从壹开始微服务 [ DDD ] 之终篇 ║当事件溯源 遇上 粉丝活动
回首
哈喽~大家好,时间过的真快,关于DDD领域驱动设计的讲解基本就差不多了,本来想着周四再开一篇,感觉没有太多的内容了,剩下的一个就是验证的问题,就和之前的JWT很类似,就不打开一个章节了,而且这个也不是领域驱动设计范畴之内的,下一个系列 Ids 的讲解中,可能会穿插着讲一讲,然后到时候正好一起完善了。
虽然是完结了,不过心里还是不是很开森呀,通过小伙伴的反馈,然后我也咨询了官方的建议,好像这个DDD领域驱动设计系列,并没有得到很多的支持,影响力完全比不过第一个系列《从壹开始前后端分离》,原因可能是,我也没有在项目中真正的使用过DDD的原因吧,也或许是写的比较生硬,主要我也一直在研究,不过我这里一定要说一下,还是要多看看的,不一定要看我讲的,可以看看书也行,或者看看别人的博客,DDD领域驱动设计思想真的很不错,然后还夹带着CQRS命令查询职责分离、Bus总线思想、EDA事件驱动思想、ES事件溯源思想(今天要说到的)、
举个溯源的例子(我瞎想的):
可能不是很恰当,也可能他们根本不是这么做的,我只是用这个感觉来说明什么是溯源:
大家在玩儿消消乐的时候,偶尔会遇到这个情况,比如玩儿了二十步的时候,突然闪退了,然后我们重新进去,重新进这一关的时候,会看到系统快速的把我们的这二十步进行了还原,有一个过程步骤,也许没人注意,那我想问下,这个是怎么保存的呢?难道直接获取的当前关卡的状态么,有一丝丝的溯源的意味。
大家自己思考其他的例子,比如银行查账,每天的数据汇总等等。
消息队列等等这些以前没有接触到的思想设计,也为微服务打下了一定的基础,如果没有这些基础,你是很难理解为什么要使用微服务的,这里我们就先来回顾一下这些天我们都说了什么内容吧:
- 我们第一次开始讨论DDD领域驱动设的概念已经我的个人计划书
- DDD入门 & 项目整体的第一次搭建
- 领域、子域、限界上下文
- 又一次讨论了DDD设计思想的重大意义 以及使用EFCore
- 实体 与 值对象
- 聚合 与 聚合根
- 第一次把项目跑通,然后也简单说了下 CQRS
- 剪不断理还乱的 值对象和Dto
- 明白领域验证
FluentValidator - 命令总线 Bus 分发(一)
- 事件驱动 EDA 详解
算上今天的内容,正好是十二篇,也是我的比较喜欢的一个数字(之前在文章中说到过这个原因,这里就不多说了),也是很辛苦写了这么多,希望有时间有精力的时候,还是要多看看的,多品品思想,这样我们就不会一直问一些虚无缥缈的问题了,虽然我现在是越学的多,越不会的多😂。
可能你也发现了今天的题目有些不一样,因为我之前说过,要在圣诞节简单搞个小活动,既然说了,就不能食言,不过目前我写了十六万字了,就一个小伙伴给了我一块钱红包😂,好失败,所以我就简单来个小福利吧,因为这个系列的名字就是Christ3D,当时就是想着在圣诞节前能说完,还可以,紧赶慢赶的说完了,我就想着一个给粉丝一个小小小福利:
具体的参与形式看文章末尾:(已结束)
1、免费给送三本书,可能是《实现领域驱动设计》这本书,或者《领域驱动设计 软件核心复杂性应对之道》,还有我本人的签名+贺卡哟哈哈;
2、本来想抽十位粉丝,送精装的圣诞节苹果,但是考虑食品安全问题就算了,直接到时候发红包吧(时间地点保密,提示:为了老粉丝);
缘起
言归正传,今天的重点还是要好好的说说新知识——事件溯(su)源,Event Source,也有人翻译事件采购,或者是事件回溯,或者直接就是ES,其实都是一个意思,要是下次你发现这几个词语的时候,都是指的事件溯源,其实事件溯源已经有一只脚迈进了微服务的大家族了,甚至可以说已经在微服务的一员了,他配合着事件总线EventBus、消息队列等,在微服务的工作中起着一定的作用。当然今天只是简单的入门讲解,要是想打开真正的微服务的大门,就需要大家自己去探索,当然,我也会继续跟进这个讲解,下一个系列 Ids ,其实也是微服务的一个分支,慢慢来,希望大家多捧场啦!
马上开始今天的讲解,还是一天一问吧,希望大家带着这个问题通读本文,自己能想到合适的答案:
1、你认为事件存储 EventStore 和 日志记录的区别是什么?
这里要给大家再强调两点:
1、CQRS、EDA和ES这些其实已经不在DDD设计的范围之内,只不过这些技术都是一起使用的,多个技术的相互结合使用,才能发挥很大的作用,所以说本系列教程是
DDD+CQRS+EDA+ES的结合体,以后被别人问到的时候,可别说事件溯源就是领域驱动设计的一部分哟。
2、事件溯源不是一两句能说清的,这篇文章只是一个启蒙的作用,等大家从事微服务工作的时候,就知道它深层次的意义了,切不可和平时的 CURD 项目生搬硬套做比较。
零、今天要实现右下角绿色的部分
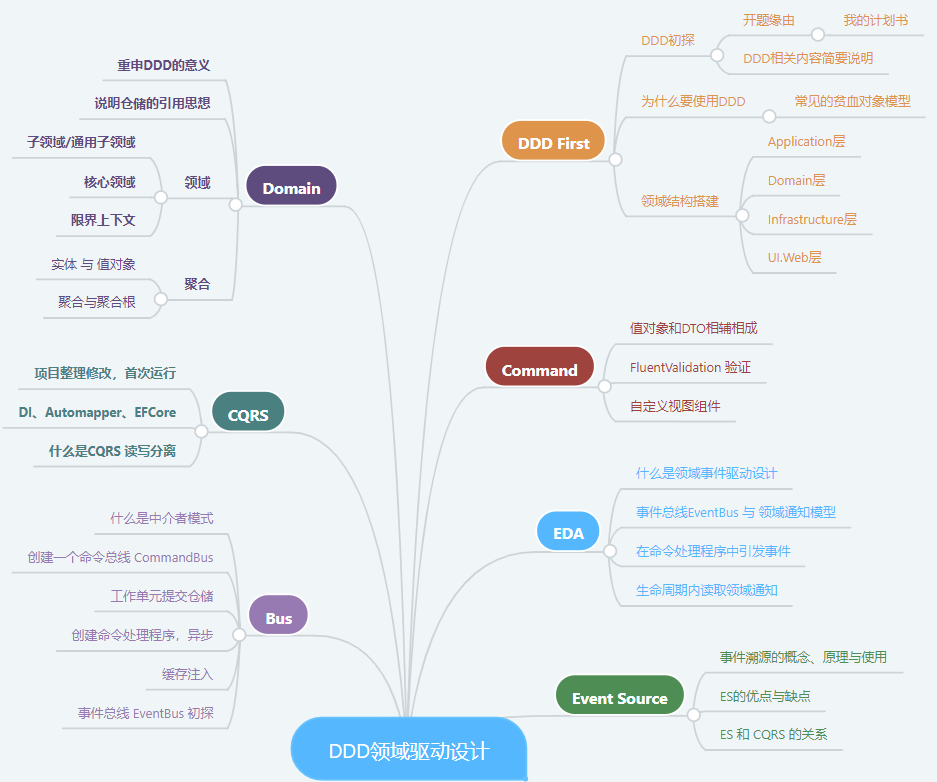
(我写的十二篇文章中的知识点,这里基本都有了,也算是一个圆满了,集齐七颗啦😀)
一、什么是事件溯源 —— Event Source
事件溯源其实很好理解,首先从字面上的理解:
事件就是 Event,溯是一个动词,可以理解为追溯,回溯的意思,源代表原始、源头的意思,合起来表示一个事件追踪源的过程。
1、理解事件溯源的概念
2、事件溯源的执行过程
这个时候你仔细想一想,我们在和领域专家(默认他们不懂技术)讨论用户下单流程的时候,专家一定会说:客户首先选择一个商品,然后添加到购物车,确认无误下单,接着用户支付,支付成功后,就给用户发货。而我们呢,我们作为一个开发人员,和领域专家讨论的时候,自然而然的也是这么思考的,对不对!(你肯定在讨论需求的时候用的不是数据库的思维!),只不过我们后期开发的时候,拘泥于技术和数据优先的思维,不得不转向CURD的道路了,当然这个没有什么错误,我只是说明一点,事件存储真的离我们不远。
那我们平时是怎么做的呢,这里说一个特别简单的:
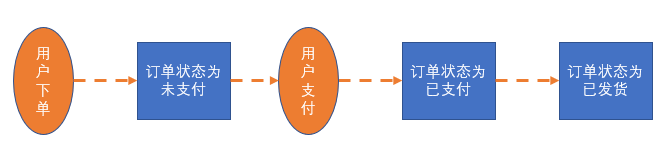
从这个特别简单的流程中我们可以看到,平时我们都是直接操作的 Order 这个领域聚合根,一直在修改模型状态,这个看似正常的操作下,有一些问题,是我们建立在每一步都正常执行的情况下,不过一般总会出现一些问题,特别是分布式的环境中。
然而,事件溯源与上述的情况恰好相反,它并不关心当前状态,而是关注持续不断的变化事件。
举个例子,假设我们有一个“购物车”,我们可以创建购物车,往里面添加商品或移除商品,然后结账。
购物车的生命周期可以包含如下一系列事件:
创建购物车
往购物车里添加商品
再次往购物车里添加商品
从购物车里移除商品
结账
这些就是一个购物车的生命周期,包含了一系列事件。这就是事件溯源,非常简单吧?

几乎所有的流程都可以被看成一系列事件。在与领域专家交谈时,他们不会提及“表”和“连接”,他们会将流程描述成一系列事件以及可以应用在这些事件上的规则。
3、事件溯源是如何更新实时状态的

二、事件溯源的存在意义与问题
事件溯源不是万能的,不过它可以在某一些领域发挥很大的作用,这个在以后的微服务设计中,会更能体现出来,那我们就简单说两点:
1、传统应用中出现的某些问题
从业务的角度
传统的应用中,数据库里存的是Domain Model的实例的当前状态,比如某个储户银行账户的存款数,通常是一个数字.如果考虑到如下的三个情形,我们可能付出的代价比较大:
1) 老规则:问题跟踪
如果某个储户的账户出现问题,那么我们只有从大到PB的日志中去分析用户的账户数据是如何出错的,而且我们在做日志的时候,不可能所有的都考虑到,就算是把全部数据都保存,时间都记下来,操作者都备份,那ATM机信息呢?(可能不恰当,只是说明我们总有想不到的地方),但如果一旦日志不够详细,找出问题根源基本只能靠猜了。
2) 新需求:趋势分析
历史数据的作用在于分析未来的趋势,如果仅仅从浩如烟海的日志中寻找规律,我们还得单独写逻辑,对日志进行建模,清洗,其实我们已经能接受,日志就是用来记录异常信息的,这个时候我们就很崩溃了。
3) 更奇葩:事务回滚
在介绍事务修正模式中,我们讲到某个步骤发生错误,之前的各个节点可以自己独立地完成回滚,回滚的依据就是记录的操作步骤及相关参数,根据这些有用信息就可以每个节点自行回滚到原始状态,并且在失败的时候可以retry
可见存储对于Domain Model 的各个事件还是非常有用的,尤其是对于复杂的系统,这也就是我们今天要讨论的事件溯源模式.
从技术角度
大多数的应用都和数据打交道,最常见的打交道方式就是将用户在使用过程中的数据最终状态同步到数据库中。例如,在传统的增删改查(CURD)模式中,一个典型的数据过程就是从数据库中读出数据,修改完后再把修改后的数据更新到数据库中——通常来说,在这个更新过程这张数据表是被锁住的。
这种传统的增删改查(CURD)方式存在一些局限性:
- 事实上执行这种直接依赖数据库的增删改查(CRUD)开销会影响系统的性能和响应性,不利于系统的可伸缩性。
- 在一个存在多个用户并发操作的领域中,因为多个用户也许会同时操作同一张表,所以数据更新造成的冲突更加可能发生。
- 除非系统额外有一个可以记录所有业务细节的日志系统以实现审查机制,否则所有的历史都会丢失。
这是一个大问题。在以表作为驱动的系统里,你只保存了系统的当前状态,你根本就无法知道系统是如何达到当前状态的。如果我问你“这个用户修改了几次邮件地址”,你有办法回答吗?或者我再问“有多少人把一件商品添加到购物车里,然后又移除掉,直到一个月之后才买了那件商品”,你就更没法回答了。你存储数据的方式丢掉了很多有用的业务信息!
2、我们有哪些理由使用Event Sourcing(优点)
尽管它是一个简单的模式,但使用它有很多优点:
事件日志具有很高的商业价值;
它在DDD和事件驱动架构下运行得非常好。
调试用应用程序状态中所有变更的来源;
它允许您重放失败的事件;
易于调试,您可以将目标实体的所有事件复制到您的机器并调试每个事件,以了解应用程序如何达到特定状态(忽略从生产环境复制数据的安全隐患);
允许您使用追溯事件模式重建/修复您的状态。
许多作者还将优先级作为时间查询的能力,但我认为查询多个后续事件不是一项简单的任务。因此,我通常认为时间查询是快照模式的一个优点。
有许多理由使用Event Sourcing,当你浏览Greg Young的系列文章和谈话你会发现下面要点:
1. 它不是一个新概念,真实世界中许多领域都很像它,看看你的银行账户状态,比如储蓄卡,它打印出一笔笔进出明细和当前余额,这一笔笔代表了领域事件。
2.通过重播事件,我们能够得到对象的任何时刻状态(这里应该用正确术语:聚合aggregate),比如储蓄卡每笔记录的当前余额代表你这个账户聚合对象的某刻时刻的状态,这可能会极大地帮助我们理解领域知识,当前状态是怎么来,因为什么改变?方便调试关键问题的错误
3.领域中当前状态和存储数据库中的数据没有任何耦合,而传统上我们都是将应用状态存储到数据库中,比如储蓄卡当前余额100元存储到数据库中,现在我们存储导致余额的进出事件了,存款了多少钱,取
款了多少钱,这一笔笔领域事件都会记录在数据库中。
4.Append-only追加模型存储这些事件,易于扩展,这样我们无论读写都有很好地性能,读取能够转为查询优化,也可以转为写优化(因为没有读,写得很快),读写分离。
5除了可以存储用户意图数据,也就是操作事件,事件存储顺序能够用来分析用户正在做什么,通往大数据。
6.我们能避免了对象与关系数据库的不匹配。
7.审计日志是免费的,一次审计日志所有变化,因为没有状态改变,只有事件。
这样不会浪费时间吗?
一点也不。一般来说,要执行约束,只需要获得事件的一个很小子集。通过简单的数据库查询就可以获得有用的历史事件,在加载完这些事件后重放它们,把它们“投射”出来,以此构建你的数据集。这样的操作其实是很快的,因为你使用的是本地的处理器,而不是执行一系列SQL查询(跨域网络的调用要比本地操作慢得多,至少会相差两个数量等级)。
你可以在后台构建数据集,然后把中间结果保存在数据库里。这样,用户就可以在很短的时间内查询到这些数据。
3、事件溯源存在的一些问题(缺点)
下面是一些困难:
1.定义事件是一件艺术,需要熟悉的领域建模,DDD领域驱动设计是关键。
2.需要软件和硬件支持事件采购,在以后几年,你会看到这个领域的很多解决方案。
3.这方面是新生事物,可指导的经验太少。
4.限制与真正成熟的DDD/ES技能。
其他带来的问题还有:
1.需要超级大的存储消耗。云存储解决。
2.比较慢也不是问题,因为我们优化优化IO来实现快照和持久。并利用基于事件的天然“推”性质,我们可以得到立即失效缓存。简而言之,能够过后有多个插入,需要这种多个的技术解决方案。
3.脆弱(丢失失过去的一个事件将导致整个流腐败)不是一个问题,因为你可以决定自己的SLA水平去(通过复制和冗余)。使用Git的方法,可以可靠地检测在任何一个副本的腐败事件包括SHA1签名针对它的内容和以前的事件签名计算。
-
在同步调用中不太直观,因为需要首先将请求转换为事件。
-
无论何时部署重大更新,如果您想要向后兼容(也称为“事件升级”),你将被迫迁移事件历史记录。
-
某些实现可能需要额外的工作来检查最新事件的状态,以确保所有事件都已被处理。
-
事件可能包含私有数据,所以不要忘记确保事件日志得到适当保护。
4、什么时候使用这种模式
这种模式在以下几种场景中是最理想的解决方案:
- 当你想获得数据的“意图”,“目的”或者“原因”的时候。 例如,一个客户的实体改变可能用一系列的类似于”搬家“,”注销账户“或者”死亡“等事件类型。
- 并发更新数据时候非常需要减少或者完全避免冲突的时候。
- 当你需要保存已经发生的事件,并且能够重播他们来还原到某个状态、使用这些事件去回滚系统的某些变化或者仅仅是历史或者审查记录的时候。例如 ,当一个任务包括几个步骤,你可能需要执行一个撤销更新的操作然后重播过去的每个步骤来回到稳定的状态。
- 当使用事件是一些应用程序的某些操作的天然属性,并且需要很少的额外扩展或者实施的时候。
- 当你需要把插入,更新数据和需要执行这些操作的应用程序解耦开的时候。用这种模式可以提高UI的性能,或者把这些事件分发给其他的监听者,比如有些应用程序或系统,它们在一些事件发生的时候必须做出一些反应。例如,将一个工资系统和一个报销系统结合起来,这样的话当报销系统更新一个事件给事件数据库,数据库对此做出的相应事件就可以被报销系统和工资系统共享。
- 当要求变更或者——当和CQRS配合使用的时候——你需要适配一个读的模型或者视图来显示数据,而你想要更灵活地改变物化视图的格式和实体数据的时候。
- 当和CQRS配合使用的时候,并且当一个读模型被更新时能接受数据的最终一致性问题,或者说从一系列的事件序列中生成实体对性能的影响可以被接受。
这种模式在以下几种场景中可能并不适用:
- 小而简单的,业务逻辑简单或者根本没有业务逻辑,或者领域概念的,一般传统的增删改查(CURD)就能实现功能的业务领域,或者系统。
- 需要实时一致和实时更新数据的系统。
- 不需要审查,历史和回滚的系统。
- 并发更新数据可能性非常小的系统。例如,只增加数据不更新数据的系统。
5、ES 和 CQRS 的关系
CQRS与事件溯源有着相辅相成的关系。CQRS允许事件溯源作为领域的数据存储机制。然而,使用事件溯源的一个最大的缺点是,你无法向你的系统提出类似“请告诉我所有名字为Greg的用户”这样的问题,这是由于事件溯源无法提供对象的当前状态而引起的。CQRS唯一支持的查询就是:GetById - 通过ID来获得某个聚合。下图为基于CQRS/ES的应用系统结构:

CQRS经常和事件溯源模式结合使用
基于CQRS的系统使用分离的读和写模型,每一个都对应相应的任务并且一般储存在不同的数据库中。当和事件溯源模式一起使用的时候,一系列的事件存储相当于“写”模型,是所有信息的可信赖来源(authoritative source )。基于CQRS的系统的读模型提供了数据的物化视图,经常是一种高度格式化的视图形式。这些视图对应相应的界面并且展示了应用程序的需求,帮助最大化展示和查询效率。
使用一系列的事件当作“写”而不是某一个时间点的数据,避免了更新的冲突并且最大化性能和系统的伸缩性,这些事件可以被异步地产生被用来展示数据的物化视图。
因为事件数据库是所有信息的可信赖来源,当系统改进的时候,有可能删除物化视图并且展示所有过去的时间来产生一个新的数据,或者当读模型必须改变的时候。物化视图是一个长久的数据缓存。
当将CQRS和事件溯源模式结合起来的时候,考虑以下几点:
- 对于任何的读写分离储存的系统,这些系统基于事件溯源模式都是“最终一致”的。因此在事件产生和数据存储之间会有一些延迟。
- 这种模式会造成一些额外的复杂度,因为代码必须要能够初始化和处理事件,然后组合或者更新相应的读写模型需要视图或者对象。这种复杂度会对让系统的实现变得有些困难,需要重新学习一些概念和一个不同的设计系统的方式。然而事件溯源可以让为领域建模,让重建视图或者对象更加容易。
- 生成物化视图
CQRS最核心的概念是Command、Event,“将数据(Data)看做是事实(Fact)。每个事实都是过去的痕迹,虽然这种过去可以遗忘,但却无法改变。” 这一思想直接发展了Event Source,即将这些事件的发生过程记录下来,使得我们可以追溯业务流程。CQRS对设计者的影响,是将领域逻辑,尤其是业务流程,皆看做是一种领域对象状态迁移的过程。这一点与REST将HTTP应用协议看做是应用状态迁移的引擎,有着异曲同工之妙。
1、必须自己实现事务的统一commit和rollback:这个是无论哪一种方式,都必须面对的问题。完全逃不掉。在DDD中有一个叫
Saga的概念,专门用于统理这种复杂交互业务的,CQRS/ES架构下,由于本身就是最终一致性,所以都实现了Saga,可以使用该机制来做微服务下的transaction治理。
2、请求幂等:请求发送后,由于各种原因,未能收到正确响应,而被请求端已经正确执行了操作。如果这时重发请求,则会造成重复操作。
CQRS/ES架构下通过AggregateRootId、Version、CommandId三种标识来识别相同command,目前的开源框架都实现了幂等支持。
3、并发:单点上,CQRS/ES中按事件的先来后到严格执行,内存中
Aggregate的状态由单一线程原子操作进行改变。
多节点上,通过EventStore的broker机制,毫秒级将事件复制到其他节点,保证同步性,同时支持版本回退。(Eventuate)
三、在项目中使用ES
大家请注意,下边的这一个流程,就和我们平时开发的顺序是一样的,比如先建立模型,然后仓储层,然后应用服务层,最后是调用的过程,东西虽然很多,但是很简单,慢慢看都能看懂。
同时也复习下我们DDD领域驱动设计是如何搭建环境的,正好在最后一篇和第一篇遥相呼应。
1、创建事件存储模型 StoredEvent : Event
namespace Christ3D.Domain.Core.Events { /// <summary> /// 抽象类Message,用来获取我们事件执行过程中的类名 /// 然后并且添加聚合根 /// </summary> public abstract class Message : IRequest { public string MessageType { get; protected set; } public Guid AggregateId { get; protected set; } protected Message() { MessageType = GetType().Name; } } }
同时在该文件夹下,新建 存储事件 模型StoredEvent.cs
public class StoredEvent : Event { /// <summary> /// 构造方式实例化 /// </summary> /// <param name="theEvent"></param> /// <param name="data"></param> /// <param name="user"></param> public StoredEvent(Event theEvent, string data, string user) { Id = Guid.NewGuid(); AggregateId = theEvent.AggregateId; MessageType = theEvent.MessageType; Data = data; User = user; } // 为了EFCore能正确CodeFirst protected StoredEvent() { } // 事件存储Id public Guid Id { get; private set; } // 存储的数据 public string Data { get; private set; } // 用户信息 public string User { get; private set; } }

2、定义事件存储上下文 EventStoreSQLContext
namespace Christ3D.Infra.Data.Mappings { /// <summary> /// 事件存储模型Map /// </summary> public class StoredEventMap : IEntityTypeConfiguration<StoredEvent> { public void Configure(EntityTypeBuilder<StoredEvent> builder) { builder.Property(c => c.Timestamp) .HasColumnName("CreationDate"); builder.Property(c => c.MessageType) .HasColumnName("Action") .HasColumnType("varchar(100)"); } } }
2、然后再上下文文件夹 Context 下,新建事件存储Sql上下文 EventStoreSQLContext.cs
namespace Christ3D.Infra.Data.Context { /// <summary> /// 事件存储数据库上下文,继承 DbContext /// /// </summary> public class EventStoreSQLContext : DbContext { // 事件存储模型 public DbSet<StoredEvent> StoredEvent { get; set; } protected override void OnModelCreating(ModelBuilder modelBuilder) { modelBuilder.ApplyConfiguration(new StoredEventMap()); base.OnModelCreating(modelBuilder); } protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder) { // 获取链接字符串 var config = new ConfigurationBuilder() .SetBasePath(Directory.GetCurrentDirectory()) .AddJsonFile("appsettings.json") .Build(); // 使用默认的sql数据库连接 optionsBuilder.UseSqlServer(config.GetConnectionString("DefaultConnection")); } } }
这里要说明下,因为已经创建了两个上下文,以后迁移的时候,就要加上 上下文名称 了:


3、持久化事件仓储 EventStoreSQLRepository : IEventStoreRepository
namespace Christ3D.Infra.Data.Repository.EventSourcing { /// <summary> /// 事件存储仓储接口 /// 继承IDisposable ,可手动回收 /// </summary> public interface IEventStoreRepository : IDisposable { void Store(StoredEvent theEvent); IList<StoredEvent> All(Guid aggregateId); } }
2、然后对上边的接口进行实现
namespace Christ3D.Infra.Data.Repository.EventSourcing { /// <summary> /// 事件仓储数据库仓储实现类 /// </summary> public class EventStoreSQLRepository : IEventStoreRepository { // 注入事件存储数据库上下文 private readonly EventStoreSQLContext _context; public EventStoreSQLRepository(EventStoreSQLContext context) { _context = context; } /// <summary> /// 根据聚合id 获取全部的事件 /// 这个聚合是指领域模型的聚合根模型 /// </summary> /// <param name="aggregateId"> 聚合根id 比如:订单模型id</param> /// <returns></returns> public IList<StoredEvent> All(Guid aggregateId) { return (from e in _context.StoredEvent where e.AggregateId == aggregateId select e).ToList(); } /// <summary> /// 将命令事件持久化 /// </summary> /// <param name="theEvent"></param> public void Store(StoredEvent theEvent) { _context.StoredEvent.Add(theEvent); _context.SaveChanges(); } /// <summary> /// 手动回收 /// </summary> public void Dispose() { _context.Dispose(); } } }

这个时候,我们的事件存储模型、上下文和仓储层已经建立好了,也就是说我们可以对我们的事件模型进行持久化了,接下来就是在建立服务了,用来调用仓储的服务,就好像我们的应用服务层的概念。
4、建立事件存储服务 SqlEventStoreService: IEventStoreService
建完了基础设施层,那我们接下来就需要建立服务层了,并对其进行调用:
1、还是在核心领域层中的Events文件夹下,建立接口
namespace Christ3D.Domain.Core.Events { /// <summary> /// 领域存储服务接口 /// </summary> public interface IEventStoreService { /// <summary> /// 将命令模型进行保存 /// </summary> /// <typeparam name="T"> 泛型:Event命令模型</typeparam> /// <param name="theEvent"></param> void Save<T>(T theEvent) where T : Event; } }

2、然后再来实现该接口
在应用层 Christ3D.Application 中,新建 EventSourcing 文件夹,用来对我们的事件存储进行溯源,然后新建 事件存储服务类 SqlEventStoreService.cs
namespace Christ3D.Infra.Data.EventSourcing { /// <summary> /// 事件存储服务类 /// </summary> public class SqlEventStoreService : IEventStoreService { // 注入我们的仓储接口 private readonly IEventStoreRepository _eventStoreRepository; public SqlEventStoreService(IEventStoreRepository eventStoreRepository) { _eventStoreRepository = eventStoreRepository; } /// <summary> /// 保存事件模型统一方法 /// </summary> /// <typeparam name="T"></typeparam> /// <param name="theEvent"></param> public void Save<T>(T theEvent) where T : Event { // 对事件模型序列化 var serializedData = JsonConvert.SerializeObject(theEvent); var storedEvent = new StoredEvent( theEvent, serializedData, "Laozhang"); _eventStoreRepository.Store(storedEvent); } } }

这个时候你会问了,那我们现在都写好了,在哪里使用呢,欸?!聪明,既然是事件存储,那就是在事件保存的时候,进行存储,请往下看。
5、在总线中发布事件的同时,对事件保存 Task RaiseEvent<T>
/// <summary> /// 引发事件的实现方法 /// </summary> /// <typeparam name="T">泛型 继承 Event:INotification</typeparam> /// <param name="event">事件模型,比如StudentRegisteredEvent</param> /// <returns></returns> public Task RaiseEvent<T>(T @event) where T : Event { // 除了领域通知以外的事件都保存下来 if (!@event.MessageType.Equals("DomainNotification")) _eventStoreService?.Save(@event); // MediatR中介者模式中的第二种方法,发布/订阅模式 return _mediator.Publish(@event); }
四、未完待续...
DDD领域驱动设计就到这里到一段落了,江湖很远,话不多说,咱们下一系列再见!
五、粉丝活动
//1、聚合根是什么?或者说是什么数据结构?(言之成理即可) //2、我的项目中,有几条总线,分别是? //3、我的项目中,在使用领域通知处理器之前,我是用什么不当的临时方法来处理验证错误信息的?(提示:在自定义视图组件中)
1、初久, 真实姓名:韩**,手机号:183******12;青岛。
六、Github & Gitee
https://github.com/anjoy8/ChristDDD
https://gitee.com/laozhangIsPhi/ChristDDD

 浙公网安备 33010602011771号
浙公网安备 33010602011771号