

pandas 自动化处理Excel数据
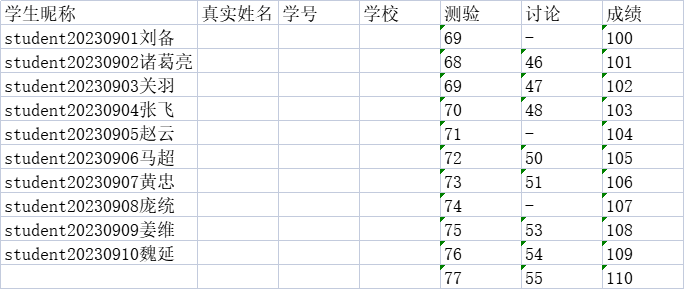
需求: 如下一份这样的Excel数据 现在需要把学生的学号、姓名分离出来到单独的一列 ,将 测验、讨论、成绩三列转换成数值,并把讨论这列的“-”转换成 0 显示
最后把处理好的内容输出到新的Excel文件!!!
对应完整的代码和解释如下:
import pandas as pd
# 1. 读取 Excel 文件到 DataFrame 中。
df = pd.read_excel('C:\\Users\\liuchunlin2\\Desktop\新建文件夹\\测试数据.xlsx', sheet_name='Sheet1')
# 2. 对 DataFrame 中“学生昵称”这一列的字符进行截取,把每个值的第7-15个字符提取出来,并且赋值给新的一列“学号”。
df['学号'] = df['学生昵称'].str[7:15]
# 3. 对 DataFrame 中“学生昵称”这一列的字符进行截取,去掉每个值的前15个字符并保留其余字符,并赋值给新的一列“真实姓名”。
df['真实姓名'] = df['学生昵称'].str[15:]
# 4. 将 DataFrame 中“讨论”这一列的所有“-”替换成“0”,并重新赋值给这一列。
df['讨论'] = df['讨论'].str.replace('-', '0')
# 5. 定义一个列表 columns_to_convert,其中包含需要转换成数字的列名('测验', '讨论', '成绩')。
columns_to_convert = ['测验', '讨论', '成绩']
# 6. 遍历列表 columns_to_convert 中的每个列名,在 DataFrame 中将其对应的列转换成数字类型。
for column in columns_to_convert:
df[column] = pd.to_numeric(df[column], errors='coerce')
df.to_excel('C:\\Users\\liuchunlin2\\Desktop\新建文件夹\\测试数据2.xlsx', index=False)
# 7. 显示数据框的前几行。
print(df.head())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号