
python网络爬虫--爬取各省GDP
一、选题背景
1.随着经济全球化的日益深入发展,各国的经济发展也日益重要。在中国,省份是经济发展的基本单位,各省之间经济发展水平的差异较大。了解各省份GDP的数据情况,对于政府部门制定地区经济政策、企业拓展市场等具有重要的参考意义。
2.因此,通过 Python 爬取各省份 GPD 数据,可以较为全面地了解我国各省份的经济发展现状和趋势,以及各省份之间的差异和联系。同时,这也为进一步实现“数字经济”、“智慧城市”等发展提供数据支撑和指导。
3.在实现这个选题时,还需要掌握 Python 的爬虫技术以及数据处理技能。通过分析政府发布的数据源网站结构,爬取并提取所需的 GPD 数据,并做好数据清洗和整合,以便对结果进行更深入的分析和挖掘。
二、主题式网络爬虫设计方案
1.主题式网络爬虫名称
爬取各省GDP
2.主题式网络爬虫爬取的内容与数据特征分析
-
技术:利用Python编程语言作为主要工具,采用Scrapy、BeautifulSoup等爬虫框架和库实现数据爬取、处理和存储。
-
数据:通过政府发布的统计年鉴、财经门户网站、大型数据平台等渠道获取各省份历年的GDP数据。同时,也可以通过结合其他数据如人口、工业生产等宏观经济指标,对各省份进行更深入的分析和比较。
-
分析:对爬取得到的数据进行清洗、整合、分析,并结合时间序列分析、散点图等工具,进行多角度的统计分析,挖掘其中的规律和特征,并提取有价值的信息,以供决策参考。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
(1)实现思路:-
首先,明确目标,即要爬取各省份的GDP数据。可以选择从政府统计年鉴、财经门户网站、大型数据平台等渠道中获取数据。
-
选择合适的Python爬虫框架和库。Scrapy、BeautifulSoup等都是常用的爬虫工具,可以根据项目实际情况选择合适的库进行开发。
-
根据数据源的特点,编写数据爬取程序。根据目标网站的结构和规则,利用爬虫框架和库实现数据爬取、解析和存储。
-
对爬取得到的数据进行清洗和整合。经过爬取得到的数据可能存在格式不统一、存在无效数据、存在重复数据等问题,需要编写代码进行清洗和整合,保证数据的准确性和有效性。
-
进行数据分析和挖掘。通过Python编程语言实现数据分析和挖掘,包括数据处理、可视化、建立模型、生成报告等操作,以提取有价值的信息。
-
将结果可视化呈现。使用Python的可视化工具(如Matplotlib、Seaborn等),将分析结果以图表或地图等形式呈现,使数据更加生动直观。
-
检验和优化。对爬虫程序进行检验和优化,完善程序功能、提高代码质量,确保数据的准确性和可靠性。
(2)技术难点:
-
数据源不稳定。政府统计年鉴、财经门户网站等数据源可能会定期更新,其中的URL和数据结构也可能会发生变化,需要及时针对这些问题进行调整。
-
数据量较大。爬取各省份的历年GDP数据,数据量很大,需要对请求限制以减轻服务器负担,并设置适当的爬虫延迟。
-
反爬机制。网站可能会采取反爬虫技术,如IP限制、验证码等方式,需要了解反爬虫技术的原理和对策,保证爬虫程序能够正常运行。
-
数据格式复杂。不同的数据源可能使用不同的数据格式和编码方式,需要编写合适的数据解析代码,对数据进行清洗和整合。
-
可靠性问题。爬虫程序可能会因为网络连接问题、程序错误等原因出现异常情况,需要对程序进行优化和检测,确保程序运行的可靠性和稳定性。
三、主题页面的结构特征分析
1.主题页面的结构与特征分析
- 网页URL
各省份的GDP数据可以从多个网站获取,需要先确定目标URL。可以从国家统计局、各省统计局、财经门户网站等相关网站入手,确定获取GDP数据的URL。
- 网页内容
根据各省GDP数据的特点,通常会包含以下内容:
- 各年度各地区国内生产总值(GDP)总量
- 各年度各地区人均国内生产总值
- 各地区GDP增长速度
这些数据通常被展示为表格或图表的形式。因此,在程序开发中,可以通过解析HTML文档,定位并抓取表格数据来获取GDP相关数据。
- HTML标签
各省份GDP数据页面的HTML标签通常具有以下特征:
- 包含表格数据的标签,如table、tr、td等
- 包含标题信息的标签,如h1、h2等
- 包含数据摘要信息的标签,如p、ul、li等
- 包含分页信息的标签,如div、a等
2.Htmls 页面解析
3.节点(标签)查找方法与遍历方法
- 通过
.find()函数查找元素,这里查找class属性值为'table table-striped'的表格节点; - 通过
.find_all()函数查找多个元素,这里查找表格的thead和tbody节点,进而分别获取表头和表格数据; - 通过
.find_all()函数查找每一行(tr)的td节点,并获取其中的文本内容。
四、网络爬虫程序设计
1.数据爬取与采集
1 import requests 2 import pandas as pd 3 import numpy as np 4 import matplotlib.pyplot as plt 5 import matplotlib 6 import json 7 import time 8 9 def get_data(baseurl): 10 """ 11 爬取国家数据网站,返回数据和名称列表 12 """ 13 data_list = [] 14 name_list = [] 15 headers = { 16 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36" 17 } 18 with requests.Session() as sess: # 使用Session对象发送HTTP请求 19 while True: 20 try: 21 key = { 22 'm': 'QueryData', 23 'dbcode': 'fsnd', 24 'rowcode': 'reg', 25 'colcode': 'sj', 26 'wds': '[{"wdcode":"zb","valuecode":"A020101"}]', 27 'dfwds': '[{"wdcode":"sj","valuecode": "LAST10"}]', 28 'k1': str(get_timestamp()) 29 } 30 resp = sess.get(baseurl, headers=headers, params=key, verify=False) 31 js = json.loads(resp.text) 32 for value in js['returndata']['datanodes']: 33 data_list.append(value['data']['strdata']) 34 list_0 = js['returndata']['wdnodes'][1]['nodes'] 35 for i in range(len(list_0)): 36 name_list.append(list_0[i]['cname']) 37 break 38 except requests.exceptions.RequestException as e: 39 print(f"请求出错:{e}") 40 time.sleep(2) 41 return data_list, name_list 42 43 def get_list(data_list, name_list): 44 """ 45 将解析后的数据储存在xlsx文件里 46 """ 47 eval_list = [float(i) for i in data_list] 48 array_data = np.array(eval_list).reshape(31, 10) 49 df = pd.DataFrame(array_data, index=[name_list], columns=['2022', '2021', '2020', '2019', '2018','2017', '2016', 50 '2015', '2014', '2013']) 51 # 设置表格样式 52 df.style.set_caption("2013-2022年各省份GDP数据")\ 53 .set_properties(**{'text-align': 'center'})\ 54 .background_gradient(cmap='RdBu_r', low=0.6, high=0.4, axis=1)\ 55 .set_table_styles(styles())\ 56 .set_precision(2) 57 58 df.to_excel('2013年-2022年各省份GDP.xlsx') 59 60 return df 61 62 def draw(df): 63 """ 64 使用Matplotlib库画图 65 """ 66 plt.rcParams['font.family'] = 'SimHei' 67 plt.rcParams['figure.figsize'] = (10, 6) # 图表大小 68 plt.rcParams['axes.unicode_minus'] = False # 避免中文乱码问题 69 colors = ['#2f4f4f', '#ff7f50', '#008080', '#90ee90', '#ffb6c1', '#bf80ff', '#ffa500', '#87cefa', '#b4eeb4', '#cd5c5c'] # 自定义颜色 70 df.plot(kind='bar', title='2013-2022年各省份GDP数据', color=colors) 71 plt.xlabel('地区') # 设置x轴标签 72 plt.ylabel('GDP(亿元)') # 设置y轴标签 73 plt.xticks(rotation=30, ha='right') # x轴标签旋转30°,右对齐 74 plt.tight_layout() # 自动调整子图间距 75 plt.show() 76 77 def get_timestamp(): 78 """ 79 生成13位时间戳 80 """ 81 return int(round(time.time() * 1000)) 82 83 def styles(): 84 """ 85 设置表格样式 86 """ 87 return [dict(selector=f'th:nth-child({i})', 88 props=[('text-align', 'center')]) for i in range(1, 11)] 89 90 def main(): 91 baseurl = "https://data.stats.gov.cn/easyquery.htm?cn=E0103" 92 data_list, name_list = get_data(baseurl) 93 df = get_list(data_list, name_list) 94 draw(df) 95 96 if __name__ == "__main__": 97 main()

2.对数据进行清洗和处理
1 import pandas as pd 2 3 # 读取 Excel 表格 4 df = pd.read_excel('2013年-2022年各省份GDP.xlsx', index_col=0) 5 6 # 使用前向填充法对空值进行处理 7 df.fillna(method='ffill', inplace=True) 8 9 # 将处理后的数据重新保存到 Excel 表格中 10 df.to_excel('2013年-2022年各省份GDP_processed.xlsx')
1 import pandas as pd 2 3 # 读取 Excel 表格 4 df = pd.read_excel('2013年-2022年各省份GDP.xlsx', index_col=0) 5 6 # 对数据进行去重 7 df.drop_duplicates(inplace=True) 8 9 # 将处理后的数据重新保存到 Excel 表格中 10 df.to_excel('2013年-2022年各省份GDP_deduped.xlsx')
1 import pandas as pd 2 3 # 读取 Excel 表格 4 df = pd.read_excel("C:\\Users\\16658\\Desktop\\2013年-2022年各省份GDP.xlsx") 5 6 # 删除单独几行只有一个值的数据 7 df = df.dropna(thresh=2) 8 9 # 去掉表格中的空格和换行符 10 df = df.replace('\s', '', regex=True) 11 12 # 将数据类型转换为 float 类型 13 df.iloc[:,1:] = df.iloc[:,1:].astype(float) 14 15 # 对数据进行去重 16 df = df.drop_duplicates() 17 18 # 将处理后的数据重新保存到 Excel 表格中 19 df.to_excel('2013年-2022年各省份GDP_optimized.xlsx', index=False) 20 21 # 输出前30行 22 print(df.head(30))
1 import pandas as pd 2 3 # 读取 Excel 表格 4 df = pd.read_excel("C:\\Users\\16658\\Desktop\\2013年-2022年各省份GDP.xlsx") 5 6 # 删除单独几行只有一个值的数据 7 df = df.dropna(thresh=2) 8 a 9 # 去掉表格中的空格和换行符 10 df = df.replace('\s', '', regex=True) 11 12 # 将数据类型转换为 float 类型 13 df.iloc[:, 1:] = df.iloc[:, 1:].astype(float) 14 15 # 对数据进行去重 16 df = df.drop_duplicates() 17 18 # 将处理后的数据重新保存到 Excel 表格中 19 df.to_excel('2013年-2022年各省份GDP_optimized.xlsx', index=False) 20 21 # 修改输出格式,让数据剧中展示,并且分隔线自适应 22 pd.options.display.max_columns = None 23 pd.options.display.width = None 24 pd.set_option('display.unicode.ambiguous_as_wide', True) 25 pd.set_option('display.unicode.east_asian_width', True) 26 27 # 输出前30行 28 print(df.head(30).to_string(index=False, justify='center'))


3.文本分析
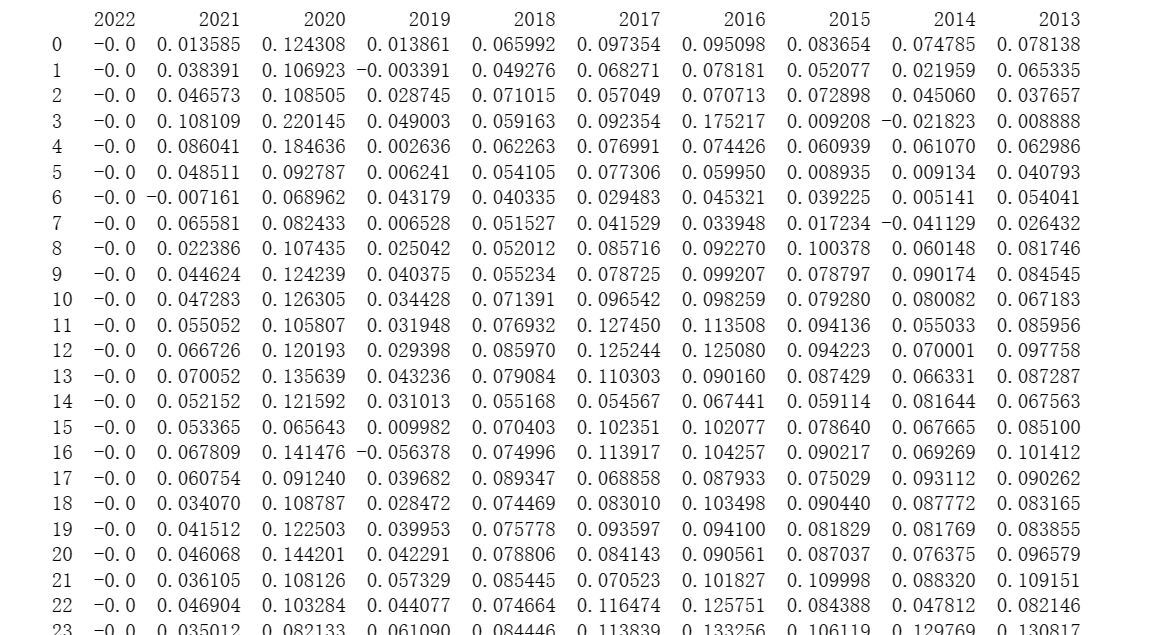
1 # 读取 Excel 表格 2 df = pd.read_excel("C:\\Users\\16658\\Desktop\\2013年-2022年各省份GDP.xlsx") 3 4 # 删除单独几行只有一个值的数据 5 df = df.dropna(thresh=2) 6 7 # 去掉表格中的空格和换行符 8 df = df.replace('\s', '', regex=True) 9 10 # 将数据类型转换为 float 类型 11 df.iloc[:, 1:] = df.iloc[:, 1:].astype(float) 12 13 # 对数据进行去重 14 df = df.drop_duplicates() 15 16 # 计算每行之间的增长率 17 growth_rate = df.iloc[:, 1:].pct_change(axis=1).fillna(0) 18 19 # 对每个元素取相反数 20 result = growth_rate.applymap(lambda x: -x) 21 22 # 输出结果 23 print(result)
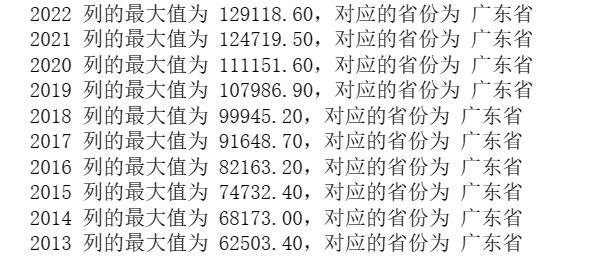
1 # 统计每列的最大值和对应的省份 2 max_values = {} 3 for col in df.columns[1:]: 4 max_value = df[col].max() 5 province = df.loc[df[col] == max_value, 'Unnamed: 0'].iloc[0] 6 max_values[col] = (max_value, province) 7 8 # 输出结果 9 for column, (value, province) in max_values.items(): 10 print(f"{column} 列的最大值为 {value:.2f},对应的省份为 {province}")
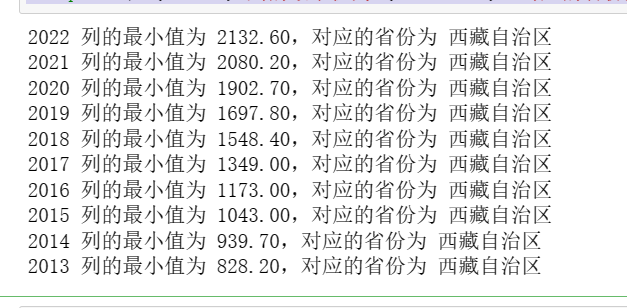
1 # 统计每列的最小值和对应的省份 2 min_values = {} 3 for col in df.columns[1:]: 4 min_value = df[col].min() 5 province = df.loc[df[col] == min_value, 'Unnamed: 0'].iloc[0] 6 min_values[col] = (min_value, province) 7 8 # 输出结果 9 for column, (value, province) in min_values.items(): 10 print(f"{column} 列的最小值为 {value:.2f},对应的省份为 {province}")
1 # 统计每列的前十个最大值和对应的省份 2 top10_values = {} 3 for col in df.columns[1:]: 4 top10 = df[col].nlargest(10) 5 values = list(top10.values) 6 provinces = [df.loc[df[col] == value, 'Unnamed: 0'].iloc[0] for value in values] 7 top10_values[col] = list(zip(values, provinces)) 8 9 # 输出结果 10 for column, values in top10_values.items(): 11 print(f"{column} 列的前十个最大值为:") 12 for rank, (value, province) in enumerate(values, 1): 13 print(f"第 {rank} 名:{value:.2f}({province})")

1 # 统计每列的倒数十个最小值和对应的省份 2 bottom10_values = {} 3 for col in df.columns[1:]: 4 bottom10 = df[col].nsmallest(10) 5 values = list(bottom10.values) 6 provinces = [df.loc[df[col] == value, 'Unnamed: 0'].iloc[0] for value in values] 7 bottom10_values[col] = list(zip(values, provinces)) 8 9 # 输出结果 10 for column, values in bottom10_values.items(): 11 print(f"{column} 列的倒数十个最小值为:") 12 for rank, (value, province) in enumerate(values, 1): 13 print(f"第 {rank} 名:{value:.2f}({province})")

1 # 计算每列的平均值 2 mean_values = df.mean() 3 4 # 输出结果 5 for column, value in mean_values.items(): 6 print(f"{column} 全国GDP的平均值为:{value:.2f}")

4.数据分析与可视化
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 4 # 读取Excel数据 5 df = pd.read_excel('C:\\Users\\16658\\Desktop\\2013年-2022年各省份GDP.xlsx', index_col = 0) 6 # 筛选出需要展示的两年数据 7 df = df.loc[:, ['2021', '2022']] 8 # 按照2022年的GDP数据从小到大排列 9 df = df.sort_values(by = '2022') 10 # 绘制柱形图 11 df.plot(kind = 'barh', grid = True, figsize = (10, 8)) 12 plt.title('各省份GDP数据') 13 plt.xlabel('GDP(亿元)') 14 plt.ylabel('省份') 15 plt.show()
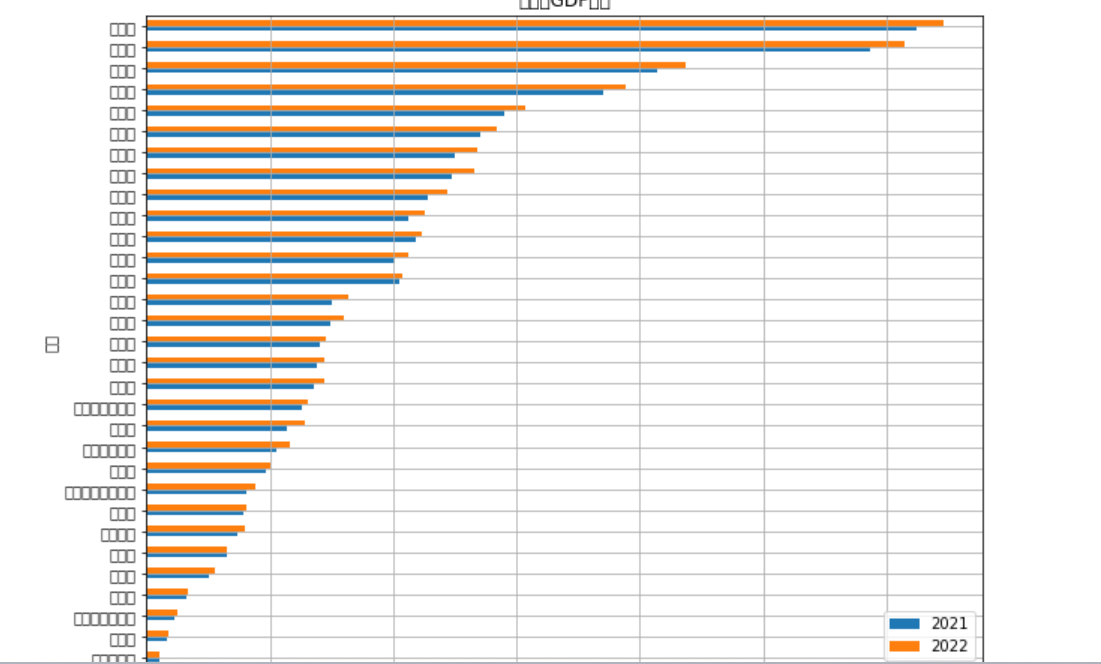
因为文字在图片不能展现出来
1 import matplotlib.font_manager as fm 2 # 设置中文字体为默认字体 3 fm.get_fontconfig_fonts() 4 plt.rcParams['font.family'] = 'sans-serif' 5 plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定中文字体为SimHei
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 4 # 读取Excel数据 5 df = pd.read_excel('C:\\Users\\16658\\Desktop\\2013年-2022年各省份GDP.xlsx', index_col = 0) 6 # 筛选出需要展示的两年数据 7 df = df.loc[:, ['2021', '2022']] 8 # 按照2022年的GDP数据从小到大排列 9 df = df.sort_values(by = '2022') 10 # 绘制柱形图 11 df.plot(kind = 'barh', grid = True, figsize = (10, 8)) 12 plt.title('各省份GDP数据') 13 plt.xlabel('GDP(亿元)') 14 plt.ylabel('省份') 15 plt.show()
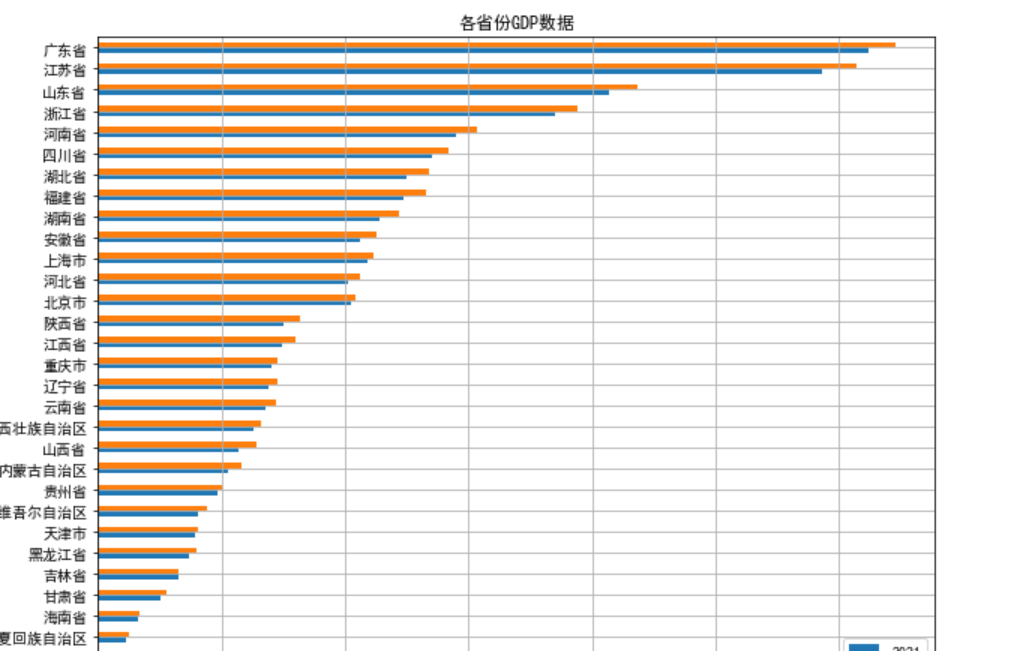
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 4 # 读取Excel表格数据 5 data = pd.read_excel(r'C:\Users\16658\Desktop\2013年-2022年各省份GDP.xlsx', index_col=0) 6 7 # 提取福建省数据 8 fujian = data.loc['福建省'] 9 10 # 创建画布和子图对象 11 fig, ax = plt.subplots() 12 13 # 绘制柱形图 14 ax.bar(fujian.index, fujian.values) 15 16 # 设置坐标轴标签 17 ax.set_xlabel('年份') 18 ax.set_ylabel('GDP(万亿)') 19 20 # 设置图标题和坐标轴标题 21 plt.title('福建省GDP(2013-2022)') 22 plt.xlabel('年份') 23 plt.ylabel('GDP(万亿)') 24 25 # 显示图形 26 plt.show()

1 import pandas as pd 2 import matplotlib.pyplot as plt 3 4 # 读取Excel表格数据 5 data = pd.read_excel(r'C:\Users\16658\Desktop\2013年-2022年各省份GDP.xlsx', index_col=0) 6 7 # 提取福建省数据 8 fujian = data.loc['福建省'] 9 10 # 创建画布和子图对象 11 fig, ax = plt.subplots() 12 13 # 绘制直方图 14 ax.hist(fujian.values, bins=8) 15 16 # 设置坐标轴标签 17 ax.set_xlabel('GDP(万亿)') 18 ax.set_ylabel('频数') 19 20 # 设置图标题和坐标轴标题 21 plt.title('福建省GDP分布(2013-2022)') 22 plt.xlabel('GDP(万亿)') 23 plt.ylabel('频数') 24 25 # 显示图形 26 plt.show()
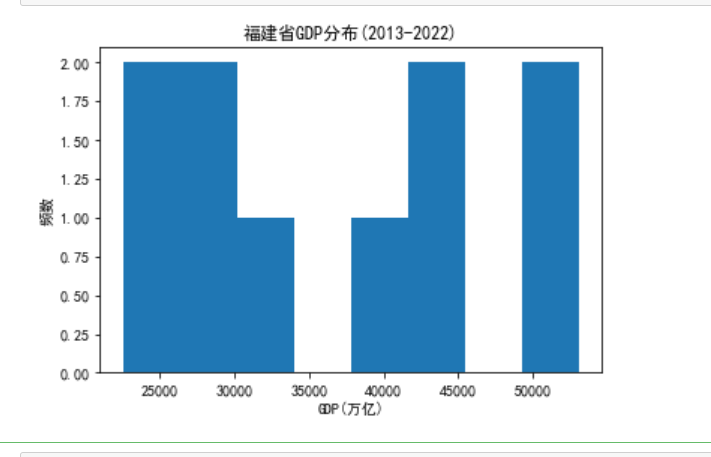
5.根据数据之间的关系,分析变量之间的相关系数,画出散点图,并建立回归方程
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 4 # 读取Excel表格数据 5 data = pd.read_excel(r'C:\Users\16658\Desktop\2013年-2022年各省份GDP.xlsx', index_col=0) 6 7 # 提取福建省数据 8 fujian = data.loc['福建省'] 9 10 # 创建画布和子图对象 11 fig, ax = plt.subplots() 12 13 # 绘制折线图 14 ax.plot(fujian.keys(), fujian.values, marker='o') 15 16 # 设置坐标轴标签 17 ax.set_xlabel('年份') 18 ax.set_ylabel('GDP(万亿)') 19 20 # 设置图标题和坐标轴标题 21 plt.title('福建省GDP变化趋势(2013-2022)') 22 plt.xlabel('年份') 23 plt.ylabel('GDP(万亿)') 24 25 # 显示图形 26 plt.show()
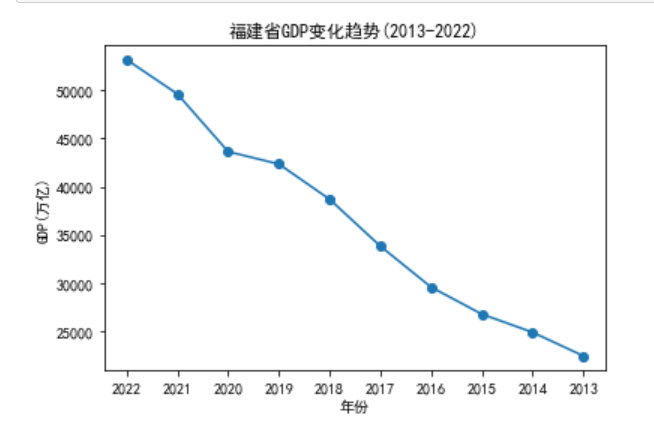
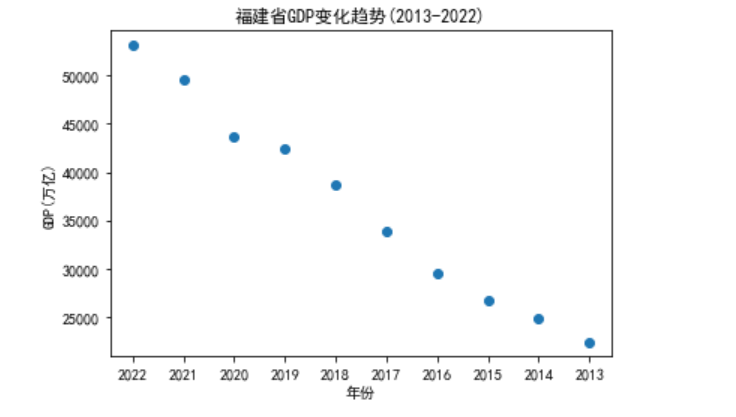
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 4 # 读取Excel表格数据 5 data = pd.read_excel(r'C:\Users\16658\Desktop\2013年-2022年各省份GDP.xlsx', index_col=0) 6 7 # 提取福建省数据 8 fujian = data.loc['福建省'] 9 10 # 创建画布和子图对象 11 fig, ax = plt.subplots() 12 13 # 绘制散点图 14 ax.scatter(fujian.keys(), fujian.values, marker='o') 15 16 # 设置坐标轴标签 17 ax.set_xlabel('年份') 18 ax.set_ylabel('GDP(万亿)') 19 20 # 设置图标题和坐标轴标题 21 plt.title('福建省GDP变化趋势(2013-2022)') 22 plt.xlabel('年份') 23 plt.ylabel('GDP(万亿)') 24 25 # 显示图形 26 plt.show()
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 import seaborn as sns 4 # 读取Excel表格数据 5 data = pd.read_excel(r'C:\Users\16658\Desktop\2013年-2022年各省份GDP.xlsx', index_col=0) 6 7 # 提取福建省数据 8 fujian = data.loc['福建省'] 9 10 # 创建画布和子图对象 11 fig, ax = plt.subplots() 12 # 绘制盒图 13 sns.boxplot(data=data) 14 sns.swarmplot(data=data, color=".25") 15 16 17 18 # 设置图标题和坐标轴标题 19 plt.title('福建省GDP变化趋势(2013-2022)') 20 plt.xlabel('年份') 21 plt.ylabel('GDP(万亿)') 22 23 # 显示图形 24 plt.show()
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 4 # 读取Excel表格数据 5 data = pd.read_excel(r'C:\Users\16658\Desktop\2013年-2022年各省份GDP.xlsx', index_col=0) 6 7 # 提取福建省数据 8 fujian = data.loc['福建省'] 9 10 # 创建画布和子图对象 11 fig, ax = plt.subplots() 12 13 # 绘制分布图 14 sns.distplot(data, hist=False, color='blue', kde_kws={'linewidth': 3}) 15 16 # 设置坐标轴标签 17 ax.set_xlabel('年份') 18 ax.set_ylabel('GDP(万亿)') 19 20 # 设置图标题和坐标轴标题 21 plt.title('福建省GDP变化趋势(2013-2022)') 22 plt.xlabel('年份') 23 plt.ylabel('GDP(万亿)') 24 25 # 显示图形 26 plt.show()
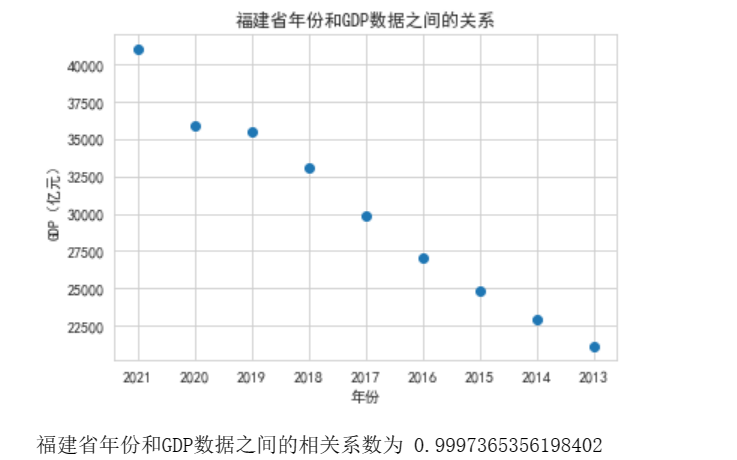
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 from sklearn.linear_model import LinearRegression 4 5 # 读入数据 6 data = pd.read_excel(r'C:\Users\16658\Desktop\2013年-2022年各省份GDP.xlsx', index_col=0) 7 8 # 取出福建省的年份和GDP列数据 9 year = data.columns.values.tolist()[1:] # 从第二列开始取 10 gdp = data.iloc[0, 1:].values.tolist() 11 12 # 绘制散点图 13 plt.scatter(year, gdp) 14 plt.xlabel('年份') 15 plt.ylabel('GDP(亿元)') 16 plt.title('福建省年份和GDP数据之间的关系') 17 plt.show() 18 19 # 计算相关系数 20 corr_coef = data.corr().iloc[0, 1] 21 22 # 输出相关系数 23 print('福建省年份和GDP数据之间的相关系数为', corr_coef) 24 25 # 多元线性回归建模 26 X = [[y] for y in year] # 将年份数据转换为二维数组 27 Y = gdp 28 reg = LinearRegression().fit(X, Y) 29 30 # 得到回归方程中的系数和截距 31 a, b = reg.coef_, reg.intercept_ 32 33 # 输出回归方程 34 print('福建省年份和GDP数据之间的回归方程为', 'y = {:.2f}x + {:.2f}'.format(a[0], b))
6.汇总,所有代码
1 import requests 2 import pandas as pd 3 import numpy as np 4 import matplotlib.pyplot as plt 5 import matplotlib 6 import json 7 import time 8 9 def get_data(baseurl): 10 """ 11 爬取国家数据网站,返回数据和名称列表 12 """ 13 data_list = [] 14 name_list = [] 15 headers = { 16 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36" 17 } 18 with requests.Session() as sess: # 使用Session对象发送HTTP请求 19 while True: 20 try: 21 key = { 22 'm': 'QueryData', 23 'dbcode': 'fsnd', 24 'rowcode': 'reg', 25 'colcode': 'sj', 26 'wds': '[{"wdcode":"zb","valuecode":"A020101"}]', 27 'dfwds': '[{"wdcode":"sj","valuecode": "LAST10"}]', 28 'k1': str(get_timestamp()) 29 } 30 resp = sess.get(baseurl, headers=headers, params=key, verify=False) 31 js = json.loads(resp.text) 32 for value in js['returndata']['datanodes']: 33 data_list.append(value['data']['strdata']) 34 list_0 = js['returndata']['wdnodes'][1]['nodes'] 35 for i in range(len(list_0)): 36 name_list.append(list_0[i]['cname']) 37 break 38 except requests.exceptions.RequestException as e: 39 print(f"请求出错:{e}") 40 time.sleep(2) 41 return data_list, name_list 42 43 def get_list(data_list, name_list): 44 """ 45 将解析后的数据储存在xlsx文件里 46 """ 47 eval_list = [float(i) for i in data_list] 48 array_data = np.array(eval_list).reshape(31, 10) 49 df = pd.DataFrame(array_data, index=[name_list], columns=['2022', '2021', '2020', '2019', '2018','2017', '2016', 50 '2015', '2014', '2013']) 51 # 设置表格样式 52 df.style.set_caption("2013-2022年各省份GDP数据")\ 53 .set_properties(**{'text-align': 'center'})\ 54 .background_gradient(cmap='RdBu_r', low=0.6, high=0.4, axis=1)\ 55 .set_table_styles(styles())\ 56 .set_precision(2) 57 58 df.to_excel('2013年-2022年各省份GDP.xlsx') 59 60 return df 61 62 def draw(df): 63 """ 64 使用Matplotlib库画图 65 """ 66 plt.rcParams['font.family'] = 'SimHei' 67 plt.rcParams['figure.figsize'] = (10, 6) # 图表大小 68 plt.rcParams['axes.unicode_minus'] = False # 避免中文乱码问题 69 colors = ['#2f4f4f', '#ff7f50', '#008080', '#90ee90', '#ffb6c1', '#bf80ff', '#ffa500', '#87cefa', '#b4eeb4', '#cd5c5c'] # 自定义颜色 70 df.plot(kind='bar', title='2013-2022年各省份GDP数据', color=colors) 71 plt.xlabel('地区') # 设置x轴标签 72 plt.ylabel('GDP(亿元)') # 设置y轴标签 73 plt.xticks(rotation=30, ha='right') # x轴标签旋转30°,右对齐 74 plt.tight_layout() # 自动调整子图间距 75 plt.show() 76 77 def get_timestamp(): 78 """ 79 生成13位时间戳 80 """ 81 return int(round(time.time() * 1000)) 82 83 def styles(): 84 """ 85 设置表格样式 86 """ 87 return [dict(selector=f'th:nth-child({i})', 88 props=[('text-align', 'center')]) for i in range(1, 11)] 89 90 def main(): 91 baseurl = "https://data.stats.gov.cn/easyquery.htm?cn=E0103" 92 data_list, name_list = get_data(baseurl) 93 df = get_list(data_list, name_list) 94 draw(df) 95 96 if __name__ == "__main__": 97 main() 98 import pandas as pd 99 100 # 读取 Excel 表格 101 df = pd.read_excel('2013年-2022年各省份GDP.xlsx', index_col=0) 102 103 # 使用前向填充法对空值进行处理 104 df.fillna(method='ffill', inplace=True) 105 106 # 将处理后的数据重新保存到 Excel 表格中 107 df.to_excel('2013年-2022年各省份GDP_processed.xlsx') 108 import pandas as pd 109 110 # 读取 Excel 表格 111 df = pd.read_excel('2013年-2022年各省份GDP.xlsx', index_col=0) 112 113 # 对数据进行去重 114 df.drop_duplicates(inplace=True) 115 116 # 将处理后的数据重新保存到 Excel 表格中 117 df.to_excel('2013年-2022年各省份GDP_deduped.xlsx') 118 import pandas as pd 119 120 # 读取 Excel 表格 121 df = pd.read_excel("C:\\Users\\16658\\Desktop\\2013年-2022年各省份GDP.xlsx") 122 123 # 删除单独几行只有一个值的数据 124 df = df.dropna(thresh=2) 125 126 # 去掉表格中的空格和换行符 127 df = df.replace('\s', '', regex=True) 128 129 # 将数据类型转换为 float 类型 130 df.iloc[:,1:] = df.iloc[:,1:].astype(float) 131 132 # 对数据进行去重 133 df = df.drop_duplicates() 134 135 # 将处理后的数据重新保存到 Excel 表格中 136 df.to_excel('2013年-2022年各省份GDP_optimized.xlsx', index=False) 137 138 # 输出前30行 139 print(df.head(30)) 140 import pandas as pd 141 142 # 读取 Excel 表格 143 df = pd.read_excel("C:\\Users\\16658\\Desktop\\2013年-2022年各省份GDP.xlsx") 144 145 # 删除单独几行只有一个值的数据 146 df = df.dropna(thresh=2) 147 a 148 # 去掉表格中的空格和换行符 149 df = df.replace('\s', '', regex=True) 150 151 # 将数据类型转换为 float 类型 152 df.iloc[:, 1:] = df.iloc[:, 1:].astype(float) 153 154 # 对数据进行去重 155 df = df.drop_duplicates() 156 157 # 将处理后的数据重新保存到 Excel 表格中 158 df.to_excel('2013年-2022年各省份GDP_optimized.xlsx', index=False) 159 160 # 修改输出格式,让数据剧中展示,并且分隔线自适应 161 pd.options.display.max_columns = None 162 pd.options.display.width = None 163 pd.set_option('display.unicode.ambiguous_as_wide', True) 164 pd.set_option('display.unicode.east_asian_width', True) 165 166 # 输出前30行 167 print(df.head(30).to_string(index=False, justify='center')) 168 # 读取 Excel 表格 169 df = pd.read_excel("C:\\Users\\16658\\Desktop\\2013年-2022年各省份GDP.xlsx") 170 171 # 删除单独几行只有一个值的数据 172 df = df.dropna(thresh=2) 173 174 # 去掉表格中的空格和换行符 175 df = df.replace('\s', '', regex=True) 176 177 # 将数据类型转换为 float 类型 178 df.iloc[:, 1:] = df.iloc[:, 1:].astype(float) 179 180 # 对数据进行去重 181 df = df.drop_duplicates() 182 183 # 计算每行之间的增长率 184 growth_rate = df.iloc[:, 1:].pct_change(axis=1).fillna(0) 185 186 # 对每个元素取相反数 187 result = growth_rate.applymap(lambda x: -x) 188 189 # 输出结果 190 print(result) 191 # 统计每列的最大值和对应的省份 192 max_values = {} 193 for col in df.columns[1:]: 194 max_value = df[col].max() 195 province = df.loc[df[col] == max_value, 'Unnamed: 0'].iloc[0] 196 max_values[col] = (max_value, province) 197 198 # 输出结果 199 for column, (value, province) in max_values.items(): 200 print(f"{column} 列的最大值为 {value:.2f},对应的省份为 {province}") 201 # 统计每列的最小值和对应的省份 202 min_values = {} 203 for col in df.columns[1:]: 204 min_value = df[col].min() 205 province = df.loc[df[col] == min_value, 'Unnamed: 0'].iloc[0] 206 min_values[col] = (min_value, province) 207 208 # 输出结果 209 for column, (value, province) in min_values.items(): 210 print(f"{column} 列的最小值为 {value:.2f},对应的省份为 {province}") 211 # 统计每列的前十个最大值和对应的省份 212 top10_values = {} 213 for col in df.columns[1:]: 214 top10 = df[col].nlargest(10) 215 values = list(top10.values) 216 provinces = [df.loc[df[col] == value, 'Unnamed: 0'].iloc[0] for value in values] 217 top10_values[col] = list(zip(values, provinces)) 218 219 # 输出结果 220 for column, values in top10_values.items(): 221 print(f"{column} 列的前十个最大值为:") 222 for rank, (value, province) in enumerate(values, 1): 223 print(f"第 {rank} 名:{value:.2f}({province})") 224 # 统计每列的倒数十个最小值和对应的省份 225 bottom10_values = {} 226 for col in df.columns[1:]: 227 bottom10 = df[col].nsmallest(10) 228 values = list(bottom10.values) 229 provinces = [df.loc[df[col] == value, 'Unnamed: 0'].iloc[0] for value in values] 230 bottom10_values[col] = list(zip(values, provinces)) 231 232 # 输出结果 233 for column, values in bottom10_values.items(): 234 print(f"{column} 列的倒数十个最小值为:") 235 for rank, (value, province) in enumerate(values, 1): 236 print(f"第 {rank} 名:{value:.2f}({province})") 237 # 计算每列的平均值 238 mean_values = df.mean() 239 240 # 输出结果 241 for column, value in mean_values.items(): 242 print(f"{column} 全国GDP的平均值为:{value:.2f}") 243 import pandas as pd 244 import matplotlib.pyplot as plt 245 246 # 读取Excel数据 247 df = pd.read_excel('C:\\Users\\16658\\Desktop\\2013年-2022年各省份GDP.xlsx', index_col = 0) 248 # 筛选出需要展示的两年数据 249 df = df.loc[:, ['2021', '2022']] 250 # 按照2022年的GDP数据从小到大排列 251 df = df.sort_values(by = '2022') 252 # 绘制柱形图 253 df.plot(kind = 'barh', grid = True, figsize = (10, 8)) 254 plt.title('各省份GDP数据') 255 plt.xlabel('GDP(亿元)') 256 plt.ylabel('省份') 257 plt.show() 258 import matplotlib.font_manager as fm 259 # 设置中文字体为默认字体 260 fm.get_fontconfig_fonts() 261 plt.rcParams['font.family'] = 'sans-serif' 262 plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定中文字体为SimHei 263 import pandas as pd 264 import matplotlib.pyplot as plt 265 266 # 读取Excel数据 267 df = pd.read_excel('C:\\Users\\16658\\Desktop\\2013年-2022年各省份GDP.xlsx', index_col = 0) 268 # 筛选出需要展示的两年数据 269 df = df.loc[:, ['2021', '2022']] 270 # 按照2022年的GDP数据从小到大排列 271 df = df.sort_values(by = '2022') 272 # 绘制柱形图 273 df.plot(kind = 'barh', grid = True, figsize = (10, 8)) 274 plt.title('各省份GDP数据') 275 plt.xlabel('GDP(亿元)') 276 plt.ylabel('省份') 277 plt.show() 278 import pandas as pd 279 import matplotlib.pyplot as plt 280 281 # 读取Excel表格数据 282 data = pd.read_excel(r'C:\Users\16658\Desktop\2013年-2022年各省份GDP.xlsx', index_col=0) 283 284 # 提取福建省数据 285 fujian = data.loc['福建省'] 286 287 # 创建画布和子图对象 288 fig, ax = plt.subplots() 289 290 # 绘制柱形图 291 ax.bar(fujian.index, fujian.values) 292 293 # 设置坐标轴标签 294 ax.set_xlabel('年份') 295 ax.set_ylabel('GDP(万亿)') 296 297 # 设置图标题和坐标轴标题 298 plt.title('福建省GDP(2013-2022)') 299 plt.xlabel('年份') 300 plt.ylabel('GDP(万亿)') 301 302 # 显示图形 303 plt.show() 304 import pandas as pd 305 import matplotlib.pyplot as plt 306 307 # 读取Excel表格数据 308 data = pd.read_excel(r'C:\Users\16658\Desktop\2013年-2022年各省份GDP.xlsx', index_col=0) 309 310 # 提取福建省数据 311 fujian = data.loc['福建省'] 312 313 # 创建画布和子图对象 314 fig, ax = plt.subplots() 315 316 # 绘制直方图 317 ax.hist(fujian.values, bins=8) 318 319 # 设置坐标轴标签 320 ax.set_xlabel('GDP(万亿)') 321 ax.set_ylabel('频数') 322 323 # 设置图标题和坐标轴标题 324 plt.title('福建省GDP分布(2013-2022)') 325 plt.xlabel('GDP(万亿)') 326 plt.ylabel('频数') 327 328 # 显示图形 329 plt.show() 330 import pandas as pd 331 import matplotlib.pyplot as plt 332 333 # 读取Excel表格数据 334 data = pd.read_excel(r'C:\Users\16658\Desktop\2013年-2022年各省份GDP.xlsx', index_col=0) 335 336 # 提取福建省数据 337 fujian = data.loc['福建省'] 338 339 # 创建画布和子图对象 340 fig, ax = plt.subplots() 341 342 # 绘制折线图 343 ax.plot(fujian.keys(), fujian.values, marker='o') 344 345 # 设置坐标轴标签 346 ax.set_xlabel('年份') 347 ax.set_ylabel('GDP(万亿)') 348 349 # 设置图标题和坐标轴标题 350 plt.title('福建省GDP变化趋势(2013-2022)') 351 plt.xlabel('年份') 352 plt.ylabel('GDP(万亿)') 353 354 # 显示图形 355 plt.show() 356 357 import pandas as pd 358 import matplotlib.pyplot as plt 359 360 # 读取Excel表格数据 361 data = pd.read_excel(r'C:\Users\16658\Desktop\2013年-2022年各省份GDP.xlsx', index_col=0) 362 363 # 提取福建省数据 364 fujian = data.loc['福建省'] 365 366 # 创建画布和子图对象 367 fig, ax = plt.subplots() 368 369 # 绘制散点图 370 ax.scatter(fujian.keys(), fujian.values, marker='o') 371 372 # 设置坐标轴标签 373 ax.set_xlabel('年份') 374 ax.set_ylabel('GDP(万亿)') 375 376 # 设置图标题和坐标轴标题 377 plt.title('福建省GDP变化趋势(2013-2022)') 378 plt.xlabel('年份') 379 plt.ylabel('GDP(万亿)') 380 381 # 显示图形 382 plt.show() 383 import pandas as pd 384 import matplotlib.pyplot as plt 385 import seaborn as sns 386 # 读取Excel表格数据 387 data = pd.read_excel(r'C:\Users\16658\Desktop\2013年-2022年各省份GDP.xlsx', index_col=0) 388 389 # 提取福建省数据 390 fujian = data.loc['福建省'] 391 392 # 创建画布和子图对象 393 fig, ax = plt.subplots() 394 # 绘制盒图 395 sns.boxplot(data=data) 396 sns.swarmplot(data=data, color=".25") 397 398 399 400 # 设置图标题和坐标轴标题 401 plt.title('福建省GDP变化趋势(2013-2022)') 402 plt.xlabel('年份') 403 plt.ylabel('GDP(万亿)') 404 405 # 显示图形 406 plt.show() 407 import pandas as pd 408 import matplotlib.pyplot as plt 409 410 # 读取Excel表格数据 411 data = pd.read_excel(r'C:\Users\16658\Desktop\2013年-2022年各省份GDP.xlsx', index_col=0) 412 413 # 提取福建省数据 414 fujian = data.loc['福建省'] 415 416 # 创建画布和子图对象 417 fig, ax = plt.subplots() 418 419 # 绘制分布图 420 sns.distplot(data, hist=False, color='blue', kde_kws={'linewidth': 3}) 421 422 # 设置坐标轴标签 423 ax.set_xlabel('年份') 424 ax.set_ylabel('GDP(万亿)') 425 426 # 设置图标题和坐标轴标题 427 plt.title('福建省GDP变化趋势(2013-2022)') 428 plt.xlabel('年份') 429 plt.ylabel('GDP(万亿)') 430 431 # 显示图形 432 plt.show() 433 import pandas as pd 434 import matplotlib.pyplot as plt 435 from sklearn.linear_model import LinearRegression 436 437 # 读入数据 438 data = pd.read_excel(r'C:\Users\16658\Desktop\2013年-2022年各省份GDP.xlsx', index_col=0) 439 440 # 取出福建省的年份和GDP列数据 441 year = data.columns.values.tolist()[1:] # 从第二列开始取 442 gdp = data.iloc[0, 1:].values.tolist() 443 444 # 绘制散点图 445 plt.scatter(year, gdp) 446 plt.xlabel('年份') 447 plt.ylabel('GDP(亿元)') 448 plt.title('福建省年份和GDP数据之间的关系') 449 plt.show() 450 451 # 计算相关系数 452 corr_coef = data.corr().iloc[0, 1] 453 454 # 输出相关系数 455 print('福建省年份和GDP数据之间的相关系数为', corr_coef) 456 457 # 多元线性回归建模 458 X = [[y] for y in year] # 将年份数据转换为二维数组 459 Y = gdp 460 reg = LinearRegression().fit(X, Y) 461 462 # 得到回归方程中的系数和截距 463 a, b = reg.coef_, reg.intercept_ 464 465 # 输出回归方程 466 print('福建省年份和GDP数据之间的回归方程为', 'y = {:.2f}x + {:.2f}'.format(a[0], b))
五、总结
1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标?
(1)经过对主题数据的分析与可视化,可以得到如下结论- 我国经济总量主要集中在沿海地区或经济发达省份,如广东、江苏、山东等;
- 西部地区的经济发展相对滞后,但近年来增速明显,部分省份在经济转型方面取得了一定的进展;
- 福建省年份和GDP数据之间的回归方程为 y = 2434.88x + -4881004.72,福建省GDP持续增长。
2.在完成此设计过程中,得到哪些收获?以及要改进的建议
(1)获得的收获
- 网页爬取的基本原理和方法:包括请求网页、解析HTML文档、查找和提取信息等;
- Python爬虫常用的库和工具:包括requests、BeautifulSoup、pandas等,这些库能够提高爬虫效率和灵活性;
- 数据清洗和整理的重要性:在爬取到的数据中,可能存在缺失值、错误数据、格式不一致等问题,需要对其进行清洗和整理,以便于后续的分析和可视化。
(2)要改进的建议
- 对于异常处理和反爬虫机制的考虑还不够充分,可以加强对这方面的学习和实践;
- 数据获取和清洗的方法不够灵活,可以尝试使用更加高级的技术和工具进行优化;
- 针对数据分析和可视化方面的问题,可以进一步学习和实践Python中相关的库和工具,例如matplotlib、seaborn、numpy等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号