
测试-1.0
FILM(Image Fusion via Vision-Language Model)方法实现步骤分析
本文提出的 FILM 方法通过结合视觉-语言模型(VLM)的语义理解能力,将文本信息引入图像融合任务,以增强对深层语义特征的利用。以下是其具体实现步骤:
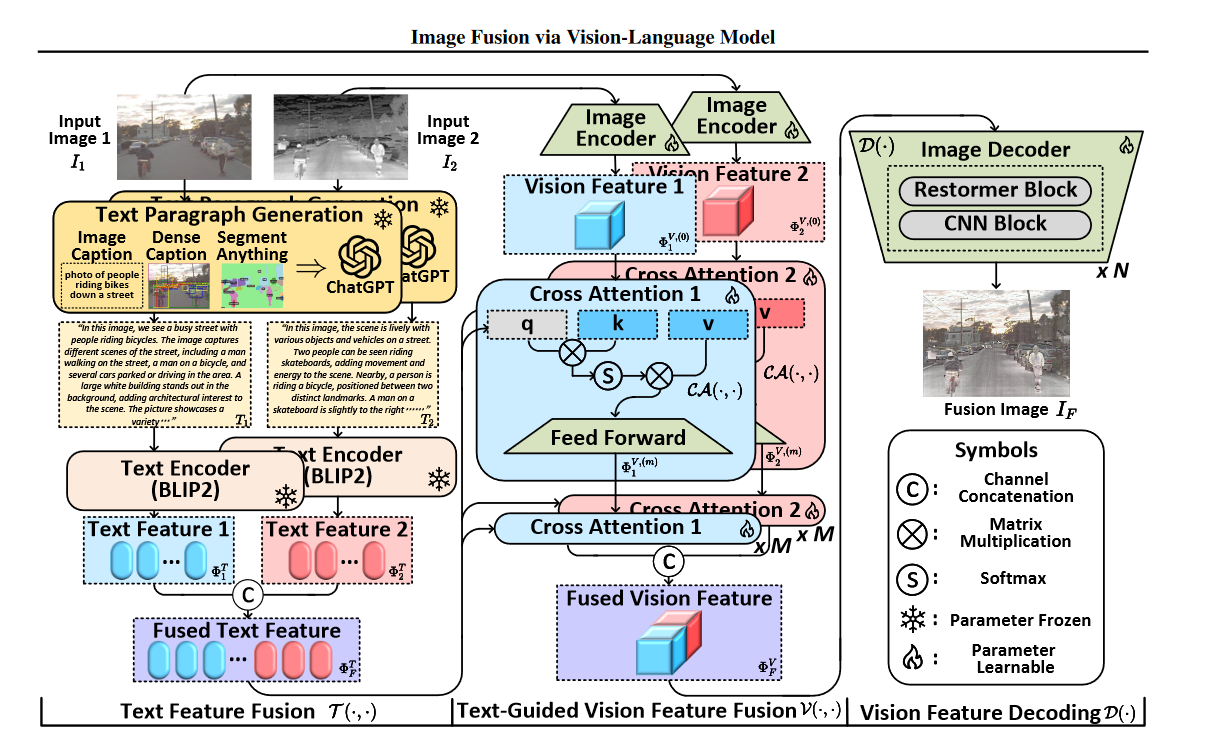
1. 文本特征融合(Text Feature Fusion)
- 输入:源图像对$ I_1 $$ 和 $$ I_2 $(如红外-可见光、医学、多曝光、多焦点图像)。
- 步骤:
- 多粒度语义提示生成:
- 整体描述:使用 BLIP2 模型生成图像描述(Image Caption),提供全局语义信息。
- 密集描述:通过 GRIT 模型生成密集描述(Dense Caption),捕捉物体级细节。
- 语义掩码:利用 Segment Anything 模型生成语义掩码(Semantic Mask),提取像素级语义。
- 文本描述生成:将上述三种语义提示输入 ChatGPT,生成针对每张源图像的详细段落描述 $ T_1 $$ 和 $$ T_2 $。
- 文本特征编码与融合:
- 使用 参数冻结的BLIP2 的文本编码器 将 $ T_1 $$ 和 $$ T_2 $ 编码为文本特征 $ \Phi_1^T $$ 和 $$ \Phi_2^T $。
- 通过通道拼接(Channel Concatenation)融合为统一文本特征 $ \Phi_F^T $。
- 多粒度语义提示生成:
2. 语言引导的视觉特征融合(Language-Guided Vision Feature Fusion)
- 输入:融合后的文本特征 $ \Phi_F^T $、源图像 $ I_1 $$ 和 $$ I_2 $。
- 步骤:
- 浅层视觉特征提取:
- 源图像通过 Restormer 和 CNN 块 组成的编码器,生成初始视觉特征 $ \Phi_1^{V,(0)} $$ 和 $$ \Phi_2^{V,(0)} $。
- 跨注意力机制(Cross-Attention):
- 文本引导特征增强:将文本特征 $ \Phi_F^T $ 作为查询(Query),视觉特征作为键(Key)和值(Value),通过多级交叉注意力模块迭代增强视觉特征:
$ \Phi_1^{V,(m)} = \mathcal{CA}\left(\Phi_F^T, \Phi_1^{V,(m-1)}\right) \quad (m=1,\dots,M) $ - 最终得到增强后的视觉特征 $ \Phi_1^{V,(M)} $$ 和 $$ \Phi_2^{V,(M)} $。
- 值得注意的是交叉注意力中的前馈神经网络是由Restormer块实现的。
- 文本引导特征增强:将文本特征 $ \Phi_F^T $ 作为查询(Query),视觉特征作为键(Key)和值(Value),通过多级交叉注意力模块迭代增强视觉特征:
- 视觉特征融合:将两路视觉特征拼接,生成融合后的视觉特征 $ \Phi_F^V $。
- 浅层视觉特征提取:
3. 视觉特征解码(Vision Feature Decoding)
- 输入:融合后的视觉特征 $ \Phi_F^V $。
- 步骤:
- 解码器结构:由 Restormer 和 CNN 块 组成的解码器逐步重建图像。
- 图像生成:通过多层解码块将 $ \Phi_F^V $ 映射为最终融合图像 $ I_F $。
关键技术细节
- 跨模态对齐:跨注意力机制将文本语义信息注入视觉特征,确保融合过程关注关键区域(如红外图像的热辐射区域或医学图像的病灶区域)。
- 损失函数设计:
- 强度损失(\(\mathcal{L}_{\text{int}}\)):确保融合图像与源图像的强度分布一致。
- 梯度损失(\(\mathcal{L}_{\text{grad}}\)):保留边缘和纹理细节。
- 结构相似性损失(\(\mathcal{L}_{\text{SSIM}}\)):优化视觉感知质量。
- 数据集构建:提出 VLF 数据集,包含 ChatGPT 生成的文本描述,涵盖 8 个数据集(如 MSRS、Harvard Medical 等),支持多任务训练与评估。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号