USE MMLU datset to test llama2
run llama2
1 llama2 repository: here
dataset
mmlu dataset structure
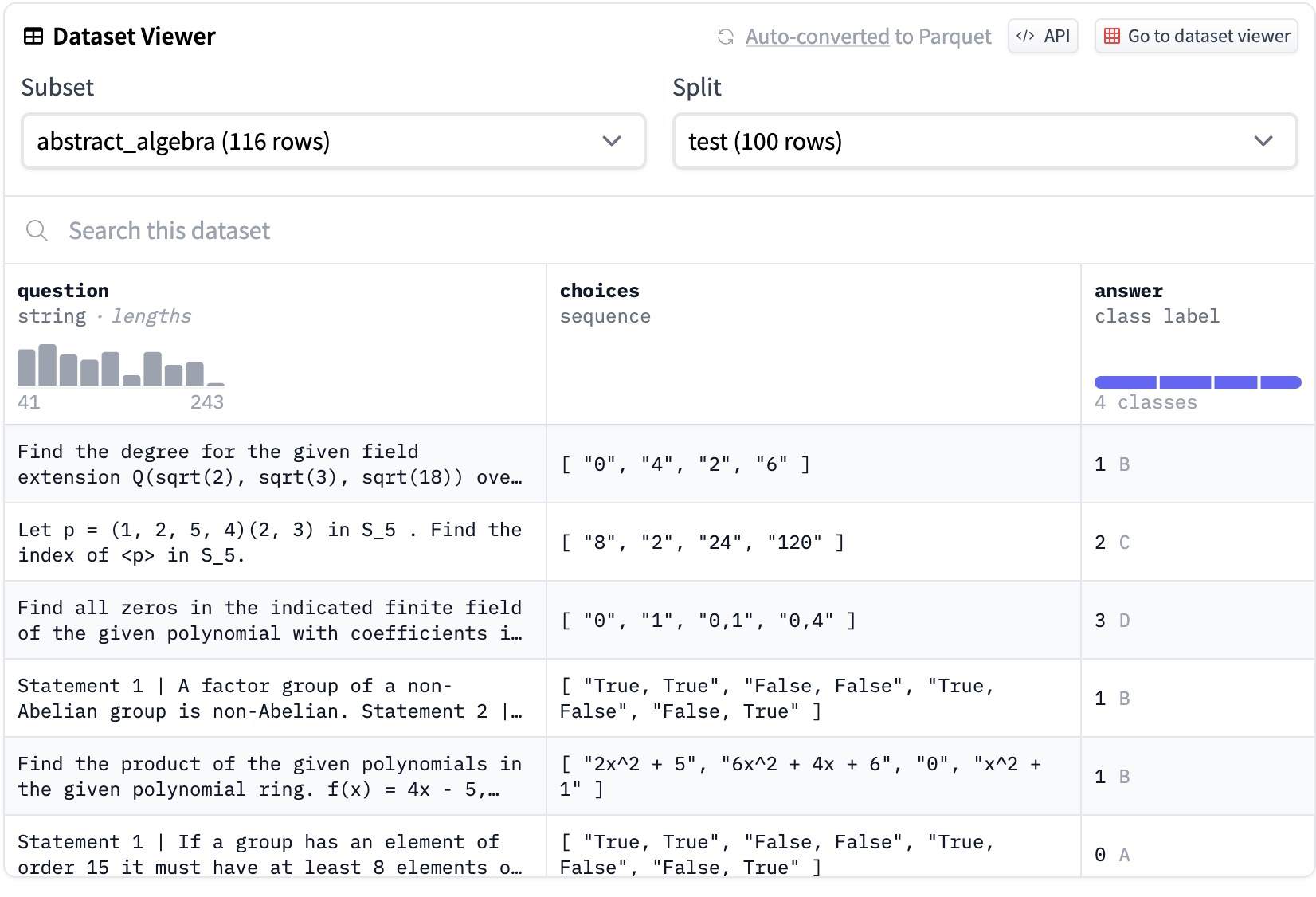
RESULT
command
CUDA_VISIBLE_DEVICES=0 python src/evaluate.py \
--model_name_or_path ../llama/models_hf/7B \
--adapter_name_or_path ./FINE/llama2-7b-chat-alpaca_gpt4_single/checkpoint-20000 \
--template vanilla \
--finetuning_type lora \
--task mmlu \
--split test \
--lang en \
--n_shot 5 \
--batch_size 4
68.9% is the official evaluation result of 70b model
result explanation
STEM (Science, Technology, Engineering, and Mathematics): This category includes questions related to natural sciences, technology, engineering, and mathematics, typically involving quantitative analysis, logical reasoning, and technical knowledge.
Social Sciences: This category covers questions from fields like economics, sociology, psychology, and more, which usually require qualitative analysis of human behavior, social structures, and culture.
Humanities: The humanities category encompasses fields such as history, philosophy, and literature, often requiring analysis and interpretation of cultural works, historical events, or philosophical concepts.
Other: This category likely includes questions that do not fall into the previous classifications, such as arts, sports, general knowledge, etc.
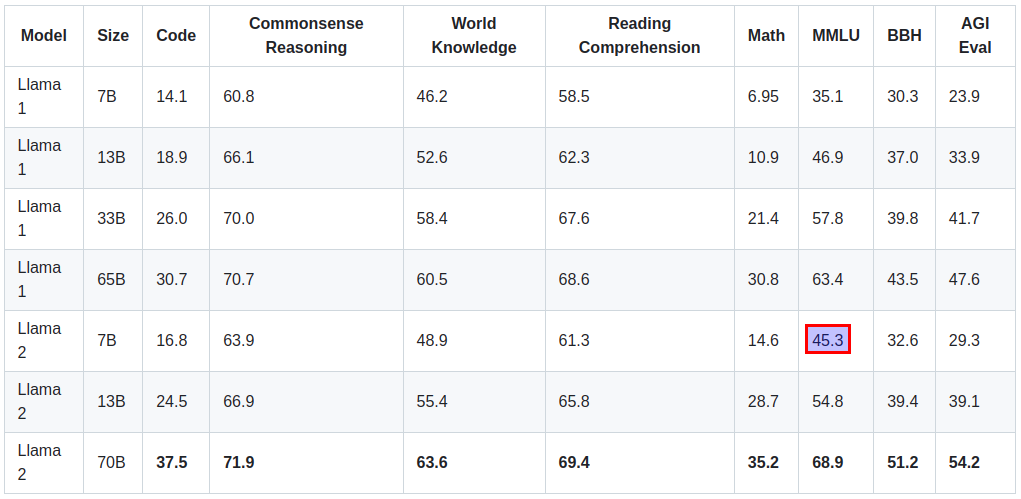
llama official evaluation result
Q&A
1 torchrun: not found in pycharm, but in remote server, the file could work.
import os os.system("torchrun --nproc_per_node 1 example_chat_completion.py --ckpt_dir llama-2-7b-chat --tokenizer_path tokenizer.model --max_seq_len 512 --max_batch_size 6")
2 run llama2 7b-chat out of memory
an A6000(48GB) is not enough, we should assign more cards to it, but before that, we have to split the checkpoint(for llama-2-7b-chat, just one checkpoint) see here to download reshards.py
3 torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
which occur after splitting the checkpoint into 4 nodes.
reference
1 GitHub llama-factory use evaluate.py to evaluate llama2, here

 浙公网安备 33010602011771号
浙公网安备 33010602011771号