

面向对象第一单元总结
2019年面向对象第一单元总结
写在前面:
第一单元总共三次作业,第一次简单多项式导函数的求解,仅包含幂函数和常数;第二次在第一次的基础上加入简单幂函数和简单正余弦函数的导函数的求解;第三次添加嵌套因子和表达式因子,实现更为复杂的多项式求导。
一、第一次作业
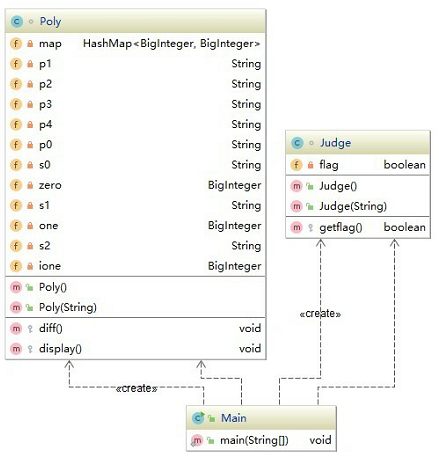
类图
- 缺点:之前一直是过程式编程,刚刚接触java的类和对象,对一些概念的了解不够深入,在设计poly类时,将求导和输出等和poly相关操作都放在其中,这样看起来显得比较臃肿。
实现思路
初次接触类和对象的概念,把程序分成了三个类:Main类是程序的入口;Judge类运用正则表达式判断输入字符串的合法性;Poly实现对多项式的求导和display功能,考虑到有同类项的存在,使用Hashmap数据容器较为方便。
测试
在中测中没有出现问题就以为万事大吉,在求导过程中使用int类型变量忽略数据可能溢出触发的异常,在强测中暴露问题,只过了四组数据,最终没能进入互测。
Bug分析
在修复bug阶段,将int变量修改为BigInteger,成功修复bug。对于一次进行正则表达式匹配存在潜在爆栈的风险,我做了如下改进:将表达式拆分成项,将项拆分成因子,对因子进行正则匹配,满足了最长输入1000字符的要求。
二、第二次作业
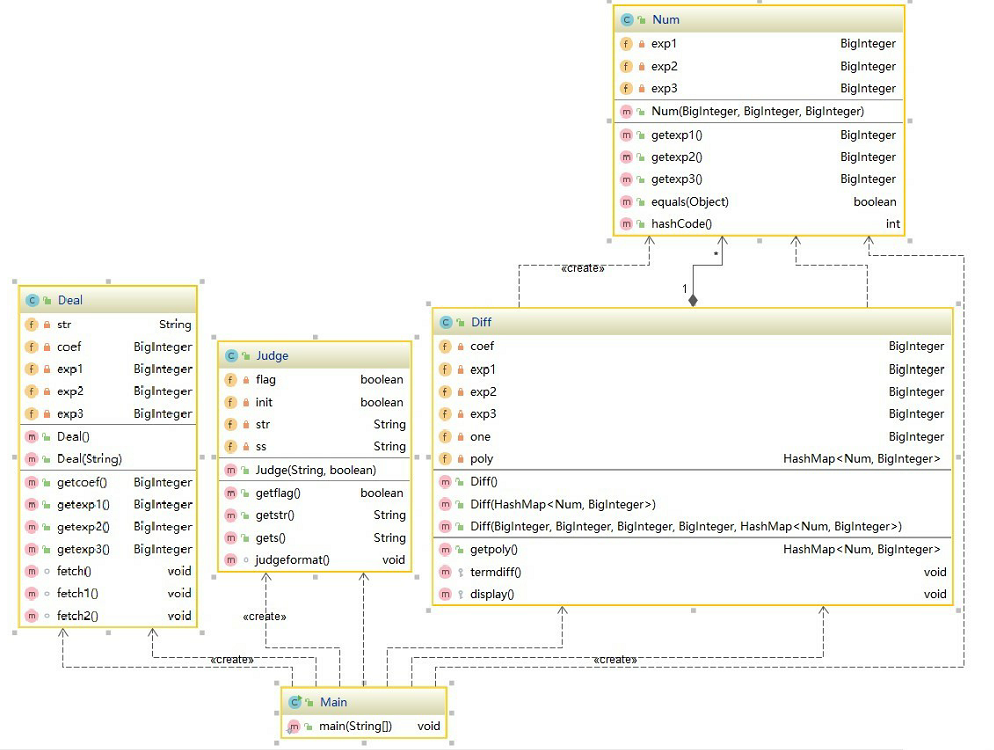
类图
-
优点:每个类的功能比较单一,这样在修改时便于操作。
-
缺点:可变对象的存在,给调试和维护带来不便。单个类存在过长的情况,给阅读带来困难。
实现思路
和第一次作业类似,在第一次作业的基础上进行扩展,先把输入的字符串进行拆分成项,对项进行正则匹配,匹配成功后新建deal对象,将每个项整理成coefxexp1*sin(x)exp2cos(exp3),之后通过diff实现对项的求导,在求导时同样采用hashmap存储求导结果;如果项在正则检验失败,则直接输出wrong format,结束程序的执行。考虑到化简,仍然采用hashmap进行存储,由于单一的key无法满足要求,我重新设计了一个num类,把exp1、exp2、exp3作为成员变量,重写equals和hashcode方法(idea的自动生成hashcode和equals很好用)。最终对hashmap进行遍历,输出求导结果。
测试
公测和强测数据全部通过,互测阶段也没有出现问题,hack别人两次。
虽说测试全部通过,但是在强测时扣掉性能分5分,这是因为当如果的第一项带有‘+’时,可以把符号省略。
Bug分析
在找同room其它同学的bug时,我主要从以下几个方面来看:正则表达式设计的合理性、化简时考虑是否全面(不该省略的一定不要省略)
一位同学在判断字符串合法性的时候出现bug,最后一个字符是‘-’,没有输出wf;另外一位同学则是在化简时出现了错误,对省略的情况没有考虑全面,比如输入-x,错误输出’-‘。
三、第三次作业
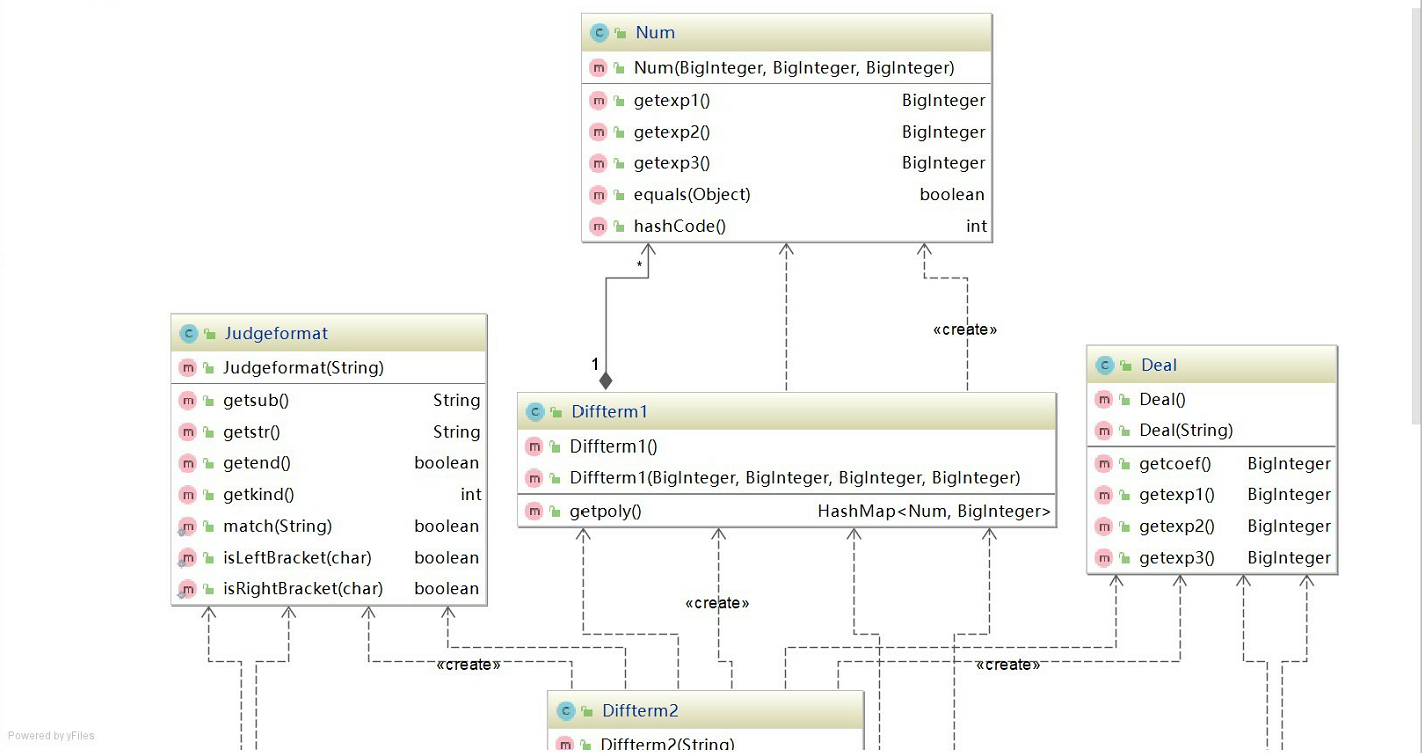
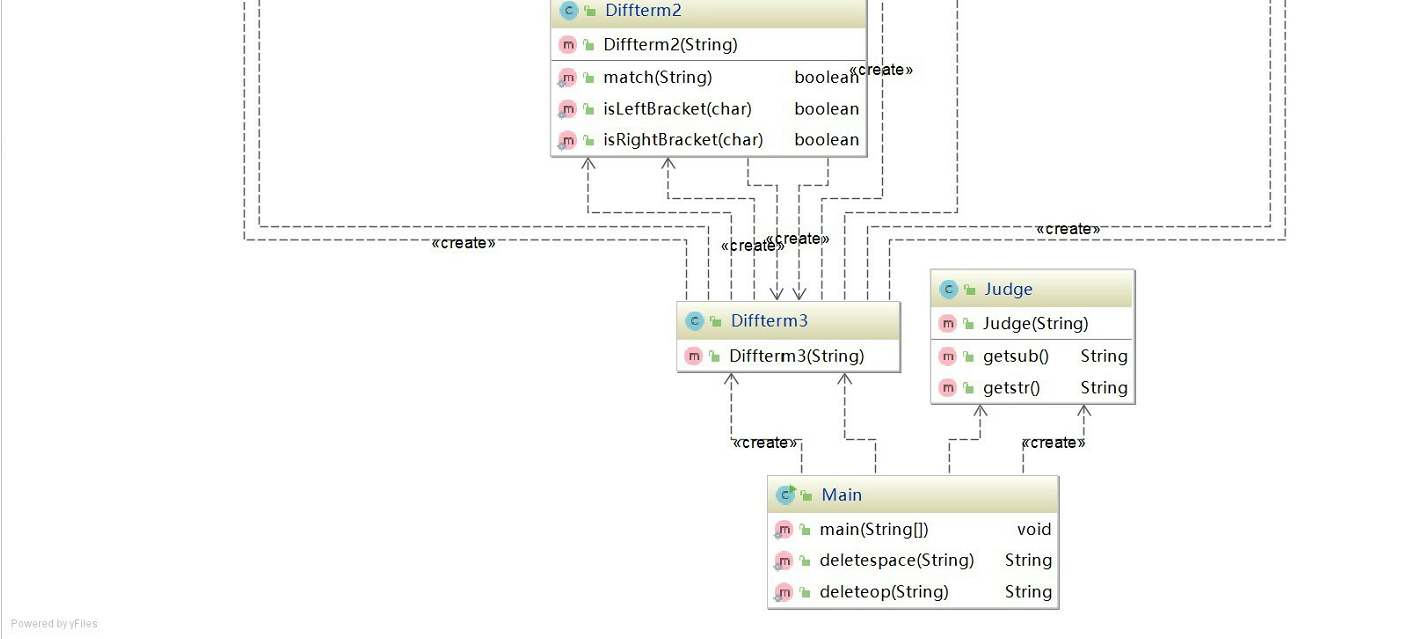
类图
-
优点:程序分为四层,各个类之间的关系一目了然。
-
缺点:存在类和类之间互相引用的情况,给调试和维护带来困难,未能熟练地运用接口和继承。
实现思路
第三次作业新加入了嵌套因子和表达式因子,乘法求导更为复杂(第二次的乘法使用对应系数进行求导,这里已经行不通),无法在第二次的基础上进行扩展,实现这次的求导功能,只能重新构建。首先明确一下常数、幂函数(x、sin(x)、cos(x)的幂)、嵌套因子、表达式因子的关系,发现表达式因子是最顶层的,表达式因子可以包含任何因子,嵌套因子可以包含常数、幂函数和’表达式因子。对输入的字符串判断格式,在格式正确的前提下,对表达式进行预处理,去掉空白字符,幂若带有+,则省去,最后加上(),这样输入的字符串就转化为表达式因子。要对表达式因子求导,则必须实现对幂函数和嵌套因子的求导(类图中diffterm1为幂函数求导,diffterm2为嵌套因子求导,diffterm3为表达式因子求导),对嵌套因子求导可以调用幂函数和表达式因子求导方法,对表达式因子求导可以调用幂函数和嵌套因子求导方法。求导时采用按项求导然后相加。在对每个项求导时,用动态容器arraylist存储项的因子和对应的求导结果,按照乘法求导法则返回求导结果。
测试
公测和强测数据全部通过,互测阶段也没有出现问题,hack别人一次。
这次测试数据全部通过,但是没对求导结果进行化简,丢掉5分性能分。本次测试我发现自己的bug,对形如sin(-(x))的输入,未能输出wf,而是输出其求导结果。
同room同学的bug出现在三角函数求导上,sin(9)能输出求导结果0,sin(-9)却触发异常。
度量分析
第三次作业最为复杂,主要对第三次进行分析。
程序整体分析:
程序代码总共700行左右,这其中最长的类达到200多行,显得有点长。有很大的提升空间,主要是未能充分利用继承和接口来简化设计。

类复杂度分析:
这个程序总共有8个类,每各类属性比较少,但方法3-12个不等,Judgeformat类的方法比较多,总共12个,功能是把字符串拆成项,再把项中的因子提取出来并判断因子类型,为简化类的复杂度,可以把Judgeformat分成拆分和判断两个类。
方法复杂度分析:
总共有40多个方法,方法基本在50行左右(还有一个是60行),在圈复杂度方面,有4个超过了10,这就给代码逻辑的正确性带来很大的挑战,需要多次测试,调试起来也比较费劲。造成复杂度过高的原因是出现了类和类的相互引用和if-else的嵌套结构。可以通过修改类的结构,避免嵌套结构,通过继承关系减少引用次数。
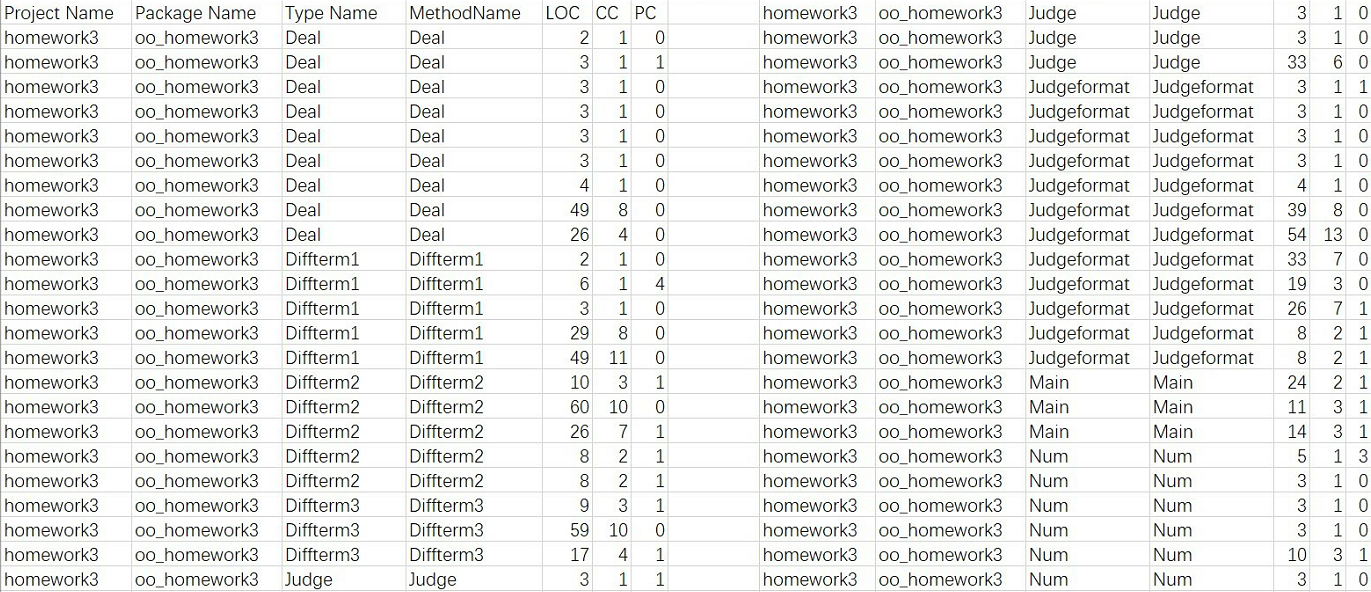
内聚耦合分析:
-
内聚分析
LCOM (Lack of Cohesion in Methods – Class) : 方法的内聚缺乏度。值越大,说明类内聚合度越小。
程序的最大LCOM是0.5,这个类实现的是输入字符串的校验,定义了很多正则匹配规则,是造成内聚度过低的原因。Diffterm1内聚度过低是因为该类调用了deal,num方法,而deal的内聚度也不是很高。改进:简化Deal内部设计,提高内聚度;对于judge,采用拆分匹配的方法实现。
-
耦合分析
FANIN (Fan-in–Class) : 类的扇入。扇入表示调用该模块的上级模块的个数,扇入越大,表示该模块的复用性好。
FANOUT (Fan-out–Class) : 类的扇出。扇出表示该模块直接调用的下级模块的个数,扇出过大表明模块复杂度高,但扇出过小也不好。
设计要求一般是高内聚低耦合,即LCOM值要小,FANIN值要大,FANOUT值要合理。
程序的最大FANOUT为5,这是因为在对嵌套因子和表达式因子求导时会调用其它因子的求导方法。
四、重构设计
重复代码的提炼
重复代码是重构收效最大的手法之一,进行这项重构的原因不需要多说。它有很多很明显的好处,比如总代码量大大减少,维护方便,代码条理更加清晰易读。它的重点就在于寻找代码当中完成某项子功能的重复代码,找到以后请毫不犹豫将它移动到合适的方法当中,并存放在合适的类当中。
嵌套条件分支的优化
大量的嵌套条件分支是很容易让人望而却步的代码,我们应该极力避免这种代码的出现。尽管结构化原则一直在说一个函数只能有一个出口,但是在这么大量的嵌套条件分支下,让我们忘了这所谓的规则吧。
拆分冗长的类
大部分时候,我们拆分一个类的关注点应该主要集中在类的属性上面。拆分出来的两批属性应该在逻辑上是可以分离的,并且在代码当中,这两批属性的使用也都分别集中于某一些方法当中。如果实在有一些属性同时存在于拆分后的两批方法内部,那么可以通过参数传递的方式解决这种依赖。 类的拆分是一个相对较大的工程,毕竟一个大类往往在程序中已经被很多类所使用着,因此这项重构的难度相当之大,一定要谨慎,并做好足够的测试。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号