
Python学习之基本数据类型
运算符
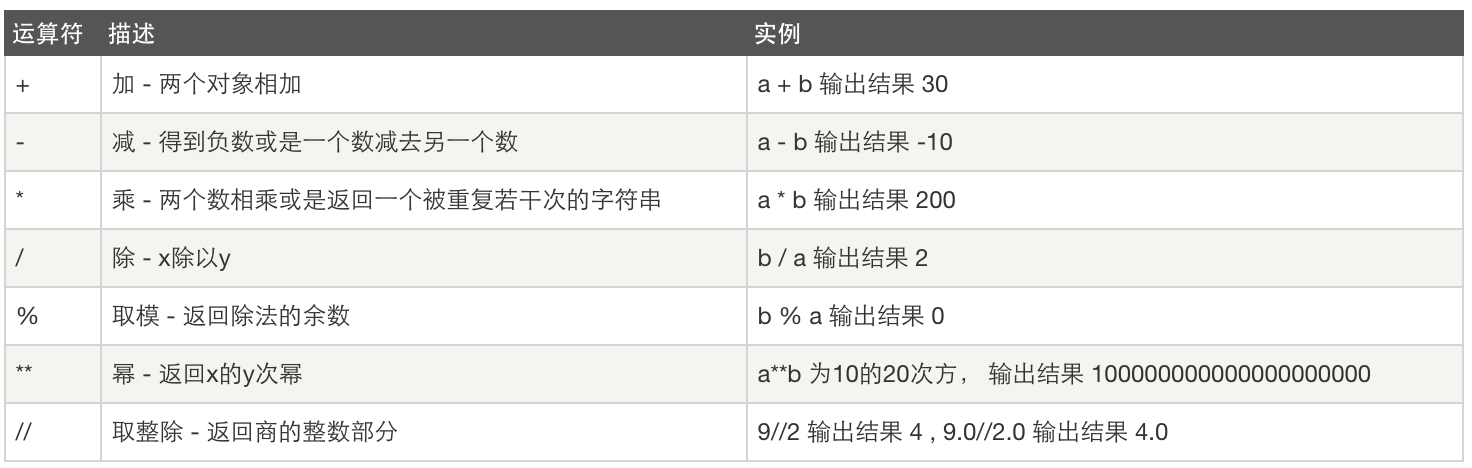
- 算数运算
- 比较运算

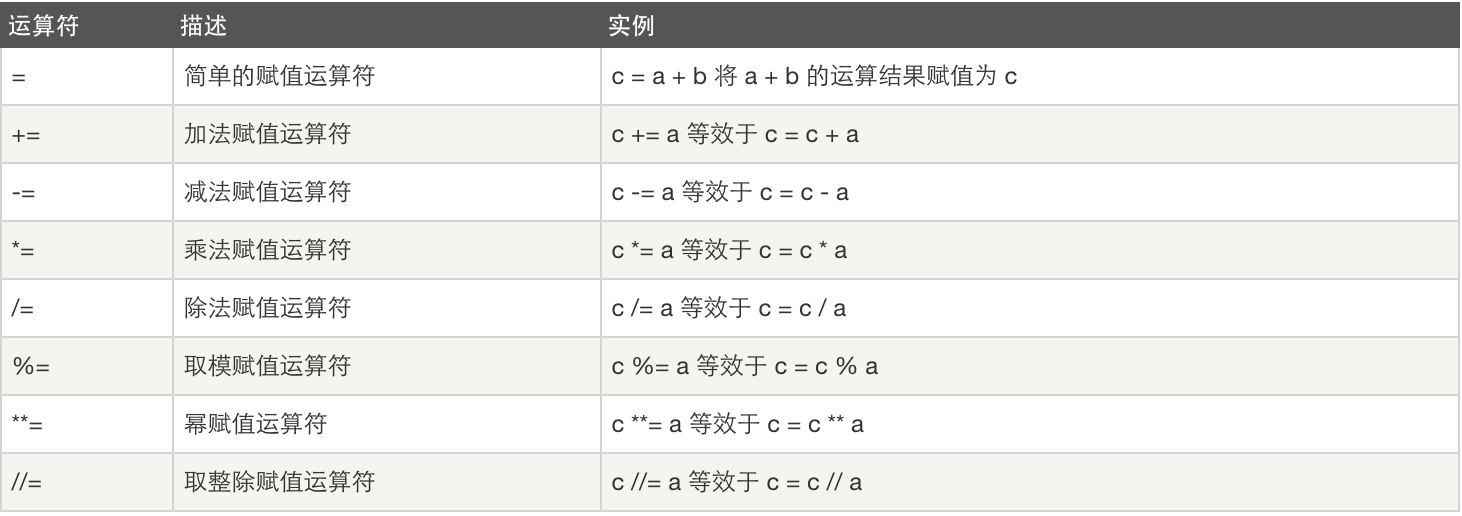
- 赋值运算
- 逻辑运算

- 成员运算

基本数据类型
- 数字
#int整型 定义:age=10 #age=int(10) 用于标识:年龄,等级,身份证号等等 #float浮点型 定义:salary=3.1 #salary=float(3.1) 用于标识:工资,身高,体重等


#int(整型) 在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647 在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807 #long(长整型) 跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。 注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。 注意:在Python3里不再有long类型了,全都是int >>> a= 2**64 >>> type(a) #type()是查看数据类型的方法 <type 'long'> >>> b = 2**60 >>> type(b) <type 'int'> #complex复数型 >>> x=1-2j >>> x.imag -2.0 >>> x.real 1.0
- 布尔值
True or False #1或0
- 字符串
#在python中,加了引号的字符就是字符串类型 实例:name='lay' #name = str('lay')
实例: msg = "My name is Lay, i'm 18 years old!" msg = ''' 窗前明月光, 疑似地上霜, 举头望明月, 低柔思故乡。 ''' print(msg)
#1.按索引取值(正向取+反向取) #2.切片(左闭右开) #3.长度len #4.成员运算in和not in #5.移除空白strip #6.分列split
#1、strip,lstrip,rstrip #2、lower,upper #3、startswith,endswith #4、format的三种玩法 #5、split,rsplit #6、join #7、replace #8、isdigit
#strip name='*egon**' print(name.strip('*')) print(name.lstrip('*')) print(name.rstrip('*')) #lower,upper name='egon' print(name.lower()) print(name.upper()) #startswith,endswith name='alex_SB' print(name.endswith('SB')) print(name.startswith('alex')) #format的三种玩法 res='{} {} {}'.format('egon',18,'male') res='{1} {0} {1}'.format('egon',18,'male') res='{name} {age} {sex}'.format(sex='male',name='egon',age=18) #split name='root:x:0:0::/root:/bin/bash' print(name.split(':')) #默认分隔符为空格 name='C:/a/b/c/d.txt' #只想拿到顶级目录 print(name.split('/',1)) name='a|b|c' print(name.rsplit('|',1)) #从右开始切分 #join tag=' ' print(tag.join(['egon','say','hello','world'])) #可迭代对象必须都是字符串 #replace name='alex say :i have one tesla,my name is alex' print(name.replace('alex','SB',1)) #isdigit:可以判断bytes和unicode类型,是最常用的用于于判断字符是否为"数字"的方法 age=input('>>: ') print(age.isdigit())
- 列表
#列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。 #列表的数据项不需要具有相同的类型 #创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。
#1、按索引存取值(正向存取+反向存取):即可存也可以取 #2、切片(顾头不顾尾,步长) #3、长度 #4、成员运算in和not in #5、追加 #6、删除 #7、循环
参考:列表
- 元祖
#元组使用小括号,列表使用方括号 #区别:存多个值,对比列表来说,不同之处在于元组的元素不能修改。
参考:元祖
- 字典
#字典是另一种可变容器模型,且可存储任意类型对象。 #字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中
参考:字典
- 集合
#集合(set)是一个无序的不重复元素序列。 #可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
#1、长度len #2、成员运算in和not in #3、|合集 #4、&交集 #5、-差集 #6、^对称差集 #7、== #8、父集:>,>= #9、子集:<,<=
1. 有列表l=['a','b',1,'a','a'],列表元素均为可hash类型,去重,得到新列表,且新列表无需保持列表原来的顺序 2.在上题的基础上,保存列表原来的顺序 3.去除文件中重复的行,肯定要保持文件内容的顺序不变 4.有如下列表,列表元素为不可hash类型,去重,得到新列表,且新列表一定要保持列表原来的顺序 l=[ {'name':'egon','age':18,'sex':'male'}, {'name':'alex','age':73,'sex':'male'}, {'name':'egon','age':20,'sex':'female'}, {'name':'egon','age':18,'sex':'male'}, {'name':'egon','age':18,'sex':'male'}, ]
参考:集合

 浙公网安备 33010602011771号
浙公网安备 33010602011771号