

第二次结对作业
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018SE1/homework/11250 |
|---|---|
| 作业目标 | <根据要求编写代码,建仓,用博客记录作业过程> |
| 作业源代码 | https://gitee.com/li-wenlin/pair |
| 队员1 | <211806323> |
| 队员2 | <211806421> |
编码记录
| 代码行数 | 174行 |
|---|---|
| 需求分析 | 30min |
| 代码编写时间 | 7h |
| 代码复核 | 2h |
| markdown | 2h |
李文淋,来自计算机软件工程2018级1班学生,学号211806323,平时喜欢运动,玩王者荣耀,睡觉!!!睡觉最香!!!
詹泽浩,来自计算机软件工程2018级2班的学生,学号211806421,平时喜欢健身,打LOL,听歌
给你们看看我们努力的样子!!!

我们对爬虫一无所知,所以我们觉得这次作业太难,如何网络爬取我们需要的数据, 如何得到课堂完成部分的所有url再进行解析,如何得到每个同学的信息, 如何处理得到的数据,都是非常值得研究的问题。
让我们好好分析一下~
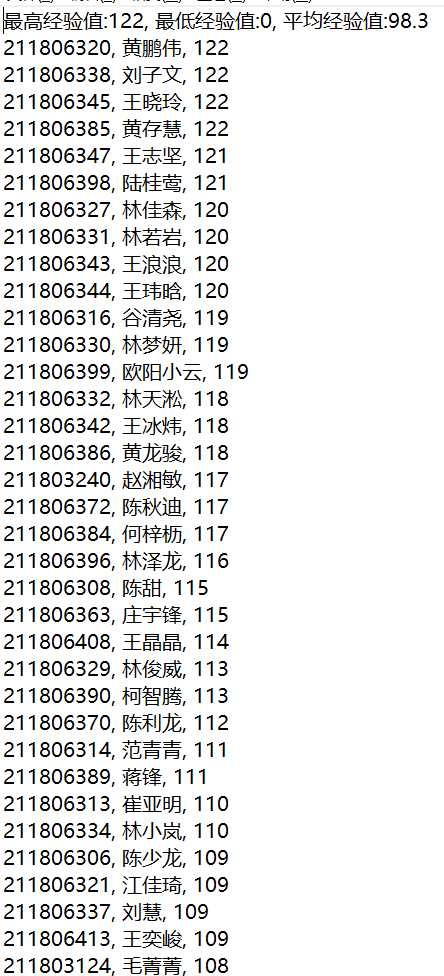
网络爬取云班课的数据,将云班课上全班的课堂完成部分的经验值爬取下来, 根据经验值排序,看看自己和自己的同学在全班第几名,同时计算出平均经验、最低经验、最高经验。
那么面临的 一个问题就是如何进入云班课,万事开头难,这时候我们发现需要用cookie进行模拟登陆。
开始操作它!!!
cookie它!!!

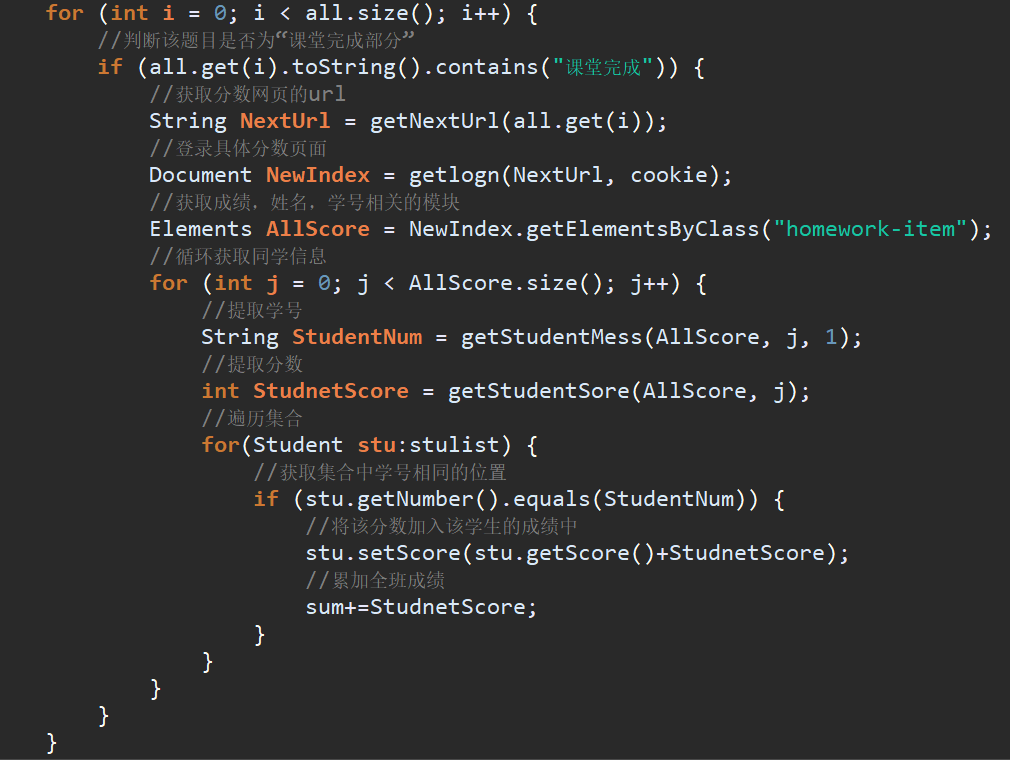
由于要排序的只有课堂完成部分,那么就要找到这一模块,我首先是把所有的作业板块都提取下来,然后判断是否含有“课堂完成”来提取课堂完成部分,当然也可以直接通过span标签获取课堂完成部分内容。
接着我通过判断是否为课堂完成部分进入活动板块的网页地址,获取成绩页面所有成绩,姓名,学号相关模块。

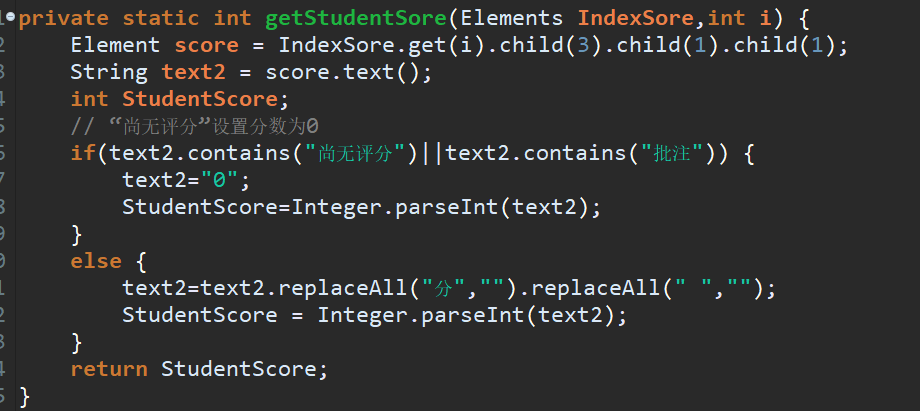
当我们遇到那些没提交作业的同学,要考虑到没评分和未提交的情况,没评分和未提交成绩都为0
终于,得到了结果!!!
巴适!巴适得很!!!
我又觉得我行了!!!
展示一下commit~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号