
llama-factory fine-tuning-2 (conception and technologies explanation)
train method
Reward Modeling
PPO training
DPO training
full-parameter
fine-tuning all weights.
partial-parameter
freeze some weights and change some weights, set layers.trainable=True or False to let them to be trainable or not.
LoRA
QLoRA
command parameter
fp16
here are some data types used in NVIDIA GPU, such as fp16, fp32, bf16, tf16, tf32, and INT8.
Most AI floating-point operations use 16-bit 'half' precision (FP16), 32-bit 'single' precision (FP32), and 64-bit 'double' precision (FP64) aimed at professional computations. The default for artificial intelligence training is FP32, which does not have Tensor Core acceleration. NVIDIA's Ampere architecture introduced new support for TF32, enabling AI training to use Tensor Cores by default. Non-tensor operations continue to use the FP32 data path, while TF32 Tensor Cores read FP32 data and use the same range as FP32 but with reduced internal precision, and then produce standard IEEE FP32 output.
Generally, fp32 will take more device memory than fp16.
gradient_accumulation_steps
accumulate several steps' gradient and calculate in a time, which could save the memory.
lr_scheduler_type cosine
learning rate scheduler, with that we can schedule the value of learning rate based on some factors, While we cannot possibly cover the entire variety of learning rate schedulers, we attempt to give a brief overview of popular policies below. Common choices are polynomial decay and piecewise constant schedules. Beyond that, cosine learning rate schedules have been found to work well empirically on some problems.
cosine scheduler
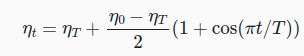
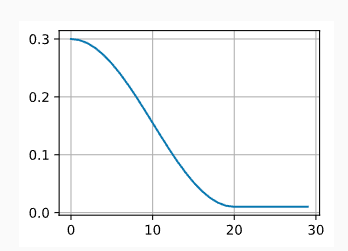
where
look here for more details.
lora_target
The specific options for lora_target can vary depending on the architecture of the model, we usually add the lora weight to transormer-based models, here are the options for it
q_proj Query Projection: targets the query projection in the attention mechanism;
k_proj Key projection: targets the key projection in the attention mechanism;
o_proj Output Projection: targets the output projection in the attention mechanism;
ff Feed-Forward Network Layers: targets the feed-forward network layers within the transformer block;
all All Layers: applies LoRA to all applicable layers or components in the model.
overwrite_cache
if overwrites local cache, no impact on model training.
stage
training method used, here are options
stf means supervised fine-tuning
pt means pre-training
rm reward modeling
ppo PPO training
dpo DPO training

 浙公网安备 33010602011771号
浙公网安备 33010602011771号