llama-factory fine-tuning-1
data preparation
for llama-factory fine-tuning, here is the instruction for custom dataset preparation.
dataset classification
alpaca
stanford_alpaca dataset is a famous example to fine-tuning llama2 to get alpaca model, follow is its structure.
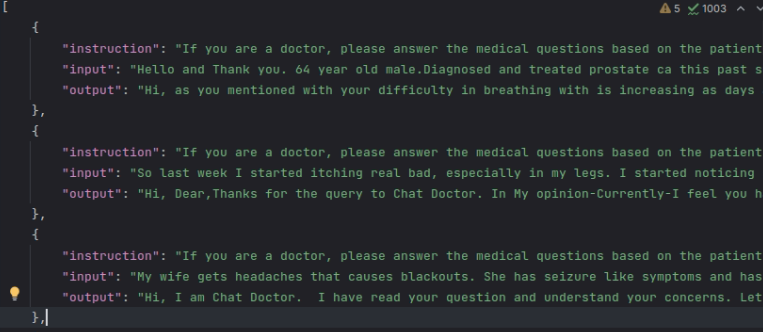
[ { "instruction": "user instruction (required)", "input": "user input (optional)", "output": "model response (required)", "history": [ ["user instruction in the first round (optional)", "model response in the first round (optional)"], ["user instruction in the second round (optional)", "model response in the second round (optional)"] ] } ]
from bellow digraph, you can get how they get alpaca model:

sharegpt
command
CUDA_VISIBLE_DEVICES=3 python src/train_bash.py \ --stage rm \ --model_name_or_path ../llama/models_hf/7B \ --do_train \ --dataset comparison_gpt4_en \ --template default \ --finetuning_type lora \ --lora_target q_proj,v_proj \ --resume_lora_training False \ --checkpoint_dir ./FINE/llama2-7b-medical_single/checkpoint-70000 \ --output_dir ./Reward/medical \ --per_device_train_batch_size 2 \ --gradient_accumulation_steps 4 \ --lr_scheduler_type cosine \ --logging_steps 10 \ --save_steps 1000 \ --learning_rate 1e-6 \ --num_train_epochs 1.0 \ --plot_loss \ --fp16
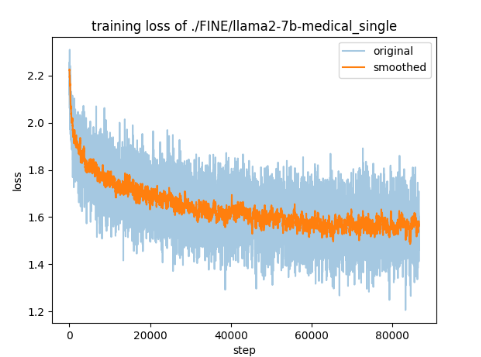
loss digraph
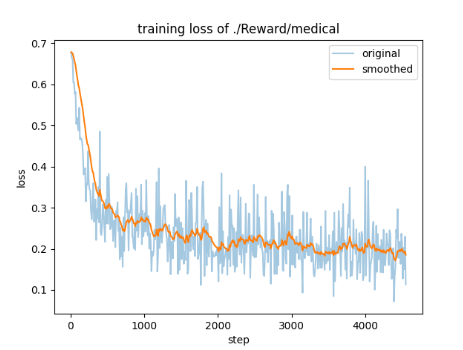
evaluation
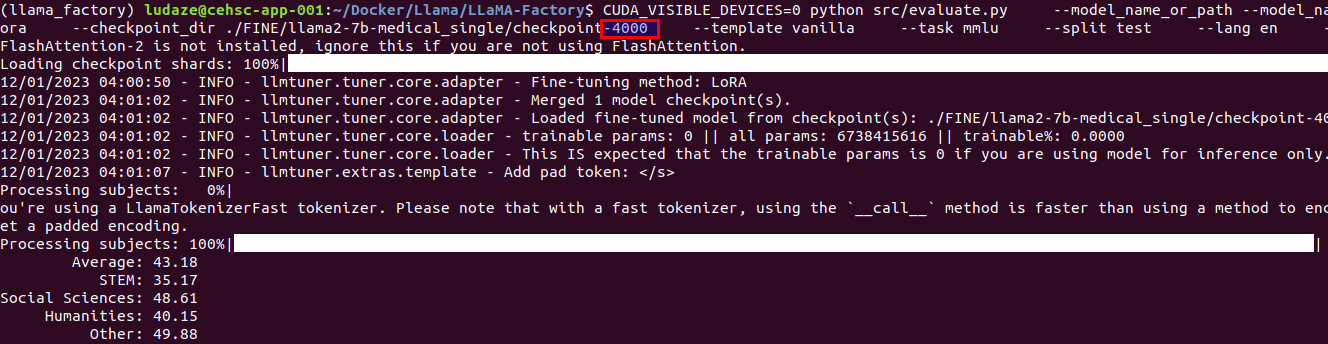
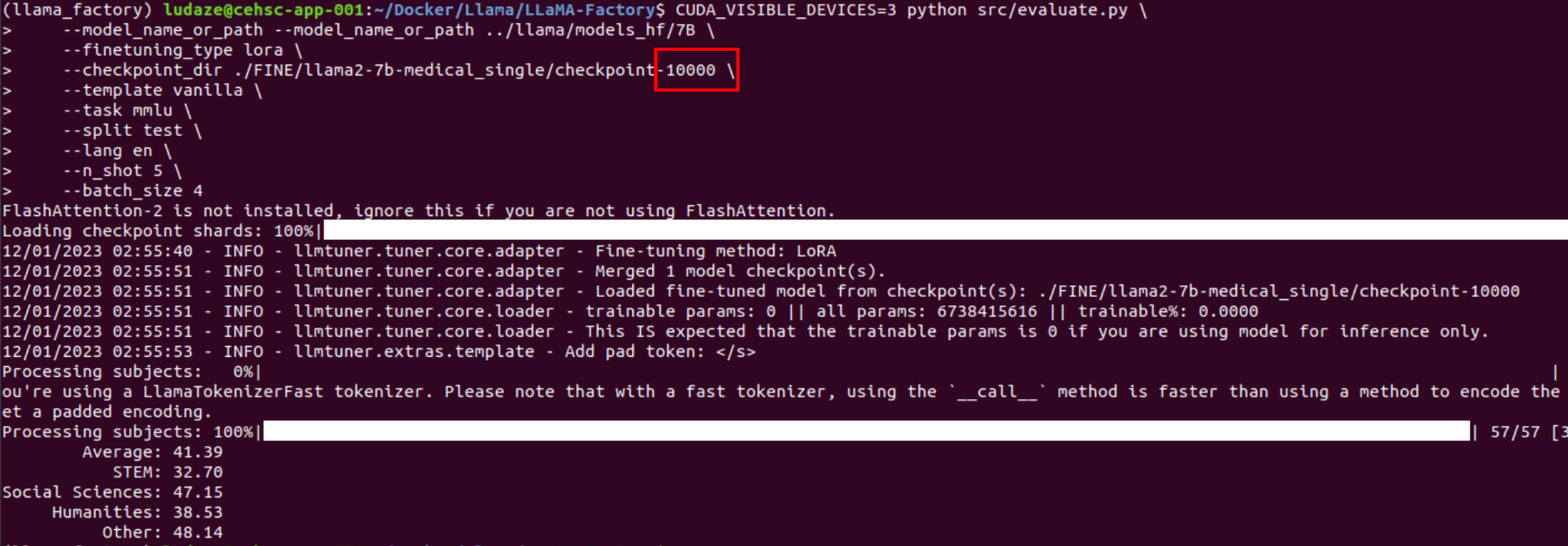
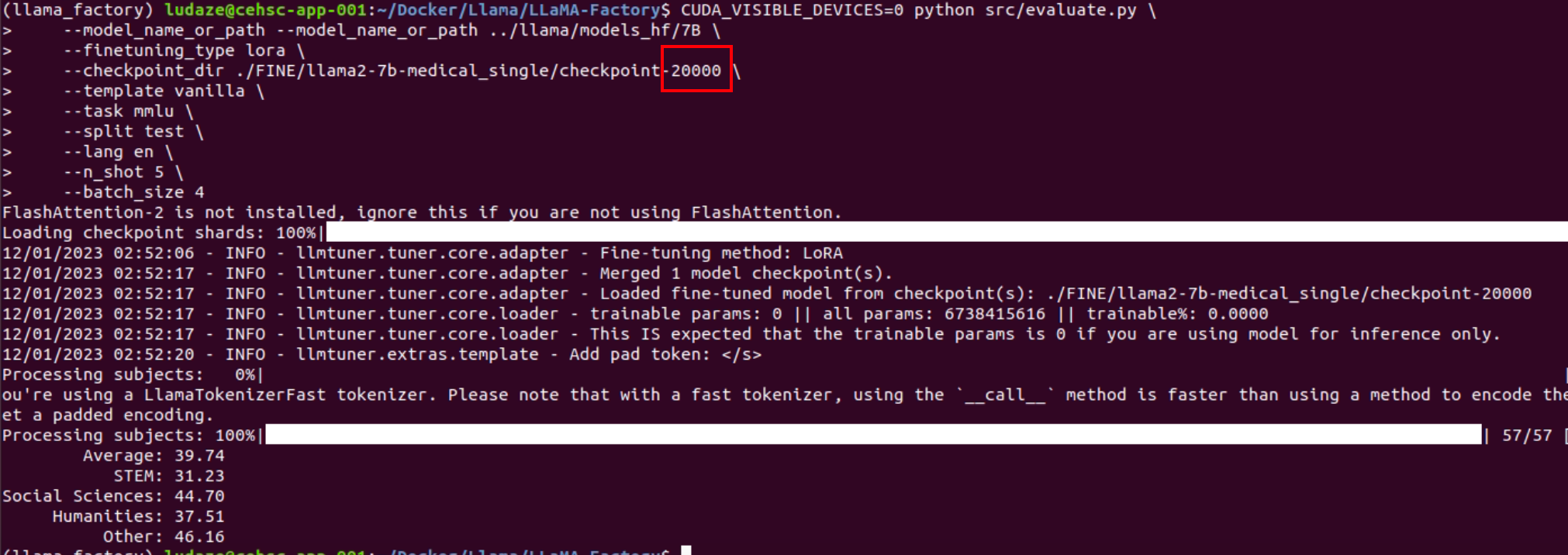
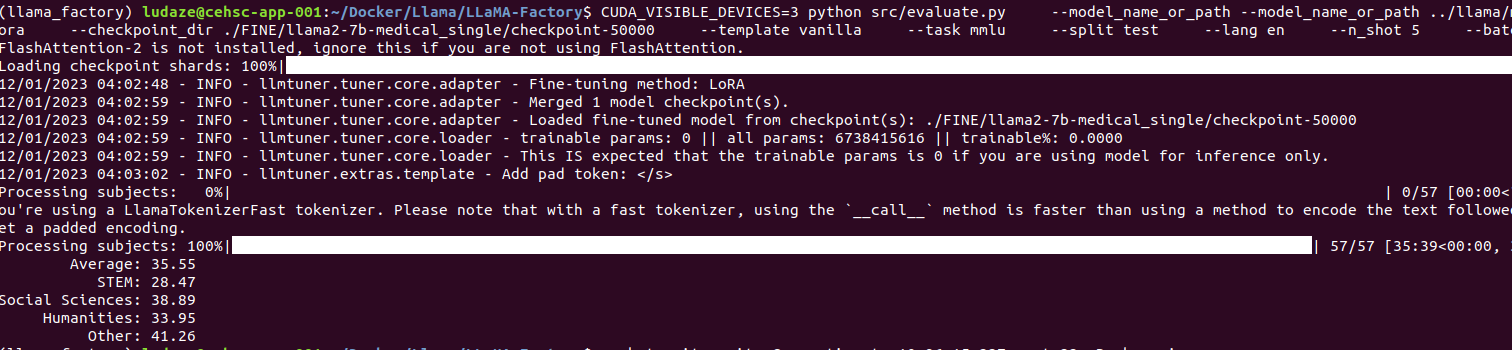
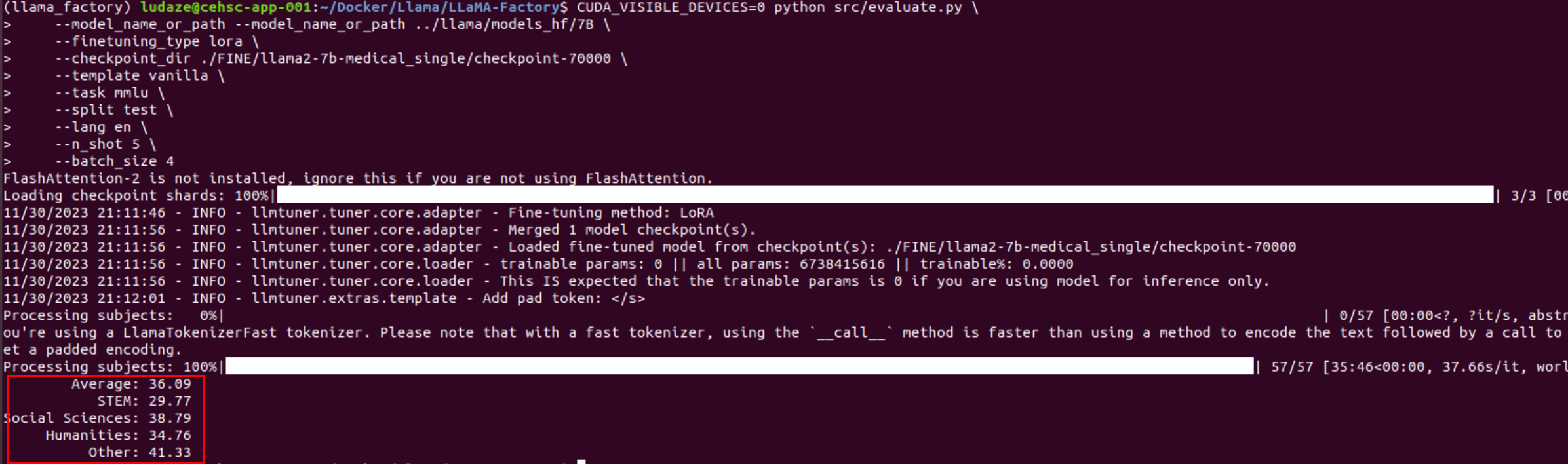
2000 steps
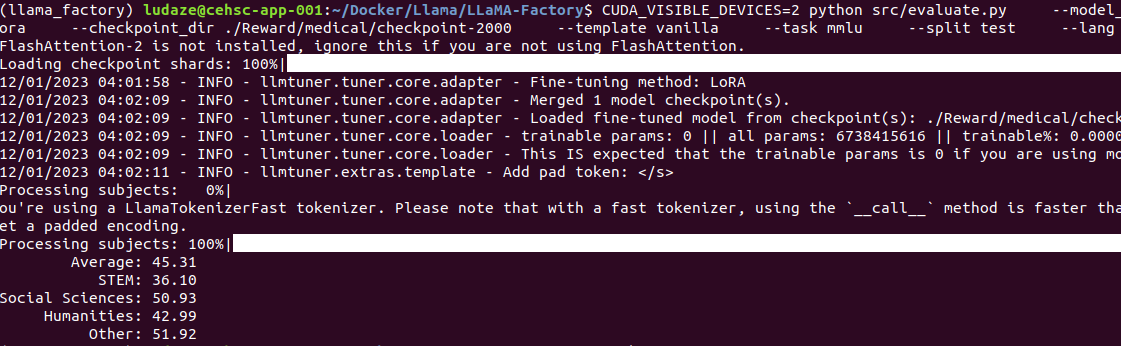
4000 steps
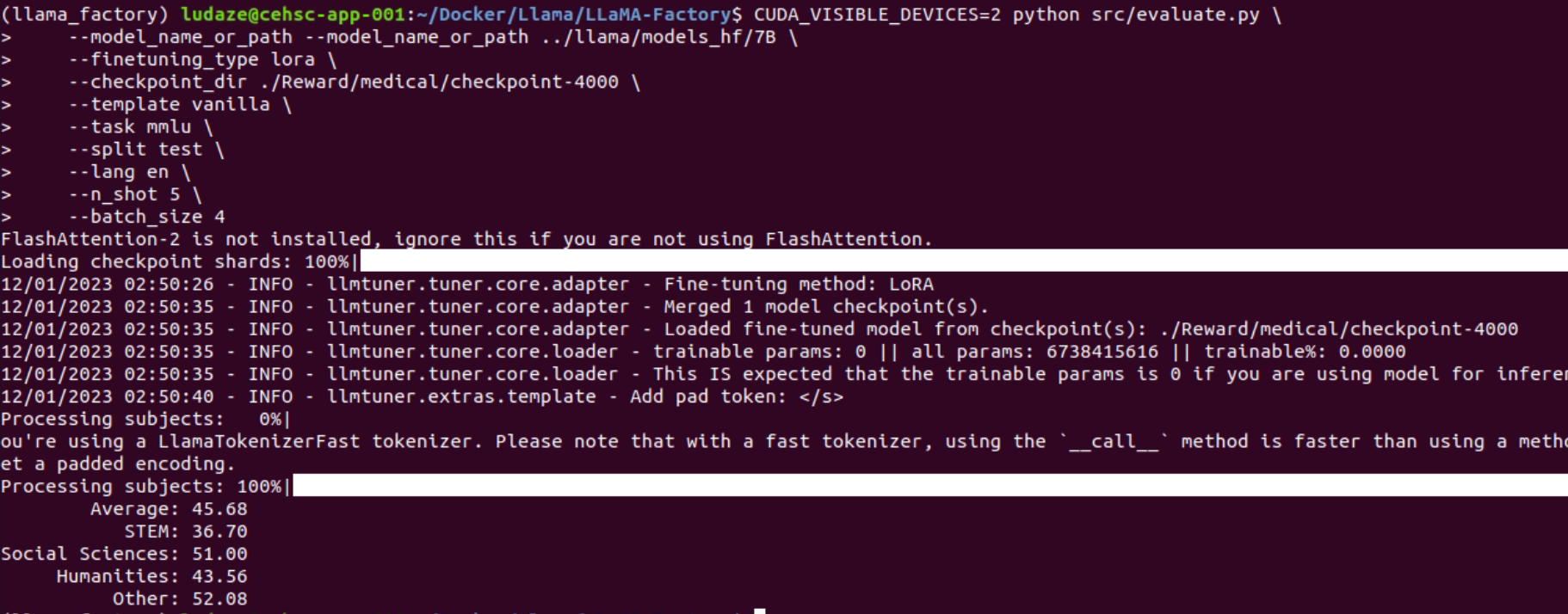
PPO training
command (do not use fp16, otherwise there will be an error: ValueError: Attempting to unscale FP16 gradients)
CUDA_VISIBLE_DEVICES=1 python src/train_bash.py \ --stage ppo \ --model_name_or_path ../llama/models_hf/7B \ --do_train \ --dataset alpaca_medical_en \ --template default \ --finetuning_type lora \ --lora_target q_proj,v_proj \ --resume_lora_training False \ --checkpoint_dir ./FINE/llama2-7b-medical_single/checkpoint-70000 \ --reward_model ./Reward/medical/checkpoint-4000 \ --output_dir ./PPO/medical/medical_gpt4 \ --per_device_train_batch_size 2 \ --gradient_accumulation_steps 4 \ --lr_scheduler_type cosine \ --top_k 0 \ --top_p 0.9 \ --logging_steps 10 \ --save_steps 1000 \ --learning_rate 1e-5 \ --num_train_epochs 1.0 \ --plot_loss

 浙公网安备 33010602011771号
浙公网安备 33010602011771号