
清北学堂Day 6之STL
电脑突然一炸,什么都没有保存,凉了。(又出现了笔记凉凉事件嘤嘤嘤)
行吧慢慢回忆
就算我们会手写,我们也要学STL。吸了O2的STL可是要上天的。
数据结构
pair
使用方式:
pair<类型名,类型名>变量名
里面的类型是任意的,所以我们也可以有pair<pair<int,int>,int> a,这种诡异的操作。
在pair里面,是以第一个元素为第一关键字,第二个元素为第二关键字进行排序的。
有什么用呢?可以当做一个二元组,代替结构体(在吸氧之后变的贼快)
string
这个东西可以用来代替字符型数组,但是它比字符型数组神奇多了,比如我们可以这样搞:
string a,b;
a+b:把a和b拼起来
例如:
a=qingbei
b=zaotang
a+b=qingbeizaotang
a.size()字符串长度
a[i]:可以下表访问

vector
vector是不定长数组。
写法:vecor<类型> 变量名,例如:vector<int> a
这时用a的话,就写a[i].如果是这样:vector<int>a[100],这时每个a[i]都是一个数组,表示方式就是a[i][j],因为vector分配内存是动态的,所以当数据较大时,可以代替邻接矩阵进行存图。但是它很慢?why?这就和vector分配内存的原理有关。
vector的内存大小永远是2^k。
举个例子,一开始我们往a里面存入一个数,那a的大小就是1,当我们要存第二个数的时候,vector就会制造一个大小为2的连续内存,把第一个数复制过去,再加入第二个数。当要存第三个数时,就开一个大小为4的内存,把第一个数,第二个数复制过去。vector就是这种存储方式。当存的数多了,复制的次数也就多了,所以会慢。当然STL遇见O2就是上天。当然,这样存也是占空间的,但不会造成空间的浪费,这点在数据大的时候是完胜二维数组的。
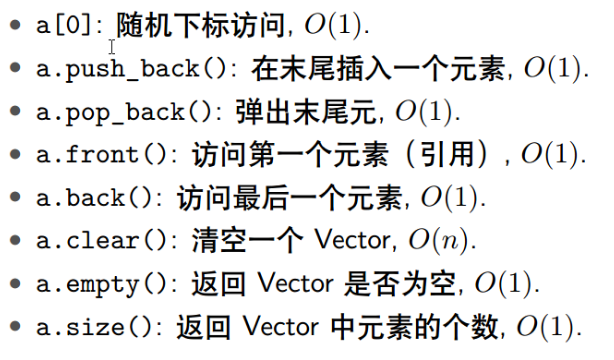
iterator:vector的迭代器

啥是迭代器?简单的说,就是某个元素的地址(但不严谨,不过这么理解就够了)
vector的遍历:

set
set是个集合,既然是个集合,就肯定不会有重复的元素了。OI的集合还有一个特性:它是有序的。所以set中的元素都要满足可以排序,不然会报错的。

注意这里的a.end()返回的是一个不存在的地址,要用到最后一个,要减一。当a.find()无法找到对应元素的时候,就会返回a.end(),也就是那个不存在的地址。

一些用法qwq
set是个神奇的东西,它的底层是平衡树。顾名思义,就是长得平衡的树。
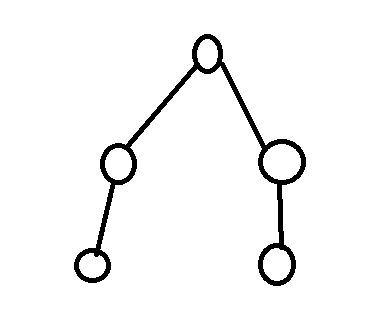
这就是棵平衡树。
在这里扯淡点有关平衡树的东西。
OI常用平衡树:
替罪羊树,红黑树,AVL,Treap,伸展树。(小姐姐只讲了替罪羊树,其他的没讲qwq,贴个百度链接好了(其实我看不懂它在说些什么))
什么是替罪羊树?
你有一棵树,它奇丑无比。比如这样

这时候,我们想把它变成平衡树。显然这很费劲,那我们换个思路,不在原图上改变,而是把节点摘出来,在不改变前序遍历的顺序的前提下,重建一棵树。这就是替罪羊树的想法。
前面说到set会自动排序,如果我们想在set里面装点不是int,double之类的类型(比如结构体),怎么办?
首先,我们要手写排序。

就像这种神奇的操作。
Muilt Set

那我们怎么样让它只删除一个数字呢?
我们只删去它的迭代器就好了(也就是a.find(i))
Map

O(n)的暴力扫显然太暴力了,不优雅。我们来想想怎么O(1)就找到它。
cout<<a[__debug]??
上面的东西在一般情况下显然是不行的。
但是我们这里讲的是map

map的第一维是这个数组下标的类型(要求必须可排序),第二维是值。

栈(Stack)(念zhàn,不念zhài(致某些嘴piao的孩子))
栈是一种后进先出的结构,据说没有什么卵用,平常在没有O2的时候一维数组显然要快。

队列(queue)
这个东西比栈有用多了,在广搜,spfa.....里面用的比较多。

注意队列出队的永远只是队首。
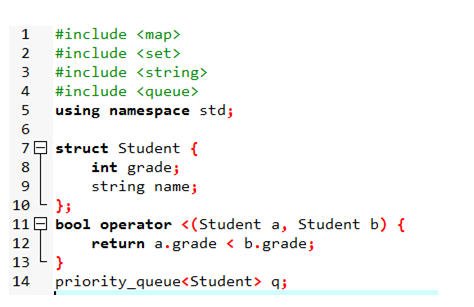
优先队列(priority_queue)
这个东西叫优先队列,但其实和堆没有什么区别。优先队列默认的是大根堆,但我们可以通过一系列神奇的操作把它变成小根堆。
先来看看成员函数

把大根堆搞成小根堆:
priority_queue<int,vector<int>,greater<int> >q (注意q前面的>前面的空格不能省略)
用结构体:

二.函数
sort
快排大家都用过对吧。
格式:sort(a+开始下标,a+结束下标+1,cmp(比较函数))
sort默认升序排序
这里的比较函数不一定要叫cmp,只要你愿意,叫caixukunjinitaimei都可以qwq
cmp写法(这里拿降序排序举例):
bool cmp (int a,int b) {return a>b; }
Reverse
按照输入的顺序倒序输出

用处:目前没有发现
Unique
去重。还是比较常用的。unique要求去重的序列有序,不然会出来一些奇奇怪怪的东西。
比如: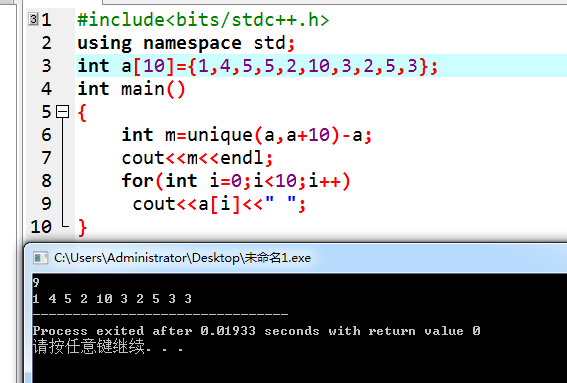
unique返回的是一个迭代器,是去重后的最后一位的下标。
正确打开方式:

输出:
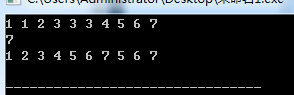
把后面重复的东西置为0:
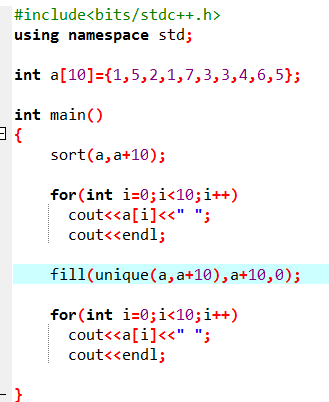
输出:

fill和memset的区别:fill是填充,memset是清0(也可以是-1)。
但是用其他的数,fill可以操作,但memset之后就是一些鬼畜的东西。而且fill是o(n)的,memset巨快无比
Next Permutation
找到数组的下一个排列
最大用处:全排列(麻麻全排列的题我不用写搜索了qwq)

如果要用这个求全排列的话,复杂度至少是阶乘级别的(吸氧之后就不知道了)
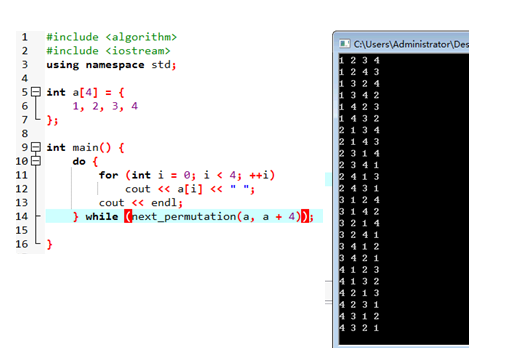
一份全排列的代码+输出
Binary Search
就是二分查找。

格式什么的。
当然要查结构体类型的数组里的数的话,就手写吧,反正我是不会用结构体类型的Binary Search(尝试手写结构体类型的lower_bound,竟然没炸!!!)
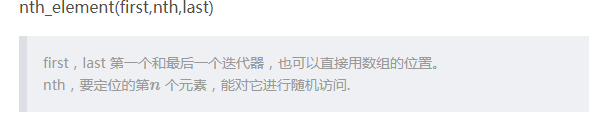
Nth Element
把一个数放进有序数组里它该放的位置,还是挺好用的。
当然,在无序的情况下保证放进去的i的前一个数比i大,但不保证整体有序。
复杂度O(n)

Random_Shuffle
随机重排
c++的随机性特别差,总是出现41。这是有原因的,因为rand并不是随机数,而是根据随机种子算出来的一个数。所以我们要得到随机数,就得改随机种子。
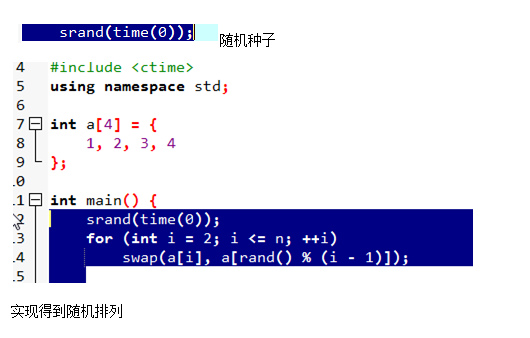
一波神奇的操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号