Linux 复习1
问:makefile 文件的作用
makefile文件保存了编译器和连接器的参数选项,表述了所有源文件的关系,是整个工程的编译规则,一旦写好,只需要一个make命令,整个工程就自动编译完成,极大的提高了效率
// main是最终生成的可执行文件名,即就是最终的要生成的目标文件(大Boss)。
main : main.o test.o list.o vector.o <在此必须一个TAB键> gcc -o main main.o test.o list.o vector.o main.o : main.c <在此必须一个TAB键>gcc -c main.c test.o : test.c <在此必须一个TAB键>gcc -c test.c list.o : list.c <在此必须一个TAB键>gcc -c list.c vector.o : vector.c <在此必须一个TAB键>gcc -c vector.c clean: <在此必须一个TAB键>rm *.o main
问: 什么是库文件
答:本质上说 库文件是可执行的二进制文件,可直接被操作系统载入内存执行,是提前编译好的方法,分为静态库和动态库,一般放在/lib 或者/usr/lib中
静态库以.a后缀,程序在编译链接的时候,会将库中的代码链接复制到可执行文件中,程序运行时,不再需要动态库,当删掉.a库文件,程序还可以运行
生成静态库:ar -cr libtest.a test.o 调试: gcc -o main main.c -L(路径) -ltest.a (引用库)
动态库以.so后缀,程序在运行的时候才会去,链接动态库的方法,在运行的时候加载到内存,这个操作是操作系统完成,称为动态链接
生成动态库:gcc --shared -fPIC -o libtest.so test.o
静态库和动态库的差异:
不同:
1.动态库是运行时系统调用库函数实现链接,代码较小巧,
而静态库是在链接时复制到代码中,代码量较庞大,冗余度高。
2.正因为静态库这种方式也决定了她,在链接后不再依赖静态库存在,及即使静态库被删除程序依然可以正常运行,可移植性强。
而动态库因为是利用本机的库函数,所以可能移植到其他电脑会出现运行bug等问题,可移植性差。
3.他俩的区别在于链接过程的差异,和代码被载入的时刻不同
4.动态库必须放在指定的目录下完成链接,而静态库给出链接文件路径即可
相同:
1.库文件中都不可以出现主mian函数
2.这些库都是提供函数接口,满足功能的,不暴露源代码 3.目的增加代码复用,可共享性,减小冗余
问:fork 复制进程的过程
答:当fork函数被调用时,内核会在物理内存中开辟新的一个PCB tast_struct结构体,将父进程的结构体中的内容复制到子进程中,并修改部分内容,然后为子进程分配堆栈,并分配唯一的pid进程标识符,插入进程队列中,fork之后,物理内存相同,虚拟地址空间不同,子进程只有读的权限,当任意一方进程出现写权限时,内核才会将需要修改的页复制出来,提高效率。
问:什么是僵死进程?处理方法
答:当子进程先于父进程结束时,或者exit系统调用时,内核会释放进程的所有存取区,关闭掉打开的文件描述符,但是保存了进程PCB信息,而父进程并为调用wait()或者waitpid()来获取这些信息,导致pid和内核栈无法释放,意味着海量的子进程会导致资源被消耗完,无法在进行fork()。
解决办法: 父进程调用wait()函数,获取子进程结束信息,或者让父进程先结束,交给一号进程init托管,也可以设置信号处理函数,当收到信号时调用wait()等待子进程结束
让父进程先结束的方法:fork两次 父进程fork出子进程调用wait()然后子进程在fork出子孙进程后,立即exit(),此时父进程的wait()接收 ,而子孙进程交给init托管
问:写实拷贝的作用
答:内核为新生成的子进程,只创建虚拟地址空间,不立即分配物理内存,共享父进程的物理内存,只有当任意进程出现数据修改时,才会将数据所在页复制出来,分配对应的物理段,如果出现像fork+ececl 若直接复制物理内存,大大浪费了资源,降低了效率。
问: 了解进程控制块吗?
答:PCB实际上是一个结构体,放在sched.h文件中 其中包括了1 pid(进程标识符)2 处理机制 3 进程调度信息 4 进程控制信息 PCB的管理方式有链式管理和索引管理
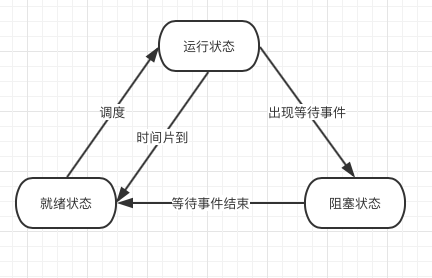
问:进程的状态转移图?
问:并发并行的区别?
答:并发运行是指,多个进程或者线程,交替进行,在某个时刻上,也只有一个进程被调度,并行运行,是一种特殊的并发,可以同步执行,硬件上必须多核
问:然后调试跟踪子进程
答:在GDB调试时,使用set follow-fork-mode child 必须在fork 之前设置,设置完后父进程无法单步执行,直接run 完 然后子进程会单步执行,当有多个子进程的时候,需要添加循环因子控制 如:if i==3 set follow-fork-mode child 跟踪第三个子进程 set follow-fork-mode parent 跟踪父进程
问:什么是文件描述符?
答:Linux就是一个文件管理系统,当打开文件时或者socket,系统就会返回一个文件描述符,文件描述符是一个低级的整数,前3个(0,1,2)表示,标准输入stdin 标准输出stdout 标准错误stderr,每个进程都有一个文件描述符表,当进程打开文件时,系统会给分配最小的fd 来表示,一般Linux文件描述符为1024个
问: 文件共享
答:父子进程共享了文件偏移量
问:系统调用和库函数的区别
答:系统调用是系统本身底层的接口,面向底层软件,通过系统调用,可以使程序和底层硬件交互,是系统的一部分,而使用系统调用,会影响系统性能,会从用户态到内核态,处理完成又返回用户态,为了减小开销,应减少系统调用。而库函数是将写好的方法提供给别人使用,面向应用开发,是语言或者程序的一部分,
库函数的调用在用户空间执行,属于用户时间,而系统调用在内核空间,开销属于内核时间,开销较大
系统调用依赖平台,而库函数不依赖
问:系统调用的过程?
- 程序调用libc库中的封装函数
- 调用软中断int 0X80 进入内核态
- 在内核中执行system_call 函数,将系统调用号,和所有寄存器放到相应的堆栈中,接着用系统调用号在系统调用表中查找到对应服务,
- 执行服务
- 转入ret_from_sys_call 服务,从系统调用结束
问:内核态用户态区别?
答:特权级是对用户态和内核态一个很好的区别,当程序运行在3级特权级以上,称为用户态,这是最低的级别,当程序运行在0级特权级上时,为内核态

 浙公网安备 33010602011771号
浙公网安备 33010602011771号