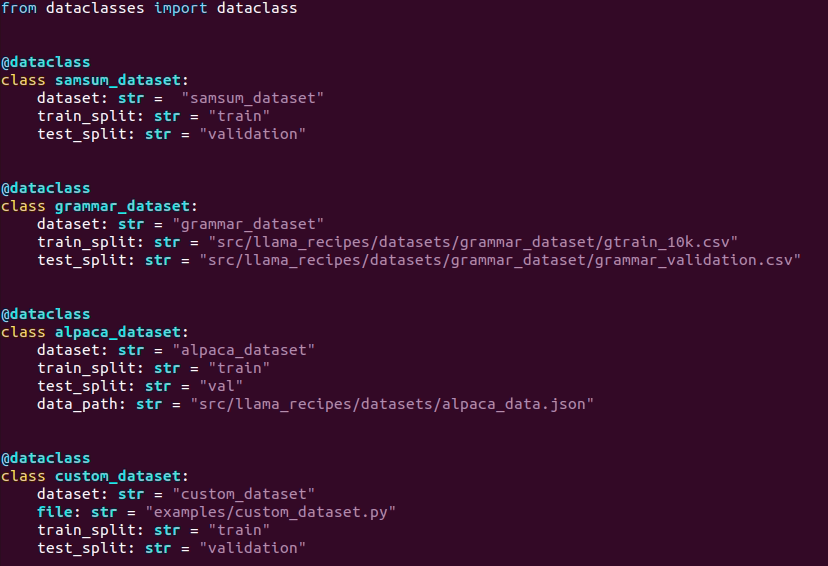
Dataset
dataset configuration
path: llama-recipes/src/llama_recipes/configs
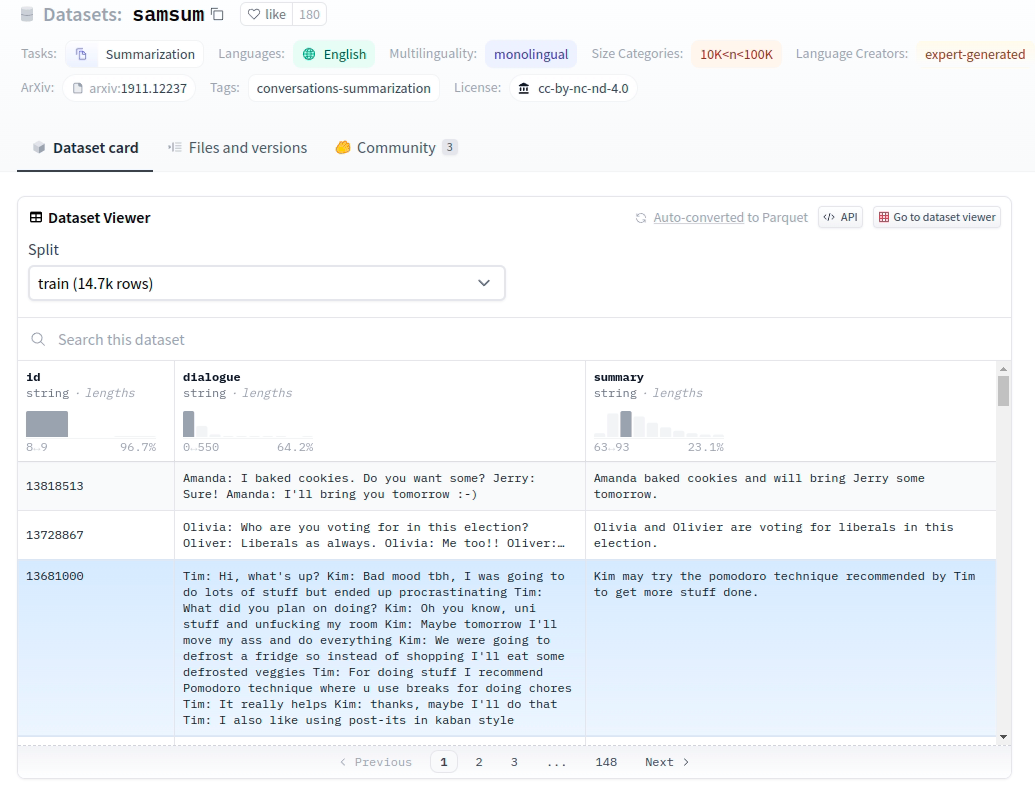
samsum dataset
using samsum dataset in default, bellow is the structure of samsum dataset structure(link of samsum dataset)
custom dataset
we can refer llama2-tutorials to create our custom dataset, under current directory structure, we can use the following command
python -m llama_recipes.finetuning \ --use_peft \ --peft_method lora \ --quantization \ --model_name ../llama/models_hf/7B \ --dataset alpaca_dataset \ --custom_dataset.file "dataset.py:get_preprocessed_arithmetic" \ --output_dir ../llama/fine-tuning/arithmetic \ --batch_size_training 1 \ --num_epochs 1 # remember use local llama_recipes moudle, set corrct PYTHONPATH value
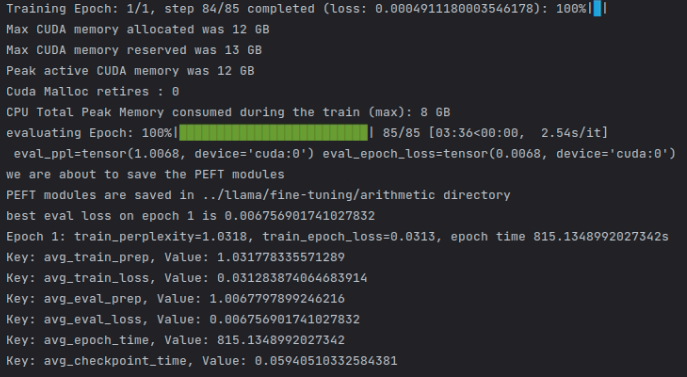
here is the screenshot of the result
Addition
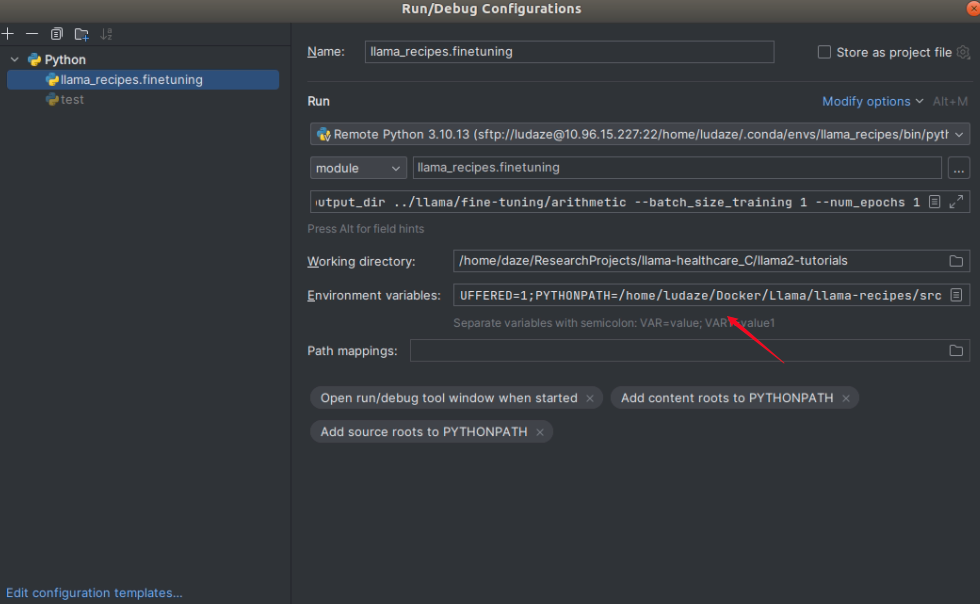
1. how to debug -m script in pycharm

2. set PYTHONPATH in pycharm when you want to use local package instead of site-package, but the path should be romote path when using remote server.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号