
Impala基于内存的SQL引擎的详细介绍
一、简介
1、概述
Impala是Cloudera公司推出,提供对HDFS、Hbase数据的高性能、低延迟的交互式SQL查询功能。
•基于Hive使用内存计算,兼顾数据仓库、具有实时、批处理、多并发等优点
impala使用hive的元数据, 完全在内存中计算
•是CDH平台首选的PB级大数据实时查询分析引擎
2、Impala的特点
impalak快的原因:1、2、3、6
1、基于内存进行计算,能够对PB级数据进行交互式实时查询、分析
2、无需转换为MR,直接读取HDFS及Hbase数据 ,从而大大降低了延迟。
Impala没有MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分组成
3、C++编写,LLVM统一编译运行
在底层对硬件进行优化, LLVM:编译器,比较稳定,效率高
4、兼容HiveSQL
支持hive基本的一些查询等,hive中的一些复杂结构是不支持的
5、具有数据仓库的特性,可对hive数据直接做数据分析
6、支持Data Local
数据本地化:无需数据移动,减少数据的传输
7、支持列式存储
可以和Hbase整合:因为Hive可以和Hbasez整合
8、支持JDBC/ODBC远程访问
3、Impala劣势
1、对内存依赖大
只在内存中计算,官方建议128G(一般64G基本满足),可优化: 各个节点汇总的节点(服务器)内存选用大的,不汇总节点可小点
2、C++编写 开源 ?
对于java, C++可能不是很了解
3、完全依赖hive
4、实践过程中分区超过1w 性能严重下下降
定期删除没有必要的分区,保证分区的个数不要太大
5、稳定性不如hive
因完全在内存中计算,内存不够,会出现问题, hive内存不够,可使用外存
4、Impala的缺点
- Impala不提供任何对序列化和反序列化的支持。
- Impala只能读取文本文件,而不能读取自定义二进制文件。
- 每当新的记录/文件被添加到HDFS中的数据目录时,该表需要被刷新。
二、Impala架构
1、Impala的核心组件
Statestore Daemon
- 负责收集分布在集群中各个impalad进程的资源信息、各节点健康状况,同步节点信息
- 负责query的调度
Catalog Daemon
-
从Hive元数据库中同步元数据,分发表的元数据信息到各个impalad中
-
接收来自statestore的所有请求
impala版本1.2之后开始有的,不是很只能,有些元数据信息并不能同步到各个impalad的,例如hive中创建表,Catalog Daemon不能同步,需要在imapala手动执行命令同步。
Impala Daemon(impalad) <具有数据本地化的特性所以放在DataNode上>
-
接收client、hue、jdbc或者odbc请求、Query执行并返回给中心协调节点
-
子节点上的守护进程,负责向statestore保持通信,汇报工作
Impala daemon:执行计算。因内存依赖大,所最好不要和imapla的其他组件放到同意节点
考虑集群性能问题,一般将StateStoreDaemon与 Catalog Daemon放在统一节点上,因之间要做通信
2、整体架构流程
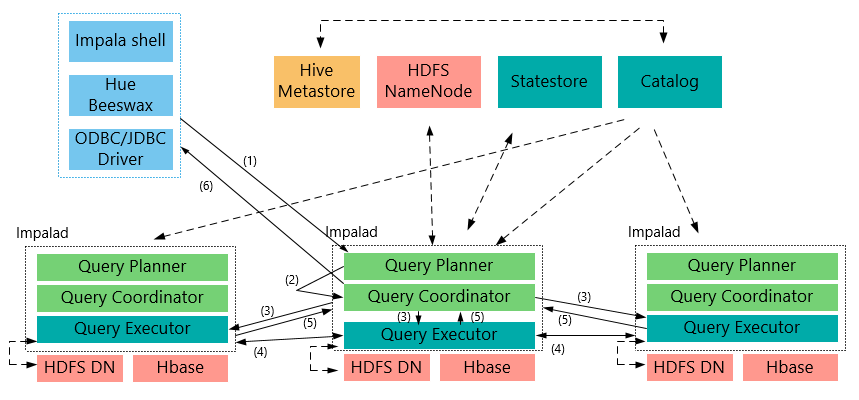
-
客户端向某一个Impalad发送一个query(SQL)
上Impalad会与StateStore保持连接(通信),确定impala集群哪写Impalad是否健康可工作,与NameNode得到数据元数据信息(数据的位置等);每个Impalad通过Catalog可知表元数据据信息;
-
Impalad将query解析为具体的执行计划Planner, 交给当前机器Coordinator即为中心协调节点
Impalad通过jni,将query传送给java前端,由java前端完成语法分析和生成执行计划(Planner),并将执行计划封装成thrift格式返回执行计划分为多个阶段,每一个阶段叫做一个(计划片段)PlanFragment,每一个PlanFragment在执行时可以由多个Impalad实例并行执行(有些PlanFragment只能由一个Impalad实例执行),
-
Coordinator(中心协调节点)根据执行计划Planner,通过本机Executor执行,并转发给其它有数据的impalad用Executor进行执行
-
impalad的Executor之间可进行通信,可能需要一些数据的处理
-
各个impalad的Executor执行完成后,将结果返回给中心协调节点
用户调用GetNext()方法获取计算结果,如果是insert语句,则将计算结果写回hdfs
当所有输入数据被消耗光,执行结束(完成)。
在执行过程中,如果有任何故障发生,则整个执行失败
-
有中心节点Coordinator将汇聚的查询结果返回给客户端
3、Impala与Hive的异同

数据存储
- 使用相同的存储数据池都支持把数据存储于HDFS, HBase。
元数据:
- 两者使用相同的元数据
SQL解释处理:
- 比较相似都是通过词法分析生成执行计划。
执行计划:
- Hive: 依赖于MapReduce执行框架,执行计划分成 map->shuffle->reduce->map->shuffle->reduce…的模型。如果一个Query会 被编译成多轮MapReduce,则会有更多的写中间结果。由于MapReduce执行框架本身的特点,过多的中间过程会增加整个Query的执行时间。
- Impala: 把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,而不用像Hive那样把它组合成管道型的 map->reduce模式,以此保证Impala有更好的并发性和避免不必要的中间sort与shuffle。
数据流:
- Hive: 采用推的方式,每一个计算节点计算完成后将数据主动推给后续节点。
- Impala: 采用拉的方式,后续节点通过getNext主动向前面节点要数据,以此方式数据可以流式的返回给客户端,且只要有1条数据被处理完,就可以立即展现出来,而不用等到全部处理完成,更符合SQL交互式查询使用。
内存使用:
- Hive: 在执行过程中如果内存放不下所有数据,则会使用外存,以保证Query能顺序执行完。每一轮MapReduce结束,中间结果也会写入HDFS中,同样由于MapReduce执行架构的特性,shuffle过程也会有写本地磁盘的操作。
- Impala: 在遇到内存放不下数据时,当前版本1.0.1是直接返回错误,而不会利用外存,以后版本应该会进行改进。这使用得Impala目前处理Query会受到一 定的限制,最好还是与Hive配合使用。Impala在多个阶段之间利用网络传输数据,在执行过程不会有写磁盘的操作(insert除外)
调度
- Hive任务的调度依赖于Hadoop的调度策略。
- Impala的调度由自己完成,目前的调度算法会尽量满足数据的局部性,即扫描数据的进程应尽量靠近数据本身所在的物理机器。但目前调度暂时还没有考虑负载均衡的问题。从Cloudera的资料看,Impala程序的瓶颈是网络IO,目前Impala中已经存在对Impalad机器网络吞吐进行统计,但目前还没有利用统计结果进行调度。
容错
- Hive任务依赖于Hadoop框架的容错能力,可以做到很好的failover
- Impala中不存在任何容错逻辑,如果执行过程中发生故障,则直接返回错误。当一个Impalad失败时,在这个Impalad上正在运行的所有query都将失败。但由于Impalad是对等的,用户可以向其他Impalad提交query,不影响服务。当StateStore失败时,也不会影响服务,但由于Impalad已经不能再更新集群状态,如果此时有其他Impalad失败,则无法及时发现。这样调度时,如果谓一个已经失效的Impalad调度了一个任务,则整个query无法执行。
三、Impala Shell
1、Impala 外部shell
不进入Impala内部,直接执行的ImpalaShell
例如:
$ impala-shell -h -- 通过外部Shell查看Impala帮助
$ impala-shell -p select count(*) from t_stu -- 显示一个SQL语句的执行计划
下面是Impala的外部Shell的一些参数:
-h (--help) 帮助
-v (--version) 查询版本信息
-V (--verbose) 启用详细输出
--quiet 关闭详细输出
-p 显示执行计划
-i hostname (--impalad=hostname) 指定连接主机格式hostname:port 默认端口21000, impalad shell 默认连接本机impalad
- r(--refresh_after_connect)刷新所有元数据
-q query (--query=query) 从命令行执行查询,不进入impala-shell
-d default_db (--database=default_db) 指定数据库
-B(--delimited)去格式化输出
--output_delimiter=character 指定分隔符
--print_header 打印列名
-f query_file(--query_file=query_file)执行查询文件,以分号分隔
-o filename (--output_file filename) 结果输出到指定文件
-c 查询执行失败时继续执行
-k (--kerberos) 使用kerberos安全加密方式运行impala-shell
-l 启用LDAP认证
-u 启用LDAP时,指定用户名
2、Impala内部Shell
# impala shell进入
# 普通连接
impala-shell
# impala shell命令
# 查看impala版本
select version;
# 特殊数据库
# default,建立的没有指定任何数据库的新表
# _impala_builtins,用于保存所有内置函数的系统数据库
# 库操作
# 创建
create database tpc;
# 展示
show databases;
# 展示库名中含有指定(格式)字符串的库展示
# 进入
use tpc;
# 当前所在库
select current_database();
#表操作
# 展示(默认default库的表)
show tables;
# 指定库的表展示
show tables in tpc;
# 展示指定库中表名中含有指定字符串的表展示
show tables in tpc like 'customer*';
# 表结构
describe city; 或 desc city;
# select insert create alter
# 表导到另一个库中(tcp:city->d1:city)
alter table city rename to d1.city
# 列是否包含null值
select count(*) from city where c_email_address is null
# hive中 create、drop、alter,切换到impala-shell中需要如下操作
invalidate metadata
# hive中 load、insert、change表中数据(直接hdfs命令操作),切换到impala-shell中需要如下操作
refresh table_name
3、参考文章
https://www.w3cschool.cn/impala/impala_overview.html
https://blog.csdn.net/flyingsk/article/details/8590000
https://blog.csdn.net/qiyongkang520/article/details/51067803
转载自链接:https://www.jianshu.com/p/257ff24db397

 浙公网安备 33010602011771号
浙公网安备 33010602011771号