
数据采集第四次作业
作业一:基于 Selenium + MySQL 的沪深 A 股股票数据爬取
一、作业功能与整体设计思路
1.1 作业功能说明与页面分析(含部分代码与截图)
这次作业的目标是:使用 Selenium 框架 + MySQL 数据库存储,从东方财富网爬取以下 3 个板块的股票数据,并写入本地数据库中:
- 沪深 A 股
- 上证 A 股
- 深证 A 股
对应的网址例如(沪深 A 股):
在代码中,我先用一个字典把三个板块和它们对应的 URL 管理起来,方便后续循环处理:
BOARD_URLS = {
"沪深A股": "https://quote.eastmoney.com/center/gridlist.html#hs_a_board",
"上证A股": "https://quote.eastmoney.com/center/gridlist.html#sh_a_board",
"深证A股": "https://quote.eastmoney.com/center/gridlist.html#sz_a_board",
}
为了从网页中拿到数据,我的整体思路是:
- 使用 Selenium 启动 Chrome 浏览器,访问每个板块的 URL;
- 等待页面加载完成后,找到股票数据所在的表格
<table>元素; - 遍历表格中每一行
<tr>,从每一列<td>中提取股票代码、名称、最新价、涨跌幅等字段; - 对于数字类的数据(价格、涨幅、成交量等),做一个统一的清洗和类型转换;
- 把结构化后的数据写入 MySQL 数据库中的
t_stock_info表。
在正式爬取之前,页面大致长这样:
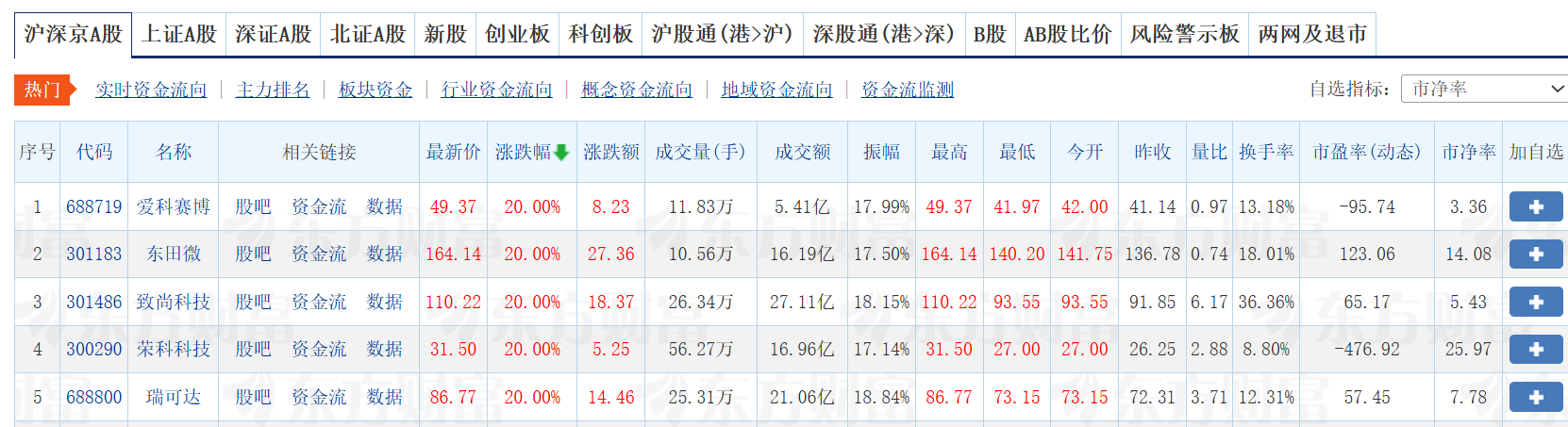
1.2 核心代码
下面是这次作业的完整核心代码,我在关键位置加了一些注释,方便理解整体流程。
import time
from datetime import datetime
import pymysql
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
from webdriver_manager.chrome import ChromeDriverManager
BOARD_URLS = {
"沪深A股": "https://quote.eastmoney.com/center/gridlist.html#hs_a_board",
"上证A股": "https://quote.eastmoney.com/center/gridlist.html#sh_a_board",
"深证A股": "https://quote.eastmoney.com/center/gridlist.html#sz_a_board",
}
def to_float(v):
if v is None:
return None
s = str(v).replace(",", "").replace("%", "").strip()
if s in ("", "-", "--", ""):
return None
try:
return float(s)
except Exception:
return None
def to_int(v):
if v is None:
return None
s = str(v).replace(",", "").strip()
if s in ("", "-", "--", ""):
return None
try:
return int(float(s))
except Exception:
return None
def get_driver(): # 初始化一个 Chrome 浏览器的 Selenium driver
opts = Options()
opts.add_argument("--disable-gpu")
opts.add_argument("--no-sandbox")
opts.add_argument("--window-size=1920,1080")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=opts)
driver.implicitly_wait(10)
return driver
def get_db_conn(): # 接入本地的数据库
return pymysql.connect(
host="127.0.0.1",
port=3306,
user="root",
password="root",
database="stock_db",
charset="utf8mb4",
)
def insert_rows(conn, rows):
if not rows:
return
sql = """
INSERT INTO t_stock_info (
bStockNo,
bStockName,
bLatestPrice,
bChangePercent,
bChangeAmount,
bVolume,
bAmplitude,
bHigh,
bLow,
bOpenToday,
bCloseYesterday,
update_time
) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
data = [
(
r["bStockNo"],
r["bStockName"],
to_float(r["bLatestPrice"]),
to_float(r["bChangePercent"]),
to_float(r["bChangeAmount"]),
to_int(r["bVolume"]),
to_float(r["bAmplitude"]),
to_float(r["bHigh"]),
to_float(r["bLow"]),
to_float(r["bOpenToday"]),
to_float(r["bCloseYesterday"]),
datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
)
for r in rows
]
with conn.cursor() as cur:
cur.executemany(sql, data)
conn.commit()
print(f"写入 MySQL {len(rows)} 条")
def parse_page(driver):
rows_data = [] # 通过 XPATH 找到页面中表格 <table> 的 <tbody> 里所有 <tr>(每一行对应一只股票)。
try:
trs = driver.find_elements(By.XPATH, '//table[contains(@class,"table")]/tbody/tr')
except NoSuchElementException:
return rows_data
for tr in trs:
tds = tr.find_elements(By.TAG_NAME, "td") # 将 tr 里的每个 td 取出来
if len(tds) < 13:
continue
# 从每个 td 里提取数据
code = tds[1].text.strip()
name = tds[2].text.strip() # 股票名称
latest = tds[3].text.strip()
change_amt = tds[4].text.strip()
change_pct = tds[5].text.strip()
vol = tds[6].text.strip()
amp = tds[8].text.strip()
high = tds[9].text.strip()
low = tds[10].text.strip()
open_ = tds[11].text.strip()
prev_close = tds[12].text.strip()
row = {
"bStockNo": code,
"bStockName": name,
"bLatestPrice": latest,
"bChangePercent": change_pct,
"bChangeAmount": change_amt,
"bVolume": vol,
"bAmplitude": amp,
"bHigh": high,
"bLow": low,
"bOpenToday": open_,
"bCloseYesterday": prev_close,
}
print(code, name, latest, change_pct, vol)
rows_data.append(row)
return rows_data
def crawl_board(driver, conn, name, url):
print(f"=== 板块:{name}(仅第一页)===")
driver.get(url)
time.sleep(3)
rows = parse_page(driver)
insert_rows(conn, rows)
def main():
driver = get_driver()
conn = get_db_conn()
try:
for name, url in BOARD_URLS.items():
crawl_board(driver, conn, name, url)
finally:
conn.close()
driver.quit()
if __name__ == "__main__":
main()
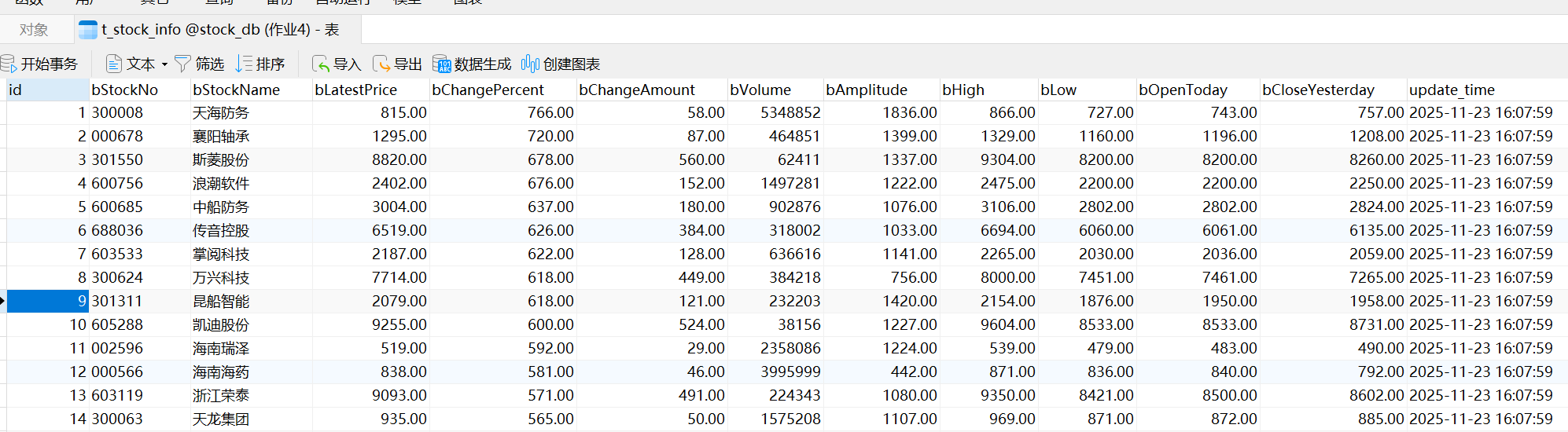
二、作业心得与总结
这次作业整体让我把 Selenium 和 MySQL 串了起来,比较完整地体验了一遍“从网页到数据库”的流程。一开始对 Ajax 页面不太熟,只看源代码找不到表格数据,后来通过 Selenium 等待页面加载,再结合 XPATH 去定位表格行,才顺利把数据抓下来。实现过程中,我也意识到数字字段清洗、类型转换这些“小细节”其实很重要,不然插库很容易出错。
作业二:基于 Selenium + MySQL 的中国大学MOOC课程信息爬取
一、作业功能与整体设计思路
1.1 作业功能说明与页面分析(含部分代码与截图)
这次作业的要求是:使用 Selenium + MySQL,从 中国大学MOOC(icourse163) 上爬取课程信息,并保存到本地数据库中。相比作业一,这次多了一个重点:模拟用户访问课程详情页、处理 Ajax 加载的数据,以及更加细化的课程字段。
作业中需要获取的课程信息包括:
- 课程号(我这里用的是顺序号)
- 课程名称
- 学校名称
- 主讲教师
- 团队成员
- 参加人数
- 课程进度
- 课程简介
我这次是选取了 8 门课程的详情页来做实验,把它们的 URL 事先整理成一个列表,后面直接用 Selenium 逐个访问:
COURSE_URLS = [
"https://www.icourse163.org/course/NHDX-1463126169",
"https://www.icourse163.org/course/XAUAT-1205987803",
"https://www.icourse163.org/course/ZJU-1206446832",
"https://www.icourse163.org/course/XJTU-1001595002",
"https://www.icourse163.org/course/HUBU-1001939003",
"https://www.icourse163.org/course/NUDT-9004",
"https://www.icourse163.org/course/JNU-1002527019",
"https://www.icourse163.org/course/BNU-1001998011",
]
整体思路可以概括为:
- 用 Selenium 启动浏览器,依次打开
COURSE_URLS里的每一个课程链接; - 在课程详情页上定位课程名、学校、教师团队、人数、进度、简介等元素;
- 把解析出的信息封装成字典;
- 通过
pymysql把数据写入本地 MySQL 数据库mooc_db的t_mooc_course表。
课程详情页大致会包含课程封面、课程标题、学校 Logo、教师团队列表、报名人数以及课程简介等内容:
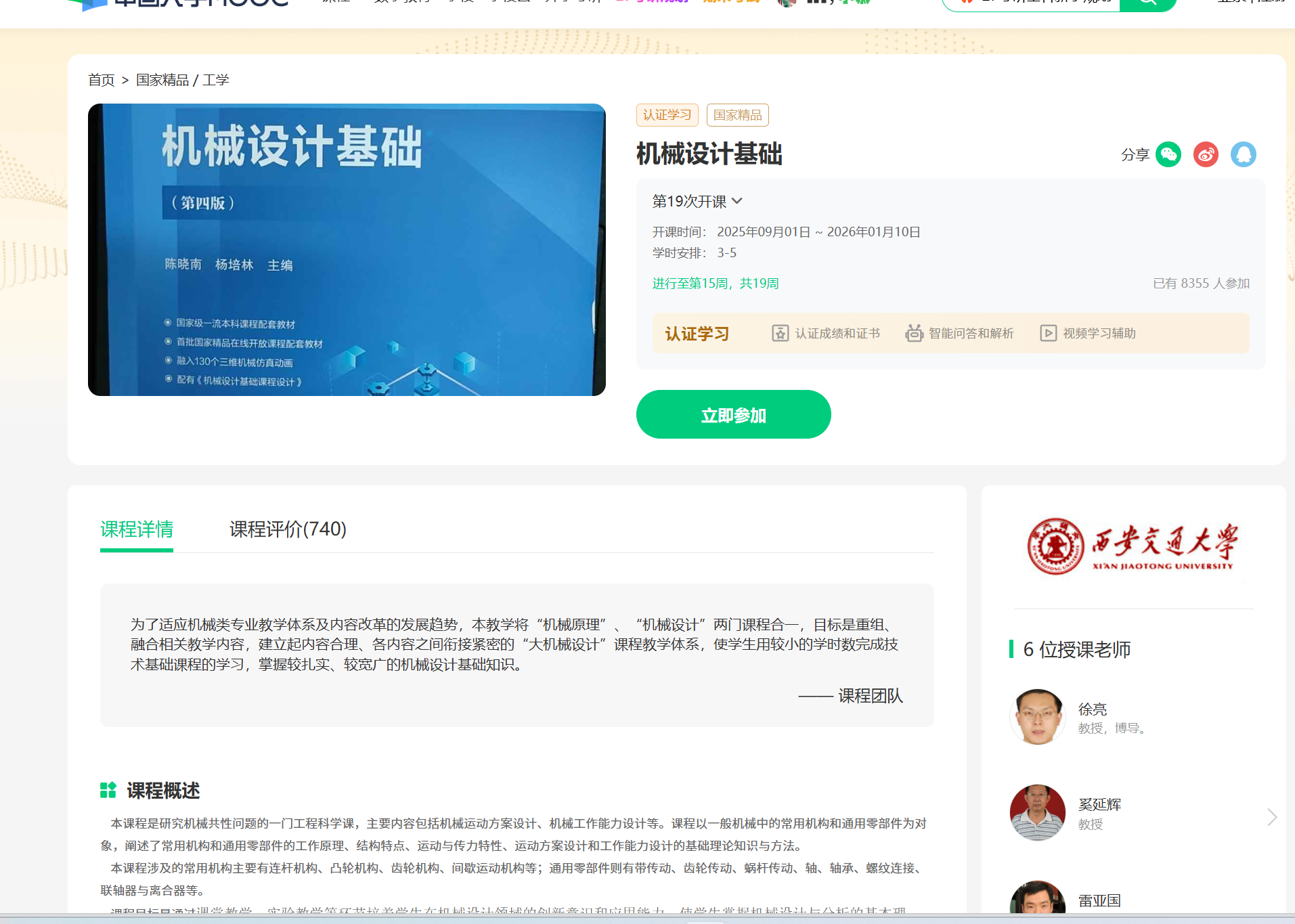
1.2 Selenium 启动与数据库连接(环境准备)
首先是浏览器和数据库的初始化。浏览器部分我用的是 Chrome,通过 webdriver_manager 自动安装和管理 ChromeDriver,并设置了一些简单的启动参数:
def get_driver():
opts = Options()
# 如需无头模式:取消下一行注释
# opts.add_argument("--headless=new")
opts.add_argument("--disable-gpu")
opts.add_argument("--no-sandbox")
opts.add_argument("--window-size=1920,1080")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=opts)
driver.implicitly_wait(10)
return driver
数据库连接部分还是和作业一类似,只是库名换成了 mooc_db:
def get_db_conn():
return pymysql.connect(
host="127.0.0.1",
port=3306,
user="root",
password="root",
database="mooc_db",
charset="utf8mb4",
)
对应的 MySQL 表(t_mooc_course)字段大致如下(字段名是我自己按英文定义的):
id(自增主键,可选)course_id(课程号,这里用顺序号)course_name(课程名称)school_name(学校名称)teacher(主讲教师)team(团队成员,多个老师用顿号拼接)learner_count(参加人数)progress(课程进度,比如正在进行/已结束)intro(课程简介)create_time(入库时间)
插入数据的函数 insert_course() 如下:
def insert_course(conn, c):
"""把课程信息插入 t_mooc_course,包含 course_id(顺序号)"""
sql = """
INSERT INTO t_mooc_course (
course_id, course_name, school_name, teacher,
team, learner_count, progress, intro, create_time
) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
with conn.cursor() as cur:
cur.execute(
sql,
(
c.get("course_id"),
c.get("course_name"),
c.get("school_name"),
c.get("teacher"),
c.get("team"),
c.get("learner_count"),
c.get("progress"),
c.get("intro"),
datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
),
)
conn.commit()
1.3 查找 HTML 元素与处理 Ajax 内容
核心逻辑都在 parse_course_detail() 函数里,这个函数负责:
- 打开课程详情页;
- 等待页面加载;
- 通过 CSS 选择器查找需要的元素;
- 把信息整理成字典返回。
def parse_course_detail(driver, url):
"""在课程详情页解析:课程名、学校、主讲、团队、人数、进度、简介"""
driver.get(url)
time.sleep(5)
1)课程名称
# 课程名
course_name = ""
try:
title_el = driver.find_element(
By.CSS_SELECTOR,
".course-title",
)
course_name = title_el.text.strip()
except NoSuchElementException:
pass
2)学校名称
学校名称是从老师区域的图片 img 的 alt 属性里拿到的:
# 学校名:#j-teacher > div > a > img 的 alt
school_name = ""
try:
school_img = driver.find_element(
By.CSS_SELECTOR,
"#j-teacher > div > a > img"
)
school_name = (school_img.get_attribute("alt") or "").strip()
except NoSuchElementException:
pass
3)教师团队、主讲教师
教师团队位于 .m-teachers_teacher-list 下面,我把所有老师名先收集起来:
# 教师团队列表:.m-teachers_teacher-list 下面的 h3.f-fc3
team_names = []
try:
teacher_items = driver.find_elements(
By.CSS_SELECTOR,
".m-teachers_teacher-list .um-list-slider_con_item h3.f-fc3"
)
team_names = [t.text.strip() for t in teacher_items if t.text.strip()]
except Exception:
pass
# 主讲教师:团队列表中第一个
teacher = team_names[0] if team_names else ""
# 团队:所有教师名用顿号连接
team = "、".join(team_names)
4)参加人数与课程进度
参加人数通常在课程信息区域的 span.count 中,课程进度则在一个比较深的层级里,我用的是较长的 CSS 路径:
# 参加人数:span.count
learner_count = ""
try:
count_el = driver.find_element(By.CSS_SELECTOR, "span.count")
learner_count = count_el.text.strip().replace("\n", "")
except NoSuchElementException:
pass
# 课程进度:
progress = ""
try:
progress_el = driver.find_element(
By.CSS_SELECTOR,
"#course-enroll-info > div > div.course-enroll-info_course-info "
"> div.course-enroll-info_course-info_term-info > div > span:nth-child(2)"
)
progress = progress_el.text.strip().replace("\n", "")
except NoSuchElementException:
pass
5)课程简介
课程简介是一个文本区域,我把其中所有 <p> 标签里的文字拼接起来:
# 课程简介:div.f-richEditorText 里的所有 <p>
intro = ""
try:
rich_div = driver.find_element(By.CSS_SELECTOR, "div.f-richEditorText")
ps = rich_div.find_elements(By.TAG_NAME, "p")
texts = [p.text.strip() for p in ps if p.text.strip()]
intro = "\n".join(texts)
except NoSuchElementException:
pass
最后简单打印一下结果,同时返回一个字典,方便后面入库:
print("课程名:", course_name)
print("学校:", school_name)
print("主讲:", teacher)
print("团队:", team)
print("人数/进度:", learner_count, "/", progress)
return {
"course_name": course_name, # cCourse
"school_name": school_name, # cCollege
"teacher": teacher, # cTeacher
"team": team, # cTeam
"learner_count": learner_count, # cCount
"progress": progress, # cProcess
"intro": intro, # cBrief
}
1.4 主程序:循环课程列表并写入 MySQL
主函数 main() 把前面的几个部分串联在一起。
def main():
driver = get_driver()
conn = get_db_conn()
try:
for idx, url in enumerate(COURSE_URLS, start=1):
print("\n抓取详情:", url)
detail = parse_course_detail(driver, url)
course = {
"course_id": str(idx), # 用顺序号填充 course_id
**detail,
}
insert_course(conn, course)
print("入库完成:", course["course_id"], course["course_name"])
finally:
conn.close()
driver.quit()
if __name__ == "__main__":
main()

二、作业心得与总结
这次中国大学MOOC的爬取作业,让我对 Selenium 爬取「复杂页面」有了更直观的感觉。相比作业一简单的表格列表,这次需要进入每门课的详情页,通过不同的 CSS 选择器去找课程名、学校、教师团队、人数、进度和简介。
作业三:实时分析
环境搭建任务一:开头MapReduce服务
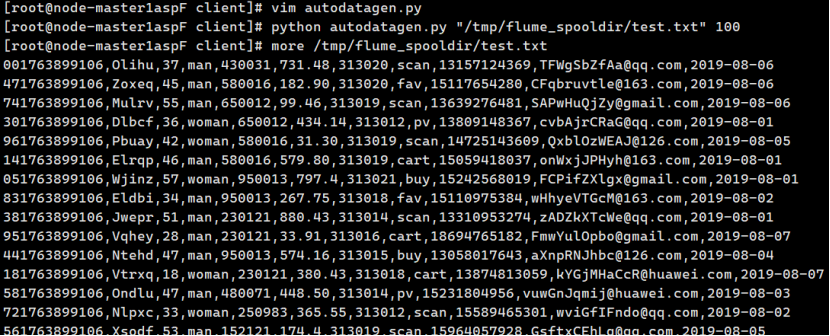
实战任务一:Python脚本生成测试数据
任务二:配置Kafka
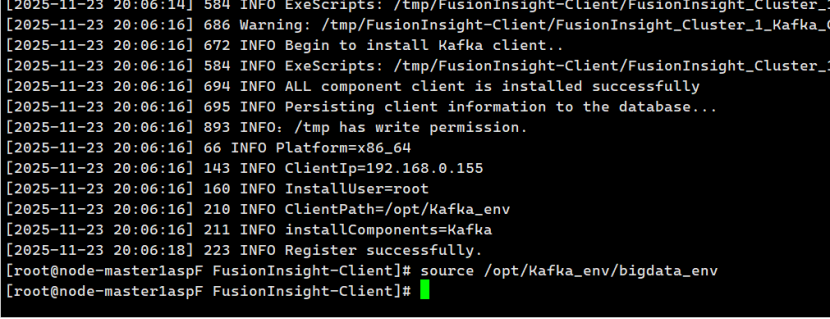
任务三: 安装Flume客户端

任务四:配置Flume采集数据
创建消费者消费kafka中的数据
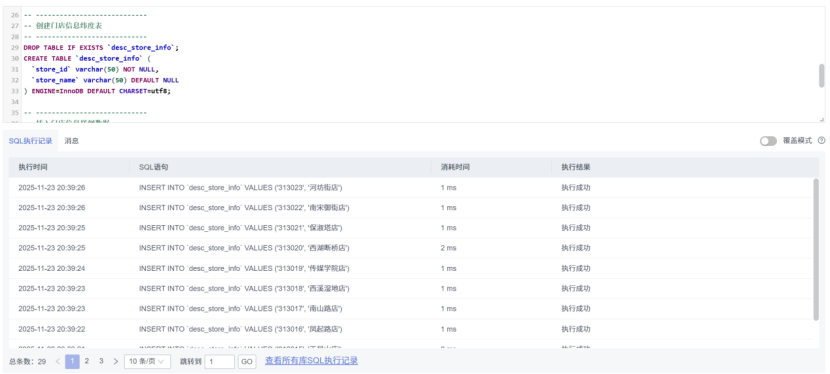
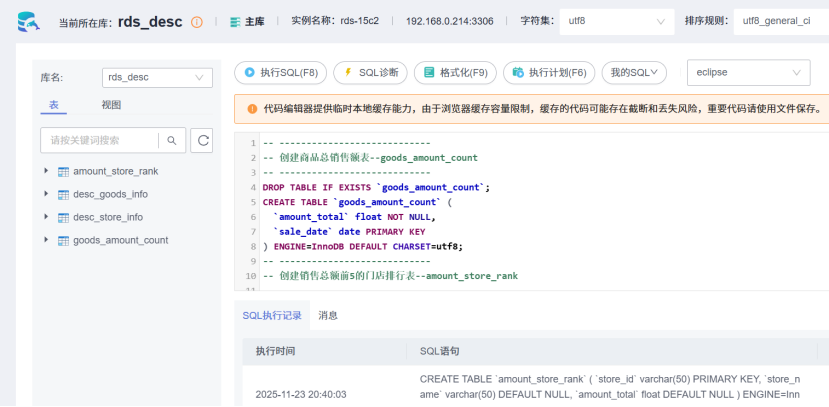
创建维度表

 浙公网安备 33010602011771号
浙公网安备 33010602011771号