第一次个人编程作业
[github链接](Gainpaolo/software-engineering: 软件工程作业 (github.com))
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 400 | 500 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 15 |
| · Design | · 具体设计 | 60 | 70 |
| · Coding | · 具体编码 | 600 | 800 |
| · Code Review | · 代码复审 | 60 | 200 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 50 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 60 | 90 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| · 合计 | 1340 | 1815 |
二、计算机模块
(3.1)计算模块接口的设计与实现过程。
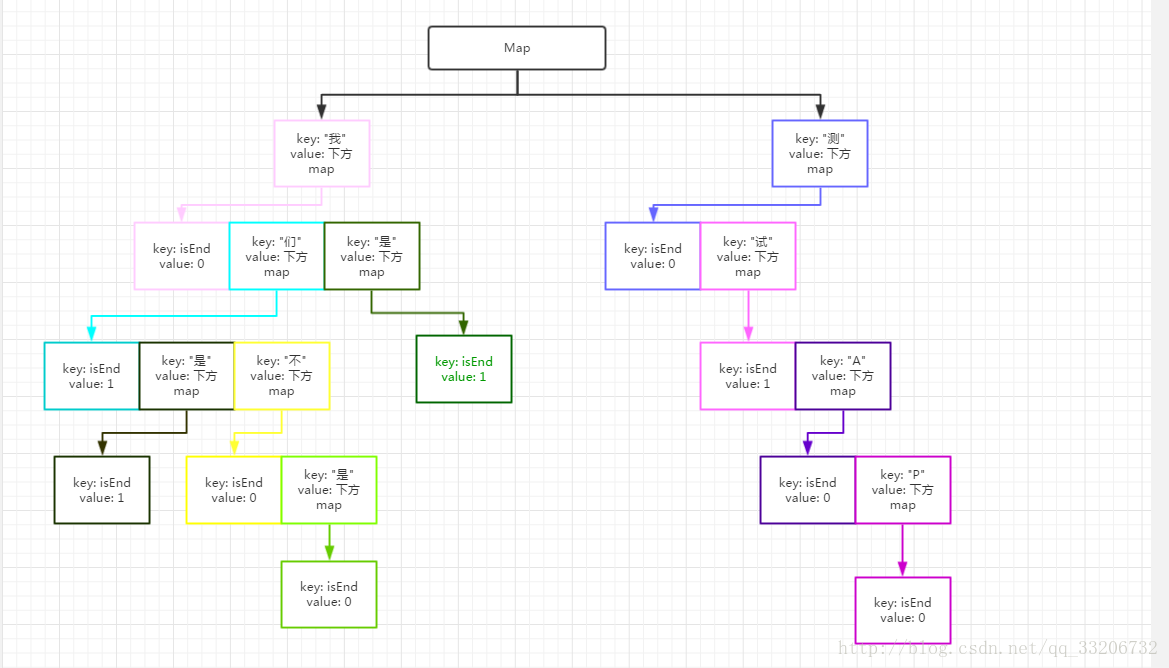
这次作业的底层代码是DFA算法,定义DFAFilter类和把敏感词进行变形的WORDword类。DFAFilter类中有3个函数,分别是add(加入新词),parse(构建敏感词树),filter(模式匹配);word_word类中就一个changeandarra函数(进行敏感词变形重组)。首先我们需要根据敏感词库构造一个树,我的想法就是把所有的变形情况都加到树中,再利用这个树形成的敏感词模式串去匹配要检测的文章。
-
DFAFilter类:定义了结尾标志符号 '\x00' 和 敏感词链表。
-
add函数:这里接受两个参数,一个就是敏感词字符串(改敏感词经过了变形或者没有),一个是这个敏感词是在敏感词源文件中的第几个敏感词的int型的参数ww,为后面复原敏感词做标记。把这个ww作为结尾标志符号 '\x00' 的值。这样在检测的结尾的时候只要看一下这个值是什么就知道该变形敏感词原来是什么样子的。
-
parse函数:读取敏感词文件,调用WORDword.changeandarra()(自定义)对敏感词进行变形和重组形成该敏感词对应的一个列表,再一个个和int型的ww(对原敏感词的标记)一起传入add。建立一个完整的敏感词。
-
filter函数:算法和原来的DFA匹配算法差不多,但是原先没有最长匹配和对干扰符号有效检测。
- 最长匹配:这里设置一个标志位mark=0,第一次遇到结尾标志符号 '\x00'的时候就把mark设置为1,并且把当前匹配的原文段,所在行数,和是哪一个敏感词记录在一个temp字典中,然后继续往下找。遇到找不到的情况就判断temp是否为空,如果不为空就加入结果中,并清空temp字典,设置mark=0,这样不断找下去。这样就可以把最长的匹配串找出来了。
- 干扰符号:干扰符号较为简单,如果是检测到干扰符号,只要这个字典树不是还在第一步,没有进入子字典,就跳过这个干扰符号,否则就把符号记录到我们最后的敏感词原字符串中,在后面如果没有遇到到结束符就把整个字符串清空,重新再找。
-
changeandarra函数:调用工具包对一个敏感词的每个字进行变形,有拼音变形,繁体字变形,拼音首字母变形,一个字一个列表,在通过笛卡尔积把列表相乘得出所有重新组合的敏感词。其中通过拼音生成的谐音字由于返回的是根据概率越大的先返回,这样很多生僻的谐音字就没有被考虑到,而且这个返回谐音字的函数也是消耗时间最多的。
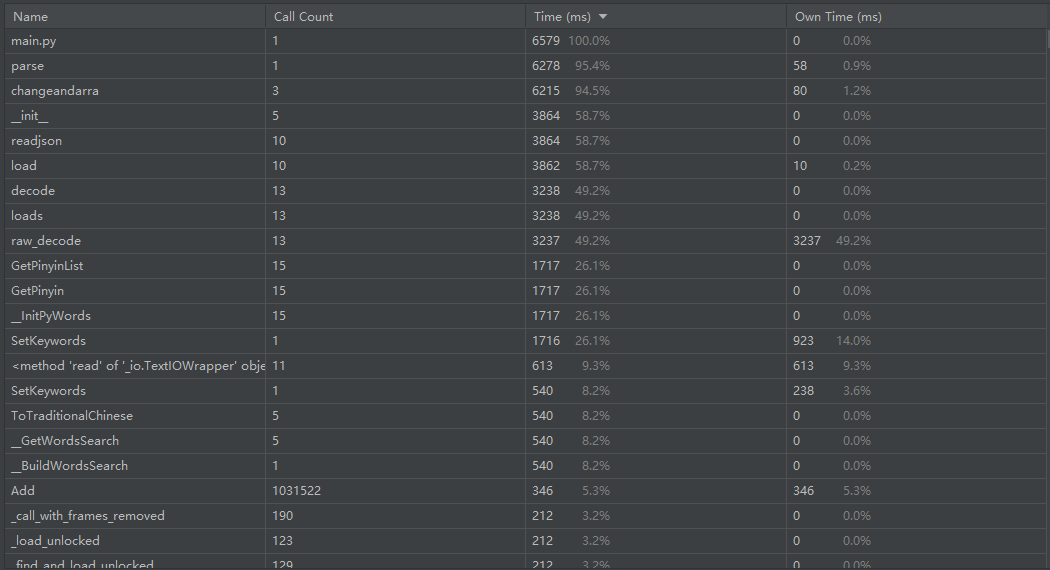
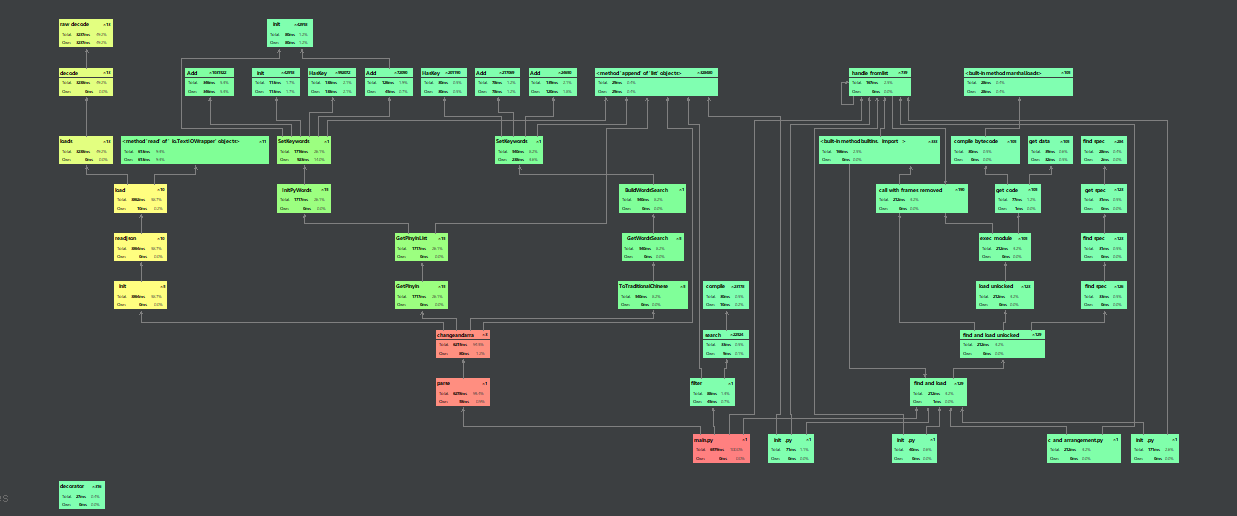
(3.2)计算模块接口部分的性能改进。
- 性能分析图
def changeandarra(self,str1):
ALL=[]
for i in str1:
one_word=[]
one_word.append(i)
if '\u4e00' <= i <= '\u9fff':
one_word.append(pinyin.GetPinyin(i))
d=[]
d.append(pinyin.GetPinyin(i).lower())
dagParams = DefaultDagParams()
# 10个候选值
result = dag(dagParams, d, path_num=15, log=True)
for item in result:
res = item.path # 转换结果
if res[0] not in one_word:
one_word.append(res[0])
one_word.append(pinyin.GetPinyin(i)[0])
one_word.append(translate.ToTraditionalChinese(i))
if i in read_dictionary:
one_word.append(read_dictionary[i])
ALL.append(one_word)
for i in range(0,len(ALL)-1):
if i==0:
g=[k for k in itertools.product(ALL[i],ALL[i+1])]
else:
g = [k for k in itertools.product(g, ALL[i + 1])]
ALL.clear()
for i in g:
ALL.append(''.join(e for e in str(i) if e.isalnum()))
ALL.sort()
return ALL
这个其中的path_num参数(生成谐音字个数),但是把参数调小了会失去更多可能的谐音字,导致准确率不高,只能在其中权衡一下选择较合适的参数。还没有想到合适的解决办法。有一个想法就是找一个字不在我们建立的字典树的时候中的时候就把这个字变成拼音再在字典中去匹配,这样就可以减少changeandarra函数去生成大量的谐音字的时间,而且把所有相同拼音的字都找出来,提高命中率。还没有去尝试,先写了博客交了作业再改。
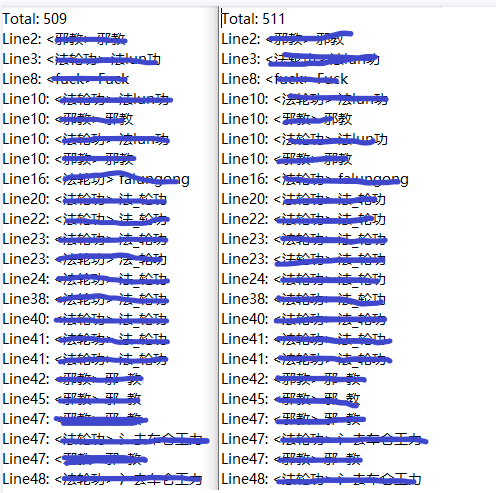
- 下面就是最后的结果截图:
![]()
(3.3)计算模块部分单元测试展示
- 验证敏感词检测
from main import DFAFilter
def test_W():
org_txt = "E:/hh/1.txt "
word_txt = "E:/hh/2.txt "
ans_txt = "E:/hh/3.txt"
compare_txt = "E:/hh/compare.txt"
gfw = DFAFilter()
gfw.parse(word_txt)
gfw.filter(org_txt, ans_txt, word_txt)
with open(ans_txt, "r", encoding="utf8") as f:
out_list = f.read().splitlines()
with open(compare_txt, "r", encoding="utf8") as f:
compare_list = f.read().splitlines()
for i in range(len(compare_list)):
assert out_list[i] == compare_list[i]
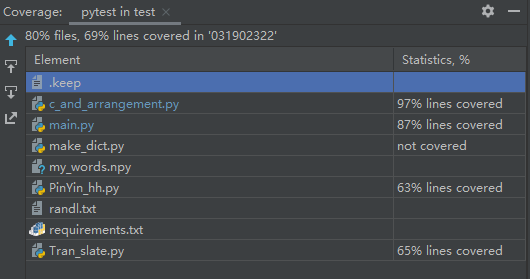
- 原因分析:c_and_arrangement.py就一个函数调用所有基本全部执行,在main.py中__main__下有有一段调用执行,因为没有就没有执行,覆盖率就没有达到很高。PinYin.py中有一大段的静态资源,在没有大量的输入文本的时候覆盖率就没有非常高,如图只有63%。在Tran_slate.py代码中有很长一段的用来演示的代码段没有在在测试中被执行以及大量的静态资源。

(3.4)计算模块部分异常处理说明。
对于文件打开的异常测试。应用于对敏感词的测试文本和敏感词的读,和输出文本的写。
import unittest
import os
def pass_path(path1):
with open(path1,"r", encoding="utf8") as f:
return f.read().splitlines()[0]
class demoRaiseTest(unittest.TestCase):
def test_IO(self):
self.assertRaises(IOError,pass_path,"E:/hh/3")
if __name__ == '__main__':
unittest.main()
三、心得
完成这次的项目真的是一波三折的,从一开始的一点思路都没有到慢慢写出雏形,但是一堆的bug,再慢慢改,最终可以写出来一份可以对各个功能都可以较为完整的执行的成品。
在刚刚开始的时候对于拼音和各种变形不知道如何去检测,好在有人指导在github上有个可以用的开源代码可以把汉字进行转化,这简直是强大的武器,好比之前都是在用小米加步枪打项目,有了GitHub简直像升级了核导弹一样。一下子我的基本功能就可以实现了。接下来就是靠自己进行一些细节的修改。
这次作业我也学习到很多东西,比如一直没有用过的性能分析和单元测试,通过这样可以分析你的代码质量,不断通过改代码的过程中也不断的提高自己的能力。提高自己的发现问题和解决问题的能力。
最后还是觉得自己的能力确实还有很大的空间需要去提高,希望在接下来的课程实践的过程中不断可以发现自己的问题并且提高自己的能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号