作业三
1). 扑克牌手动演练k均值聚类过程:>30张牌,3类
2). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。(加分题)
3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
4). 鸢尾花完整数据做聚类并用散点图显示.
5).想想k均值算法中以用来做什么?
1、

2、
3、代码如下:
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
iris=load_iris()
data=iris.data[:,1]
x=data.reshape(-1,1)
y=KMeans(n_clusters=3)
y.fit(x)
y_pre=y.predict(x)
plt.scatter(x[:,0],x[:,0],c=y_pre,s=50,cmap='rainbow')
plt.show()
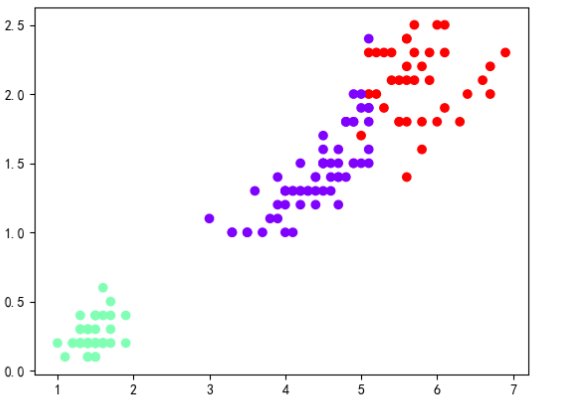
结果如下:

4、代码如下:
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
iris=load_iris()
X_iris=iris.data
model=KMeans(n_clusters=3)
model.fit(X_iris)
Y_iris=model.predict(X_iris)
plt.rcParams['font.sans-serif']=['SimHei']
plt.scatter(X_iris[:,2],X_iris[:,3],c=Y_iris,cmap="rainbow")
plt.show()
结果如下:
5、
对于大数据集。K均值聚类算法相对是可伸缩和高效的,他的计算复杂度是O(NKt)接近与线性,其中N是数据对象的数目,K是聚类的簇数,t是迭代的轮数。尽管算法经常以局部最优结束,但一般情况下达到局部最优已经可以满足聚类的需求。用来做聚类分析,人工智能。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号