
作业4 102302138 林楚涵
作业四
作业①:使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、
“深证 A 股”3 个板块的股票数据信息。
① 核心代码与运行截图
(此处粘贴你的代码和结果图片)
点击查看代码
import time
import re
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import mysql.connector
import decimal
# === 数据库连接配置===
DB_CONFIG = {
'host': 'localhost',
'user': 'root',
'password': '123456',
'database': 'stock_db'
}
# === 定义要爬取的三个市场板块及其URL(使用前端路由#切换)===
MARKETS = [
('sh_a', 'http://quote.eastmoney.com/center/gridlist.html#sh_a_board'),
('sz_a', 'http://quote.eastmoney.com/center/gridlist.html#sz_a_board'),
('hs_a', 'http://quote.eastmoney.com/center/gridlist.html#hs_a_board')
]
def safe_decimal(value):
"""
安全地将字符串转为 Decimal,处理千分位逗号和无效值(如'-')
"""
try:
v = str(value).replace(',', '').strip()
return decimal.Decimal(v) if v and v not in ['-', ''] else None
except:
return None
def create_driver():
"""
创建并配置 Edge WebDriver 实例,重点强化反反爬能力
"""
edge_options = Options()
edge_options.add_argument("--disable-gpu")
edge_options.add_argument("--no-sandbox")
edge_options.add_argument("--disable-dev-shm-usage")
edge_options.add_argument("--disable-images")
edge_options.add_argument("--start-maximized")
# 伪装成最新版 Edge 浏览器
ua = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0"
edge_options.add_argument(f"user-agent={ua}")
# 关键:隐藏自动化特征
edge_options.add_experimental_option("excludeSwitches", ["enable-automation"])
edge_options.add_experimental_option('useAutomationExtension', False)
edge_options.add_argument('--disable-blink-features=AutomationControlled')
# 禁用通知和弹窗
prefs = {
"profile.default_content_setting_values.notifications": 2,
"profile.default_content_settings.popups": 0,
}
edge_options.add_experimental_option("prefs", prefs)
driver = webdriver.Edge(options=edge_options)
# 通过 CDP 注入 JS 脚本,彻底抹除自动化痕迹 + 拦截广告请求
driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': '''
// 隐藏 webdriver 标志,模拟真实浏览器环境
Object.defineProperty(navigator, 'webdriver', { get: () => undefined });
Object.defineProperty(navigator, 'languages', { get: () => ['zh-CN', 'zh'] });
Object.defineProperty(navigator, 'platform', { get: () => 'Win32' });
Object.defineProperty(navigator, 'deviceMemory', { get: () => 8 });
Object.defineProperty(navigator, 'hardwareConcurrency', { get: () => 8 });
window.chrome = { runtime: {} };
// 拦截含广告关键词的 Ajax 请求,从源头阻止广告加载
const originalOpen = window.XMLHttpRequest.prototype.open;
window.XMLHttpRequest.prototype.open = function(method, url, ...args) {
if (url && (url.includes('/ad/') || url.includes('promotion') || url.includes('popup'))) {
return; // 不发起该请求
}
return originalOpen.call(this, method, url, ...args);
};
'''
})
return driver
def extract_table_data(driver, market_key):
data = []
rows = driver.find_elements(By.CSS_SELECTOR, "#table_wrapper-table tbody tr")
for row in rows:
cols = row.find_elements(By.TAG_NAME, "td")
if len(cols) < 13:
continue # 跳过不完整行(如加载中、广告行)
item = {
'market': market_key,
'bStockNo': cols[1].text.strip(), # 股票代码
'bStockName': cols[2].text.strip(), # 股票名称
'latestPrice': safe_decimal(cols[3].text), # 最新价
'changePercent': cols[4].text.strip('%').strip(), # 涨跌幅(去掉%)
'changeAmount': safe_decimal(cols[5].text), # 涨跌额
'volume': cols[6].text.strip(), # 成交量(含“万”“亿”,保留字符串)
'turnover': cols[7].text.strip(), # 成交额(同上)
'amplitude': cols[8].text.strip('%').strip(), # 振幅
'highest': safe_decimal(cols[9].text), # 最高价
'lowest': safe_decimal(cols[10].text), # 最低价
'openPrice': safe_decimal(cols[11].text), # 开盘价
'closePrice': safe_decimal(cols[12].text), # 昨收价
}
# 只保留6位纯数字股票代码(排除指数、基金等非个股)
if item['bStockNo'] and len(item['bStockNo']) == 6 and item['bStockNo'].isdigit():
data.append(item)
return data
def save_to_db(data_list):
"""
将数据批量写入 MySQL,使用 ON DUPLICATE KEY UPDATE 实现更新
"""
if not data_list:
return
conn = mysql.connector.connect(**DB_CONFIG)
cursor = conn.cursor()
# 创建表,注意字符集设为 utf8mb4 支持中文
cursor.execute("""
CREATE TABLE IF NOT EXISTS a_stocks (
id INT AUTO_INCREMENT PRIMARY KEY,
market VARCHAR(10),
bStockNo VARCHAR(20),
bStockName VARCHAR(100),
latestPrice DECIMAL(20,4),
changePercent VARCHAR(20),
changeAmount DECIMAL(20,4),
volume VARCHAR(30), -- 保留原始格式如"1.23亿"
turnover VARCHAR(30),
amplitude VARCHAR(20),
highest DECIMAL(20,4),
lowest DECIMAL(20,4),
openPrice DECIMAL(20,4),
closePrice DECIMAL(20,4),
UNIQUE KEY uk_market_code (market, bStockNo) -- 唯一索引用于更新
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
""")
conn.commit()
sql = """
INSERT INTO a_stocks (
market, bStockNo, bStockName, latestPrice, changePercent,
changeAmount, volume, turnover, amplitude, highest,
lowest, openPrice, closePrice
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE
latestPrice=VALUES(latestPrice),
changePercent=VALUES(changePercent),
changeAmount=VALUES(changeAmount),
volume=VALUES(volume),
turnover=VALUES(turnover),
amplitude=VALUES(amplitude),
highest=VALUES(highest),
lowest=VALUES(lowest),
openPrice=VALUES(openPrice),
closePrice=VALUES(closePrice)
"""
values = [(d['market'], d['bStockNo'], d['bStockName'], d['latestPrice'],
d['changePercent'], d['changeAmount'], d['volume'], d['turnover'],
d['amplitude'], d['highest'], d['lowest'], d['openPrice'], d['closePrice'])
for d in data_list]
cursor.executemany(sql, values)
conn.commit()
print(f"成功入库 {cursor.rowcount} 条数据。")
cursor.close()
conn.close()
def scrape_market(driver, market_key, url):
"""
爬取单个市场板块的所有分页数据
"""
print(f"\n正在爬取【{market_key}】板块: {url}")
driver.get(url)
time.sleep(8) # 初始加载等待
# 尝试点击 body,规避 Cookie 同意框等轻微遮挡
try:
body = driver.find_element(By.TAG_NAME, "body")
driver.execute_script("arguments[0].click();", body)
except:
pass
# 等待表格容器出现
WebDriverWait(driver, 30).until(
EC.presence_of_element_located((By.ID, "table_wrapper-table"))
)
table = driver.find_element(By.ID, "table_wrapper-table")
driver.execute_script("arguments[0].scrollIntoView({block: 'center'});", table)
time.sleep(1)
# 核心等待:确保第一行第二列是6位数字(即有效股票代码)
WebDriverWait(driver, 40).until(
lambda d: len(d.find_elements(By.CSS_SELECTOR, "#table_wrapper-table tbody tr")) > 0 and
len(d.find_elements(By.CSS_SELECTOR, "#table_wrapper-table tbody tr td")) > 2 and
d.find_elements(By.CSS_SELECTOR, "#table_wrapper-table tbody tr")[0]
.find_elements(By.TAG_NAME, "td")[1].text.strip().isdigit()
)
print(" 表格数据已成功加载!")
# 解析总页数(如 "1/120" → 120)
try:
page_info = driver.find_element(By.CSS_SELECTOR, ".paginate_page").text
total_pages = int(re.search(r'/(\d+)', page_info).group(1))
except:
total_pages = 1
print(f" 共 {total_pages} 页(最多爬前 100 页)")
all_data = []
for page in range(1, min(total_pages + 1, 101)):
if page > 1:
try:
# 点击下一页按钮(需确保未禁用)
next_btn = driver.find_element(By.CSS_SELECTOR, "a.next:not(.disabled)")
driver.execute_script("arguments[0].click();", next_btn)
time.sleep(2)
# 等待旧数据消失 + 新数据出现(双重保障)
WebDriverWait(driver, 15).until(
EC.staleness_of(driver.find_element(By.CSS_SELECTOR, "#table_wrapper-table tbody tr:first-child"))
)
WebDriverWait(driver, 15).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#table_wrapper-table tbody tr"))
)
time.sleep(1)
except:
print(f" 第 {page} 页翻页失败,跳过")
break
data = extract_table_data(driver, market_key)
all_data.extend(data)
print(f" 第 {page} 页获取 {len(data)} 条数据")
# 每20页或最后一批提交一次,避免内存溢出
if page % 20 == 0 or page == min(total_pages, 100):
save_to_db(all_data)
all_data.clear()
# 处理剩余未保存的数据
if all_data:
save_to_db(all_data)
if __name__ == "__main__":
print("启动股票数据爬虫")
driver = None
try:
driver = create_driver()
for market_key, url in MARKETS:
scrape_market(driver, market_key, url)
print("\n所有板块爬取完成!")
except Exception as e:
print(f"\n错误: {e}")
finally:
if driver:
driver.quit() # 确保浏览器关闭,释放资源

② 作业心得
为应对现代网站普遍存在的反爬机制,我在浏览器驱动初始化阶段做了深度优化:通过伪装真实用户代理、禁用图片与通知以加速加载,并利用 Chrome DevTools Protocol(CDP)注入脚本,彻底隐藏自动化特征(如移除 navigator.webdriver 标志),同时重写 XMLHttpRequest 的 open 方法,在网络请求层面主动拦截包含 /ad/、promotion 或 popup 等关键词的广告资源,从源头减少干扰、提升页面渲染效率与数据纯净度。在数据采集环节,我摒弃了简单的 sleep 等待,转而采用显式等待结合 DOM 状态判断——不仅等待表格元素出现,还进一步验证首行第二列是否为有效的 6 位数字股票代码,确保所提取的是真实交易品种而非加载占位符或推广内容。
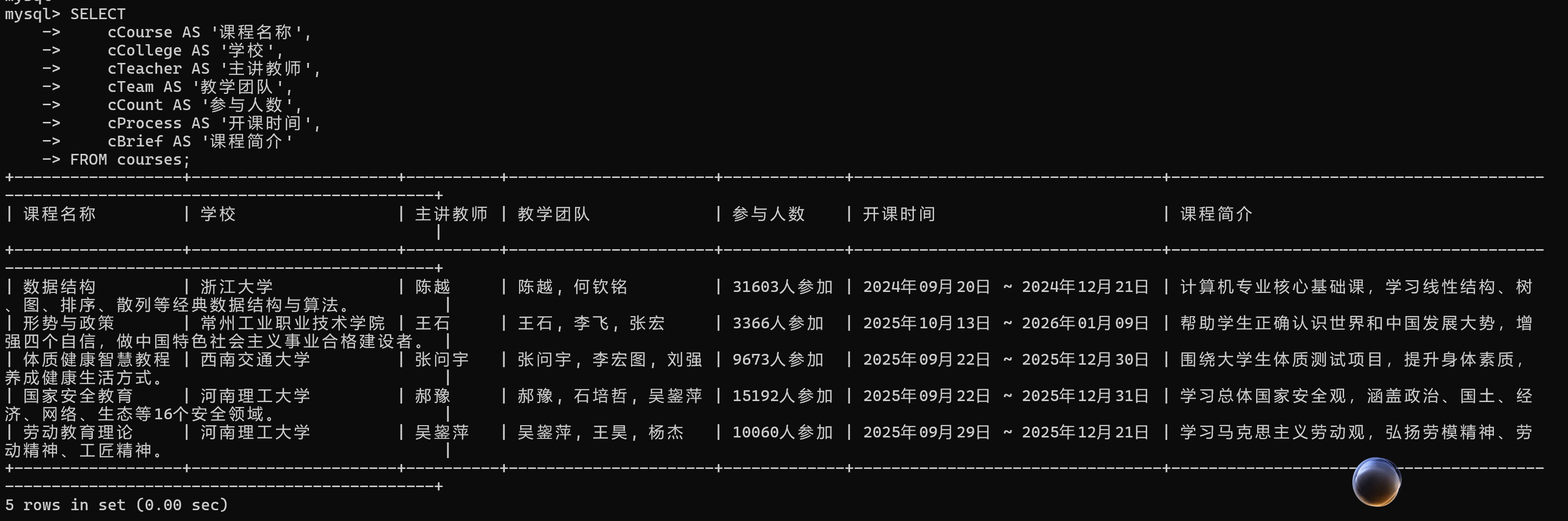
作业②:使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名
称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
① 核心代码与运行截图
*
点击查看代码
import time
import os
import re
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.edge.service import Service as EdgeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import mysql.connector
# === 数据库配置(本地测试环境)===
DB_CONFIG = {
'host': 'localhost',
'user': 'root',
'password': '123456',
'database': 'mooc_db'
}
def create_driver():
"""
创建并配置 Edge WebDriver 实例
"""
driver_path = os.path.join(os.getcwd(), "msedgedriver.exe")
if not os.path.exists(driver_path):
raise FileNotFoundError(f"未找到 msedgedriver.exe!路径: {driver_path}")
service = EdgeService(executable_path=driver_path)
options = Options()
options.add_argument("--disable-gpu")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--start-maximized")
options.add_argument("--disable-images") # 禁用图片加速加载
# 伪装 User-Agent 避免被识别为爬虫
ua = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
options.add_argument(f"user-agent={ua}")
# 关键反反爬设置:隐藏自动化特征
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
options.add_argument('--disable-blink-features=AutomationControlled')
driver = webdriver.Edge(service=service, options=options)
# 通过 CDP 注入脚本,彻底移除 navigator.webdriver 标志
driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': '''
Object.defineProperty(navigator, 'webdriver', { get: () => undefined });
'''
})
return driver
def init_db():
"""
初始化数据库:创建数据库和 courses 表
使用 utf8mb4 字符集以支持完整中文及表情符号
"""
conn = mysql.connector.connect(**DB_CONFIG)
cursor = conn.cursor()
cursor.execute("CREATE DATABASE IF NOT EXISTS mooc_db CHARACTER SET utf8mb4")
conn.database = 'mooc_db' # 切换到目标数据库
cursor.execute("""
CREATE TABLE IF NOT EXISTS courses (
id INT AUTO_INCREMENT PRIMARY KEY,
cCourse VARCHAR(255), -- 课程名称
cCollege VARCHAR(255), -- 开课学校
cTeacher VARCHAR(255), -- 主讲教师
cTeam TEXT, -- 教学团队(多教师拼接)
cCount VARCHAR(50), -- 参与人数(保留原始格式如"10.2万人")
cProcess VARCHAR(255), -- 开课时间/进度
cBrief TEXT -- 课程简介(截断至1000字符)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
""")
conn.commit()
cursor.close()
conn.close()
def is_valid_course_url(url):
"""
严格校验是否为标准课程详情页 URL
规则:必须是 https://www.icourse163.org/course/ 后接字母数字组合 + 数字结尾
示例:https://www.icourse163.org/course/ZJU-199001
目的:过滤掉广告、专题页、非课程链接(如 /spoc/、/kaoyan/ 等)
"""
pattern = r'^https://www\.icourse163\.org/course/[A-Za-z0-9_-]+\d+$'
return bool(re.match(pattern, url))
def parse_standard_course(driver, url):
"""
解析单个标准课程详情页,提取结构化信息
采用“多重尝试”策略:优先用明确 CSS 选择器,失败后降级到 meta 或标签名
所有字段均有默认值,确保返回有效字典或 None
"""
try:
driver.get(url)
time.sleep(4) # 给页面足够时间渲染(可优化为显式等待)
# --- 课程标题 ---
title = "未知课程"
try:
title = driver.find_element(By.CSS_SELECTOR, ".course-title").text.strip()
except:
try:
title = driver.find_element(By.TAG_NAME, "h1").text.strip()
except:
pass # 保留默认值
# --- 开课学校 ---
school = "未知学校"
try:
school = driver.find_element(By.CSS_SELECTOR, ".school a").text.strip()
except:
try:
school = driver.find_element(By.CSS_SELECTOR, ".school-name").text.strip()
except:
pass
# --- 教师信息 ---
teachers = []
try:
# 尝试多种可能的教师姓名选择器
teacher_elems = driver.find_elements(By.CSS_SELECTOR, ".teacher-name, .j-teacher-name")
teachers = [e.text.strip() for e in teacher_elems if e.text.strip()]
except:
pass
main_teacher = teachers[0] if teachers else "未知"
team = "; ".join(teachers) if teachers else "无团队"
# --- 参与人数 ---
count = "0人"
try:
count_elem = driver.find_element(By.CSS_SELECTOR, ".enroll-count span")
count = count_elem.text.strip()
except:
# 备用方案:从页面 meta description 中提取
try:
meta_desc = driver.find_element(By.CSS_SELECTOR, "meta[name='description']").get_attribute("content")
match = re.search(r'(\d+\.?\d*[万]?人)', meta_desc)
if match:
count = match.group(1)
except:
pass
# --- 开课时间/进度 ---
process = "时间未知"
try:
time_elem = driver.find_element(By.CSS_SELECTOR, ".term-time, .course-time")
process = time_elem.text.strip()
except:
pass
# --- 课程简介 ---
brief = "暂无简介"
try:
brief_elem = driver.find_element(By.CSS_SELECTOR, ".course-desc-content, .course-intro")
brief = brief_elem.text.strip().replace("\n", " ")[:1000] # 清理换行并限制长度
except:
# 备用:从 meta description 获取
try:
brief = driver.find_element(By.CSS_SELECTOR, "meta[name='description']").get_attribute("content")[:1000]
except:
pass
return {
'cCourse': title,
'cCollege': school,
'cTeacher': main_teacher,
'cTeam': team,
'cCount': count,
'cProcess': process,
'cBrief': brief
}
except Exception as e:
print(f"解析失败 ({url}): {str(e)[:80]}")
return None
def main():
"""
主流程:
1. 初始化数据库
2. 打开 MOOC 计算机分类页
3. 滚动加载更多课程(模拟人工浏览)
4. 提取并过滤出标准课程链接(最多6个,避免作业超时)
5. 逐个进入详情页解析并入库
"""
print("启动中国大学MOOC课程爬虫(作业② - 严格过滤标准课程)")
init_db()
driver = create_driver()
all_data = []
try:
driver.get("https://www.icourse163.org/category/computer")
print("加载计算机分类页面...")
time.sleep(6) # 等待初始内容加载
# 模拟滚动,触发懒加载(部分课程需滚动才出现)
driver.execute_script("window.scrollTo(0, document.body.scrollHeight * 0.7);")
time.sleep(3)
# 提取所有包含 '/course/' 的链接
raw_links = driver.find_elements(By.XPATH, "//a[contains(@href, '/course/')]")
valid_links = []
for elem in raw_links:
href = elem.get_attribute("href")
if href and is_valid_course_url(href):
valid_links.append(href)
# 去重 + 限制数量(作业要求少量即可,避免耗时过长)
valid_links = list(dict.fromkeys(valid_links))[:6]
print(f"找到 {len(valid_links)} 个标准课程链接")
# 逐个解析课程详情
for i, link in enumerate(valid_links, 1):
print(f"[{i}/{len(valid_links)}] 解析: {link}")
data = parse_standard_course(driver, link)
if data:
all_data.append(data)
print(f" → {data['cCourse']} | {data['cCollege']}")
time.sleep(2) # 礼貌性延迟,避免请求过快
# 批量入库
if all_data:
conn = mysql.connector.connect(**DB_CONFIG)
cursor = conn.cursor()
sql = """
INSERT INTO courses (cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief)
VALUES (%s, %s, %s, %s, %s, %s, %s)
"""
vals = [(d['cCourse'], d['cCollege'], d['cTeacher'], d['cTeam'],
d['cCount'], d['cProcess'], d['cBrief']) for d in all_data]
cursor.executemany(sql, vals)
conn.commit()
print(f"\n成功入库 {len(all_data)} 门课程!")
cursor.close()
conn.close()
else:
print("未获取到有效课程数据。")
finally:
driver.quit() # 确保浏览器关闭,释放资源
if __name__ == "__main__":
main()
② 作业心得
首先配置数据库连接参数并导入所需模块,接着定义一个创建反检测 Edge 浏览器驱动的函数,通过设置用户代理、禁用自动化特征和图像加载等方式规避网站反爬机制;随后初始化数据库,自动创建名为 mooc_db 的数据库及 courses 表,确保字段结构符合要求;主流程中,程序访问中国大学MOOC计算机分类页面,滚动加载后提取所有包含 "/course/" 的链接,并通过正则表达式严格过滤出标准课程URL,去重后取前6个;对每个有效链接,程序进入课程详情页,依次尝试多种选择器定位课程名称、学校、教师团队、参与人数、开课时间和课程简介等信息,若某字段无法获取则使用默认值(如“未知学校”);解析完成后,将收集到的有效课程数据批量插入数据库 courses 表中。
作业③:要求:
• 掌握大数据相关服务,熟悉 Xshell 的使用
• 完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验(部
分)v2.docx 中的任务,即为下面 5 个任务,具体操作见文档。
① 核心代码与运行截图
环境搭建:
任务一:开通 MapReduce 服务
实时分析开发实战:
任务一:Python 脚本生成测试数据

任务二:配置 Kafka

任务三: 安装 Flume 客户端



任务四:配置 Flume 采集数据

② 作业心得
完成华为云大数据实时分析处理的 Flume 日志采集实验后,我不仅熟练掌握了 putty 的远程操作技巧,成功完成了 MapReduce 服务开通、Python 脚本生成测试数据、Kafka 配置、Flume 客户端安装及数据采集配置的全流程操作,还理清了 MapReduce、Kafka、Flume 等组件的协同逻辑,深刻理解了各组件在大数据实时处理中的角色与作用;实验过程中,我曾因 Flume 配置文件参数错误、组件依赖包缺失等问题遇到阻碍,通过逐行核对配置项、查阅官方文档、提前梳理依赖关系等方式成功解决,这让我意识到大数据实验中严谨性和预处理的重要性,也显著提升了自己的问题排查与动手实践能力,更体会到大数据技术 “理论结合实践” 的核心要求,后续我会继续深入学习大数据生态组件,尝试拓展实验场景,积累更丰富的项目经验。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号