
Map集合
Map集合:
1,双列集合,一个元素包含两个值(key value)
2,两个值的元素可以相同,也可以不同
3,key值不允许重复,value可以重复
4,key value 一一对应
HashMap特点:
1.集合底层是哈希表,线程不安全(多线程,速度快) java1.8之前:数组+单向链表 1.8之后:数组+单向链表/红黑树(当链表长度超过8时):提高查询速度
2.无序
3.LinkedHashMap继承HashMap集合
4.可以存储null值
package MapTest; import java.util.HashMap; import java.util.Map; public class MapDemo { public static void main(String[] args) { show1(); show2(); } /** * remove、get方法的测试案例 key存在,返回的是删除的value值;若不存在,返回null */ private static void show2() { Map<String,Integer> map=new HashMap<>(); map.put("laura",20); map.put("lili",22); map.put("ning",23); System.out.println(map); Integer i=map.remove("lili");//用Integer类型 接收,若不存在,会报空指针异常 System.out.println(map.remove("lily")); System.out.println(i); System.out.println(map); System.out.println(map.get("ning"));//返回值23 System.out.println(map.containsKey("laura")); } /** * put方法的测试案例 */ private static void show1() { Map<String,String> map=new HashMap<>(); //key值不重复,返回nul String s1=map.put("a","A"); System.out.println(s1); //key值重复时,返回被替换的value值 String s2=map.put("a","B"); System.out.println(s2); //此时集合中只有一个替换后的键值对 System.out.println(map); //value值可以重复 map.put("c","C"); map.put("d","D"); map.put("e","D"); System.out.println(map); } }
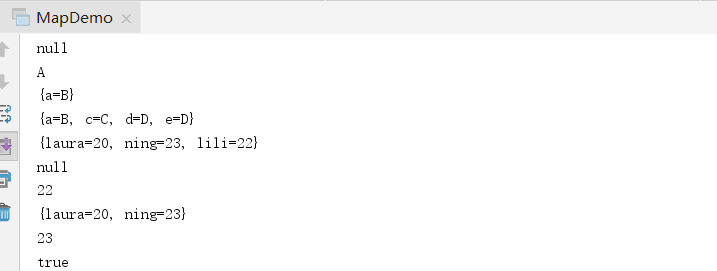
通过map集合的key找到对应的value,对Map集合的遍历
步骤:1.map的keySet方法把map集合中的key放在Set集合中;keySet方法的返回值是Set类型
2.遍历Set集合,通过map集合的get方法,得到Set集合中每个key对应的value]
/** * map集合的遍历 */ private static void show3() { Map<String,Integer> map=new HashMap<>(); map.put("laura",20); map.put("lili",22); map.put("ning",23); Set<String> set=map.keySet();//返回的就是一个存储map的key的Set集合 //set.add(map.keySet()); Iterator<String> i=set.iterator(); while (i.hasNext()){ String key=i.next(); Integer value=map.get(key); System.out.println(key+"="+value); } System.out.println(); for (String s:set) { Integer value=map.get(s); System.out.println(s+"="+value); } }
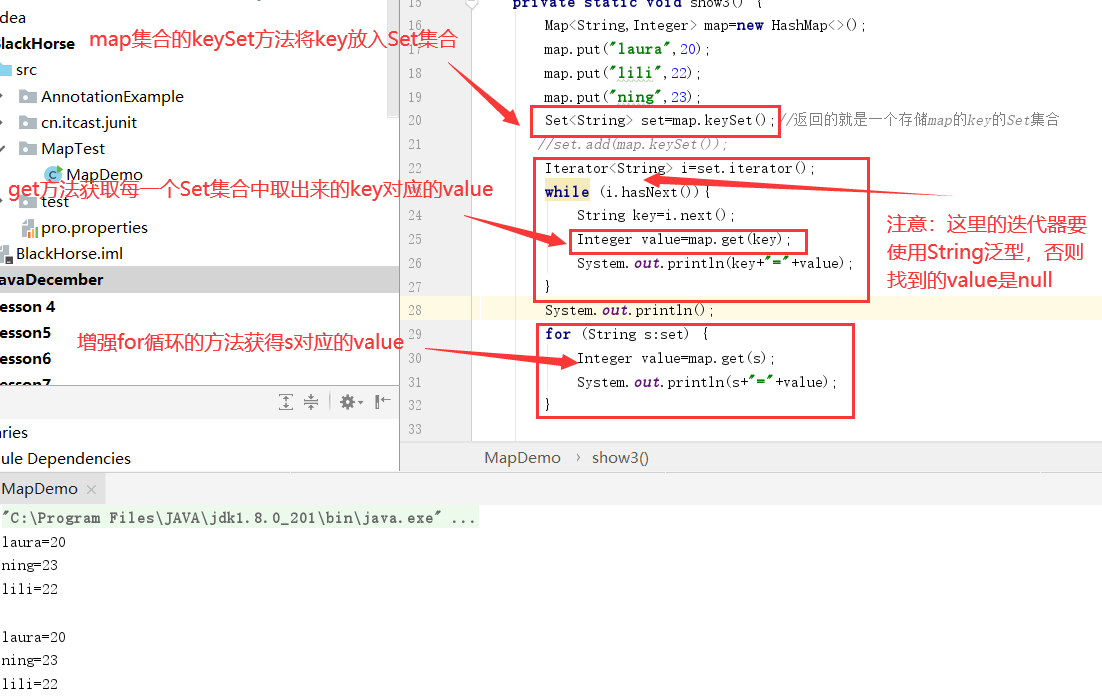
注:开始想到遍历map集合获取它的key和vaule,不现实!!
Entry对象:当Map集合一创建,就会在map集合中创建一个Entry对象,用来记录键值对 ;可用entrySet方法遍历Map集合存储在Set集合中。分别通过getKey 和getValue方法获取Entry对象中的key和Value.
/** * map集合遍历的第二种方式:Entry对象 */ private static void show() { Map<String,Integer> map=new HashMap<>(); map.put("laura",20); map.put("lili",22); map.put("ning",23); Set<Map.Entry<String,Integer>> set= map.entrySet(); for(Map.Entry<String,Integer> entry:set){ System.out.println(entry); //System.out.println(entry.getKey()+"="+entry.getValue()); } }
HashMap自定义类:
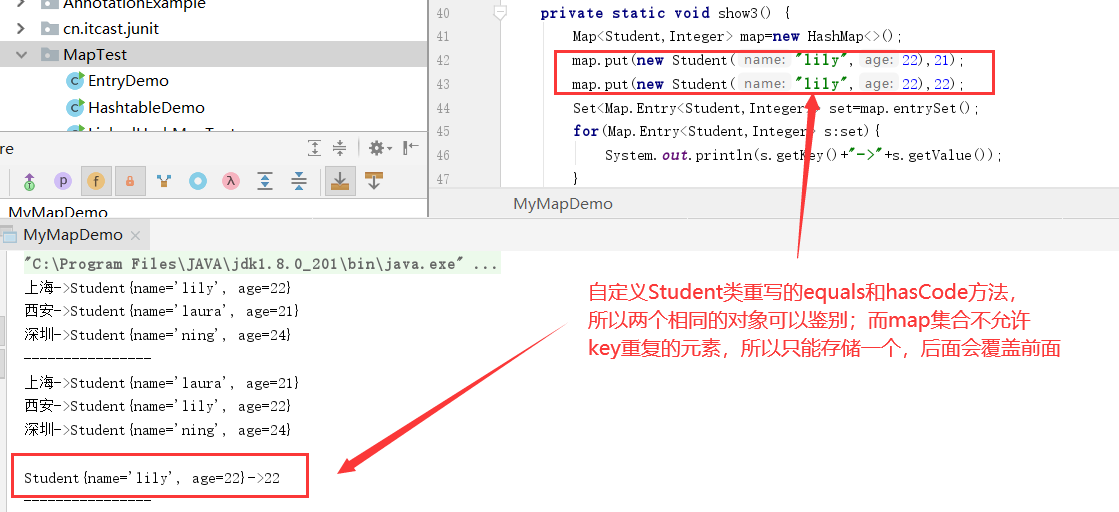
HashMap集合的自定义类的排序:自定义的Student类

注:难点主要在泛型的一致性上,以及Collections的sort方法的参数问题。
或者,可以直接在List集合中存入Student对象,然后ArrayList的构造器里面写上map集合的key;再直接用compare方法比较。
List<Student> list=new ArrayList<Student>(map.keySet()); Collections.sort(list,new Comparator<Student>(){ @Override public int compare(Student s1, Student s2) { return s1.getAge().compareTo(s2.getAge()); } }); System.out.println(list.toString());
也可以比较包装类型的排序:compare方法更为简单

完整代码:
package MapTest; /** * @since 2002/1/26 27 */ import java.util.*; public abstract class MyMapDemo { public static void main(String[] args) throws Exception{ show1(); System.out.println("----------------"); show2(); System.out.println("----------------"); show3(); System.out.println("----------------"); show4(); System.out.println("----------------"); show5(); } private static void show1() { Map<String,Student> map=new HashMap<>(); map.put("西安",new Student("laura",21)); map.put("上海",new Student("lily",22)); map.put("深圳",new Student("ning",24)); Set<String> set=map.keySet(); for (String s:set) { Student student=map.get(s); System.out.println(s+"->"+student); } } private static void show2() { Map<String,Student> map=new HashMap<>(); map.put("西安",new Student("lily",22)); map.put("上海",new Student("laura",21)); map.put("深圳",new Student("ning",24)); Set<Map.Entry<String,Student>> set=map.entrySet(); for(Map.Entry<String,Student> s:set){ System.out.println(s.getKey()+"->"+s.getValue()); } } private static void show3() { Map<Student,Integer> map=new HashMap<>(); map.put(new Student("lily",22),21); map.put(new Student("lily",22),22); Set<Map.Entry<Student,Integer>> set=map.entrySet(); for(Map.Entry<Student,Integer> s:set){ System.out.println(s.getKey()+"->"+s.getValue()); } } public static void show4() { Map<Student,Integer> map=new HashMap<Student,Integer>(); map.put(new Student("lily",22),21); map.put(new Student("laura",21),22); map.put(new Student("ning",24),18); // Set<Map.Entry<Student,Integer>> set=map.entrySet(); List<Map.Entry<Student,Integer>> list=new ArrayList<Map.Entry<Student, Integer>>(map.entrySet()); Collections.sort(list,new Comparator<Map.Entry<Student,Integer>>(){ @Override public int compare(Map.Entry<Student,Integer> o1, Map.Entry<Student,Integer> o2) { return o1.getKey().getAge().compareTo(o2.getKey().getAge()); } }); for (Map.Entry<Student,Integer> mapping : list) { System.out.println(mapping.getKey() + ":" + mapping.getValue()); } } public static void show5(){ HashMap<Integer,String> hashMap = new HashMap<>(); hashMap.put(400,"dd"); hashMap.put(3,"cc"); hashMap.put(2,"bb"); hashMap.put(1,"aa"); System.out.println(hashMap); //将keySet放入list ArrayList<Integer> list= new ArrayList<>(hashMap.keySet()); //调用sort方法并重写比较器进行升/降序 Collections.sort(list, new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { return o1>o2?1:-1; } }); Iterator<Integer> iterator = list.iterator(); //迭代排序后的key的list while ((iterator.hasNext())){ Integer key = iterator.next(); String value = hashMap.get(key); System.out.print(key+"="+value+","); } } }

注:show1 show2 方法主要判别自定义类存储进Map集合的两种遍历;show3方法主要判断该自定义是否重写equals和hasCode方法,以及map集合的特点,不允许存相同的key值元素;show4方法主要实现自定义类的比较,需要实现comparator接口的比较,需要注意泛型的一致性,以及Collections类的sort方法的参数,以及Entry对象需要得到它的Key或者Value再去得到对应的属性;show5方法主要实现了包装类型的compare方法重写。
LinkedHashMap(简单): key值不允许重复; 有序, 保证存入顺序与取出顺序一致(类似于LinkedHashSet); 集合底层是哈希表+链表

Hashtable:不可以存储null值;是单线程的,属于线程安全,速度慢;和Vector一样,在1.2版本之后被HashMap取代,子类Properties依然活跃,是一个唯一一个和IO流相结合的集合。
package MapTest; import java.util.HashMap; import java.util.Hashtable; public class HashTableDemo { public static void main(String[] args) { /** * 可以存放null值 */ HashMap<Integer,Integer> map=new HashMap<>(); map.put(null, 2); map.put(3, null); map.put(null, null); System.out.println(map); /** * 存放含null的key或者value都会报 NullPointerException异常 */ Hashtable<Integer,Integer> table=new Hashtable<>(); table.put(null, 2); table.put(3, null); table.put(null, null); System.out.println(table); } }
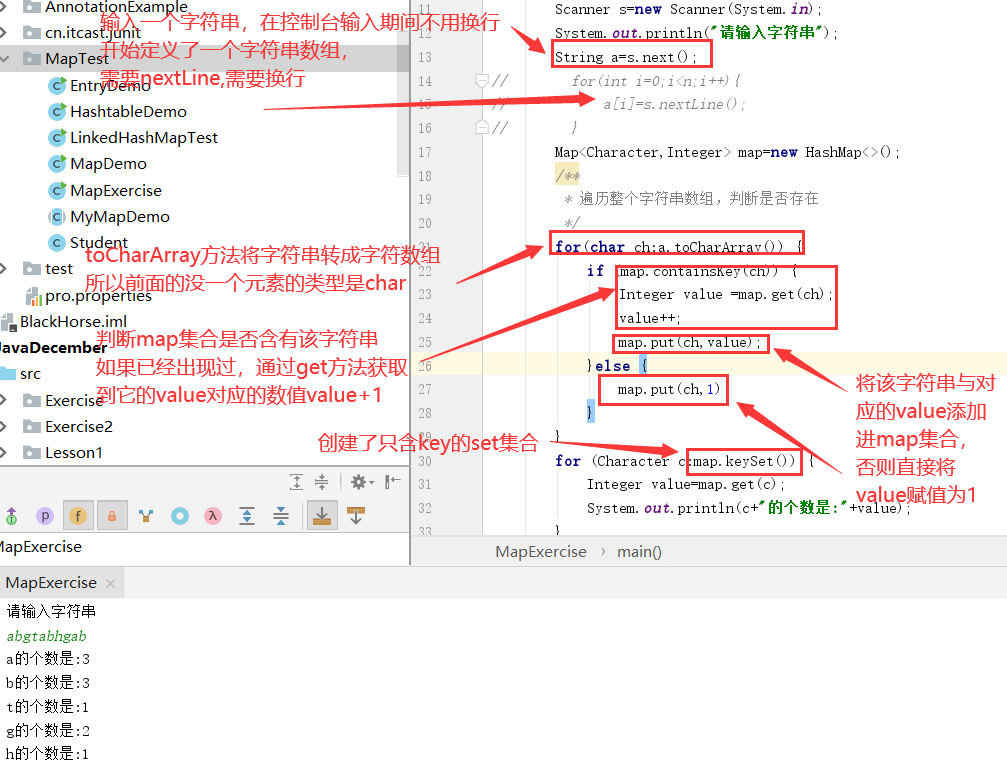
练习:输入一个字符串,获取一个字符串中每个字符的个数
Treemap:
TreeMap 是一个有序的(大小顺序,而非插入顺序)key-value集合,非同步,基于红黑树(Red-Black tree)实现,每一个key-value节点作为红黑树的一个节点。TreeMap存储时会进行排序的,会根据key来对key-value键值对进行排序,其中排序方式也是分为两种,一种是自然排序,一种是定制排序,具体取决于使用的构造方法。
自然排序:TreeMap中添加的key元素类型必须实现Comparable接口,并重写compareTo(),并且所有的key都应该是同一个类的对象,否则会报ClassCastException异常。
定制排序:定义TreeMap时,创建一个comparator比较器对象,该对象对所有的treeMap中所有的key值进行排序,采用定制排序的时候不需要TreeMap中所有的key必须实现Comparable接口。
TreeMap判断两个元素相等的标准:两个key通过compareTo()方法返回0,则认为这两个key相等。
如果使用自定义的类来作为TreeMap中的key值,且想让TreeMap能够良好的工作,则必须重写自定义类中的equals()方法,TreeMap中判断相等的标准是:两个key通过equals()方法返回为true,并且通过compareTo()方法比较应该返回为0。
Map底层总结:
我们创建一个HashMap的时候,如果没有指定其容量,那么会得到一个默认容量为16的Map;HashMap中,有两个比较容易混淆的关键字段:size和capacity ,这其中capacity就是Map的容量,而size我们称之为Map中的元素个数。在JDK 8中,关于默认容量的定义为:static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 ,其故意把16写成1<<4,就是提醒开发者,这个地方要是2的幂。
作为默认容量,太大和太小都不合适,所以16就作为一个比较合适的经验值被采用了。
为了保证任何情况下Map的容量都是2的幂,HashMap在两个地方都做了限制。
首先是,如果用户制定了初始容量,那么HashMap会计算出比该数大的第一个2的幂作为初始容量。
另外,在扩容的时候,也是进行成倍的扩容,即4变成8,8变成16。
当HashMap中的元素个数(size)超过临界值(threshold 16*0.75)时就会自动扩容,扩容成原容量的2倍,即从16扩容到32、64、128 ...
HashMap和HashTable的异同点:
1、继承的父类不同
Hashtable继承自Dictionary类,而HashMap继承自AbstractMap类。但二者都实现了Map接口。
2.线程安全性不同
HashMap中的方法在缺省情况下是非Synchronize的。在多线程并发的环境下,可以直接使用Hashtable,不需要自己为它的方法实现同步,但使用HashMap时就必须要自己增加同步处理。
3、是否提供contains方法
HashMap把Hashtable的contains方法去掉了,改成containsValue和containsKey,因为contains方法容易让人引起误解。
Hashtable则保留了contains,containsValue和containsKey三个方法,其中contains和containsValue功能相同。
4.是否允许null值
Hashtable中,key和value都不允许出现null值。
HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。
5.两个遍历方式的内部实现上不同
Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。 5 通过 Iterator 迭代器遍历时,遍历的顺序不同HashMap 是“ 从前向后”的遍历数组;再对数组具体某一项对应的链表,从表头开始进行遍历。
Hashtable 是“ 从后往前”的遍历数组;再对数组具体某一项对应的链表,从表
头开始进行遍历。
6 容量的初始值 和 增加方式都不一样
HashMap 默认的容量大小是16;增加容量时,每次将容量变为“ 原始容量x2”。
Hashtable 默认的容量大小是 11;增加容量时,每次将容量变为“ 原始容量 x2+1"
7 添加 key-value 时的 hash 值算法不同
HashMap 添加元素时,是使用 自定义的哈希算法。
Hashtable 没有自定义哈希算法,而 直接采用的 key 的 的 hashCode() 。
8 部分 API 不同
Hashtable 支持 contains(Object value) 方法,而且重写了 toString()方法。
而 HashMap 不支持 contains(Object value) 方法,没有重写 toString()方法。
ConcurrentHashMap补充:
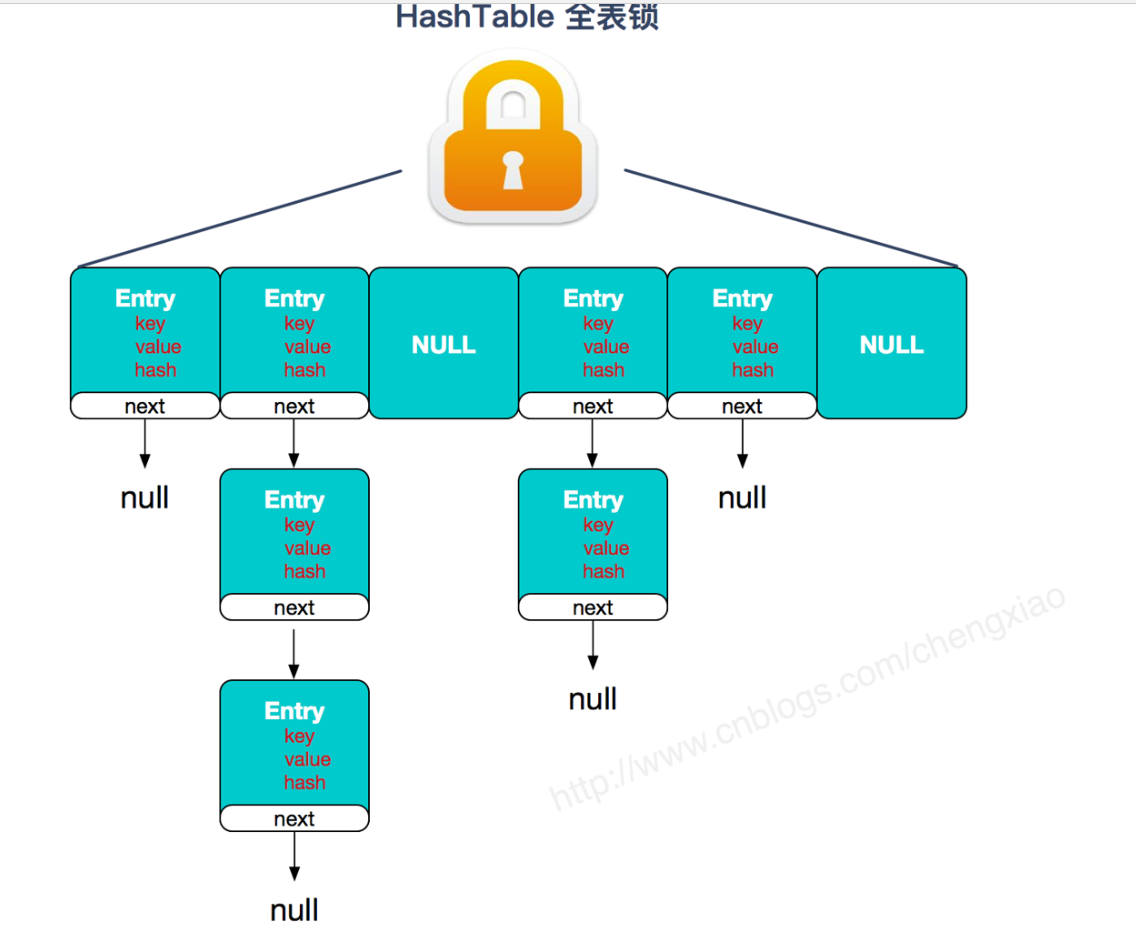
HashTable性能差主要是由于所有操作需要竞争同一把锁,而如果容器中有多把锁,每一把锁锁一段数据,这样在多线程访问时不同段的数据时,就不会存在锁竞争了,这样便可以有效地提高并发效率。这就是ConcurrentHashMap所采用的"分段锁"思想。
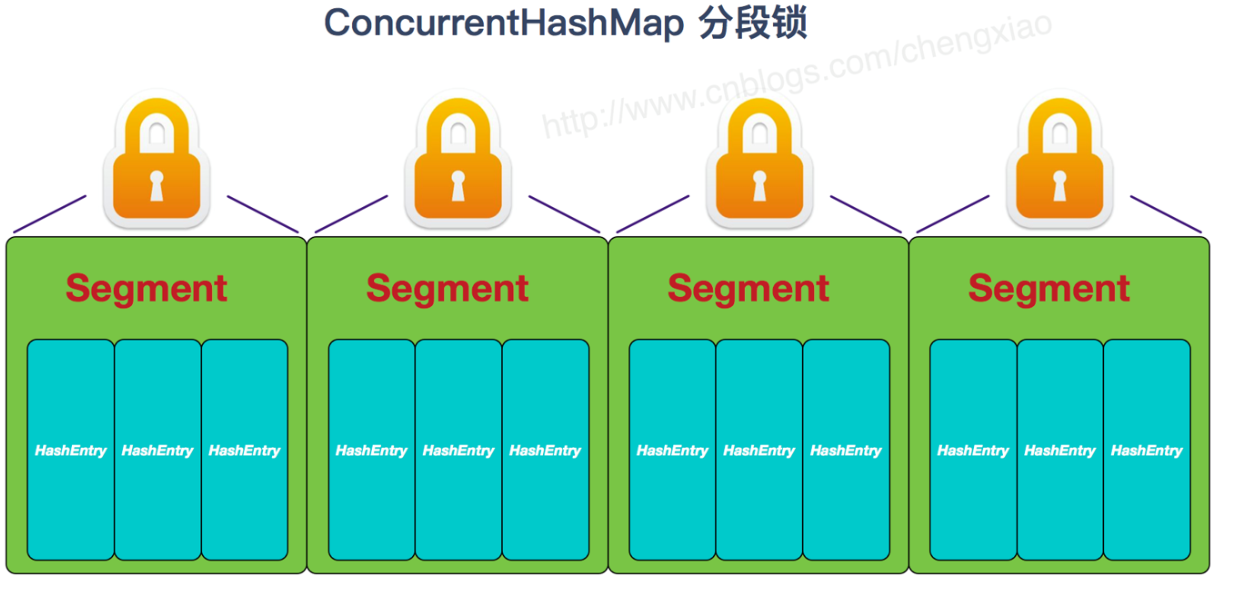
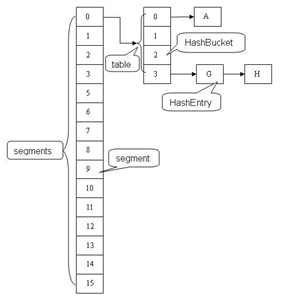
ConcurrentHashMap采用了非常精妙的"分段锁"策略,ConcurrentHashMap的主干是个Segment数组。
final Segment<K,V>[] segments;
Segment继承了ReentrantLock,所以它就是一种可重入锁(ReentrantLock)。在ConcurrentHashMap,一个Segment就是一个子哈希表,Segment里维护了一个HashEntry数组,并发环境下,对于不同Segment的数据进行操作是不用考虑锁竞争的。(就按默认的ConcurrentLeve为16来讲,理论上就允许16个线程并发执行,有木有很酷)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号