[数据库] 理解数据库范式-通俗易懂
转自:http://blog.chinaunix.net/uid-10073362-id-225057.html
数据库范式是数据库设计中必不可少的知识,没有对范式的理解,就无法设计出高效率、优雅的数据库。甚至设计出错误的数据库。而想要理解并掌握范式却并不是那么容易。教科书中一般以关系代数的方法来解释数据库范式。这样做虽然能够十分准确的表达数据库范式,但比较抽象,不太直观,不便于理解,更难以记忆。
本文用较为直白的语言介绍范式,旨在便于理解和记忆,这样做可能会出现一些不精确的表述。但对于初学者应该是个不错的入门。我写下这些的目的主要是为了加强记忆,其实我也比较菜,我希望当我对一些概念生疏的时候,回过头来看看自己写的笔记,可以快速地进入状态。如果你发现其中用错误,请指正。
下面开始进入正题:
一、基础概念
要理解范式,首先必须对知道什么是关系数据库,如果你不知道,我可以简单的不能再简单的说一下:关系数据库就是用二维表来保存数据。表和表之间可以……(省略10W字)。
然后你应该理解以下概念:
实体:现实世界中客观存在并可以被区别的事物。比如“一个学生”、“一本书”、“一门课”等等。值得强调的是这里所说的“事物”不仅仅是看得见摸得着的“东西”,它也可以是虚拟的,比如说“老师与学校的关系”。
属性:教科书上解释为:“实体所具有的某一特性”,由此可见,属性一开始是个逻辑概念,比如说,“性别”是“人”的一个属性。在关系数据库中,属性又是个物理概念,属性可以看作是“表的一列”。
元组:表中的一行就是一个元组。
分量:元组的某个属性值。在一个关系数据库中,它是一个操作原子,即关系数据库在做任何操作的时候,属性是“不可分的”。否则就不是关系数据库了。
码:表中可以唯一确定一个元组的某个属性(或者属性组),如果这样的码有不止一个,那么大家都叫候选码,我们从候选码中挑一个出来做老大,它就叫主码。
全码:如果一个码包含了所有的属性,这个码就是全码。
主属性:一个属性只要在任何一个候选码中出现过,这个属性就是主属性。
非主属性:与上面相反,没有在任何候选码中出现过,这个属性就是非主属性。
外码:一个属性(或属性组),它不是码,但是它别的表的码,它就是外码。
二、6个范式
好了,上面已经介绍了我们掌握范式所需要的全部基础概念,下面我们就来讲范式。首先要明白,范式的包含关系。一个数据库设计如果符合第二范式,一定也符合第一范式。如果符合第三范式,一定也符合第二范式……
·第一范式(1NF):属性不可分。
在前面已经介绍了属性值的概念,我们说,它是“不可分的”。而第一范式要求属性也不可分。那么它和属性值不可分有什么区别呢?给一个例子:

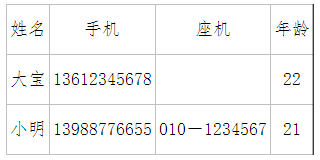
这个表中,属性值“分”了。“电话”这个属性里对于“小明”属性值分成了两个。

这两种情况都不满足第一范式。不满足第一范式的数据库,不是关系数据库!所以,我们在任何关系数据库管理系统中,做不出这样的“表”来。针对上述情况可以做成这样的表:这个表中,属性 “分”了。也就是“电话”分为了“手机”和“座机”两个属性。
·第二范式(2NF):符合1NF,并且,非主属性完全依赖于码。(注意是完全依赖不能是部分依赖,设有函数依赖W→A,若存在XW,有X→A成立,那么称W→A是局部依赖,否则就称W→A是完全函数依赖)

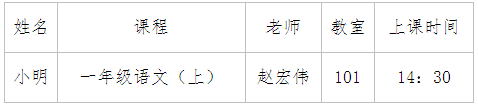
一个学生上一门课,一定是特定某个老师教。所以有(学生,课程)->老师;
一个学生上一门课,一定在特定某个教室。所以有(学生,课程)->教室;
一个学生上一门课,他老师的职称可以确定。所以有(学生,课程)->老师职称;
一个学生上一门课,一定是特定某个教材。所以有(学生,课程)->教材
一个学生上一门课,一定在特定时间。所以有(学生,课程)->上课时间
因此(学生,课程)是一个码。
然而,一个课程,一定指定了某个教材,一年级语文肯定用的是《小学语文1》,那么就有课程->教材。(学生,课程)是个码,课程却决定了教材,这就叫做不完全依赖,或者说部分依赖。出现这样的情况,就不满足第二范式!
有什么不好吗?你可以想想:
1、校长要新增加一门课程叫“微积分”,教材是《大学数学》,怎么办?学生还没选课,而学生又是主属性,主属性不能空,课程怎么记录呢,教材记到哪呢? ……郁闷了吧?(插入异常)
2、下学期没学生学一年级语文(上)了,学一年级语文(下)去了,那么表中将不存在一年级语文(上),也就没了《小学语文1》。这时候,校长问:一年级语文(上)用的什么教材啊?……郁闷了吧?(删除异常)
3、校长说:一年级语文(上)换教材,换成《大学语文》。有10000个学生选了这门课,改动好大啊!改累死了……郁闷了吧?(修改/更新异常,在这里你可能觉得直接把教材《小学语文1》替换成《大学语文》不就可以了,但是替换操作虽然计算机运行速度很快,但是毕竟也要替换10000次,造成了很大的时间开销)
那应该怎么解决呢?投影分解,将一个表分解成两个或若干个表


·第三范式(3NF):符合2NF,并且,消除传递依赖(也就是每个非主属性都不传递依赖于候选键,判断传递函数依赖,指的是如果存在"A → B → C"的决定关系,则C传递函数依赖于A。)
上面的“学生上课新表”符合2NF,但是它有传递依赖!在哪呢?问题就出在“老师”和“老师职称”这里。一个老师一定能确定一个老师职称。(学生,课程)->老师->职称。
有什么问题吗?想想:
1、老师升级了,变教授了,要改数据库,表中有N条,改了N次……(修改异常)
2、没人选这个老师的课了,老师的职称也没了记录……(删除异常)
3、新来一个老师,还没分配教什么课,他的职称记到哪?……(插入异常)
那应该怎么解决呢?和上面一样,投影分解:

·BC范式(BCNF):符合3NF,并且,主属性不依赖于主属性(也就是不存在任何字段对任一候选关键字段的传递函数依赖)
BC范式既检查非主属性,又检查主属性。当只检查非主属性时,就成了第三范式。满足BC范式的关系都必然满足第三范式。
还可以这么说:若一个关系达到了第三范式,并且它只有一个候选码,或者它的每个候选码都是单属性,则该关系自然达到BC范式。
给你举个例子:假设仓库管理关系表 (仓库ID, 存储物品ID, 管理员ID, 数量),且有一个管理员只在一个仓库工作;一个仓库可以存储多种物品。
这个数据库表中存在如下决定关系:
(仓库ID, 存储物品ID) →(管理员ID, 数量)
(管理员ID, 存储物品ID) → (仓库ID, 数量)
所以,(仓库ID, 存储物品ID)和(管理员ID, 存储物品ID)都是StorehouseManage的候选关键字,表中的唯一非关键字段为数量,它是符合第三范式的。但是,由于存在如下决定关系:
(仓库ID) → (管理员ID)
(管理员ID) → (仓库ID)
即存在关键字段决定关键字段的情况,所以其不符合BCNF范式。它会出现如下异常情况:
(1) 删除异常:
当仓库被清空后,所有"存储物品ID"和"数量"信息被删除的同时,"仓库ID"和"管理员ID"信息也被删除了。
(2) 插入异常:
当仓库没有存储任何物品时,无法给仓库分配管理员。
(3) 更新异常:
如果仓库换了管理员,则表中所有行的管理员ID都要修改。
把仓库管理关系表分解为二个关系表:
仓库管理:StorehouseManage(仓库ID, 管理员ID);
仓库:Storehouse(仓库ID, 存储物品ID, 数量)。
这样的数据库表是符合BCNF范式的,消除了删除异常、插入异常和更新异常。
一般,一个数据库设计符合3NF或BCNF就可以了。在BC范式以上还有第四范式、第五范式。
·第四范式:要求把同一表内的多对多关系删除。
·第五范式:从最终结构重新建立原始结构。
其实数据库设计范式这方面重点掌握的就是1NF、2NF、3NF、BCNF
四种范式之间存在如下关系:
这里主要区别3NF和BCNF,一句话就是3NF是要满足不存在非主属性对候选码的传递函数依赖,BCNF是要满足不存在任一属性(包含非主属性和主属性)对候选码的传递函数依赖。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号