爬虫(龙哥纯手撸博客)
---恢复内容开始---
jupyter 环境配置
jupyter基于浏览器的可视化工具
(不会安装就 百度 什么都有)
官网下载 https://jupyter.org/install
可以使用 conda 或者 pip
conda 安装
conda install -c conda-forge jupyterlabpip 安装
pip install jupyterlab
安装成功之后 可以使用 jupyter 安装 notebook
jupyter notebook
https://www.anaconda.com/ anaconda 下载地址
1 右上角 new 创建 python3 后 文件后缀 ipynb
2 在编辑 菜单中 可以设置 指定的 cell的 模式 可以是 code 和 Markdown 等待
1 markdown中 可以使用 html 样式 来 控制
2 code 模式中 不分上下之分 下面 定义的变量 上面也可以 获取 (可以写多行) 也叫源文件缓存
jupyter 快捷键 :
1 插入 cell : a b (选中cell 后按 a 就可以 向上 插入 b 是 向下插入 ) 提示 : 选中是蓝色的 2 删除 cell:x 3 执行 : shift + enter 4 tab: 自动补全 5 模式的切换 : m -> markdown y -> code 6 shift+tab : 打开 帮助文档
爬虫概念
什么是爬虫? :爬虫: 通过 编写程序 模拟 浏览器上网 让其去互联网上爬取数据的过程 (浏览器就是 一个 天然的爬虫)
爬虫的分类:
1 .通用爬虫: 全局页面的爬取(增张页面)
2. 聚焦爬虫 :局部页面的爬取
3.增量式:只爬取 最新的数据
反爬机制:某某网站不想让你爬取的机制
反反爬策略:破解他给你设置的机制呀 爬死他
- robots.txt 协议(第一个反爬机制): 例如 我们 在淘宝网后 输入后缀 robots.txt https://www.taobao.com/robots.txt
防君子 不 防小人
超文本传输协议 : http 和 https 以前的博客有 去找吧!
User-Agent 和 connection
以上了解即可 累了吧?
fiddler抓包工具
工具下载 https://www.telerik.com/fiddler
傻瓜式安装 一直点
配置
在 tools 中 options 点击 https 装一个 fiddle证书 全部选√ 重启就可以了
打开工具 当你 在浏览器发起请求时会自动捕获到数据 选择 右边的 inspector (检查员)
inspector 分上下两个 页面 上面是 请求 的 主要就用的到 webfrom 和 raw(请求头)
下面是 响应 用的到的是 raw 和 json (返回的不是字典的时候是 html)
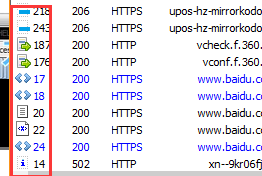
< > 开头的是 get 请求 绿色箭头 的是 post 请求
requests 模块
指定 url 指定请求方式 获取响应数据 保存响应数据
四个案例
sogo搜索

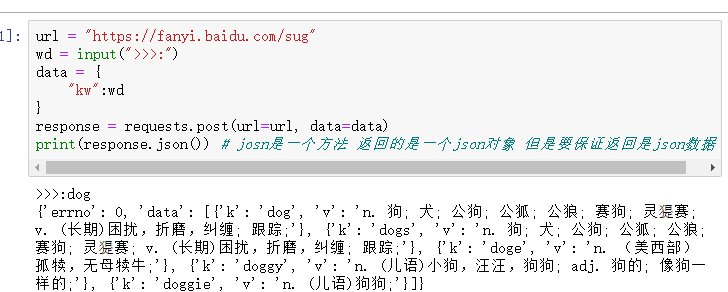
百度翻译
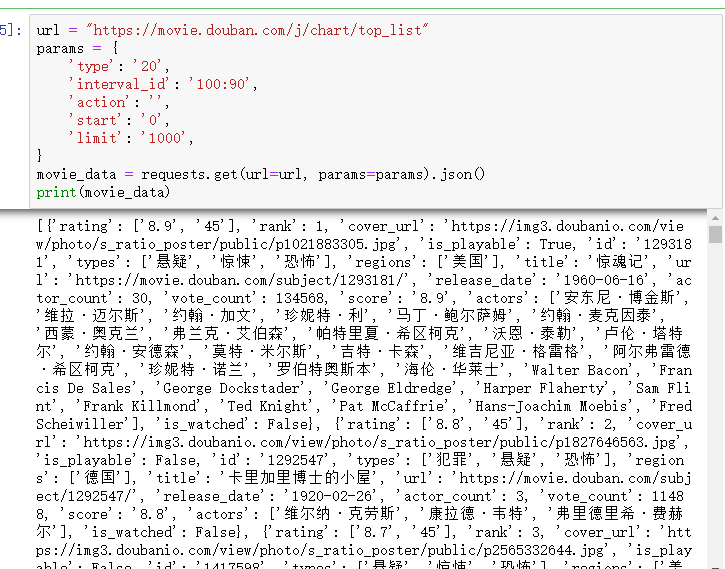
豆瓣电影
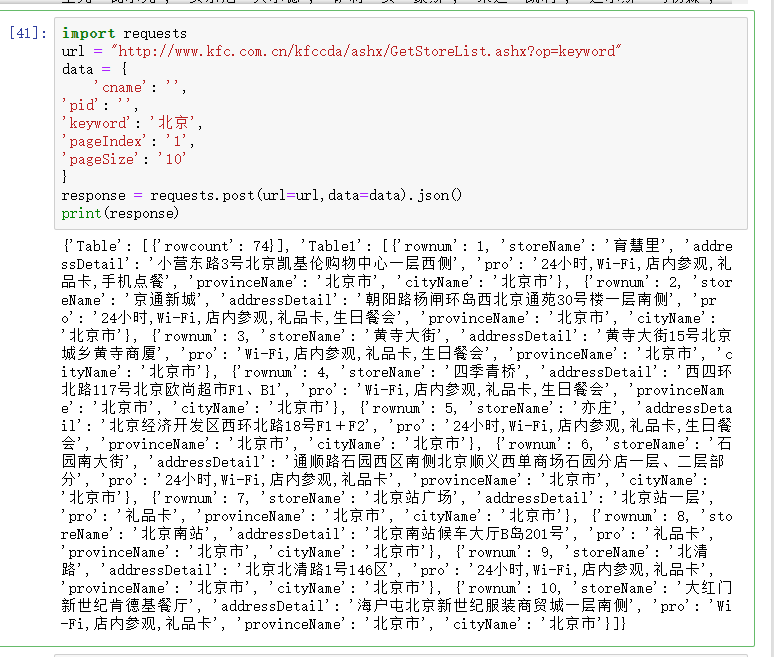
kfc
http://125.35.6.84:81/xk/ 爬取详细信息
---恢复内容结束---

 浙公网安备 33010602011771号
浙公网安备 33010602011771号