
优雅的分块
优雅的分块
最近做了一大堆分块题 / 口胡了一大堆分块题,有感而发,真是美妙的算法。
分块究其根本实际上是一个调和的算法,并且在很多方面都有应用。
其中,我们抛开数论分块和根号分治不谈,找一找分块思想在数据结构上和优化问题上的应用。
首先,分块基于调和的思想,调和在百度百科上的定义是:调解使和好,我觉得和分块的定义很像就拿过来用了。
先引出一个简单的问题:
给一个 1 到 \(n\) 的序列,有 \(m\)次操作,区间加或者区间求和,要求做到 \(O(n^{1.5})\) 一下。
这个问题想必大家都非常熟悉,有各种 \(O(nlogn)\) 到 \(O(n^{1.5})\) 的数据结构做法。我们先抛开这些做法不谈,考虑最基础的暴力:
如果我们使用简单的循环枚举每次修改或回答:
-
对于修改,我们每次最多有 \(O(n)\) 的位置需要修改,对于每个位置上的修改我们只需 \(O(1)\) 维护它的值。每次修改总的时间复杂度是 \(O(n)\)。
-
对于查询我们用同样的方式分析,我们最多要将 \(O(n)\) 个位置相加求和,每次维护的时间复杂度是 \(O(1)\) ,总的时间复杂度是 \(O(n)\)。
这个算法并不像我们想的那么劣,毕竟它做单次修改或维护的时间复杂度都是 \(O(1)\) 的。只是我们维护的数量太多了,导致时间超限。
我们对这个算法抽丝剥茧,我们实际上在维护 \(O(n)\) 个变量。这个变量可以看作内层的数据结构,它能快速的修改/查询,只是我们需要维护的变量太多了,导致时间超限。
为了方便下文的叙述,请允许我为这种分析方法下一个定义:
我们将一道数据结构题分为两个部分:修改和查询。
对于修改操作,我们定义总的时间复杂度叫做外层修改时间复杂度,需要维护的内层数据结构的个数叫做修改量级,内层数据结构修改的时间复杂度叫做内层修改时间复杂度。
同样的,对于查询操作,我们定义总的时间复杂度叫做外层查询时间复杂度,需要维护的内层数据结构的个数叫做查询量级,内层数据结构查询的时间复杂度叫做内层查询时间复杂度。
有时,一些题目对答案的维护较为复杂,所以我们可以定义维护时间复杂度为维护的时间复杂度。
我们用我自己口胡出来的方式描述一下上面的算法:
-
我们需要维护的信息是加法,维护时间复杂度为 \(O(1)\).
-
内层我们维护的数据结构实际上是一个变量,内层修改/查询时间复杂度都是 \(O(1)\)。一次查询/修改操作最多涉及 \(O(n)\) 个变量,所以修改/查询量级为 \(O(n)\),因此外层修改/查询时间复杂度,为两者相乘,即 \(O(n)\)。
我们发现时间复杂度的瓶颈在于修改/查询量级。
我们考虑另一种以维护思想为主的朴素算法,在上述算法中,内层数据结构每次只能维护一个信息,我们将它扩展一下,让一个变量维护序列上一个连续的区间,维护这个区间上的信息。
我们设维护区间长度为 \(len\),量级为 \(O(len)\),我们给它命名为块/大块,你可以理解为大块就是一段区间,我们同时命名块内部的变量为散块/小块。
每次修改/查询只需将大块的信息相加,在加上小块的信息即可。
Q:如何让内层修改时间复杂度变为 \(O(1)\) ?
A:我们类似线段树给区间打上标记,需要用到散块信息时就暴力将散块重构即可。
我们每次做多让查询/修改区间的左右两端的块重构,这部分的量级是 \(O(len)\) 的。
我们发现每次操作的修改/查询量级变为 \(O(\frac{n}{len}+len)\)。
我们对维护的算法抽丝剥茧,我们发现这个算法每次都有一部分通过大块的维护将修改量级优化到了 \(O(\frac{n}{len})\),同时我们不能无脑将块长变大,因为对于每次操作,我们最多会将两个块遍历一遍用于重构。
我们称大块的部分叫做维护部分,将重构部分叫做暴力部分。
通常情况下,维护部分的时间复杂度减小会导致暴力部分的时间复杂度增大,一个形象的比喻是维护部分和暴力部分在”掰手腕“。
作为和平主义者,我们想要画出最大同心圆,找出最大公约数,利用均值不等式可以得到当 \(len=n^{0.5}\) 时,时间复杂度最优,外层修改/查询时间复杂度为 \(O(n^{0.5})\)。
利用均值不等式,我们同时让两个部分相对优秀一点,总的时间复杂度也变为 \(O(n^{1.5})\)。
这个就是序列分块,这个分块的思想也就是我说的调和。
这种思想通常有两种应用,第一种是我们只存一个一个块,然后每次运算都加上,即小块暴力去做,大块每次维护出来,再去处理每次查找,代表有:序列分块、值域分块、询问分块等等。
另一种是我们对于小于 \(\sqrt n\) 的部分暴力的做,大于等于 \(\sqrt n\) 部分我们预处理出来直接查询,代表有根号分治。
我们先讨论第一种应用,第二种应用不在本 blog 的讨论范围内,其中第一种应用可以处理一类数据结构题,也有人称它为块状数组。
分块思想在数据结构上的应用
遇到一道数据结构题时,题目通常有查询或修改操作,我们考虑下面三种设问方式:
-
只有查询操作。
-
只有修改操作,最后进行一次查询。
-
既有查询操作,又有修改操作。
我们一个一个来看。如果只有查询操作。我们考虑莫队的思想,即如何从一个询问通过移动左右端点转换为另一个端点。
莫队
- 先来看一道题:P4688 [Ynoi2016] 掉进兔子洞(插入/删除集合时间复杂度都能做到 \(O(1)\) )。
题目只有查询操作,每次给三个区间,求三个区间中都出现的数的个数。
由于没有修改操作,我们可以先离散化,考虑如可维护这个信息。
我们使用 std::bitset 对一个区间中出现位置进行标记。将三个 std::bitset 交起来就能得到重复数的个数,在用全集减去这个 std::bitset 就能得到一个询问的答案。
我们发现,使用 std::bitset 时,每次插入/删除都能做到 \(O(1)\),于是我们得到了一个 \(O(n^{1,5})\)。
但是这是 Ynoi ,需要一点点的 trick 才能通过这道题。
我们发现 \(O(n)\) 个 std::bitset 我们存不下。于是我们可以分批次处理查询,这样我们每次就只用开一部分的 std::bitset ,从 \(O(\frac{n^2}{w})\) 优化为 \(O(\frac{nM}{w})\),取 \(M=2e4\) 时足以通过这道题。
- 再看一道:CF765E Souvenirs (插入/删除集合时间复杂度只有一个能做到 \(O(1)\) )。
给一个序列 \(a\),每次查询 \([l,r]\) 内 \(|a_i-a_j|_{min},i,j\in[l,r]\) 且 \(i\not =j\)。
我们发现这个条件好眼熟,想想我们之前做过的题目AcWing 136. 邻值查找,这道题在蓝书上出现过。
让我们简单回忆一下做法,我们发现,对于每个点,它只可能和它的前驱/后继更新答案,所以我们只需找到一种快速查询前驱后继的数据结构就可以维护了。
这种事情平衡树很擅长,我们用一个 std::set,来每次找前驱和后继就行了。
同时在蓝书中,lyd曾介绍了一种使用链表的做法,具体做法是,我们先将数组排序,在建好链表,每次查完一个删除一个,链表插入/查前驱后继的时间复杂度为\(O(1)\),非常优秀。
我们迁移到这道题上,由于链表每次只能插入和删除一个元素,又有若干个区间查询,并且不带删,还不要求强制在线,自然而然的想到莫队(快把莫队写到你脸上了)。
我们发现莫队移动端点是\(O(N\sqrt N)\)的,不太好用 std::set 维护,于是我们考虑使用链表。
同时,我们又发现对于每次加入操作,我们能很轻松的维护最大值,但是对于一个已有的链表,我们却无法直接快速的找到他的最大值。
对于这种插入好做的数据结构,我们可以联想到莫队的变种回滚莫队(不删除莫队)。
我们将每个询问分成两个部分,第一部分是左端点所在的块,第二部分是询问的另一半。
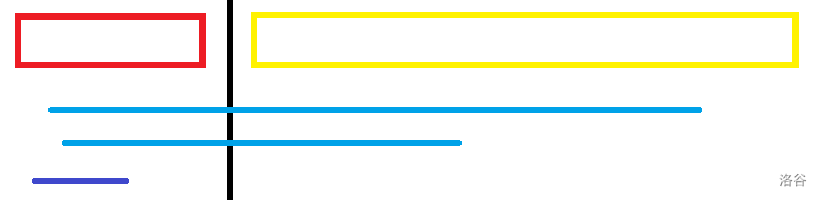
显然答案为左半段的贡献(红色),右半段的贡献(黄色),左半段到右半段的贡献三者中的最小值。
对于深蓝色的询问,我们暴力计算,对于浅蓝色的询问,我们考虑维护。
-
对于左半段的贡献,我们每次暴力跑就行了因为总长不超过\(O(\sqrt N)\)。
-
对于右边的贡献,我们将左端点相同的询问放在一起考虑,将这些询问按照右端点排序后离线一起做即可,跑一次\(O(N)\)。由于这是莫队,我们只会跑\(O(\sqrt N)\)次,所以总的时间复杂度为\(O(N\sqrt N)\)。
-
对于左半段到右半段的贡献,我们在跑贡献的时候维护重构维护就行了。
我们发现对于操作一和操作三,我们可以放在一起做,这样总的时间复杂度为\(O(N\sqrt N)\)。
这种拆贡献的思路很妙,有点像大分块题统计答案一样,考虑块对块的贡献,块对散块的贡献,散块对散块的贡献。
像这样合并两个区间的题目,如果我们发现要重构其中的一个区间,不妨试试回滚莫队。
其实将链表换成0/1 trie也可以,它们两个都是插入好做删除难做。
再来:P5047 [Ynoi2019 模拟赛] Yuno loves sqrt technology II (插入/删除集合时间复杂度无法在线 \(O(1)\),但离线可以)。
给你一个长为 \(n\) 的序列 \(a\),\(m\) 次询问,每次查询一个区间的逆序对数。
继续考虑莫队,每次扩展端点时对就是查询逆序对数,并进行一次修改。
查询逆序对通常有三种解决方式,一种是归并排序(不支持修改)、树状数组(查询和询问的时间复杂度为 \(O(log n)\) )、值域分块(查询 \(O(n^{0.5})\),修改 \(O(1)\) 或查询 \(O(1)\) ,修改 \(O(n^{0.5})\) )。
这里直接用莫队 + 树状数组的时间复杂度为 \(O(n^{1.5}logn)\),无法通过。
换一个角度思考问题,莫队移动端点时查询量级为 \(O(n^{1.5})\),但是实际上我们修改量级最少可以做到 \(O(n)\) (每个元素只加入/删除一次)。
我们考虑将它们的贡献离线下来一起计算,通过扫描线一起计算。具体一点就是将端点从 \(x\) 移动到 \(y\) 保存下来,将 \(y\) 以前的元素先加在集合中,然后累加贡献,再减去重复的部分。
重复的部分就是移动端点时的总对数减去逆序对数。
按照向左和向右移动将询问分为两类,顺序扫描分别计算贡献即可。
大分块
这种只查询不修改的分块题都比较套路。这类题目需要考虑两个维度对答案的贡献,即考虑散块对答案的贡献和整块对答案的贡献,将必要的东西先预处理出来再去应对每次询问。
以一道题目为例:P5048 [Ynoi2019 模拟赛] Yuno loves sqrt technology III (强化版:P4168 [Violet] 蒲公英)
给你一个长为 \(n\) 的序列 \(a\),\(m\) 次询问,每次查询一个区间的众数的出现次数,强制在线。
一个小 trick:设每次查询的区间为 \([l,r]\),忽略 \(l,r\) 在同一块内的编号,块的编号 \([p,q]\),众数只会出现在 \([p+1,q-1]\) 中或是旁边的散块中。
我们可以通过预处理求出 \([p+1,q-1]\) 的块的众数,这样我们完成了对大块的维护。
考虑如何维护散块,散块只有 \(O(n^{0.5})\),我们抽象一下问题,发现我们需要 \(O(1)\) 查询 \([l,r]\) 内的同种元素个数。
一个直接的想法时将同种元素的位置离线下来,然后二分去找,这样我们的维护时间复杂度就变为 \(O(log n)\) ,无法通过。
我们发现,答案最多只会变化 \(O(n^{0.5})\) 次,这是一个好性质,当答案变大时,它就再也不会变小,然后我们只需每次检查当前元素往后 \(cnt\) 个元素是否还在区间中即可,知道当前元素无法更新再往下,无需二分。
由于答案只会更新 \(O(n^{0.5})\) 次,所以维护时间复杂度变为了均摊 \(O(1)\) 。
强化版需要在维护众数是哪个,在取 max 的同时维护即可。
另一道题目:P5046 [Ynoi2019 模拟赛] Yuno loves sqrt technology I
给你一个长为 \(n\) 的排列,\(m\) 次询问,每次查询一个区间的逆序对数,强制在线。
本题强制在线,无法使用二次离线莫队,但本题只是排列,这启发我们从值域的角度思考问题。
同样,逆序对通常有三种求法,一种是归并排序(不支持修改)、树状数组(查询和询问的时间复杂度为 \(O(log n)\) )、值域分块(查询 \(O(n^{0.5})\),修改 \(O(1)\) 或查询 \(O(1)\) ,修改 \(O(n^{0.5})\) )。
只查不修的分块题考虑整块和散块角度,由于逆序对是二元关系,由此我们引申出来三个方面,将它们代数相加就是答案。
-
散块对散块
-
散块对整块
-
整块对整块
一个一个考虑,散块对散块分为两种情况。
-
属于不同块的散块:如果元素有序,我们直接归并排序即可。随后我们发现散块有没有序对答案没影响,先对块内排序,在暴力扫描整个块,只让属于块内的元素进队,再归并排序,总的时间复杂度为 \(O(n^{0.5})\) 。
-
属于相同的块:我们发现它只可能是原块的一段前缀或后缀,一共只有 \(O(n^{0.5})\) 种情况,可以直接预处理出来,顺序扫描即可。
再考虑散块对整块的贡献,直接预处理每个块对整个序列的逆序对的前缀和然后差分即可。
最后考虑整块对整块的贡献,可以用上面散块对整块的贡献递推即可。
本质上就是分类讨论 + 预处理大题,只需一通预处理就做完了,相当套路。
扫描线
本质上就是维护二维信息,其中一位通常为序列上。由于这不是根号数据结构,所以不过多涉及,但是我个人觉得它同样优雅,同时又很有代表性,所以来一道例题看看。
P8421 [THUPC2022 决赛] rsraogps (强化版:P9335 [Ynoi2001] 雪に咲く花)
定义 \(w(l,r)\) 为 \(a(l)\) 到 \(a(r)\) 按位与的值、\(b(l)\) 到 \(b(r)\) 按位或的值、\(c(l)\) 到 \(c(r)\) 的最大公因数三者之积,\(m\) 次询问,每次给一个区间 \([l,r]\) ,求 \(l\le l'\le r' \le r\) 的 \(w(l',r')\) 之和。
发现区间套区间,一眼扫描线。将整个问题抽象成一个二维平面,一个区间 \([l,r]\) 对应点 \((l,r)\) ,查询相当于查询一个矩阵的和,左下角为 \((l,l)\) ,右上角为 \(O(r,r)\) 。
我们对 \(r\) 扫描,记 \(s(i)\) 为 \([1,i]\) 的贡献,然后转为前缀和差分,答案为 \(s(r)-s(l-1)\) 。
观察题目性质,当有一个新的元素插入集合时,按位与、按位或、最大公因数只会发生 \((logV)\) 次变化,我们只需维护发生变化的位置,对于每个询问暴力往前跳计算贡献即可。
如果没发生变化,就顺延上一位的贡献。
总的时间复杂度为 \(O(nlogV)\),主要是函数的变化只有 \(O(logV)\) 次比较难想。
对于第二第三种设问方式,都是既有查询操作又有修改操作,比较综合。
由于一下的题目大量涉及 Ynoi ,所以先介绍一下分块的常见优化。
- 割块优化:
如果我们发现在一道分块题中不涉及块对块且带修改的情况,我们可以将操作离线下来,一个块一个块的计算贡献,最后累加。
通俗得来说,就是将区间割成一个一个块,在按照块统一处理,这样也要求不存在块与块之间的联动操作。
这样空间复杂度就可以优化一个 \(O(\sqrt n)\) 。
举一个例子:用分块实现 P3870 [TJOI2009] 开关。我们发现它的块与块之间是没有相互关联的,我们可以将一个个块视为一个个子问题,子问题是独立的。
对于每种子问题,有两种修改/查询方式,维护和暴力,这里不多赘述。
贴一下代码方便大家理解:
void change(int L,int R){
int p=pos[L],q=pos[R];
if(B.id<p||B.id>q)return;
if(p==q){
B.change(L,R);
return;
}
if(B.id==p)B.change(L,B.R);
else if(B.id==q)B.change(B.L,R);
else B.rev^=1;
}
int ask(int L,int R){
int p=pos[L],q=pos[R];
if(B.id<p||B.id>q)return 0;
if(p==q){
return B.ask(L,R);
}
if(B.id==p)return B.ask(L,B.R);
else if(B.id==q)return B.ask(B.L,R);
else{
if(B.rev)return (B.R-B.L+1)-B.sum;
else return B.sum;
}
}
- 块长优化:
有时我们用正常的块长无法通过一道题目,我们要根据维护部分和暴力部分的比重来调整块长,经常要手动二分块长。
有时每个块的块长不一定要等长,我们可以像倍增一样维护 \([2^k,2^{k+1})\) 的区间,这个东西通常出现在值域分块上,也被叫做倍增分块。
同时,由于维护部分和暴力部分的不协调,我们也可以使用四毛子算法,将块长变为 \(O(log n)\) ,同样不失为一种做法。
- 各种卡常/剪枝技巧和十足的耐心。(这不用多说了吧)
来看看这道题:CF896E Welcome home, Chtholly (加强版:P4117 [Ynoi2018] 五彩斑斓的世界)。
给定一个序列 \(a\) ,\(1\le a(i),x \le 1e5\),\(m\) 次操作:
-
修改:将 \([l,r]\) 内大于 \(x\) 的元素减去 \(x\) 。
-
查询:询问 \([l,r]\) 内 \(a(i)=x\) 的元素个数。
这个值域只有 \(O(n)\) ,考虑从值域上下手。我们可以大胆猜测一下,大概是外层分块 + 内层值域数据结构。
对于修改操作,我们又两种维护方式:
-
暴力将 \(a(i)>x\) 的元素减去 \(x\) 。
-
将 \(a(i)\le x\) 的元素加上 \(x\) ,再打上区间减的
tag=x。
我们发现一个块内的最大值是在不断减小的,分类讨论:
-
当 \(tag\le Max-tag\) ,即 \(tag \times 2 \le Max\) ,这时我们更改 \([1,tag]\) 的部分,再打标记。
-
当 \(tag>Max-tag\) ,即 \(tag \times 2 > Max\),此时更改 \([tag+1,Max]\) 的部分,本质上就是暴力。
由于 \(tag \ge 1\) ,所以每次要么不修改,要么只有 \(O(n)\) 次修改。
所以我们外层的数据结构已经处理好了,考虑一个内层的数据结构,支持快速将两个集合合并,查询集合中元素个数,显然并查集就能胜任,总的时间复杂度为 \(O(n^{1.5})\) 。
对于加强版,我们使用割块优化将空间复杂度从 \(O(n^{1.5})\) 优化到 \(O(n)\) ,卡卡常足以通过。
总结
分块大概就这样吧,做到新题再回来丰富一下题目,太菜了qwq 。
总之就是先看题目的类型判断题型,然后思考题目维护的性质。
优先想好维护时间复杂度,这个东西通常是定值,然后外层线段树或者是分块(这里的题大部分都是分块)。
然后考虑外层数据结构的修改/查询量级,按照题目所给的时间限制选取合适的内层数据结构,可以从值域/序列的角度思考思考问题。
如果题目只有查询,可以考虑莫队,再按照题目的维护时间复杂度判断加入/删除的时间复杂度,使用普通莫队/回滚莫队/二次离线莫队进行维护。(通常要求 \(O(1)\) )。
分块题总是越做越有感觉的,本质上是对信息维护的考察,内外层的数据结构需要多见。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号