在计算机早期,都是由一台主机承担全部存储和计算工作,这种方式被称为集中处理。后来随着处理器发展和网络出现,衍生出客户机/服务器架构,即由服务器完成主要的存储计算工作,客户机则负责较弱的存储计算和显示工作。到了今天,客户机的角色未变,但是存储计算工作已经不是单台服务器所能承载,需要由一堆服务器共同完成,这也就是通常说的集群架构。
现在我们所说的分布式计算,主要是指集群架构下的分布式计算工作。这种工作要求从某个客户机节点出发,将一个计算工作分割成若干小的子任务,分配给多台服务器节点去处理,并从这些服务器获得结果的计算过程。
由于分布式计算整合了大量计算机,处理效果远超单点计算,自带高性能和高效率光环,这些年随着各行业加速向数字化转移,产生的数据越来越多,数据业务复杂度也在同步增加,促使各行业对计算性能和计算效率的要求越来越高,必须使用分布式计算来完成日益庞大和复杂的计算工作。
所有分布式计算,抛开各种分布式计算模型表面的包装,回归计算本质,都可以分解成“分散”和“聚合”两个动作,执行顺序是先分散再聚合。更加复杂的,为了提高分布式计算效率,会运用迭代技术,持续将上阶段计算结果传输给下个阶段,滚动地进行分散计算和聚合计算,最终得出计算结果。
在分散和聚合基础上,已经衍生出许多分布式计算模型,比如谷歌的MapReduce,就属于比较简单的分布式计算模型,最初是用在它的搜索引擎上,后来也被Hadoop采用,用于大数据处理。Spark的分布式计算模型就复杂一些,因为它能够同时操作多个Map任务和Reduce任务一起工作。Laxcus更进一步,将分布式计算和计算机硬件整合起来,发展成一个分布式操作系统,它的分布式软件工具包(DSDK)里面,针对不同的分布式计算业务,封装了多种分布式计算模型,同样它也提供可以迭代运行技术,支持持续地处理分布式计算。
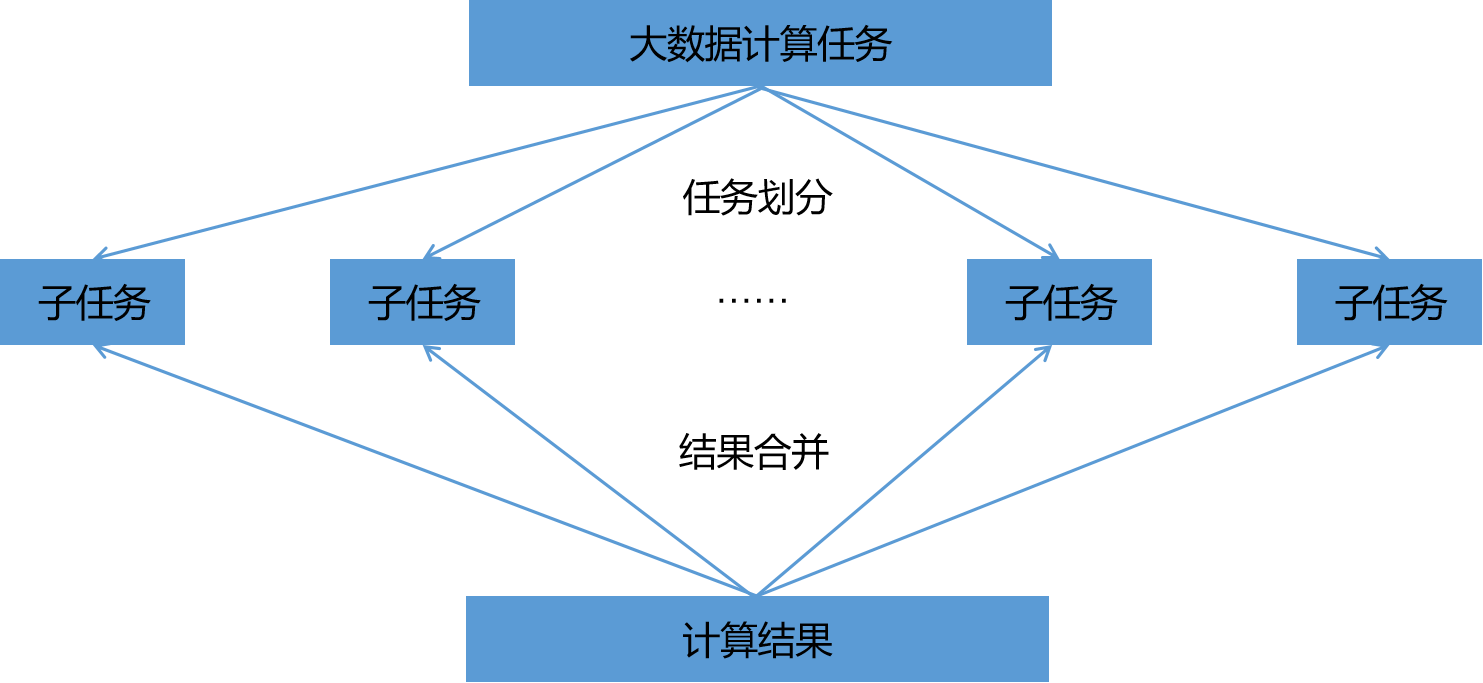
(基本是最简单的分布式计算)
分布式计算的“分散”,指的是从一个节点出发,把指令或者数据传递到多个节点上运行,按照某种计算规则,驱动这些节点生成计算结果。“聚合”是对结果数据的编排和汇总,根据不同的需求,聚合又分为对数据本身的聚合和对元数据的聚合。
对数据本身的聚合比较容易理解,就是把相同性质的数据放到一起进行处理。比如MPP数据库,当Select执行Group by和Order by操作时,就需要先提取多个节点上的同质数据,经过汇集后,再进行分组计算和排序计算。
元数据的聚合通常发生在数据聚合前,这是一种预处理操作,要求按照某种预定的规则,对不同性质的数据进行分区。分区后产生的对原来数据集合的映射,就是元数据。
元数据产生在迭代计算过程中,这种数据属于中间数据,被用来做为输入提供给下个阶段使用。元数据现在被各种分布式计算模型普遍使用,因为这些分布式计算模型都需要提高计算效率,最后都统一了选择这种小样本管理大数据的策略。
面对不同的业务,元数据的格式和内容虽然多种多样,但是有两个参数是必须具有的:1. 标记元数据唯一性的散列码。2. 产生元数据的节点。这两个参数保证分布式计算过程中,每一块数据都能够被定位和识别。
现在各种分布式计算框架,基本都提供元数据编程接口,允许开发者自己定义元数据。象Laxcus集群操作系统,它的分布式软件开发工具包里面,每套分布式计算模型都有对应的元数据编程接口,同样也支持开发者在即有规则上,定义自己的元数据规范。这样做,即简化了开发分布式应用软件的难度,也给开发者带来更多灵活性和开发便利。
为了更好地提升计算效率和节省计算资源,所有分布式计算模型都会建议开发者采用“移动计算”,减少“移动数据计算”。这个概念现在很少有人提及,但是非常重要,所以要说一说。
移动计算就是在产生数据本身的节点上进行计算,移动数据计算需要把数据搬运到指定的目标节点上,再进行计算工作。相比移动数据计算,移动计算省略了数据在网络中的传输开销,计算效率会大大提高。
但是完全摆脱移动数据计算也是不可能的,因为分布计算过程中,一旦涉及数据的编组、排列、汇总等计算工作,就需要把若干节点的数据传递到指定的目标节点上,网络数据传输工作不可避免。目前很多分布式计算执行过程中,相当大的一部分时间会被数据传输占用,而计算工作处于空置状态,所以为了减少时延提高计算效率,各种分布式计算模型也在用各种办法改进网络通信效率。
在改善网络通信效率方面,尤其以Laxcus做得最为出色。它提供了一套类似5G Massive MIMO的多通道传输技术,同时还有人工智能技术辅助管控通信设备和网络流量,数据传输的稳定性可靠性非常高。在对比测试中,在网络基础环境不变情况下,它比更早期不支持多通道的数据传输,改进后的通信效率能够提升5-20倍。这是一种非常有前景的技术,也是目前所有分布式计算模型中独树一帜的。

(多点连接,多通道并行,数据传输效果会更好)
现在的分布式计算,无论是理论、技术,还是产品和使用上,都已经日臻完善。它的未来发展趋势,正在以肉眼可见的速度,快速向软件化方向,特别是当Laxcus这样的分布式操作系统出现后,由于有了统一和标准化的基础平台,更容易部署和使用分布式应用软件。目前这股发展趋势已经非常明显,象高速空气流体、基因工程、生物医药、人工智能的计算工作,都重度依赖大规模分布式计算和它的基础平台。一旦分布式计算全面应用软件化,整个市场都会发生巨大变化。这些好处,我总结一下,大概有以下三点:
1. 有了统一的标准平台,就意味着,只是操作系统不改变,应用软件放在哪里都可以运行。不象现在各家云服务商自己建立一套,导致互相不兼容,应用软件迁移难度非常大。而企业如果不上云,就需要自己搭建基础平台,建设成本非常高。
2. 分布式应用软件的开发会更加规范,同时也意味着开发成本更低,这方面可以参考安卓、IOS、Windows上的开发经验。
3. 形成生态,产生更大的新的市场。分布式应用在没有软件化之前,主要以解决方案的方式出现,这种模式重度依赖特定企业和特定目标群体,无论开发成本还是使用成本都非常高,而且市场容量有限。现在有了分布式操作系统,应用软件的开发工作可以快速下沉到个体开发者。以当前分布式计算蓬勃的发展势头,一旦把海量个体开发者群体纳入进来,与市场上各种需求对接,形成用户与开发者的良性互动,就会出现供需市场。当用户有了更多更丰富的分布式应用软件可供选择,市场就会发展起来,最终通过市场规模的持续扩大,就会形成分布式应用生态。同理参考这十年手机生态的发展历程。
所以说,分布式计算的发展趋势是应用软件化和生态化,也是它的最终形态。
未来结果如何,各位拭目以待吧!欢迎大家在下方评论!
(Laxcus集群操作系统桌面,类似Windows,客户端远程操控集群上运行的分布式应用软件)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号