

MongoDB的聚合命令
聚合aggregate:
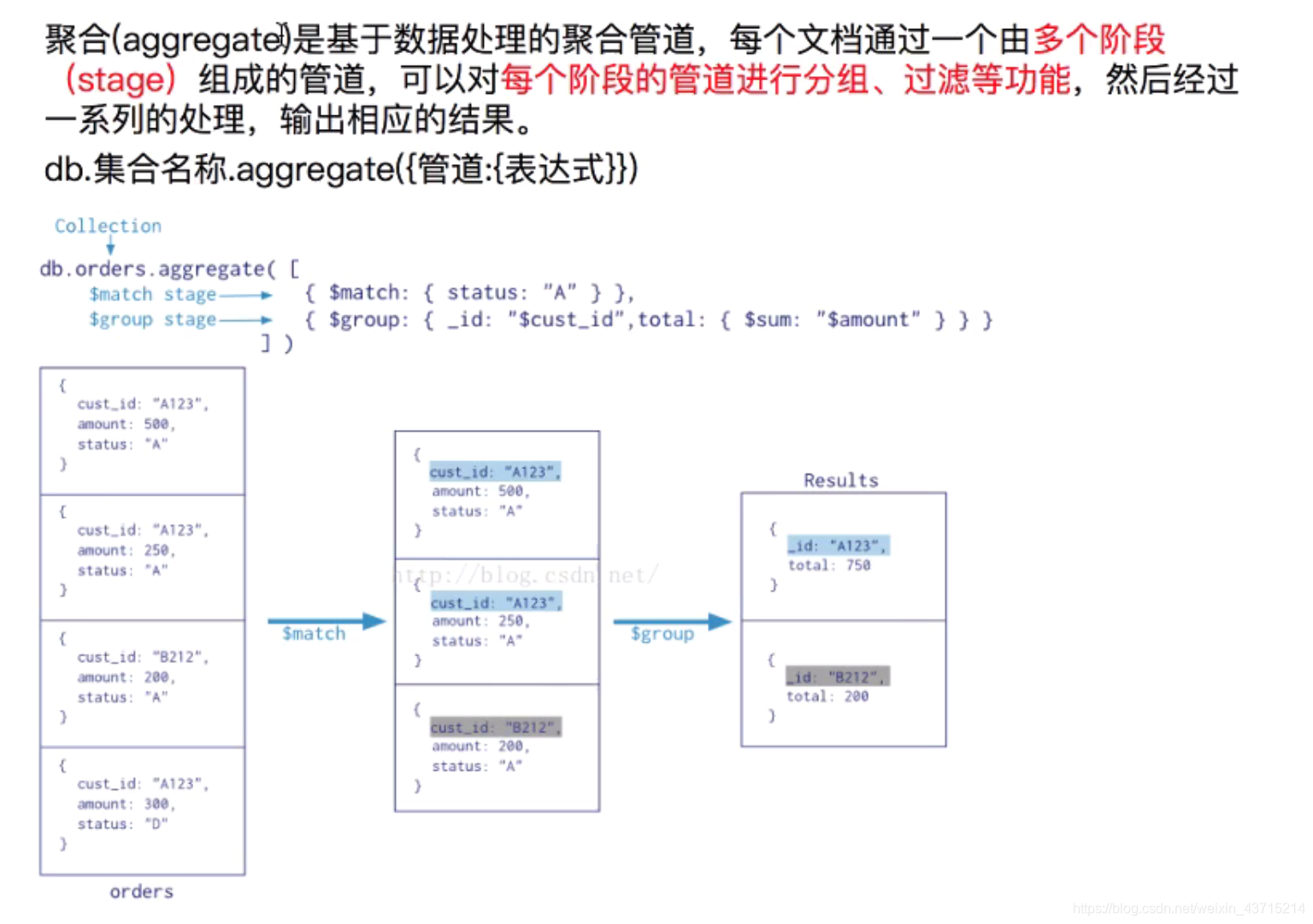
常用的管道命令:
在mongodb中,文档处理完毕的,通过管道进行下次处理。
$group:将集合中的文档分组,可用于统计结果。$match:过滤数据,只输出符合条件的文档。$project:修改文档结构,eg:重命名、增加、删除字段、创建计算结果。$sort:将文档排序后输出。$limit:限制聚合管道返回的文档数。$skip:跳过指定文档数量,并返回余下的文档。$unwind:将数组类型的字段进行拆分。
表达式:

1.$group:
首先准备好数据:
合计7条数据。
在$group中_id是分组依据
1.将数据集按照sex(性别)进行分组,并统计各组的数量。
Code:
db.stu.aggregate(
{$group:
{
_id:"$sex",
counter:{$sum:1}
}
}
)输出:
{ "_id" : "女", "counter" : 2 }{ "_id" : "男", "counter" : 5 }
-
_id,表示分组依据。
-
_id之后的 "$sex",其中的“$”符号一定要记得加!!!若不加上 "$" 符号,则会出现一下结果: { "_id" : "sex", "counter" : 7 }
-
上述正确结果中带有 "_id","counter",两个字段,其中 "_id"字段是必须要指定的!
-
counter:{$sum:1},其中{$sum:1}的意思是——以一倍数计数。
2.求男女生的平均年龄。
db.stu.aggregate(
{$group:
{
_id:"$sex",
"avg_age":{$avg:"$age"}
}
}
)#输出
{ "_id" : "女", "avg_age" : 24 }{ "_id" : "男", "avg_age" : 23.2 }
Group by null:
_id:null 把集合中的所有文档归为一组
db.stu.aggregate(
{$group:
{
_id:null,
counter:{$sum:1},
avg_age:{$avg:"$age"}
}
}
)#输出
{ "_id" : null, "counter" : 7, "avg_age" : 23.428571428571427 }
注:
$group中有几个键,结果就有几个键。
取不同字段的值需要使用 "$" 符号来取,例如上述的 "$age"
但是有些时候,我们觉得 上述的输出结果带有 _id,太丑了!!!所以我们可以使用 $project。
2.$project:
修改输入文档的结构,如重命名、增加、删除字段、创建计算结果。
如上述Group的例子:
db.stu.aggregate(
{$group:
{
_id:"$sex",
counter:{$sum:1},
avg_age:{$avg:"$age"}
}
},
{$project:
{
sex:"$_id",
count:"$counter",
avg:"$avg_age"
}
}
)
#结果{ "_id" : "女", "sex" : "女", "count" : 2, "avg" : 24 }{ "_id" : "男", "sex" : "男", "count" : 5, "avg" : 23.2 }#不加$project的结果{ "_id" : "女", "counter" : 2, "avg_age" : 24 }{ "_id" : "男", "counter" : 5, "avg_age" : 23.2 }
对比:
使用$project可以改变字段名!
but有更加简便的写法:
db.stu.aggregate(
{$group:
{
_id:"$sex",
counter:{$sum:1},
avg_age:{$avg:"$age"}
}
},
{$project:
{
sex:"$_id",
count:"$counter",
avg:"$avg_age",
_id:0
}
}
)#输出:{ "sex" : "女", "count" : 2, "avg" : 24 }{ "sex" : "男", "count" : 5, "avg" : 23.2 }
很明显可以看见 _id 的字段不见了,或则可以说是使用$project将 "_id" 字段改名为 sex!
亦可以:
db.stu.aggregate(
{$group:
{
_id:"$sex",
counter:{$sum:1},
avg_age:{$avg:"$age"}
}
},
{$project:
{
sex:"$_id",
counter:1,
avg_age:1,
_id:0
}
}
)#输出
{ "counter" : 2, "avg_age" : 24, "sex" : "女" }{ "counter" : 5, "avg_age" : 23.2, "sex" : "男" }
这一种写法较为简便 counter:1 <==> counter:{$sum:1}
但是其变量就不能改名!!!即counter:{$sum:1} 不能写成 count:1
还有顺序发生变化!!
1.查询学生的姓名、年龄:
db.stu.aggregate(
{$project:
{
_id:0,
name:1,
age:1
}
}
)
#输出
{ "name" : "小明", "age" : 18 }{ "name" : "李百", "age" : 20 }{ "name" : "张三", "age" : 26 }{ "name" : "王五", "age" : 26 }{ "name" : "赵六", "age" : 26 }{ "name" : "小美", "age" : 26 }{ "name" : "小白", "age" : 22 }
2.查询男、女生人数,输出人数。
db.stu.aggregate(
{$group:
{
_id:"$sex",
counter:{$sum:1}
}
},
{$project:
{
counter:1,
sex:"$_id",
_id:0,
}
}
)3.$match:
用于过滤数据,只输出符合条件的文档。
为什么不适用find()呢???
match是管道命令,能将结果交给一个管道,但是find()不行。
1.查询年龄大于20的学生
db.stu.aggregate(
{$match:
{
age:{$gt:20}
}
}
)#在这里与find()作用一样
db.stu.find({age:{$gt:20}});2.查询年龄大于22的男、女生人数
db.stu.aggregate(
{$match:
{
age:{$gt:22}
}
},
{$group:
{
_id:"$sex",
count:{$sum:1}
}
}
)#输出:
{ "_id" : "女", "count" : 1 }{ "_id" : "男", "count" : 3 }
4.$sort:
将输入文档排序后输出
查询男、女生的人数,按人数降序排序
db.stu.aggregate(
{$group:
{
_id:'$sex',
count:{$sum:1}
}
},
{$sort:
{
count:-1
}
}
)5.$limit 与 $skip
与上述使用方法大同小异。
6.$unwind:
将文档的某一个数组类型的字段拆分成多条,每一条包含数组种的一个值。
db.name.aggregate({$unwind:'$字段名称'});例如:
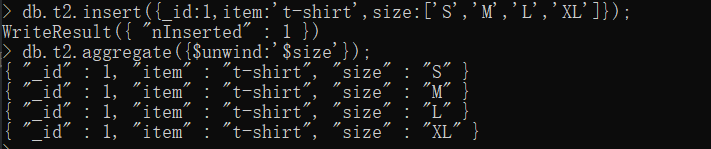
先插入一条数据
db.t2.insert({_id:1,item:'t-shirt',size:['S','M','L','XL']});再使用$unwind命令去筛选
db.t2.aggregate({$unwind:'$size'});运行结果如下:
例子:
数据库中有一条数据:
{"username":"Alex","tags":["C++","Java","Python"]}
如何获取tags的长度???
1.先将例子中的数据插入t2表中
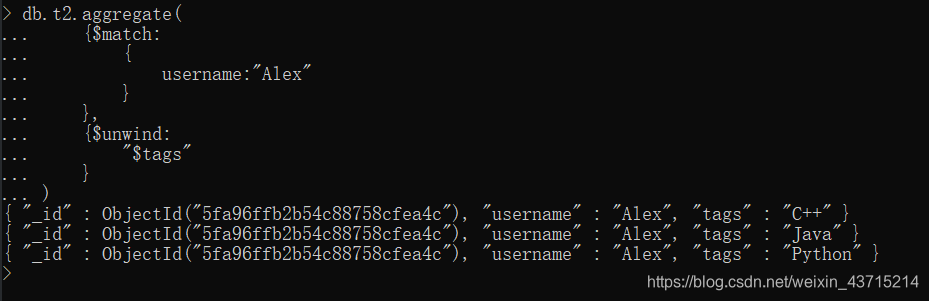
db.t2.insert({"username":"Alex","tags":["C++","Java","Python"]})2.再使用$unwind筛选结果
db.t2.aggregate(
{$match:
{
username:"Alex"
}
},
{$unwind:
"$tags"
}
) 
3.统计数量:
db.t2.aggregate(
{$match:
{
username:"Alex"
}
},
{$unwind:
"$tags"
},
{$group:
{
_id:null,
sum:{$sum:1}
}
}
)#运行结果
{ "_id" : null, "sum" : 3 }
使用$unwind的注意事项:
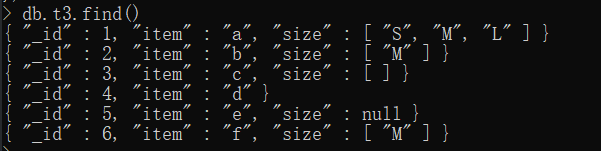
db.t3.insert([
{_id:1,item:"a",size:["S","M","L"]},
{_id:2,item:"b",size:["M"]},
{_id:3,item:"c",size:[]},
{_id:4,item:"d"},
{_id:5,item:"e",size:null},
{_id:6,item:"f",size:["M"]}
])结果如下图:
db.t3.aggregate({$unwind:"$size"});运行结果如下:
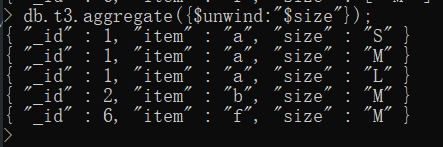
db.name.aggregate(
{$unwind:
{
path:'字段名',
preserveNullAndEmptyArrays:<boolean> #防止数据丢失。
}
}
)例如:
db.t3.aggregate(
{$unwind:
{
path:'$size',
preserveNullAndEmptyArrays:true
}
}
)
运行结果:
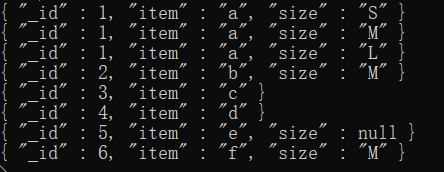

 浙公网安备 33010602011771号
浙公网安备 33010602011771号