zpar使用方法之Chinese Word Segmentation
第一步在这里:
http://people.sutd.edu.sg/~yue_zhang/doc/doc/qs.html
你可以找到这句话,

所以在命令行中分别敲入
make zpar
make zpar.zh(中文)
make zpar.en(英文)
这时会生成一个dist文件夹 在里面你可以找到(如果做了英文的 还会有一个zpar.en)

之后进http://people.sutd.edu.sg/~yue_zhang/doc/doc/segmentor.html
这里做的是分词
第二步如何编译:

如何编译:敲入make segmentor
你将在dist目录下看到生成一个文件夹segmentor
在这里会有
这两个文件 train是用来训练模型的 segmentor是用来用训练好的模型做分词的
第三步那么如何训练模型呢?
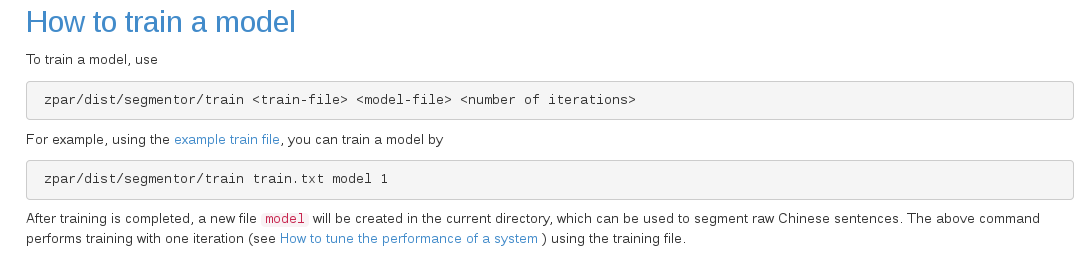
由于train 和segmentor是两个可执行文件 所以要进入到所生成他们的目录下给定好输入文本的位置 生成模型的位置以及名称 和迭代次数

这里model就是所生成模型的名称,当然也可以起别的名字,这不是一个关键字。后面的1就是迭代次数
这里的train.txt好像要utf-8编码。。。反正我直接从 下载的文本。
下载的文本。
训练结束你可以找到

例子中没给路径就应该是在zpar底下
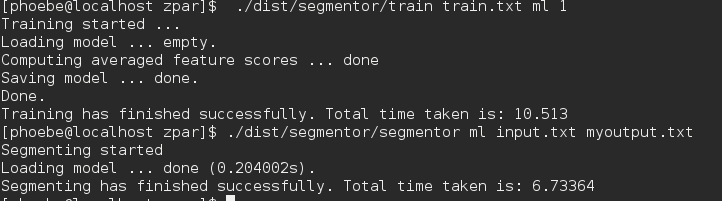
第四步如何分词:

敲入:

这里的model就是你训练出来的模型,如果你不是放在zpar下记得写出路径
太罗嗦了 就是记得把他们的路径写对
输入的文本也可以从an example input下载
这时你就可以找到你的output.txt了
应该是分好词的
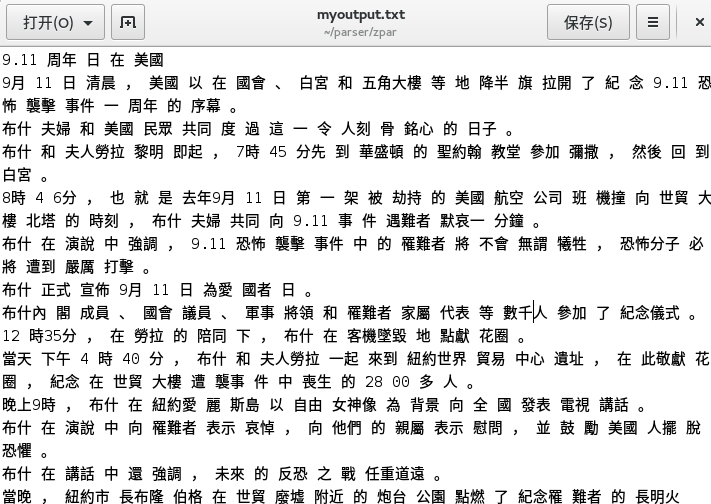
第五步评估;
记得去下载evaluate.py这个脚本还有reference.txt
然后执行这个脚本
然后你能看到准确率 召回率 和F-score
F-score其实很简单
两个最常见的衡量指标是“准确率(precision)”(你给出的结果有多少是正确的)和“召回率(recall)”(正确的结果有多少被你给出了)
这
两个通常是此消彼长的(trade
off),很难兼得。很多时候用参数来控制,通过修改参数则能得出一个准确率和召回率的曲线(ROC),这条曲线与x和y轴围成的面积就是AUC(ROC
Area)。AUC可以综合衡量一个预测模型的好坏,这一个指标综合了precision和recall两个指标。
但AUC计算很麻烦,有人用简单的F-score来代替。F-score计算方法很简单:
F-score=(2*precision*recall)/(precision+recall)
即使不是算数平均,也不是几何平均。可以理解为几何平均的平方除以算术平均。
第六步写脚本
终于到了最后一步了。。。你去这个目录下看test.sh你会发现什么???自己去看吧。要是运行不出来这个脚本就发动你的智慧稍微改动一下。相信你能运行出来的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号