

20240509xxx集群xx节点PLEG超时问题
20240509xxx集群xx节点PLEG超时问题
//20240509 写在前面
xxx集群xx节点又又又又又卡住了,经过一系列排查,终于解决了问题,由于这次找到了通用解法,所以在此记录下
ps:国内的搜索引擎是真的shi。。搜出来的帖子都是抄来抄去的,还不解决问题,还得是google/大拇指
问题起因:
- 偷得浮生半日闲,看到集群里一个节点监控没了,寻思是不是又是df卡住了,然后进去一看,果然,Ready 和 NotReady状态之间鬼畜,遂开始排查
解决流程:
-
先说结论,核心就一句命令:
for i in `docker ps -aq`; do echo $i; docker inspect $i 1>/dev/null 2>&1; done # 卡住的即为有问题的容器 -
首先需要了解PLEG的原理,看看他到底在干什么,这里我不赘述,可以看Ref第一条,老哥说的很清楚;总结出来就一个点“遍历检查所有pod所属容器的状态”
-
那既然知道了在干什么,分析就变得很简单了,又如下几点:
- PLEG过程中哪里夯住了
- pod太多,预设阈值中3分钟处理不完【这种一般很少见了,因为PLEG是节点级别的,一个节点不会有那么多pod,除非超级节点。。】
-
所以有以下几个排查方向:
- 节点pod数
- docker状态【或者说底层CRI的状态】
- 因为PLEG需要的信息是从底层接口中获取的
- 本地所有由kubelet产生的容器信息
- 使用开头的那句命令即可,PLEG拿到的信息,从inspect也可以拿到,如果拿不到,那肯定是有问题
-
找到问题之后,处理问题节点即可,本案例是因为ceph挂载卡住,杀死相关进程即可【容器杀不掉,只能强杀进程】
Ref:
- https://icloudnative.io/posts/understanding-the-pleg-is-not-healthy/【pleg-原理】
- https://isekiro.com/kubernetes排错-kubelet-报错-pleg-is-not-healthy/【找到解决办法】
- https://cloud.tencent.com/developer/article/1736775
// 20250722 更新 最近在整理PLEG相关内容 补充下PLEG的流程图&相关AI生成补充资料
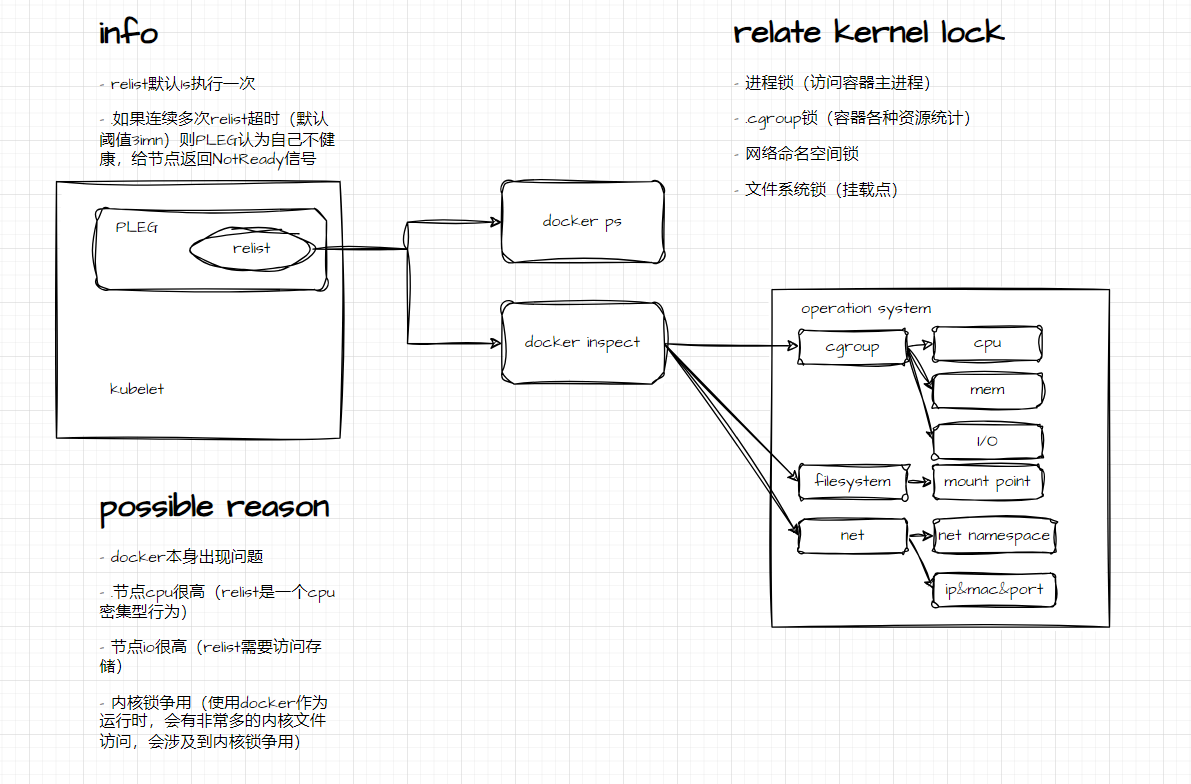
补充资料(deepseek生成)
它是 Kubelet 中一个至关重要但相对底层的组件,负责高效地检测 Pod 及其容器状态的变化,并将这些变化转化为事件驱动 Kubelet 内部的协调循环。
理解 PLEG 的关键在于认识到 Kubelet 需要持续监控节点上运行的 Pod 和容器的状态(运行中、退出、创建、删除等),并根据这些状态变化做出响应(重启容器、更新状态等)。PLEG 就是专门为解决高效状态监控这个问题而设计的。
- PLEG 的核心目标与解决的问题
问题背景: Kubelet 需要知道节点上每个 Pod 及其包含容器的实时状态(如 Running、Terminated、Exited、Created、Unknown 等)。如果 Kubelet 采用简单的轮询方式不断地、主动地去查询容器运行时(如 containerd、CRI-O)获取所有容器的当前状态,会产生极高的开销,尤其是在节点上运行大量 Pod/容器时。这种轮询的效率低下且不可扩展。
核心目标:
高效状态监控: 以尽可能小的开销,及时、准确地检测到 Pod 和容器生命周期的状态变化(事件)。
事件驱动: 将状态变化转化为事件,通知给 Kubelet 的核心协调循环 (syncLoop),触发必要的协调操作(如重启崩溃的容器)。
避免轮询开销: 减少对容器运行时进行不必要的、昂贵的全量状态查询。 - PLEG 的工作原理 - Relist + Diff = Event
PLEG 的核心机制是一个周期性的 relist 过程,结合状态对比 (diff) 来生成事件 (event)。以下是详细步骤:
周期性 Relist (relistPeriod):
PLEG 会按照一个固定的时间间隔(默认为 1秒,可通过 Kubelet 的 --pleg-relist-interval 参数配置)触发一次 relist 操作。
关键点: relist 不是监听事件!它是主动去容器运行时获取当前节点上所有 Pod 及其所有容器最新完整状态快照的操作。
获取 Pod 列表和容器状态 (GetPods):
在 relist 过程中,PLEG 通过 CRI 调用容器运行时的 ListPodSandbox 和 ListContainers 方法(或其他等效方法),获取当前节点上所有 Pod Sandbox(Pod 的基础设施容器)和所有容器的最新状态列表(包括 ID、状态、创建时间等元数据)。
这一步是全量查询,开销相对较大。
与上次状态缓存进行 Diff:
PLEG 内部维护着一个缓存,记录了上一次 relist 时获取到的各个 Pod 及其容器的状态 (podRecords)。
将本次 relist 获取到的新状态快照与缓存中的旧状态快照进行逐项对比 (diff)。
生成 Pod 生命周期事件:
通过 diff 操作,PLEG 能够精确地识别出哪些 Pod 的整体状态发生了变化,以及哪些容器的状态发生了变化(创建、启动、停止、退出、销毁等)。
对于每一个检测到的状态变化,PLEG 会生成一个对应的 PodLifecycleEvent 事件对象。事件类型主要包括:
ContainerStarted: 容器被启动(之前不存在或状态不是运行中)。
ContainerDied: 容器停止运行(无论正常退出还是崩溃)。这是最重要的事件之一,用于触发容器重启。
ContainerRemoved: 容器被移除(清理)。
ContainerChanged: 容器的其他状态发生变化(如重启次数变化)。
PodSync: 一个通用事件,通常表示 Pod 或其容器状态发生了变化,需要同步。它本身不携带特定容器事件信息,但会触发 syncLoop。
这些事件会被放入一个 事件通道 (eventChannel) 中。
更新状态缓存:
生成事件后,PLEG 会用本次 relist 获取到的新状态快照更新其内部的缓存 (podRecords),为下一次 diff 做准备。
事件消费 (syncLoop):
Kubelet 的核心协调循环 (syncLoop) 会持续监听 PLEG 的 eventChannel。
当 syncLoop 从通道中接收到一个事件时:
它首先会调用 HandlePodSyncs 等方法进行处理。
更重要的是,它会根据事件关联的 Pod UID,将该 Pod 标记为“需要同步”(通常加入一个队列如 podUpdates 或 workQueue)。
随后,syncLoop 会处理这个队列,针对需要同步的 Pod 执行 syncPod 操作。syncPod 是 Kubelet 的核心逻辑所在,它会比较 Pod 的期望状态(来自 API Server)与实际状态(包含 PLEG 检测到的变化),并执行必要的操作使两者一致(比如重启 ContainerDied 的容器)。
3. PLEG 的关键特性与设计考量
事件驱动而非轮询: PLEG 的核心创新在于避免了 Kubelet 主循环直接轮询容器运行时。它通过周期性(相对低频)的 relist + diff 生成了细粒度的状态变化事件,使得上层逻辑 (syncLoop) 能够基于事件高效响应。
周期性而不是实时: relist 是周期性的,因此 PLEG 检测到的状态变化不是完全实时的,存在最多一个 relistPeriod(默认1秒)的延迟。这在绝大多数场景下是可接受的,是性能和实时性之间的权衡。
健康检查 (PLEG is not healthy):
PLEG 会记录每次 relist 操作的开始时间和完成时间。
如果连续多次 relist 操作花费的时间超过了预设的阈值 (relistThreshold, 默认为 3分钟,可通过 --pleg-health-check-threshold-duration 配置),PLEG 会认为自己处于不健康状态 (Healthy() 方法返回 false)。
Kubelet 的 nodeStatus 管理器会周期性地检查 PLEG 的健康状态。如果 PLEG 不健康超过一定时间,Kubelet 会将该 Node 的 Ready 状态设置为 False,并在 Condition 中报告 NodeStatusMessage 类似于 "PLEG is not healthy: pleg was last seen active 5m0s ago; threshold 3m0s"。
意义: 这是一个非常重要的故障检测机制。长时间的 relist 阻塞通常意味着节点存在严重问题(如容器运行时无响应、磁盘IO瓶颈、节点负载过高、内核问题等),导致 Kubelet 无法正确感知 Pod 状态。标记节点 NotReady 可以阻止新 Pod 调度到问题节点,并触发控制器(如 Deployment)在其他健康节点上重新创建 Pod。
性能与扩展性:
relist 的开销随节点上 Pod/容器数量的增加而线性增长。这是 PLEG 的主要性能瓶颈点。
节点规模较大时(如数百个 Pod),过短的 relistPeriod(如默认1秒)可能会导致 PLEG 占用过多 CPU。
优化方向:
减少节点上 Pod 密度。
优化容器运行时性能(如 containerd 的性能调优)。
适当增大 --pleg-relist-interval(需权衡状态感知延迟),但这只是缓解措施而非根本解决。
Kubernetes 社区长期在探索替代方案(如基于 CRI 事件通知)来完全避免全量 relist。
4. PLEG 在 Kubelet 架构中的位置与交互
位置: PLEG 是 Kubelet 内部的一个独立模块/组件 (pkg/kubelet/pleg)。它在 Kubelet 启动时被初始化。
主要交互对象:
容器运行时 (Container Runtime): 通过 CRI (Container Runtime Interface) 进行交互,调用 ListPodSandbox 和 ListContainers 等方法获取状态。
Kubelet syncLoop: 向其 eventChannel 发送 PodLifecycleEvent 事件。
Kubelet statusManager/probeManager: 间接相关。PLEG 的事件触发 syncPod,syncPod 会更新 Pod 状态,其中可能包含 statusManager 上报给 API Server 的状态,以及触发 probeManager 进行存活/就绪检查。
5. 总结:为什么 PLEG 如此重要?
状态感知的核心: 它是 Kubelet 了解节点上 Pod 和容器真实运行状态的核心信息来源。没有 PLEG,Kubelet 就无法知道容器崩溃了需要重启。
事件驱动的基础: 它将昂贵的状态轮询转化为高效的事件通知,是 Kubelet syncLoop 协调机制高效运行的关键。
节点健康的关键指标: PLEG 的健康状态 (PLEG is not healthy) 是诊断节点问题(特别是容器运行时或节点负载问题)的一个极其重要的信号。
大规模集群的性能瓶颈点: PLEG 的 relist 机制在大规模节点上是主要的性能关注点之一,是 Kubernetes 支持更高 Pod 密度的挑战之一。
诊断 PLEG 相关问题
查看 Kubelet 日志: 搜索关键词 pleg,关注是否有 relist 耗时过长(relist took XXX, which is beyond the threshold XXX)或 PLEG is not healthy 的日志。
检查 Node 状态: kubectl describe node。关注 Conditions 部分,看 Ready 是否为 False,以及 Message 中是否包含 PLEG is not healthy 和具体的超时信息。
监控指标: Kubelet 暴露 Prometheus 指标:
kubelet_pleg_relist_interval_seconds: 实际的 relist 间隔。
kubelet_pleg_relist_latency_microseconds: 每次 relist 操作的延迟(微秒)。这是最关键的指标!关注其分布(特别是高百分位数如 p99)是否持续超过 relistThreshold (3分钟)。
kubelet_pleg_last_seen_seconds: 距离上一次成功 relist 完成的时间(秒)。如果此值持续大于 relistThreshold,则说明 PLEG 不健康。
根本原因分析:
PLEG 超时的根本原因通常不在 PLEG 本身,而在于其依赖的下层:
容器运行时无响应/卡死: containerd/CRI-O 进程本身出现问题。
容器运行时操作缓慢: ListPodSandbox/ListContainers CRI 调用执行非常慢。
节点资源瓶颈: CPU 耗尽(导致 PLEG goroutine 无法及时运行或运行时处理慢)、磁盘 IO 极高(影响容器运行时访问存储)、内存压力(导致进程缓慢或 OOM)。
内核问题: 如 cgroup 泄漏、内核锁争用等。
Docker 遗留问题 (Dockershim): 如果仍在使用已废弃的 Dockershim,其性能问题更容易导致 PLEG 超时。强烈建议迁移到 containerd 或 CRI-O。
未来演进
Kubernetes 社区意识到 PLEG 的 relist 机制在大规模场景下的局限性,正在积极研究和探索基于 CRI 事件通知的替代方案(如 RuntimeService.GetContainerEvents)。目标是让容器运行时主动推送状态变化事件给 Kubelet,从而完全避免周期性的全量 relist,实现真正的实时、高效监控。但这需要容器运行时的支持,是一个渐进的过程。
希望以上详尽的解释能帮助你彻底理解 Kubernetes 中的 PLEG!
当容器运行时是 Docker 时,Kubernetes(通过 Kubelet)与 Docker 的交互经历了两个重要阶段。由于 Docker 原生 不支持 CRI(Container Runtime Interface),Kubernetes 采用了不同的机制与其通信:
阶段 1:使用 dockershim (Kubernetes v1.20 之前)
这是 Kubernetes 内置的“适配器”,它实现了 CRI 接口,但底层调用的是 Docker Engine API。
PLEG relist 过程详解(dockershim 模式下):
PLEG 触发 relist:
PLEG 按照设定的 relistPeriod(默认 1 秒)启动一次 relist。
CRI 调用 (ListPodSandbox / ListContainers):
PLEG 调用 Kubelet 内部的 CRI 服务接口。
Kubelet 的 CRI 服务会将请求转发给 dockershim。
dockershim 翻译成 Docker API 调用:
ListPodSandbox:
dockershim 执行 docker ps -q --filter label=io.kubernetes.docker.type=podsandbox。这会列出所有 Kubernetes Pod 的 “pause” 容器(Sandbox)。
对于每个找到的 Sandbox 容器 ID,dockershim 会执行 docker inspect <container_id> 获取其详细信息(状态、标签、元数据)。
将这些 Docker inspect 信息转换成 CRI 规范的 PodSandbox 对象列表。
ListContainers:
dockershim 执行 docker ps -a -q 列出所有容器(包括非 Kubernetes 容器,但后续会过滤)。
对于每个容器 ID,dockershim 执行 docker inspect <container_id> 获取详细信息。
关键过滤: dockershim 检查容器的标签 (io.kubernetes.container.name) 和关联的 Sandbox ID (io.kubernetes.sandbox.id)。
只保留属于 Kubernetes Pod(即有 io.kubernetes.sandbox.id 标签)的容器。
将这些 Docker inspect 信息转换成 CRI 规范的 Container 对象列表。
PLEG 处理状态:
dockershim 将转换后的 PodSandbox 列表和 Container 列表返回给 Kubelet CRI 服务,进而返回给 PLEG。
PLEG 拿到这些状态信息后,与上一次缓存的旧状态进行 diff。
检测状态变化(如容器从 running 变成 exited),生成相应的 PodLifecycleEvent (如 ContainerDied)。
更新内部状态缓存。
将事件发送到 eventChannel。
syncLoop 响应事件:
Kubelet syncLoop 从 eventChannel 消费事件。
标记关联的 Pod 需要同步 (syncPod)。
执行 syncPod 操作,比较期望状态与实际状态(包含 PLEG 检测到的变化),驱动 Docker 执行必要操作(如 docker start 重启崩溃容器)。
阶段 2:弃用 dockershim (Kubernetes v1.20+) 及替代方案
Kubernetes 社区决定弃用并最终移除内置的 dockershim (v1.24 正式移除),主要原因:
维护负担: Docker API 变更需要 dockershim 同步更新,增加了 Kubernetes 核心维护成本。
性能瓶颈: docker inspect 调用非常昂贵,尤其是节点上容器数量多时。每个 relist 周期需要执行 N 次 docker inspect (N=Pod Sandbox数量 + Container数量),严重影响 PLEG 性能和节点稳定性,容易触发 PLEG is not healthy。
标准化: CRI 是 Kubernetes 定义的容器运行时标准接口,鼓励更多运行时实现(如 containerd, CRI-O)直接对接,避免适配层开销。
Docker ≠ 容器运行时: Docker 自身是一个包含多个组件(dockerd, containerd, runc)的解决方案。Kubernetes 只需要其底层符合 OCI 标准的容器运行时(containerd),不需要 Docker Engine 的上层功能(如构建、Swarm)。
现在如何使用 Docker 作为运行时?
官方解决方案:cri-dockerd:
这是一个由社区维护的开源项目,独立于 Kubernetes 核心代码。
它实现了 CRI 接口,底层调用 Docker Engine API。
工作原理与 dockershim 类似:
安装 cri-dockerd。
配置 Kubelet 使用 cri-dockerd 的 socket (--container-runtime-endpoint=unix:///var/run/cri-dockerd.sock)。
PLEG 的 relist 过程: Kubelet (PLEG) -> CRI gRPC -> cri-dockerd -> Docker Engine API (docker ps, docker inspect) -> cri-dockerd 转换 -> CRI 响应 -> Kubelet (PLEG)。
性能问题依然存在: cri-dockerd 本质上还是通过 Docker API 轮询和 inspect,在大规模节点上 PLEG 的性能瓶颈问题并未解决。
强烈推荐的替代方案:迁移到 containerd
直接使用 containerd (推荐):
Docker 本身使用的底层容器运行时就是 containerd。
Kubernetes 可以直接通过 CRI 插件 (cri) 与 containerd 通信,完全绕过 Docker Engine。
PLEG relist 过程优化:
Kubelet (PLEG) -> CRI gRPC -> containerd CRI 插件。
containerd 内部维护着 Pod 和容器的状态数据库。
ListPodSandbox / ListContainers 操作直接从 containerd 的内存数据库高效查询完整状态,无需像 Docker 那样对每个容器执行昂贵的 inspect 系统调用。
结果: PLEG relist 操作快几个数量级,显著降低 CPU 开销,极大降低 PLEG is not healthy 风险,提高节点稳定性和可扩展性。
总结与关键点:
历史: Docker 时代,Kubelet 通过 dockershim (或现在的 cri-dockerd) 间接使用 Docker API (docker ps, docker inspect) 获取状态进行 PLEG relist。
核心问题: Docker API inspect 调用开销巨大,是 PLEG 性能和节点稳定性的主要瓶颈,极易导致 PLEG is not healthy 和节点 NotReady。
现状: Kubernetes 已移除内置 dockershim。如需使用 Docker,需部署独立的 cri-dockerd,但其性能瓶颈依旧。
最佳实践: 强烈建议将容器运行时直接切换到 containerd。这是 Docker 的底层引擎,Kubernetes 通过 CRI 直接与其高效通信,PLEG relist 通过查询内存数据库完成,避免了昂贵的 Docker API 调用,从根本上解决了性能问题。
PLEG 视角: 无论底层是 cri-dockerd + Docker 还是 containerd,PLEG 的工作流程(周期 relist -> diff -> 生成事件)是相同的。区别在于底层获取状态信息的效率和方式,这直接决定了 PLEG 的性能和可靠性。
因此,如果你在 Docker 环境下遇到 PLEG 超时问题,最根本的解决方案就是迁移到 containerd,而不是继续使用 cri-dockerd + Docker。
当 Kubernetes 通过 docker inspect 获取容器状态时,实际发生了以下底层操作(以单容器为例)。这些环节揭示了为何 docker inspect 是 PLEG 的性能瓶颈:
- Docker CLI 到 Daemon 通信
CLI 命令解析
docker inspect <container_id> 被 Docker CLI 解析为 API 请求
API 请求发送
通过 UNIX Socket (/var/run/docker.sock) 或 TCP 向 Docker 守护进程 (dockerd) 发送 HTTP 请求:
GET /v1.xx/containers/<container_id>/json - Docker Daemon 处理流程
(1) 元数据查询
dockerd 从本地数据库(通常是 boltdb)查询容器元数据:
// dockerd 伪代码流程
container := daemon.containers.Get(containerID) // 内存缓存查找
if container == nil {
container = boltdb.LoadContainer(containerID) // 从磁盘数据库加载
}
(2) 实时状态收集
dockerd 通过系统调用收集动态运行时状态:
进程状态检查
向容器主进程发送 SIGNAL(0)(空信号)验证存活状态
cgroup 数据采集
访问 /sys/fs/cgroup/ 路径读取:
CPU 使用率 (cpuacct.usage)
内存统计 (memory.stat, memory.usage_in_bytes)
块设备 I/O (blkio.io_service_bytes)
文件系统挂载信息
解析 /proc/mounts 获取 overlay2/aufs 挂载点
网络配置获取
通过 netlink 查询:
网络命名空间路径 (/proc/
IP 地址、MAC 地址、端口映射
(3) 日志与配置整合
合并容器启动配置 (HostConfig, Config)
解析日志文件路径 (/var/lib/docker/containers/
3. 响应构建与返回
JSON 序列化
将收集到的 50+ 个字段组装成 JSON 结构:
{
"Id": "abc123...",
"State": {
"Status": "running",
"Pid": 12345,
"OOMKilled": false,
"Dead": false
},
"NetworkSettings": {
"IPAddress": "172.17.0.2",
"Ports": {"80/tcp": [{"HostPort": "8080"}]}
},
"Mounts": [...],
// 其他 60+ 个字段...
}
HTTP 响应
通过 Socket 返回 JSON 数据(通常 2-10KB)
4. **关键性能瓶颈分析
元数据查询 磁盘 I/O (boltdb 读操作) 和内存缓存未命中 20%
cgroup 读取 同步访问 /sys/fs/cgroup 文件(涉及内核锁竞争) 40%
网络状态获取 netlink 系统调用 + 网络命名空间切换 25%
JSON 序列化 大对象序列化与 Socket 传输 15%
5. 与 containerd 的性能对比
当使用 containerd 时(无需 Docker):
PLEG
CRI-gRPC
containerd
内存状态数据库
零系统调用:状态直接从 containerd 的内存缓存获取
单次批量操作:ListContainers 返回所有容器状态(无需循环调用)
效率差异:
100 个容器场景:
Docker:100 次独立 docker inspect ≈ 2-5秒
containerd:1 次 CRI 调用 ≈ 10-50ms
总结:为什么 docker inspect 是 PLEG 杀手?
系统调用风暴
每个容器触发 10+ 次内核调用(cgroup/netlink/procfs)
磁盘 I/O 放大
大量小文件读写(boltdb + cgroup 文件)
串行执行瓶颈
Kubelet 需顺序处理每个容器(无并发优化)
数据传输冗余
每次返回 60+ 字段的 JSON(实际 PLEG 仅需 3-4 个字段)
💡 根本解决方案:
迁移到 containerd 可消除 90% 的 PLEG 延迟,这也是 Kubernetes 弃用 Docker 集成的主因。
当 docker inspect 容器时,底层会涉及 Linux 内核的多种锁机制。以下是关键锁及其作用原理的深度解析:
- 进程锁 (
tasklist_lock)
- 场景
收集容器主进程状态(如 PID、运行状态)时,需访问/proc/<pid>文件系统。 - 锁机制
内核通过自旋锁tasklist_lock保护进程描述符链表:// Linux 内核源码 (kernel/fork.c) raw_spinlock_t tasklist_lock __cacheline_aligned;
争用风险
高并发场景下(如节点运行 100+ 容器),多个 docker inspect 同时遍历进程链表会引发锁竞争,导致延迟抖动。
2. cgroup 锁 (cgroup_mutex)
场景
读取容器的 CPU/内存统计(如 /sys/fs/cgroup/cpu/docker/
锁机制
cgroup 子系统使用互斥锁 cgroup_mutex 保护控制文件操作:
// Linux 内核源码 (kernel/cgroup/cgroup.c)
static DEFINE_MUTEX(cgroup_mutex);
性能影响
该锁是全局互斥锁,导致所有 cgroup 文件访问串行化。当大量容器同时被 inspect 时,cgroup 读取延迟显著上升。
3. 网络命名空间锁 (net->nsid_lock)
场景
获取容器的网络信息(IP、端口映射)需进入其网络命名空间。
锁机制
网络命名空间通过读写锁 nsid_lock 保护:
// Linux 内核源码 (net/core/net_namespace.c)
struct net {
rwlock_t nsid_lock;
};
竞争特点
多个 docker inspect 可并发读 (read_lock),但写入操作(如更新路由表)需独占写锁 (write_lock),导致读写互斥。
4. 文件系统锁 (vfsmount_lock)
场景
查询容器挂载点信息(如 OverlayFS 层)。
锁机制
虚拟文件系统 (VFS) 使用读写锁 vfsmount_lock 保护挂载点链表:
// Linux 内核源码 (fs/namespace.c)
static DECLARE_RWLOCK(vfsmount_lock);
瓶颈分析
遍历挂载点时需获取读锁,但频繁的文件系统操作(如容器创建/销毁)会触发写锁,阻塞 inspect 操作。
5. Docker 内部元数据锁
(1) 容器对象锁 (mapLock)
场景
dockerd 在内存缓存中查找容器元数据。
锁机制
Go 的 sync.Map 或 sync.RWMutex 保护容器对象映射:
// dockerd 源码 (daemon/daemon.go)
type Daemon struct {
containers sync.Map // map[string]*container.Container
}
优化缺陷
尽管 sync.Map 支持并发读,但写入(如容器状态更新)会触发内部锁升级,导致短暂阻塞。
(2) 存储驱动锁 (layerStoreLock)
场景
访问 OverlayFS/Btrfs 的镜像层信息。
锁机制
Docker 存储驱动使用互斥锁保护层元数据:
// dockerd 源码 (daemon/graphdriver/driver.go)
type Driver struct {
lock sync.Mutex
}
⚠️ 锁争用引发的典型问题
cgroup_mutex PLEG 延迟飙升 node_cgroup_contention_seconds
tasklist_lock 系统负载高但 CPU 利用率低 vmstat -s 查看 spin_lock
nsid_lock 网络配置查询超时 netstat -s 中的 lock_dropped
vfsmount_lock 挂载点信息返回缓慢 dmesg 中的 VFS lock contention
性能优化实践
升级内核
Linux 5.8+ 优化了 cgroup_mutex 粒度(引入 per-cgroup 锁)
减少 inspect 调用
使用 docker inspect --format 仅获取必要字段
终极方案
迁移到 containerd:
containerd
内存状态数据库
零锁状态查询
CRI 批量响应
避免所有内核锁争用
状态查询速度提升 50-100 倍
💡 关键结论:docker inspect 的性能瓶颈本质是内核锁争用与元数据串行访问的综合结果,这是 Docker 架构无法彻底解决的问题。Kubernetes 弃用 Docker 而转向 containerd 是根本性优化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号