
2022-6.824-Lab4:ShardKV
0. 准备工作
lab 地址:https://pdos.csail.mit.edu/6.824/labs/lab-shard.html
github 地址:https://github.com/lawliet9712/MIT-6.824
该 Lab 主要目的是构建一个键/值存储系统,该系统对一组副本组上的键进行“分片”或分区。分片是键/值对的子集;例如,所有以“a”开头的键可能是一个分片,所有以“b”开头的键都是另一个分片,等等。分片的原因是性能。每个副本组仅处理几个分片的放置和获取,并且这些组并行操作;因此,总系统吞吐量(每单位时间的输入和获取)与组数成比例增加。
您的分片键/值存储将有两个主要组件。首先,一组副本组。每个副本组负责分片的一个子集。副本由少数服务器组成,这些服务器使用 Raft 来复制组的分片。第二个组件是“分片控制器”。分片控制器决定哪个副本组应该为每个分片服务;此信息称为配置。配置随时间变化。客户端咨询分片控制器以找到密钥的副本组,而副本组咨询控制器以找出要服务的分片。整个系统只有一个分片控制器,使用 Raft 作为容错服务实现。
分片存储系统必须能够在副本组之间转移分片。一个原因是一些组可能比其他组负载更多,因此需要移动分片来平衡负载。另一个原因是副本组可能会加入和离开系统:可能会添加新的副本组以增加容量,或者现有的副本组可能会因维修或退役而脱机。
因此主要需要实现 2 个 Part,一个是 ShardCtrler,即分片控制器。另一个是 ShardKV,负责处理键值存储,同时需要支持分片迁移的功能。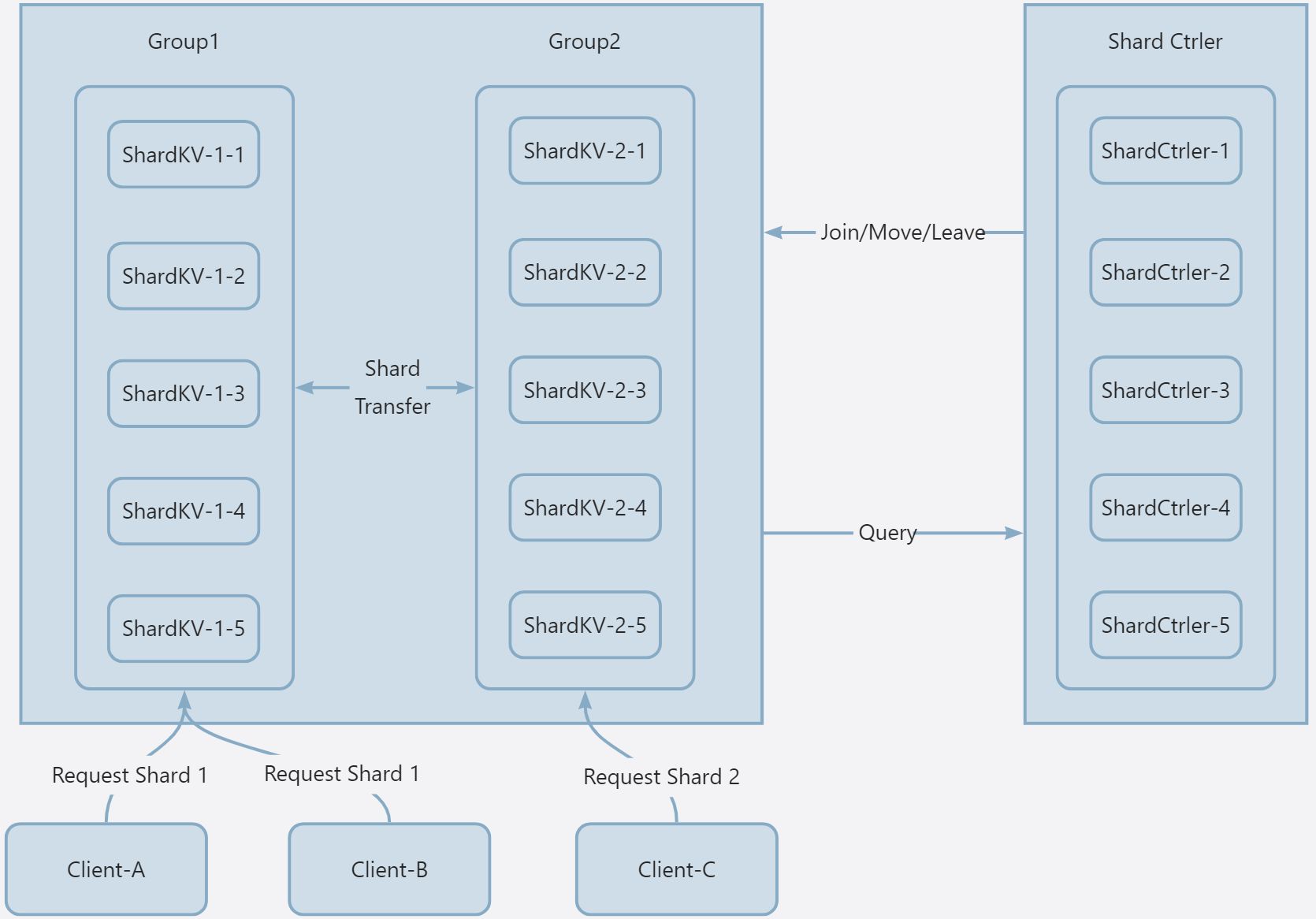
ShardCtrler 和 KVServer 都采用 Raft 来保证可靠性和安全性,其中 ShardKV 本质上功能与 lab3 的 KVRaft 差不多,可以认为多组 ShardKV 组成的功能与 KVRaft 是一致的,只是分片可以提升 DB 的性能(将请求分摊到不同 Group)。
1. ShardCtrler
1.1 分析
ShardCtrler 管理一系列编号的配置。每个配置都描述了一组副本组和分片到副本组的分配。每当此分配需要更改时,分片控制器都会使用新分配创建新配置。键/值客户端和服务器在想要了解当前(或过去)配置时联系 shardctrler。我们主要完成 4 个 RPC:
- Query:查询指定配置
- Join:添加一组新的 Group
- Leave:删除一组 Group
- Move:移动某块切片
每次执行 Join/Leave/Move 都会创建一个新的配置,并且分配新的配置编号(递增),初始会有一个空闲的配置,随着配置增加而变化,大致如下: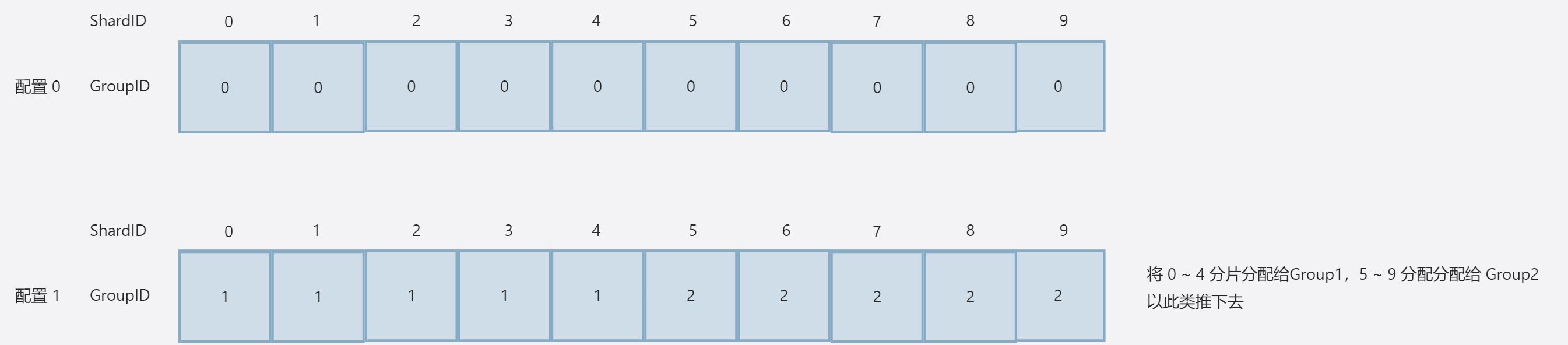
每一组配置的结构如上图所示,Code 如下:
// The number of shards.
const NShards = 10
// A configuration -- an assignment of shards to groups.
// Please don't change this.
type Config struct {
Num int // config number
Shards [NShards]int // shard -> gid
Groups map[int][]string // gid -> servers[]
}
ShardCtrler 会用数组保存所有的 Config 变更记录,RPC 主要变更的是 Shards 所属的 Group。这里需要注意一点,Move/Join/Leave 的时候:新配置应尽可能将分片均匀地分配到整组组中,并应移动尽可能少的分片以实现该目标。
因此我们需要设计合理的 rebalance 算法来满足上面的条件。其他实现与 KVRaft 差不多,需要防止重复执行请求(SeqId 机制)
1.2 实现
1.2.1 RPC 参数结构
type JoinArgs struct {
Servers map[int][]string // new GID -> servers mappings
SeqId int
CkId int64
}
type JoinReply struct {
WrongLeader bool
Err Err
}
type LeaveArgs struct {
GIDs []int
SeqId int
CkId int64
}
type LeaveReply struct {
WrongLeader bool
Err Err
}
type MoveArgs struct {
Shard int
GID int
SeqId int
CkId int64
}
type MoveReply struct {
WrongLeader bool
Err Err
}
type QueryArgs struct {
Num int // desired config number
SeqId int
CkId int64
}
type QueryReply struct {
WrongLeader bool
Err Err
Config Config
}
1.2.2 RPC Wait & Notify
RPC 的接受处理流程与 KVRaft 类似,都是收到请求 -> Start 投递到 Raft 层 -> 等待响应 -> 返回给客户端
func (sc *ShardCtrler) WaitApplyMsgByCh(ck *ShardClerk) (Op, bool) {
startTerm, _ := sc.rf.GetState()
timer := time.NewTimer(120 * time.Millisecond)
for {
select {
case Msg := <-ck.messageCh:
return Msg, false
case <-timer.C:
curTerm, isLeader := sc.rf.GetState()
if curTerm != startTerm || !isLeader {
sc.mu.Lock()
ck.msgUniqueId = 0
sc.mu.Unlock()
return Op{}, true
}
timer.Reset(120 * time.Millisecond)
}
}
}
func (sc *ShardCtrler) NotifyApplyMsgByCh(ch chan Op, Msg Op) {
// we wait 200ms
// if notify timeout, then we ignore, because client probably send request to anthor server
timer := time.NewTimer(120 * time.Millisecond)
select {
case ch <- Msg:
DPrintf("[ShardCtrler-%d] NotifyApplyMsgByCh finish , Msg=%v", sc.me, Msg)
return
case <-timer.C:
DPrintf("[ShardCtrler-%d] NotifyApplyMsgByCh Msg=%v, timeout", sc.me, Msg)
return
}
}
1.2.3 Query
func (sc *ShardCtrler) Query(args *QueryArgs, reply *QueryReply) {
// Your code here.
sc.mu.Lock()
DPrintf("[ShardCtrler-%d] Received Req [Query] args=%v", sc.me, args)
logIndex, _, isLeader := sc.rf.Start(Op{
SeqId: args.SeqId,
Command: T_Query,
CkId: args.CkId,
})
if !isLeader {
reply.WrongLeader = true
DPrintf("[ShardCtrler-%d] not leader, Req [Move] args=%v", sc.me, args)
sc.mu.Unlock()
return
}
ck := sc.GetCk(args.CkId)
ck.msgUniqueId = logIndex
sc.mu.Unlock()
_, WrongLeader := sc.WaitApplyMsgByCh(ck)
sc.mu.Lock()
defer sc.mu.Unlock()
reply.WrongLeader = WrongLeader
reply.Config = sc.getConfig(args.Num)
DPrintf("[ShardCtrler-%d] Clerk-%d Do [Query] Reply Config=%v", sc.me, args.CkId, reply)
}
1.2.4 Join
func (sc *ShardCtrler) Join(args *JoinArgs, reply *JoinReply) {
// Your code here.
sc.mu.Lock()
DPrintf("[ShardCtrler-%d] Received Req [Join] args=%v", sc.me, args)
logIndex, _, isLeader := sc.rf.Start(Op{
Servers: args.Servers,
SeqId: args.SeqId,
Command: T_Join,
CkId: args.CkId,
})
if !isLeader {
reply.WrongLeader = true
DPrintf("[ShardCtrler-%d] Received Req [Join] args=%v, not leader, return", sc.me, args)
sc.mu.Unlock()
return
}
ck := sc.GetCk(args.CkId)
ck.msgUniqueId = logIndex
DPrintf("[ShardCtrler-%d] Wait Req [Join] args=%v, ck.msgUniqueId = %d", sc.me, args, ck.msgUniqueId)
sc.mu.Unlock()
_, WrongLeader := sc.WaitApplyMsgByCh(ck)
DPrintf("[ShardCtrler-%d] Wait Req [Join] Result=%v", sc.me, WrongLeader)
reply.WrongLeader = WrongLeader
}
1.2.5 Leave
func (sc *ShardCtrler) Leave(args *LeaveArgs, reply *LeaveReply) {
// Your code here.
sc.mu.Lock()
DPrintf("[ShardCtrler-%d] Received Req [Leave] args=%v", sc.me, args)
logIndex, _, isLeader := sc.rf.Start(Op{
GIDs: args.GIDs,
SeqId: args.SeqId,
Command: T_Leave,
CkId: args.CkId,
})
if !isLeader {
reply.WrongLeader = true
DPrintf("[ShardCtrler-%d] Received Req [Leave] args=%v, not leader, return", sc.me, args)
sc.mu.Unlock()
return
}
ck := sc.GetCk(args.CkId)
ck.msgUniqueId = logIndex
DPrintf("[ShardCtrler-%d] Wait Req [Leave] args=%v ck.msgUniqueId=%d", sc.me, args, ck.msgUniqueId)
sc.mu.Unlock()
_, WrongLeader := sc.WaitApplyMsgByCh(ck)
reply.WrongLeader = WrongLeader
DPrintf("[ShardCtrler-%d] Wait Req [Leave] Result=%v", sc.me, WrongLeader)
}
1.2.6 Move
func (sc *ShardCtrler) Move(args *MoveArgs, reply *MoveReply) {
// Your code here.
sc.mu.Lock()
DPrintf("[ShardCtrler-%d] Received Req [Move] args=%v", sc.me, args)
logIndex, _, isLeader := sc.rf.Start(Op{
Shard: args.Shard,
GID: args.GID,
SeqId: args.SeqId,
Command: T_Move,
CkId: args.CkId,
})
if !isLeader {
reply.WrongLeader = true
sc.mu.Unlock()
return
}
ck := sc.GetCk(args.CkId)
ck.msgUniqueId = logIndex
sc.mu.Unlock()
_, WrongLeader := sc.WaitApplyMsgByCh(ck)
reply.WrongLeader = WrongLeader
}
1.2.7 Raft 层 Msg 处理
与 KVRaft 基本类似。
func (sc *ShardCtrler) processMsg() {
for {
applyMsg := <-sc.applyCh
opMsg := applyMsg.Command.(Op)
_, isLeader := sc.rf.GetState()
sc.mu.Lock()
ck := sc.GetCk(opMsg.CkId)
// already process
DPrintf("[ShardCtrler-%d] Received Msg %v, Isleader=%v", sc.me, applyMsg, isLeader)
if applyMsg.CommandIndex == ck.msgUniqueId && isLeader {
DPrintf("[ShardCtrler-%d] Ready Notify To %d Msg %v, msgUniqueId=%d", sc.me, opMsg.CkId, applyMsg, ck.msgUniqueId)
sc.NotifyApplyMsgByCh(ck.messageCh, opMsg)
DPrintf("[ShardCtrler-%d] Notify To %d Msg %v finish ... ", sc.me, opMsg.CkId, applyMsg)
ck.msgUniqueId = 0
}
if opMsg.SeqId < ck.seqId {
DPrintf("[ShardCtrler-%d] already process Msg %v finish ... ", sc.me, applyMsg)
sc.mu.Unlock()
continue
}
ck.seqId = opMsg.SeqId + 1
sc.invokeMsg(opMsg)
sc.mu.Unlock()
}
}
func (sc *ShardCtrler) invokeMsg(Msg Op) {
DPrintf("[ShardCtrler-%d] Do %s, Msg=%v, configs=%v", sc.me, Msg.Command, Msg, sc.getConfig(-1))
switch Msg.Command {
case T_Join: // add a set of groups
latestConf := sc.getConfig(-1)
newGroups := make(map[int][]string)
// merge new group
for gid, servers := range Msg.Servers {
newGroups[gid] = servers
}
// merge old group
for gid, servers := range latestConf.Groups {
newGroups[gid] = servers
}
// append new config
config := Config{
Num: len(sc.configs),
Groups: newGroups,
Shards: latestConf.Shards,
}
sc.configs = append(sc.configs, config)
// maybe need rebalance now
sc.rebalance()
case T_Leave: // delete a set of groups
latestConf := sc.getConfig(-1)
newGroups := make(map[int][]string)
for gid, servers := range latestConf.Groups {
// not in the remove gids, then append to new config
if !xIsInGroup(gid, Msg.GIDs) {
newGroups[gid] = servers
}
}
// append new config
config := Config{
Num: len(sc.configs),
Groups: newGroups,
Shards: latestConf.Shards,
}
sc.configs = append(sc.configs, config)
sc.rebalance()
case T_Move:
latestConf := sc.getConfig(-1)
config := Config{
Num: len(sc.configs),
Groups: latestConf.Groups,
Shards: latestConf.Shards,
}
config.Shards[Msg.Shard] = Msg.GID // no need rebalance
sc.configs = append(sc.configs, config)
case T_Query:
// nothing to do
default:
DPrintf("[ShardCtrler-%d] Do Op Error, not found type, Msg=%v", sc.me, Msg)
}
}
1.2.8 Re-Balance Shard 算法
在 Move/Join/Leave 中都需要对切片进行重分配,因此都需要进行一次 Re-Balance 操作,思路大致如下:
- 收集已经无效的 Shard(所属组已经被删除迁移的,或者未被分配的)
- 获取持有 Shard 多余平均线的 Group
- 获取持有 Shard 少于平均线的 Group
- 先将持有 Shard 少于平均线的 Group 分配一些空闲的 Shard
- 如果都平均拥有 Shard 了,则剩下的 Shard 再平均分配
这里主要需要注意,map 是无序的,遍历的时候可能不同节点处理的顺序不同,会造成结果不一致,因此采用 sort.Ints 对 Group ID 进行排序再进行分配,尽量保证一致。
func (sc *ShardCtrler) rebalance() {
// rebalance shard to groups
latestConf := sc.getConfig(-1)
// if all groups leave, reset all shards
if len(latestConf.Groups) == 0 {
for index, _ := range latestConf.Shards {
latestConf.Shards[index] = InvalidGroup
}
DPrintf("[ShardCtrler-%d] not groups, rebalance result=%v, sc.config=%v", sc.me, latestConf.Shards, sc.configs)
return
}
// step 1 : collect invalid shard
gids := sc.getGIDs()
idleShards := make([]int, 0)
// 1st loop collect not distribute shard
for index, belongGroup := range latestConf.Shards {
// not alloc shard or shard belong group already leave
if belongGroup == InvalidGroup || !xIsInGroup(belongGroup, gids) {
idleShards = append(idleShards, index)
}
}
// 2nd loop collect rich groups
avgShard := (len(latestConf.Shards) / len(gids))
richShards, poorGroups := sc.collectRichShardsAndPoorGroups(gids, avgShard)
DPrintf("[ShardCtrler-%d] rebalance avgShard=%d idleShards=%v, richShards=%v, poorGroups=%v latestConf=%v", sc.me, avgShard, idleShards, richShards, poorGroups, latestConf)
idleShards = append(idleShards, richShards...)
sort.Ints(idleShards)
allocIndex, i := 0, 0
// To prevent differnt server have diff result, sort it
poorGIDs := make([]int, 0)
for gid := range poorGroups {
poorGIDs = append(poorGIDs, gid)
}
sort.Ints(poorGIDs)
for _, gid := range poorGIDs {
groupShardsNum := poorGroups[gid]
for i = allocIndex; i < len(idleShards); i++ {
groupShardsNum += 1
latestConf.Shards[idleShards[i]] = gid
if groupShardsNum > avgShard {
break
}
}
allocIndex = i
}
// 3rd alloc left shard
for ; allocIndex < len(idleShards); allocIndex++ {
i = allocIndex % len(gids)
latestConf.Shards[idleShards[allocIndex]] = gids[i]
}
sc.configs[len(sc.configs)-1] = latestConf
DPrintf("[ShardCtrler-%d] rebalance result=%v, sc.config=%v", sc.me, latestConf.Shards, sc.getConfig(-1))
}
1.3 测试结果
该 Part 比较简单,直接贴下测试结果:
➜ shardctrler git:(main) ✗ go test -race
Test: Basic leave/join ...
... Passed
Test: Historical queries ...
... Passed
Test: Move ...
... Passed
Test: Concurrent leave/join ...
... Passed
Test: Minimal transfers after joins ...
... Passed
Test: Minimal transfers after leaves ...
... Passed
Test: Multi-group join/leave ...
... Passed
Test: Concurrent multi leave/join ...
... Passed
Test: Minimal transfers after multijoins ...
... Passed
Test: Minimal transfers after multileaves ...
... Passed
Test: Check Same config on servers ...
... Passed
PASS
ok 6.824/shardctrler 4.708s
2. ShardKV
接下来是 Lab4 的重头戏,需要实现 ShardKV,对比 KVRaft,主要要额外实现 Shard 数据迁移。该 Part 我主要分为两个部分:
- KV 部分,主要逻辑与 KVRaft 类似
- ShardTransfer 部分,负责切片迁移
对于 KV 部分不再赘述,而 Shard 迁移部分,根据 Lab 说明,Shard 迁移需要 Server 之间自主迁移。
2.1 分析
首先要发现 Shard 发生迁移,需要定时轮询 ShardCtrler,检查当前 Group 的 Shard 是否有发生变更(新的 Shard 加入,已有的 Shard 离开),设计了一个 ShardContainer 结构来管理 Join 和 Leave 的 Shard
type ShardContainer struct {
RetainShards []int
TransferShards []int
WaitJoinShards []int
ConfigNum int
QueryDone bool
ShardReqSeqId int // for local start raft command
ShardReqId int64 // for local start a op
}
一个 Group 的 Shard 主要分为三块:
- RetainShards:当前持有的 Shard
- TransferShards:当前正在迁移的 Shard
- WaitJoinShards:等待加入的 Shard
Shard 的迁移可以分为两种方式:
- A 检查到持有的 Shard 正在迁移到 B,由 A 主动发送 Shard 数据给 B
- B 检查到有新的 Shard 正在准备加入,由 B 主动从 A 拉取 Shard 数据
这里选择使用前者。定时检查配置变更的思路流程如下,新增一个 Goroutine 来定时轮询 ShardCtrler,请求当前 Container 中 ConfigNum 的 Config,ConfigNum 初始值为 1,ConfigNum 每次递增 1,其递增的时机如下:
- 当前 Group 没有等待加入或者正在迁移的 Shard,即
len(shardContainer.TransferShards) == 0 && len(shardContainer.WaitJoinShards) == 0 - 为了区分加入的 Shard 是初始化分配的还是需要等待其他组分配的,这里判断如果 ConfigNum 为 1 则执行 ShardInit,分配的切片不需要等待其他组传输数据就可用来处理请求
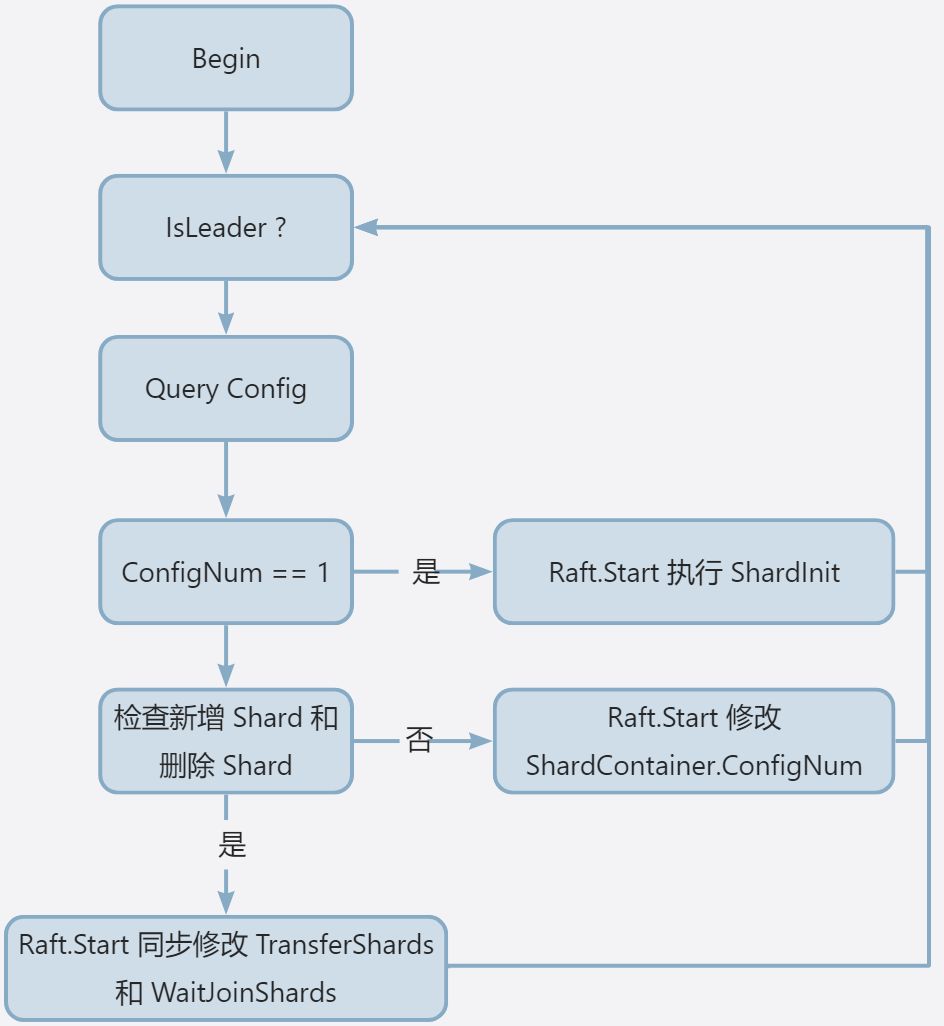
迁移 Shard 的思路如下,主要将迁移分为两步:
- 检查配置有没有需要迁移的 Shard,通过 Raft.Start 来同步哪些 Shard 需要迁移,接收到 Raft 层结果后,再发起 RPC 请求,当 RPC 请求通过时,再通过 Raft.Start 发起一个迁移完毕的 Command。
- 接收到 Raft 层迁移结束的 Command 后,清空
shardContainer.TransferShards
总体来说,需要 Raft 层同步的 Command 有如下:
- ShardInit:执行初始化切片,在轮询的配置编号为 1 时发起
- ShardConf:单纯递增 ConfigNum,在当前配置没有需要迁移或者等待加入的 Shard 时发起
- ShardChange:轮询配置时,发现有迁移或者等待加入的 Shard 时发起
- ShardLeave:删除 Shard,在处理 ShardChange 消息时,如果发现当前有
len(shardContainer.TransferShards) != 0则发起 - ShardJoin:增加 Shard,在接收到 Shard 迁移 RPC 时,校验通过后发起
2.2 实现
2.2.1 配置轮询
每次执行间隔为 100ms,检查当前配置是否有 迁移/加入 的切片,如果 100 ms 内没处理完会重复发起,可以增加可靠性,对于重复的 Raft.ApplyMsg 在消息处理层已经做了过滤。
func (kv *ShardKV) checkConfig(config shardctrler.Config) {
if config.Num < kv.shards.ConfigNum || config.Num == 0 {
DPrintf("[ShardKV-%d-%d] checkConfig not change, config=%v, kv.shards=%v", kv.gid, kv.me, config, kv.shards)
return
}
kvShards := make([]int, 0)
waitJoinShards := make([]int, 0)
// collect group shards
for index, gid := range config.Shards {
if gid == kv.gid {
kvShards = append(kvShards, index)
if !isShardInGroup(index, kv.shards.RetainShards) {
waitJoinShards = append(waitJoinShards, index)
}
}
}
// find the shard that leave this group
leaveShards := make(map[int][]int) // shard idx to new gid
for _, shard := range kv.shards.RetainShards {
if !isShardInGroup(shard, kvShards) {
shardNewGroup := config.Shards[shard]
if _, found := leaveShards[shardNewGroup]; !found {
leaveShards[shardNewGroup] = make([]int, 0)
}
leaveShards[shardNewGroup] = append(leaveShards[shardNewGroup], shard)
}
}
DPrintf("[ShardKV-%d-%d] groupNewShards=%v, OldShards=%v, leaveShards=%v query config=%v", kv.gid, kv.me, kvShards, kv.shards, leaveShards, config)
// init config
if config.Num == 1 {
kv.rf.Start(Op{
Command: "ShardInit",
ClerkId: nrand(),
SeqId: kv.shards.ShardReqSeqId,
InitOp: ShardInitOp{
Shards: kvShards,
ConfigNum: config.Num,
},
})
return
}
// only incr config num
if len(waitJoinShards) == 0 && len(leaveShards) == 0 {
kv.rf.Start(Op{
Command: "ShardConf",
ClerkId: kv.shards.ShardReqId,
SeqId: kv.shards.ShardReqSeqId,
ConfOp: ShardConfOp{
ConfigNum: config.Num + 1,
},
})
return
}
if len(leaveShards) != 0 || len(waitJoinShards) != 0 {
op := Op{
Command: "ShardChange",
ClerkId: kv.shards.ShardReqId,
SeqId: kv.shards.ShardReqSeqId,
LeaveOp: ShardChangeOp{
LeaveShards: leaveShards,
Servers: config.Groups,
ConfigNum: config.Num,
WaitJoinShards: waitJoinShards,
},
}
DPrintf("[ShardKV-%d-%d] ConfigChange, ShardChange=%v, kv.shards=%v, config=%v", kv.gid, kv.me, op, kv.shards, config)
kv.rf.Start(op)
} else {
kv.shards.QueryDone = true
}
}
func (kv *ShardKV) getNextQueryConfigNum() int {
kv.mu.Lock()
defer kv.mu.Unlock()
return kv.shards.ConfigNum
}
func (kv *ShardKV) intervalQueryConfig() {
queryInterval := 100 * time.Millisecond
for {
if _, isLeader := kv.rf.GetState(); isLeader {
config := kv.mck.Query(kv.getNextQueryConfigNum())
kv.mu.Lock()
kv.checkConfig(config)
kv.mu.Unlock()
}
time.Sleep(queryInterval)
}
}
2.2.2 Raft 消息处理
其主流程与之前的 Lab 类似:
- 对快照消息特殊处理
- 检查消息是否需要通知
- 检查是否已经处理过该消息
- 根据 Command 分流执行对应逻辑
func (kv *ShardKV) recvMsg() {
for {
applyMsg := <-kv.applyCh
kv.processMsg(applyMsg)
}
}
func (kv *ShardKV) processMsg(applyMsg raft.ApplyMsg) {
if applyMsg.SnapshotValid {
kv.readKVState(applyMsg.Snapshot)
return
}
Msg := applyMsg.Command.(Op)
DPrintf("[ShardKV-%d-%d] Received Msg from channel. Msg=%v", kv.gid, kv.me, applyMsg)
kv.mu.Lock()
defer kv.mu.Unlock()
_, isLeader := kv.rf.GetState()
if kv.needSnapshot() {
DPrintf("[ShardKV-%d-%d] size=%d, maxsize=%d, DoSnapshot %v", kv.gid, kv.me, kv.persister.RaftStateSize(), kv.maxraftstate, applyMsg)
kv.saveKVState(applyMsg.CommandIndex - 1)
}
ck := kv.GetCk(Msg.ClerkId)
needNotify := ck.msgUniqueId == applyMsg.CommandIndex
if isLeader && needNotify {
ck.msgUniqueId = 0
DPrintf("[ShardKV-%d-%d] Process Msg %v finish, ready send to ck.Ch, SeqId=%d isLeader=%v", kv.gid, kv.me, applyMsg, ck.seqId, isLeader)
kv.NotifyApplyMsgByCh(ck.messageCh, Msg)
DPrintf("[ShardKV-%d-%d] Process Msg %v Send to Rpc handler finish SeqId=%d isLeader=%v", kv.gid, kv.me, applyMsg, ck.seqId, isLeader)
}
if Msg.SeqId < ck.seqId {
DPrintf("[ShardKV-%d-%d] Ignore Msg %v, Msg.SeqId < ck.seqId=%d", kv.gid, kv.me, applyMsg, ck.seqId)
return
}
DPrintf("[ShardKV-%d-%d] Excute CkId=%d %s Msg=%v, ck.SeqId=%d, kvdata=%v", kv.gid, kv.me, Msg.ClerkId, Msg.Command, applyMsg, ck.seqId, kv.dataSource)
succ := true
switch Msg.Command {
case "Put":
if kv.isRequestKeyCorrect(Msg.Key) {
kv.dataSource[Msg.Key] = Msg.Value
} else {
succ = false
}
case "Append":
if kv.isRequestKeyCorrect(Msg.Key) {
kv.dataSource[Msg.Key] += Msg.Value
} else {
succ = false
}
case "ShardJoin":
kv.shardJoin(Msg.JoinOp)
case "ShardConf":
kv.shards.ConfigNum = Msg.ConfOp.ConfigNum
kv.shards.ShardReqSeqId = Msg.SeqId + 1
kv.shards.QueryDone = false
case "ShardChange":
kv.shardChange(Msg.LeaveOp, Msg.SeqId)
kv.shards.ShardReqSeqId = Msg.SeqId + 1
case "ShardLeave":
kv.shardLeave(Msg.LeaveOp, Msg.SeqId)
kv.shards.ShardReqSeqId = Msg.SeqId + 1
case "ShardInit":
if kv.shards.ConfigNum > 1 {
DPrintf("[ShardKV-%d-%d] already ShardInit, kv.shards=%v, Msg=%v", kv.gid, kv.me, kv.shards, Msg)
} else {
DPrintf("[ShardKV-%d-%d] ShardChange, ShardInit, kv.shards before=%v, after=%v", kv.gid, kv.me, kv.shards, Msg)
kv.shards.ShardReqId = Msg.ClerkId
kv.shards.ShardReqSeqId = Msg.SeqId + 1
kv.shards.RetainShards = Msg.InitOp.Shards
kv.shards.ConfigNum = Msg.InitOp.ConfigNum + 1
kv.shards.QueryDone = false
}
}
if succ {
DPrintf("[ShardKV-%d-%d] update seqid ck.seqId=%d -> Msg.seqId=%d ", kv.gid, kv.me, ck.seqId, Msg.SeqId+1)
ck.seqId = Msg.SeqId + 1
}
kv.persist()
}
2.2.3 切片迁移

2.2.3.1 发起迁移
Shard 迁移的 RPC 结构如下
type RequestMoveShard struct {
Data map[string]string
ClerkId int64
SeqId int
Shards []int
RequestMap map[int64]int
ConfigNum int
}
type ReplyMoveShard struct {
Err
}
RPC 请求结构中,其他参数都还好理解,RequestMap 参数是当前 Group 已经处理的 Client 请求序号,这里是为了防止出现如下情况:
- Group1 收到 Client 请求,等待 Start
- Config 发生变化
- Group1 收到 Client 请求 Start 完毕的结果并且执行,但是由于配置发生变化,客户端认为请求应该切换到 Shard 迁移后的 Group2
- Group2 收到 Group1 的 Shard 迁移数据后,又执行了一次客户端请求,导致重复执行
这里带上 Group1 已经处理的客户端 Request,然后 Update SeqId 到更大的一方即可。切片迁移的请求发起时机为,当 Raft 层返回的 Command 为 ShardChange 且有需要迁移的 Shard 时,发起迁移请求 RPC(放到 Goroutine 中执行防止阻塞)。
func (kv *ShardKV) shardChange(leaveOp ShardChangeOp, seqId int) {
if leaveOp.ConfigNum != kv.shards.ConfigNum {
DPrintf("[ShardKV-%d-%d] ignore beginShardLeave old config, kv.shards=%v, leaveOp=%v", kv.gid, kv.me, kv.shards, leaveOp)
return
}
for _, shards := range leaveOp.LeaveShards {
for _, shard := range shards {
kv.addShard(shard, &kv.shards.TransferShards)
}
}
kv.shards.WaitJoinShards = leaveOp.WaitJoinShards
DPrintf("[ShardKV-%d-%d] ShardChange ShardLeave, transferShards=%v kv.shards=%v", kv.gid, kv.me, leaveOp.LeaveShards, kv.shards)
kv.shards.QueryDone = true
_, isLeader := kv.rf.GetState()
if !isLeader {
DPrintf("[ShardKV-%d-%d] not leader, ignore leaveOp %v", kv.gid, kv.me, leaveOp)
return
}
if len(leaveOp.LeaveShards) != 0 {
go func(shardReqId int64, op ShardChangeOp, reqSeqId int) {
for gid, shards := range leaveOp.LeaveShards {
servers := leaveOp.Servers[gid]
ok := kv.transferShardsToGroup(shards, servers, leaveOp.ConfigNum)
kv.mu.Lock()
if ok {
DPrintf("[ShardKV-%d-%d] beginShardLeave to %d succ, kv.shards=%v", kv.gid, kv.me, gid, kv.shards)
} else {
DPrintf("[ShardKV-%d-%d] beginShardLeave to %d failed", kv.gid, kv.me, gid)
}
kv.mu.Unlock()
}
kv.mu.Lock()
kv.rf.Start(Op{
Command: "ShardLeave",
ClerkId: shardReqId,
SeqId: kv.shards.ShardReqSeqId,
LeaveOp: op,
})
kv.mu.Unlock()
}(kv.shards.ShardReqId, leaveOp, seqId)
}
}
具体发起迁移的接口如下
func (kv *ShardKV) transferShardsToGroup(shards []int, servers []string, configNum int) bool {
kv.mu.Lock()
data := make(map[string]string)
for _, moveShard := range shards {
for key, value := range kv.dataSource {
if key2shard(key) != moveShard {
continue
}
data[key] = value
}
}
DPrintf("[ShardKV-%d-%d] invokeMoveShard shards=%v, data=%v", kv.gid, kv.me, shards, data)
// notify shard new owner
args := RequestMoveShard{
Data: data,
SeqId: kv.shards.ShardReqSeqId,
ClerkId: kv.shards.ShardReqId,
Shards: shards,
ConfigNum: configNum,
}
args.RequestMap = make(map[int64]int)
for clerkId, clerk := range kv.shardkvClerks {
if clerkId == kv.shards.ShardReqId {
continue
}
args.RequestMap[clerkId] = clerk.seqId
}
kv.mu.Unlock()
reply := ReplyMoveShard{}
// todo when all server access fail
for {
for _, servername := range servers {
DPrintf("[ShardKV-%d-%d] start move shard args=%v", kv.gid, kv.me, args)
ok := kv.sendRequestMoveShard(servername, &args, &reply)
if ok && reply.Err == OK {
DPrintf("[ShardKV-%d-%d] move shard finish ...", kv.gid, kv.me)
return true
}
time.Sleep(100 * time.Millisecond)
}
}
}
当迁移完毕后,会发起 ShardLeave 的 Command 来删除对应数据
func (kv *ShardKV) shardLeave(leaveOp ShardChangeOp, seqId int) {
if leaveOp.ConfigNum < kv.shards.ConfigNum {
DPrintf("[ShardKV-%d-%d] ignore beginShardLeave old config, kv.shards=%v, leaveOp=%v", kv.gid, kv.me, kv.shards, leaveOp)
return
}
// update shards, only update the leave shard , the join shard need to update by shardjoin msg from the channel
if len(kv.shards.WaitJoinShards) == 0 {
kv.shards.ConfigNum = leaveOp.ConfigNum + 1
kv.shards.QueryDone = false
}
afterShards := make([]int, 0)
for _, shard := range kv.shards.RetainShards {
if isShardInGroup(shard, kv.shards.TransferShards) {
continue
}
afterShards = append(afterShards, shard)
}
// delete data
deleteKeys := make([]string, 0)
for key := range kv.dataSource {
if isShardInGroup(key2shard(key), kv.shards.TransferShards) {
deleteKeys = append(deleteKeys, key)
}
}
for _, deleteKey := range deleteKeys {
delete(kv.dataSource, deleteKey)
}
kv.shards.RetainShards = afterShards
DPrintf("[ShardKV-%d-%d] ShardChange shardLeave finish, transferShards=%v, RetainShards=%v, kv.shards=%v", kv.gid, kv.me, leaveOp.LeaveShards, afterShards, kv.shards)
kv.shards.TransferShards = make([]int, 0)
DPrintf("[ShardKV-%d-%d] Excute ShardLeave finish, leave shards=%v, kv.Shards=%v", kv.gid, kv.me, leaveOp, kv.shards)
}
2.2.3.2 接收切片
接收切片的 Group Rpc 处理如下,其整体 RPC 处理流程与之前类似,但是做了一些过滤操作,其次切片迁移的 RPC 有可能会重复发送(2.2.1 的配置轮询方式决定的),即便 ConfigNum 相同,也需要检查 Shard 是否已经添加成功了,防止执行 ShardJoin 时覆盖了数据。
func (kv *ShardKV) RequestMoveShard(args *RequestMoveShard, reply *ReplyMoveShard) {
kv.mu.Lock()
DPrintf("[ShardKV-%d-%d] Received Req MoveShard %v, SeqId=%d kv.shards=%v", kv.gid, kv.me, args, args.SeqId, kv.shards)
reply.Err = OK
// check request repeat ?
ck := kv.GetCk(args.ClerkId)
if ck.seqId > args.SeqId || kv.shards.ConfigNum != args.ConfigNum {
DPrintf("[ShardKV-%d-%d] Received Req MoveShard %v, SeqId=%d, ck.seqId=%d, already process request", kv.gid, kv.me, args, args.SeqId, ck.seqId)
// not update to this config, wait, set errwrongleader to let them retry
if kv.shards.ConfigNum < args.ConfigNum {
reply.Err = ErrWrongLeader
}
kv.mu.Unlock()
return
}
// already add shard, but config num not change (sometime a config can trigger multi shard add from two group)
alreadyAdd := true
for _, shard := range args.Shards {
if !isShardInGroup(shard, kv.shards.RetainShards) {
alreadyAdd = false
break
}
}
if alreadyAdd {
kv.mu.Unlock()
return
}
// config not query finish, waiting, let them retry
if !kv.shards.QueryDone {
reply.Err = ErrWrongLeader
kv.mu.Unlock()
return
}
// start a command
shardJoinOp := ShardJoinOp{
Shards: args.Shards,
ShardData: args.Data,
ConfigNum: args.ConfigNum,
RequestMap: args.RequestMap,
}
logIndex, _, isLeader := kv.rf.Start(Op{
Command: "ShardJoin",
ClerkId: args.ClerkId, // special clerk id for indicate move shard
SeqId: args.SeqId,
JoinOp: shardJoinOp,
})
if !isLeader {
reply.Err = ErrWrongLeader
kv.mu.Unlock()
return
}
ck.msgUniqueId = logIndex
DPrintf("[ShardKV-%d-%d] Received Req MoveShard %v, waiting logIndex=%d", kv.gid, kv.me, args, logIndex)
kv.mu.Unlock()
// step 2 : wait the channel
reply.Err = OK
notify := kv.WaitApplyMsgByCh(ck.messageCh, ck)
kv.mu.Lock()
defer kv.mu.Unlock()
DPrintf("[ShardKV-%d-%d] Recived Msg [MoveShard] from ck.channel args=%v, SeqId=%d, Msg=%v", kv.gid, kv.me, args, args.SeqId, notify.Msg)
reply.Err = notify.Result
if reply.Err != OK {
DPrintf("[ShardKV-%d-%d] leader change args=%v, SeqId=%d", kv.gid, kv.me, args, args.SeqId)
return
}
}
执行切片加入操作
func (kv *ShardKV) shardJoin(joinOp ShardJoinOp) {
if joinOp.ConfigNum != kv.shards.ConfigNum {
DPrintf("[ShardKV-%d-%d] ignore ShardJoinOp old config, kv.shards=%v, leaveOp=%v", kv.gid, kv.me, kv.shards, joinOp)
return
}
// just put it in
DPrintf("[ShardKV-%d-%d] Excute shardJoin, old shards=%v, ShardData=%v", kv.gid, kv.me, kv.shards, joinOp.ShardData)
for key, value := range joinOp.ShardData {
kv.dataSource[key] = value
}
// update request seq id
for clerkId, seqId := range joinOp.RequestMap {
ck := kv.GetCk(clerkId)
if ck.seqId < seqId {
DPrintf("[ShardKV-%d-%d] Update RequestSeqId, ck=%d update seqid=%d to %d", kv.gid, kv.me, clerkId, ck.seqId, seqId)
ck.seqId = seqId
}
}
// add shard config
for _, shard := range joinOp.Shards {
kv.addShard(shard, &kv.shards.RetainShards)
}
joinAfterShards := make([]int, 0)
for _, shard := range kv.shards.WaitJoinShards {
if !isShardInGroup(shard, kv.shards.RetainShards) {
joinAfterShards = append(joinAfterShards, shard)
}
}
kv.shards.WaitJoinShards = joinAfterShards
if (len(kv.shards.TransferShards) == 0) && len(kv.shards.WaitJoinShards) == 0 {
kv.shards.ConfigNum = joinOp.ConfigNum + 1
kv.shards.QueryDone = false
}
DPrintf("[ShardKV-%d-%d] ShardChange ShardJoin addShards shards=%v, kv.shards=%v", kv.gid, kv.me, joinOp.Shards, kv.shards)
}
2.2.4 PutAppend/Get
// Get 操作
func (kv *ShardKV) Get(args *GetArgs, reply *GetReply) {
// Your code here.
DPrintf("[ShardKV-%d-%d] Received Req Get %v", kv.gid, kv.me, args)
kv.mu.Lock()
if !kv.isRequestKeyCorrect(args.Key) {
reply.Err = ErrWrongGroup
kv.mu.Unlock()
return
}
DPrintf("[ShardKV-%d-%d] Received Req Get Begin %v", kv.gid, kv.me, args)
// start a command
ck := kv.GetCk(args.ClerkId)
logIndex, _, isLeader := kv.rf.Start(Op{
Key: args.Key,
Command: "Get",
ClerkId: args.ClerkId,
SeqId: args.SeqId,
})
if !isLeader {
reply.Err = ErrWrongLeader
ck.msgUniqueId = 0
kv.mu.Unlock()
return
}
DPrintf("[ShardKV-%d-%d] Received Req Get %v, waiting logIndex=%d", kv.gid, kv.me, args, logIndex)
ck.msgUniqueId = logIndex
kv.mu.Unlock()
// step 2 : parse op struct
notify := kv.WaitApplyMsgByCh(ck.messageCh, ck)
getMsg := notify.Msg
kv.mu.Lock()
defer kv.mu.Unlock()
DPrintf("[ShardKV-%d-%d] Received Msg [Get] args=%v, SeqId=%d, Msg=%v", kv.gid, kv.me, args, args.SeqId, getMsg)
reply.Err = notify.Result
if reply.Err != OK {
// leadership change, return ErrWrongLeader
return
}
_, foundData := kv.dataSource[getMsg.Key]
if !foundData {
reply.Err = ErrNoKey
} else {
reply.Value = kv.dataSource[getMsg.Key]
DPrintf("[ShardKV-%d-%d] Excute Get %s is %s", kv.gid, kv.me, getMsg.Key, reply.Value)
}
}
// PutAppend 操作
func (kv *ShardKV) PutAppend(args *PutAppendArgs, reply *PutAppendReply) {
// Your code here.
DPrintf("[ShardKV-%d-%d] Received Req PutAppend %v, SeqId=%d ", kv.gid, kv.me, args, args.SeqId)
kv.mu.Lock()
if !kv.isRequestKeyCorrect(args.Key) {
reply.Err = ErrWrongGroup
kv.mu.Unlock()
return
}
// start a command
logIndex, _, isLeader := kv.rf.Start(Op{
Key: args.Key,
Value: args.Value,
Command: args.Op,
ClerkId: args.ClerkId,
SeqId: args.SeqId,
})
if !isLeader {
reply.Err = ErrWrongLeader
kv.mu.Unlock()
return
}
ck := kv.GetCk(args.ClerkId)
ck.msgUniqueId = logIndex
DPrintf("[ShardKV-%d-%d] Received Req PutAppend %v, waiting logIndex=%d", kv.gid, kv.me, args, logIndex)
kv.mu.Unlock()
// step 2 : wait the channel
reply.Err = OK
notify := kv.WaitApplyMsgByCh(ck.messageCh, ck)
kv.mu.Lock()
defer kv.mu.Unlock()
DPrintf("[ShardKV-%d-%d] Recived Msg [PutAppend] from ck.putAppendCh args=%v, SeqId=%d, Msg=%v", kv.gid, kv.me, args, args.SeqId, notify.Msg)
reply.Err = notify.Result
if reply.Err != OK {
DPrintf("[ShardKV-%d-%d] leader change args=%v, SeqId=%d", kv.gid, kv.me, args, args.SeqId)
return
}
}
2.2.5 持久化和快照
这里主要需要保存的数据和 KVRaft 类似,数据持久化:
func (kv *ShardKV) persist() {
if kv.maxraftstate == -1 {
return
}
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
cks := make(map[int64]int)
for ckId, ck := range kv.shardkvClerks {
cks[ckId] = ck.seqId
}
e.Encode(cks)
e.Encode(kv.dataSource)
e.Encode(kv.shards)
kv.persister.SaveSnapshot(w.Bytes())
}
读取快照,主要在初始化和监听 Raft 层消息时会使用
func (kv *ShardKV) readKVState(data []byte) {
if data == nil || len(data) < 1 { // bootstrap without any state?
return
}
DPrintf("[ShardKV-%d-%d] read size=%d", kv.gid, kv.me, len(data))
r := bytes.NewBuffer(data)
d := labgob.NewDecoder(r)
cks := make(map[int64]int)
dataSource := make(map[string]string)
shards := ShardContainer{
TransferShards: make([]int, 0),
RetainShards: make([]int, 0),
ConfigNum: 1,
}
//var commitIndex int
if d.Decode(&cks) != nil ||
d.Decode(&dataSource) != nil ||
d.Decode(&shards) != nil {
DPrintf("[readKVState] decode failed ...")
} else {
for ckId, seqId := range cks {
kv.mu.Lock()
ck := kv.GetCk(ckId)
ck.seqId = seqId
kv.mu.Unlock()
}
kv.mu.Lock()
kv.dataSource = dataSource
kv.shards = shards
DPrintf("[ShardKV-%d-%d] readKVState kv.shards=%v messageMap=%v dataSource=%v", kv.gid, kv.me, shards, kv.shardkvClerks, kv.dataSource)
kv.mu.Unlock()
}
}
2.3 测试结果
➜ shardkv git:(main) ✗ go test -race
Test: static shards ...
labgob warning: Decoding into a non-default variable/field Err may not work
... Passed
Test: join then leave ...
... Passed
Test: snapshots, join, and leave ...
... Passed
Test: servers miss configuration changes...
... Passed
Test: concurrent puts and configuration changes...
... Passed
Test: more concurrent puts and configuration changes...
... Passed
Test: concurrent configuration change and restart...
... Passed
Test: unreliable 1...
... Passed
Test: unreliable 2...
... Passed
Test: unreliable 3...
... Passed
Test: shard deletion (challenge 1) ...
... Passed
Test: unaffected shard access (challenge 2) ...
... Passed
Test: partial migration shard access (challenge 2) ...
... Passed
PASS
ok 6.824/shardkv 108.245s
3. 总结
其实该 Lab 还有优化空间,比如 Notify 机制是通过设置一个 MsgUID 来标记,这只限于当前 Lab 的 Client 只会串行发送请求,如果 Client 可以并发 Request,那么需要换一种方式,比如用 map 来构建一个 LogIndex 和 Channel 的映射,然后读取 Raft 层的消息时,检查 LogIndex 有没有 Channel,有则表示需要通知。此外该 Lab 的 Challenge 都比较简单,因此没有细说。总体来说 ShardKV 需要注意如下几点:
- 防止接收切片数据时覆盖已经有了的数据
- 防止重复执行 Client 端的请求
其次主要通过 ShardContainer.ConfigNum 确定当前 Group 所在的配置,限制死了处理请求的范围,从而减少了错误。但是由此 ConfigNum 的更新时机也需要确定好,主要有如下时机:
- 当前 Group 所在的配置没有需要 加入/迁移 的切片
- 接收切片后,没有正在需要迁移的切片
- 迁移完毕后,没有需要等待加入的切片
最后贴上最终再复测的 lab2 ~ lab3 结果
➜ raft git:(main) go test -race -run 2A && go test -race -run 2B && go test -race -run 2C && go test -race -run 2D
Test (2A): initial election ...
... Passed -- 3.0 3 56 15548 0
Test (2A): election after network failure ...
... Passed -- 4.6 3 128 25496 0
Test (2A): multiple elections ...
... Passed -- 5.7 7 606 116938 0
PASS
ok 6.824/raft 14.240s
Test (2B): basic agreement ...
... Passed -- 0.8 3 16 4366 3
Test (2B): RPC byte count ...
... Passed -- 1.7 3 48 113850 11
Test (2B): agreement after follower reconnects ...
... Passed -- 4.0 3 96 24185 7
Test (2B): no agreement if too many followers disconnect ...
... Passed -- 3.5 5 204 40834 3
Test (2B): concurrent Start()s ...
... Passed -- 0.7 3 12 3326 6
Test (2B): rejoin of partitioned leader ...
... Passed -- 6.1 3 184 44288 4
Test (2B): leader backs up quickly over incorrect follower logs ...
... Passed -- 19.2 5 1860 1287250 103
Test (2B): RPC counts aren't too high ...
... Passed -- 2.2 3 42 12026 12
PASS
ok 6.824/raft 39.348s
Test (2C): basic persistence ...
... Passed -- 3.7 3 88 21655 6
Test (2C): more persistence ...
... Passed -- 16.4 5 1012 207576 16
Test (2C): partitioned leader and one follower crash, leader restarts ...
... Passed -- 1.6 3 36 8446 4
Test (2C): Figure 8 ...
... Passed -- 31.9 5 1204 252882 27
Test (2C): unreliable agreement ...
... Passed -- 3.3 5 224 76830 246
Test (2C): Figure 8 (unreliable) ...
... Passed -- 41.6 5 7661 15959387 179
Test (2C): churn ...
... Passed -- 16.4 5 1564 2176205 666
Test (2C): unreliable churn ...
... Passed -- 16.3 5 1548 852066 229
PASS
ok 6.824/raft 132.267s
Test (2D): snapshots basic ...
... Passed -- 5.3 3 150 65476 227
Test (2D): install snapshots (disconnect) ...
... Passed -- 53.3 3 1304 598935 307
Test (2D): install snapshots (disconnect+unreliable) ...
... Passed -- 74.4 3 1794 743006 351
Test (2D): install snapshots (crash) ...
... Passed -- 32.3 3 796 407789 327
Test (2D): install snapshots (unreliable+crash) ...
... Passed -- 43.9 3 958 520806 306
Test (2D): crash and restart all servers ...
... Passed -- 10.0 3 294 84156 54
PASS
ok 6.824/raft 220.129s
➜ kvraft git:(main) go test -race -run 3A && go test -race -run 3B
Test: one client (3A) ...
labgob warning: Decoding into a non-default variable/field Err may not work
... Passed -- 15.2 5 2904 572
Test: ops complete fast enough (3A) ...
... Passed -- 30.8 3 3283 0
Test: many clients (3A) ...
... Passed -- 15.7 5 2843 850
Test: unreliable net, many clients (3A) ...
... Passed -- 17.3 5 3128 576
Test: concurrent append to same key, unreliable (3A) ...
... Passed -- 1.6 3 152 52
Test: progress in majority (3A) ...
... Passed -- 0.8 5 76 2
Test: no progress in minority (3A) ...
... Passed -- 1.0 5 98 3
Test: completion after heal (3A) ...
... Passed -- 1.2 5 66 3
Test: partitions, one client (3A) ...
... Passed -- 22.9 5 2625 321
Test: partitions, many clients (3A) ...
... Passed -- 23.3 5 4342 691
Test: restarts, one client (3A) ...
... Passed -- 19.7 5 3229 564
Test: restarts, many clients (3A) ...
... Passed -- 21.3 5 4701 815
Test: unreliable net, restarts, many clients (3A) ...
... Passed -- 21.1 5 3670 611
Test: restarts, partitions, many clients (3A) ...
... Passed -- 27.2 5 3856 601
Test: unreliable net, restarts, partitions, many clients (3A) ...
... Passed -- 29.1 5 3427 384
Test: unreliable net, restarts, partitions, random keys, many clients (3A) ...
... Passed -- 33.4 7 7834 498
PASS
ok 6.824/kvraft 283.329s
Test: InstallSnapshot RPC (3B) ...
labgob warning: Decoding into a non-default variable/field Err may not work
... Passed -- 3.1 3 255 63
Test: snapshot size is reasonable (3B) ...
... Passed -- 13.4 3 2411 800
Test: ops complete fast enough (3B) ...
... Passed -- 17.0 3 3262 0
Test: restarts, snapshots, one client (3B) ...
... Passed -- 19.2 5 4655 788
Test: restarts, snapshots, many clients (3B) ...
... Passed -- 20.7 5 9280 4560
Test: unreliable net, snapshots, many clients (3B) ...
... Passed -- 17.6 5 3376 651
Test: unreliable net, restarts, snapshots, many clients (3B) ...
... Passed -- 21.5 5 3945 697
Test: unreliable net, restarts, partitions, snapshots, many clients (3B) ...
... Passed -- 28.3 5 3213 387
Test: unreliable net, restarts, partitions, snapshots, random keys, many clients (3B) ...
... Passed -- 31.4 7 7083 878
PASS
ok 6.824/kvraft 173.344s

 浙公网安备 33010602011771号
浙公网安备 33010602011771号