
数据采集与融合第三次作业
一.爬取中国气象网图片:单线程和多线程各来一遍
作业要求:
- 任选一个网站,爬取站点里的图片;
- 必须写单线程版和多线程版两个程序;
- 要有限制,比如:最大页数用学号后两位控制、最大图片数量用学号后三位控制;
- 下载时把图片的 URL 打印到控制台,同时把图片保存到本地
images/目录;
我选的是中国气象网的图片页面:(https://p.weather.com.cn/#tianXiaQiGuang)。
一、单线程爬取实现
1.1 单线程代码和运行结果
思路:
- 用 requests请求网页 HTML;
- 正则匹配所有图片 URL(后缀是 jpg/png);
- 去重后切片,只保留前 MAX_COUNT 条;
- 遍历 URL,逐张下载到 images/ 目录;
"""
从 https://p.weather.com.cn/#tianXiaQiGuang
抓取前 118 张图片,保存到本地 images 目录
"""
import os
import re
import time
import requests
# 目标页面
BASE_URL = "https://p.weather.com.cn/#tianXiaQiGuang"
# 保存目录
SAVE_DIR = "images"
# 学号后三位,用来限制最多下载的图片数量
MAX_COUNT = 118
# 模拟浏览器
HEADERS = {
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/119.0.0.0 Safari/537.36"
)
}
def get_html(url):
"""请求页面源码"""
try:
resp = requests.get(url, headers=HEADERS, timeout=10)
resp.encoding = resp.apparent_encoding
return resp.text
except Exception as e:
print("获取页面失败:", e)
return ""
def parse_image_urls(html):
"""用正则从页面中找出图片地址"""
pattern = r'https?://[^\s"\']+\.(?:jpg|jpeg|png|gif)'
urls = re.findall(pattern, html, re.IGNORECASE)
# 简单去重
urls = list(dict.fromkeys(urls))
# 按学号后三位限制最多下载的数量
return urls[:MAX_COUNT]
def download_image(url, index):
"""保存一张图片到本地"""
try:
resp = requests.get(url, headers=HEADERS, timeout=10)
if resp.status_code != 200:
print("响应异常,跳过:", url)
return
# 用链接后缀当作文件扩展名
ext = url.split('.')[-1].split('?')[0]
filename = os.path.join(SAVE_DIR, "img_%02d.%s" % (index + 1, ext))
with open(filename, "wb") as f:
f.write(resp.content)
print("已下载:", filename)
except Exception as e:
print("下载失败:", url, e)
def main():
# 创建保存目录
if not os.path.isdir(SAVE_DIR):
os.makedirs(SAVE_DIR)
print("请求页面:", BASE_URL)
html = get_html(BASE_URL)
if not html:
return
# 解析出所有图片链接
image_urls = parse_image_urls(html)
if not image_urls:
print("没有找到图片链接,检查一下网页或正则。")
return
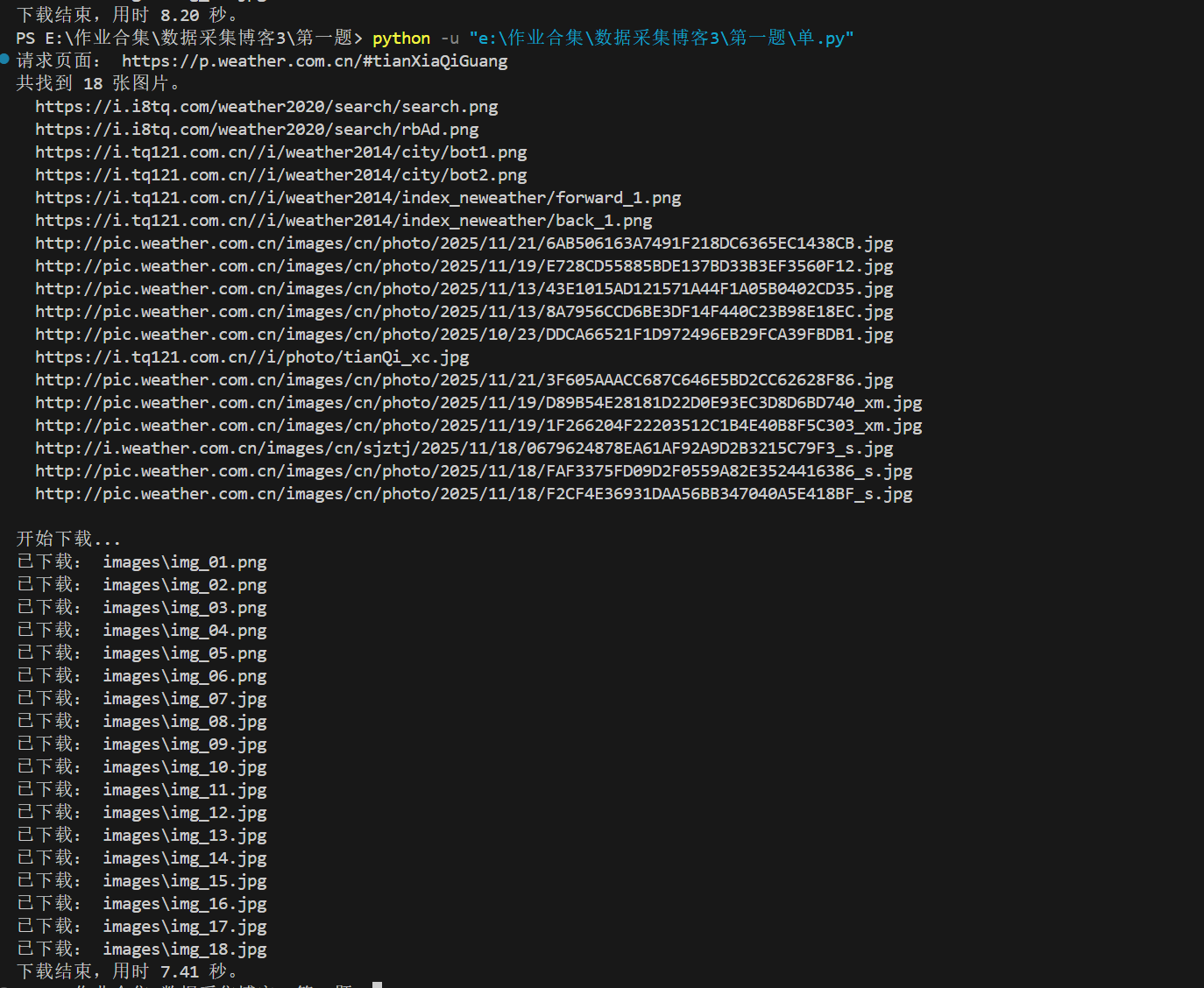
print("共找到 %d 张图片。" % len(image_urls))
for u in image_urls:
print(" ", u)
print("\n开始下载...")
start = time.time()
for i, u in enumerate(image_urls):
download_image(u, i)
cost = time.time() - start
print("下载结束,用时 %.2f 秒。" % cost)
if __name__ == "__main__":
main()
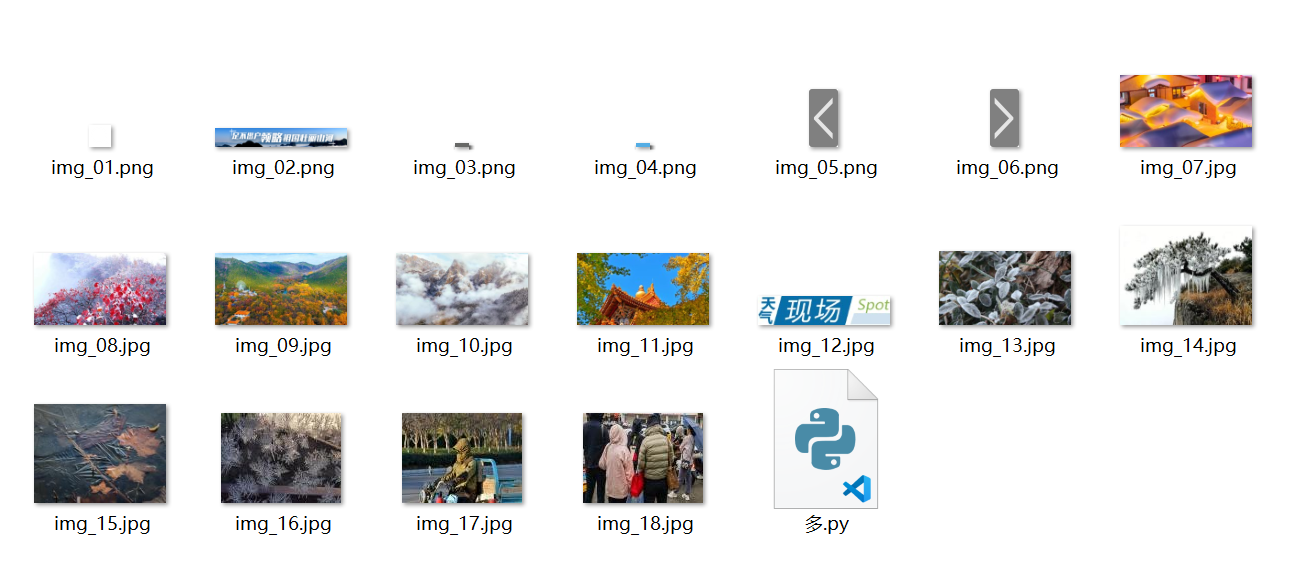
images目录里可以看到连续编号的图片文件。
- 运行脚本时的控制台截图;
![单线运行结果]()
- 打开
images目录的截图。
![image]()
1.2 单线程写完之后的想法
这一部分其实就是“基础版爬虫”:
- requests请求网页;
- 正则简单匹配图片;
- 循环下载。
二、多线程爬取实现
2.1 多线程代码和运行结果
多线程版的整体逻辑不变:还是先拿 URL,再下载。区别只在于下载阶段改成并发执行。
import os
import re
import time
import requests
from concurrent.futures import ThreadPoolExecutor, as_completed
BASE_URL = "https://p.weather.com.cn/#tianXiaQiGuang"
SAVE_DIR = "images"
MAX_COUNT = 18
HEADERS = {
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/119.0.0.0 Safari/537.36"
)
}
def get_html(url):
"""请求网页源代码"""
try:
r = requests.get(url, headers=HEADERS, timeout=10)
r.encoding = r.apparent_encoding
return r.text
except Exception as e:
print("获取页面失败:", e)
return ""
def parse_image_urls(html):
"""用正则从 html 里提取图片链接"""
pattern = r'https?://[^\s"\']+\.(?:jpg|jpeg|png|gif)'
urls = re.findall(pattern, html, re.IGNORECASE)
# 去一下重
urls = list(dict.fromkeys(urls))
return urls[:MAX_COUNT]
def download_image(url, index):
"""下载一张图片"""
try:
r = requests.get(url, headers=HEADERS, timeout=10)
if r.status_code != 200:
return "响应异常,跳过:" + url
ext = url.split(".")[-1].split("?")[0]
filename = os.path.join(SAVE_DIR, "img_%02d.%s" % (index + 1, ext))
with open(filename, "wb") as f:
f.write(r.content)
return "已下载:" + filename
except Exception as e:
return "下载失败:%s %s" % (url, e)
def main():
if not os.path.isdir(SAVE_DIR):
os.makedirs(SAVE_DIR)
print("请求页面:", BASE_URL)
html = get_html(BASE_URL)
if not html:
return
image_urls = parse_image_urls(html)
if not image_urls:
print("没有找到图片链接。")
return
print("共找到 %d 张图片:" % len(image_urls))
for u in image_urls:
print(" ", u)
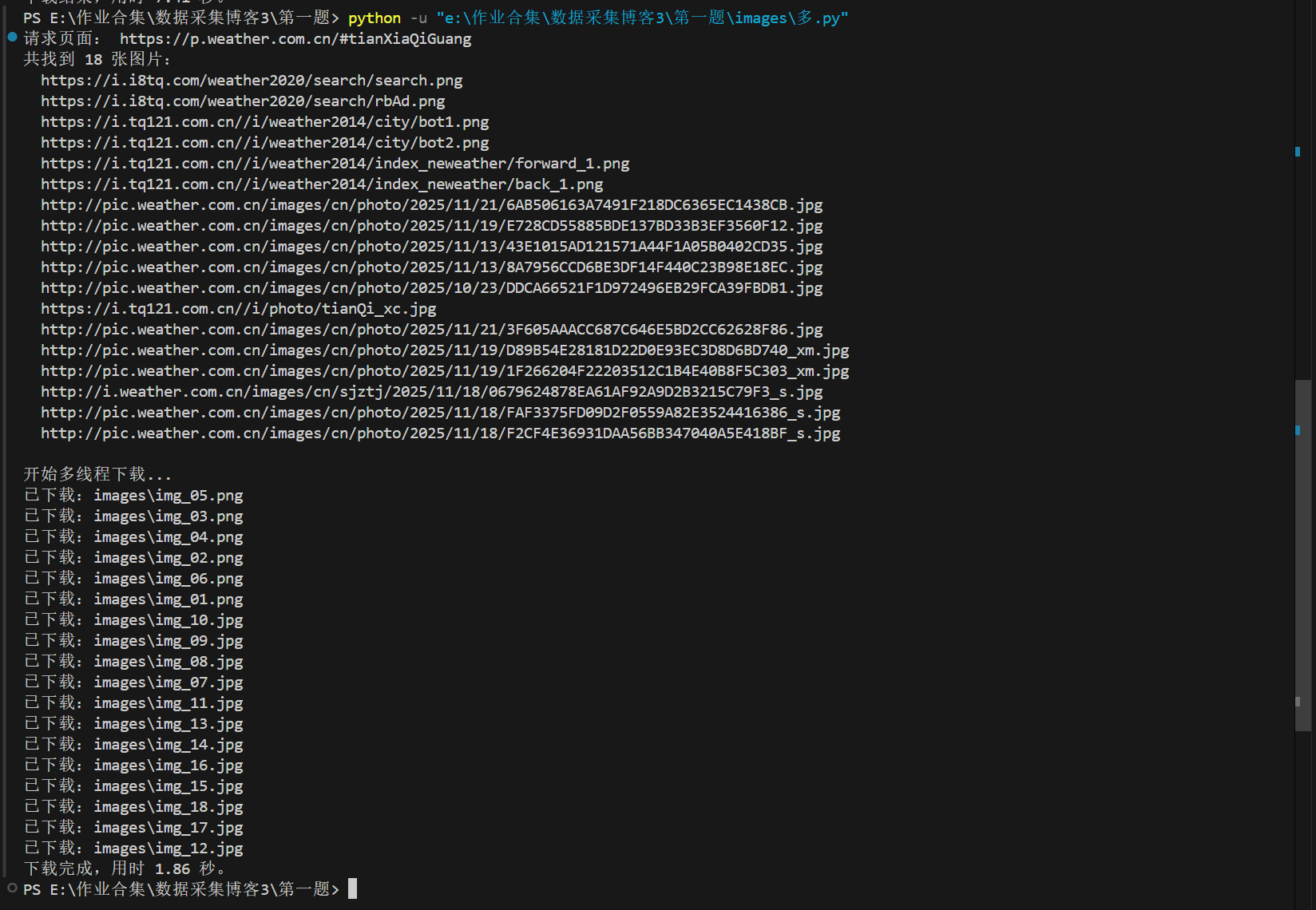
print("\n开始多线程下载...")
start = time.time()
with ThreadPoolExecutor(max_workers=6) as pool:
tasks = [pool.submit(download_image, u, i) for i, u in enumerate(image_urls)]
for t in as_completed(tasks):
# 每个线程返回一行字符串,在主线程打印
print(t.result())
cost = time.time() - start
print("下载完成,用时 %.2f 秒。" % cost)
if __name__ == "__main__":
main()
可以看到,多线程版和单线程版主要差别就在下面这段:
with ThreadPoolExecutor(max_workers=6) as pool:
tasks = [pool.submit(download_image, u, i) for i, u in enumerate(image_urls)]
for t in as_completed(tasks):
print(t.result())
- 多线程下载过程的控制台输出;
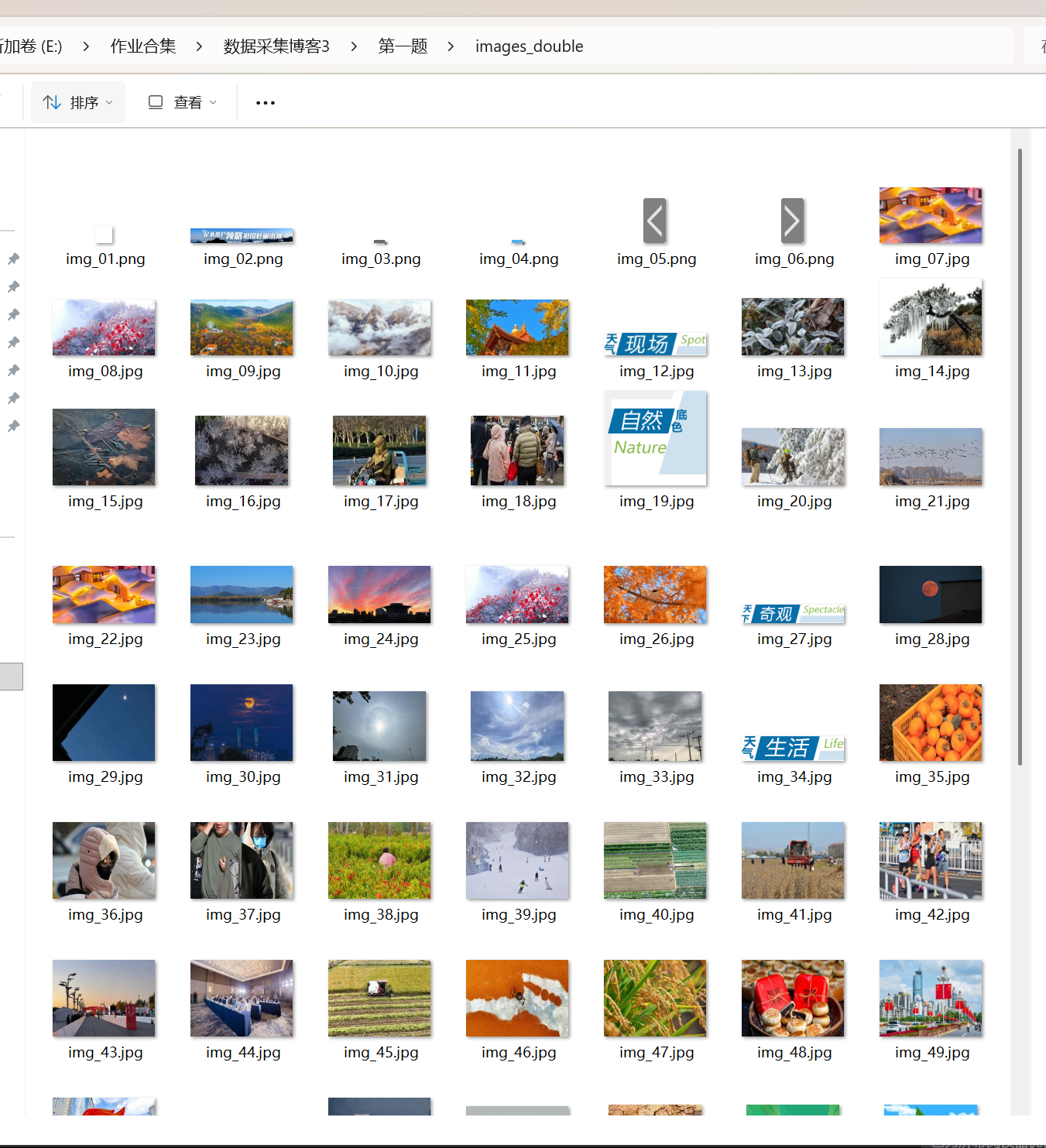
images目录下文件数量的截图
![image]()
2.2 多线程写完之后的想法
明显多线程的速度要快于单线程
作业二:Scrapy + MySQL 爬取东方财富股票信息
这次作业的要求大概是这样:
- 用 Scrapy 框架,掌握 Item、Pipeline 这一套数据流;
- 选择东方财富网,爬取股票相关信息;
- 最终结果存到 MySQL,中间字段英文名自己设计,比如
bStockNo之类;
我最后的方案是:直接抓东方财富股票列表用的接口,用 Scrapy 去请求这个接口,然后通过 Item + Pipeline 写到 MySQL 里。
一、实现过程和主要代码
1.1 目标网站和字段设计
我选的是东方财富的 A 股行情列表页面:
-https://quote.eastmoney.com/center/gridlist.html#hs_a_board
在浏览器按 F12,看 Network 里的请求,可以看到有一个叫 clist/get 的接口,地址是:
"https://push2.eastmoney.com/api/qt/clist/get"
这个接口返回的 JSON 结构里,每只股票是一条记录,大概长这样(只截一部分字段):
{
"data": {
"diff": [
{
"f12": "600000",
"f14": "浦发银行",
"f2": 9.50,
"f3": 1.28,
"f4": 0.12,
"f5": 123456,
"f7": 2.34,
"f15": 9.60,
"f16": 9.30,
"f17": 9.32,
"f18": 9.38
}
]
}
}
我把要用到的字段和数据库字段这样对应起来:
| 接口字段 | 含义 | MySQL 字段名 |
|---|---|---|
| f12 | 股票代码 | bStockNo |
| f14 | 股票名称 | bStockName |
| f2 | 最新价 | bLatestPrice |
| f3 | 涨跌幅 | bChangePercent |
| f4 | 涨跌额 | bChangeAmount |
| f5 | 成交量 | bVolume |
| f7 | 振幅 | bAmplitude |
| f15 | 最高 | bHigh |
| f16 | 最低 | bLow |
| f17 | 今开 | bOpenToday |
| f18 | 昨收 | bCloseYesterday |
对应的 MySQL 表结构如下(我放在 stock_db 这个库里):
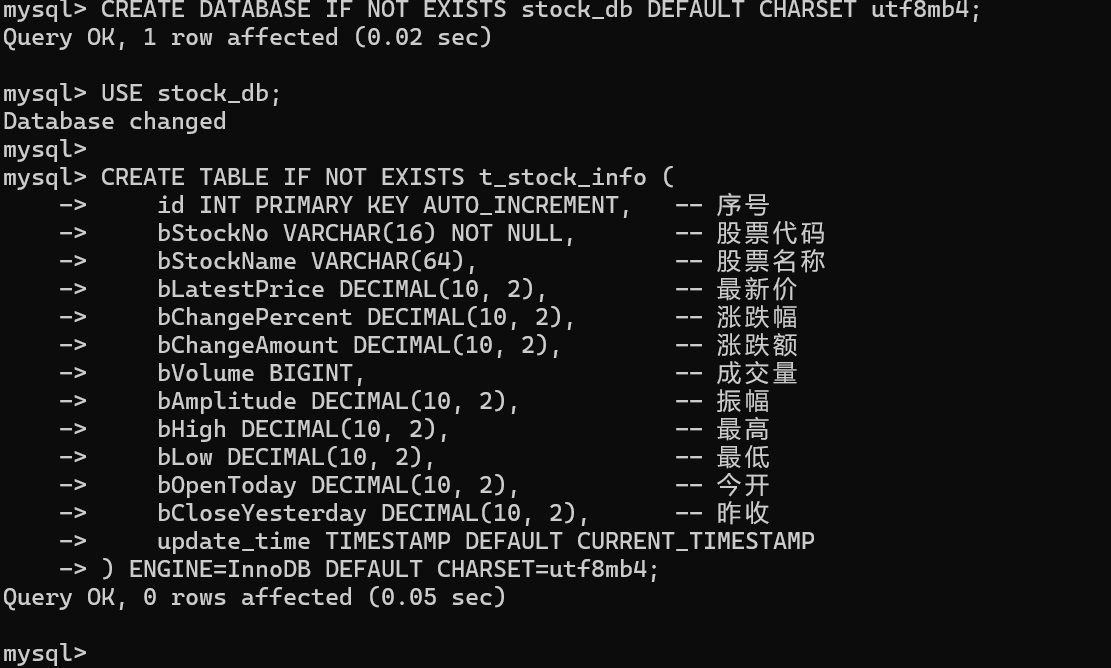
Item:在 Scrapy 里描述这行数据
import scrapy
class StockItem(scrapy.Item):
"""东方财富股票信息"""
# 序号 id 用 MySQL 自增,这里不写
bStockNo = scrapy.Field() # 股票代码
bStockName = scrapy.Field() # 股票名称
bLatestPrice = scrapy.Field() # 最新价
bChangePercent = scrapy.Field() # 涨跌幅(%)
bChangeAmount = scrapy.Field() # 涨跌额
bVolume = scrapy.Field() # 成交量
bAmplitude = scrapy.Field() # 振幅(%)
bHigh = scrapy.Field() # 最高
bLow = scrapy.Field() # 最低
bOpenToday = scrapy.Field() # 今开
bCloseYesterday = scrapy.Field() # 昨收
字段名和表结构是一一对应的,后面 Pipeline 里直接拿这些字段写 SQL 就行。
1.2 Spider + Pipeline + Settings 代码
Spider:请求东方财富接口,解析 JSON
import json
import scrapy
from stock_spider.items import StockItem
class EastmoneyApiSpider(scrapy.Spider):
name = "eastmoney_api_spider"
allowed_domains = ["push2.eastmoney.com"]
base_url = "https://push2.eastmoney.com/api/qt/clist/get"
# 这些参数基本照着浏览器里的请求抄出来
base_params = {
"np": "1",
"fltt": "1",
"invt": "2",
"fs": "m:0+t:6+f:!2,m:0+t:80+f:!2,m:1+t:2+f:!2,m:1+t:23+f:!2,m:0+t:81+s:262144+f:!2",
"fields": "f12,f13,f14,f2,f3,f4,f5,f6,f7,f15,f16,f17,f18",
"fid": "f3",
"pz": "20", # 每页 20 条
"po": "1",
"dect": "1",
"ut": "fa5fd1943c7b386f172d6893dbfba10b",
}
custom_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)",
"Referer": "https://quote.eastmoney.com/center/gridlist.html#hs_a_board",
}
def start_requests(self):
# 这里简单抓前 5 页
for page in range(1, 6):
params = self.base_params.copy()
params["pn"] = str(page)
yield scrapy.FormRequest(
url=self.base_url,
method="GET",
formdata=params,
headers=self.custom_headers,
callback=self.parse_page,
cb_kwargs={"page": page},
)
def parse_page(self, response, page):
try:
data = json.loads(response.text)
except Exception as e:
self.logger.error("第 %s 页 JSON 解析失败: %s", page, e)
return
if "data" not in data or "diff" not in data["data"]:
self.logger.error("第 %s 页 data.diff 缺失", page)
return
stocks = data["data"]["diff"]
self.logger.info("第 %s 页 共 %s 条数据", page, len(stocks))
for s in stocks:
item = StockItem()
# 字段对应关系:
# f12: 代码, f14: 名称
# f2: 最新价, f3: 涨跌幅, f4: 涨跌额
# f5: 成交量, f7: 振幅
# f15: 最高, f16: 最低, f17: 今开, f18: 昨收
item["bStockNo"] = s.get("f12")
item["bStockName"] = s.get("f14")
item["bLatestPrice"] = s.get("f2", 0)
item["bChangePercent"] = s.get("f3", 0)
item["bChangeAmount"] = s.get("f4", 0)
item["bVolume"] = s.get("f5", 0)
item["bAmplitude"] = s.get("f7", 0)
item["bHigh"] = s.get("f15", 0)
item["bLow"] = s.get("f16", 0)
item["bOpenToday"] = s.get("f17", 0)
item["bCloseYesterday"] = s.get("f18", 0)
# 打一行日志,对照网页看一下
self.logger.info(
"%s %s 最新价=%s 涨跌幅=%s 成交量=%s",
item["bStockNo"],
item["bStockName"],
item["bLatestPrice"],
item["bChangePercent"],
item["bVolume"],
)
yield item
虽然题目里提到了 XPath,但是股票列表页面是前端渲染的,直接用 XPath 很难拿到完整数据,所以我这边是通过开发者工具先确定了数据所在的接口,再用 Scrapy 去请求这个 JSON 接口。
Pipeline:把 Item 写到 MySQL
import pymysql
from itemadapter import ItemAdapter
from datetime import datetime
class MySQLStorePipeline:
"""把股票数据写入 MySQL"""
def __init__(self, host, port, db, user, password, charset):
self.host = host
self.port = port
self.db = db
self.user = user
self.password = password
self.charset = charset
@classmethod
def from_crawler(cls, crawler):
return cls(
host=crawler.settings.get("MYSQL_HOST", "127.0.0.1"),
port=crawler.settings.getint("MYSQL_PORT", 3306),
db=crawler.settings.get("MYSQL_DATABASE", "stock_db"),
user=crawler.settings.get("MYSQL_USER", "root"),
password=crawler.settings.get("MYSQL_PASSWORD", ""),
charset=crawler.settings.get("MYSQL_CHARSET", "utf8mb4"),
)
def open_spider(self, spider):
self.conn = pymysql.connect(
host=self.host,
port=self.port,
user=self.user,
password=self.password,
database=self.db,
charset=self.charset,
)
self.cursor = self.conn.cursor()
def close_spider(self, spider):
if hasattr(self, "cursor"):
self.cursor.close()
if hasattr(self, "conn"):
self.conn.close()
def process_item(self, item, spider):
adapter = ItemAdapter(item)
sql = """
INSERT INTO t_stock_info (
bStockNo,
bStockName,
bLatestPrice,
bChangePercent,
bChangeAmount,
bVolume,
bAmplitude,
bHigh,
bLow,
bOpenToday,
bCloseYesterday,
update_time
) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
values = (
adapter.get("bStockNo"),
adapter.get("bStockName"),
self._to_float(adapter.get("bLatestPrice")),
self._to_float(adapter.get("bChangePercent")),
self._to_float(adapter.get("bChangeAmount")),
self._to_int(adapter.get("bVolume")),
self._to_float(adapter.get("bAmplitude")),
self._to_float(adapter.get("bHigh")),
self._to_float(adapter.get("bLow")),
self._to_float(adapter.get("bOpenToday")),
self._to_float(adapter.get("bCloseYesterday")),
datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
)
try:
self.cursor.execute(sql, values)
self.conn.commit()
except Exception as e:
spider.logger.error("MySQL 插入失败: %s", e)
self.conn.rollback()
return item
def _to_float(self, value):
try:
if value in (None, ""):
return None
return float(value)
except Exception:
return None
def _to_int(self, value):
try:
if value in (None, ""):
return None
return int(value)
except Exception:
return None
Settings:启用 Pipeline,配置数据库
BOT_NAME = "stock_spider"
SPIDER_MODULES = ["stock_spider.spiders"]
NEWSPIDER_MODULE = "stock_spider.spiders"
# 不遵守 robots.txt,否则很多接口直接被拦
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
"stock_spider.pipelines.MySQLStorePipeline": 300,
}
# MySQL 相关配置
MYSQL_HOST = "127.0.0.1"
MYSQL_PORT = 3306
MYSQL_DATABASE = "stock_db"
MYSQL_USER = "root"
MYSQL_PASSWORD = "root"
MYSQL_CHARSET = "utf8mb4"
DEFAULT_REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)",
"Referer": "https://quote.eastmoney.com/center/gridlist.html#hs_a_board",
}
效果截图
-
命令行运行爬虫的截图;
![image]()
-
MySQL 查询
t_stock_info表前几行的截图。
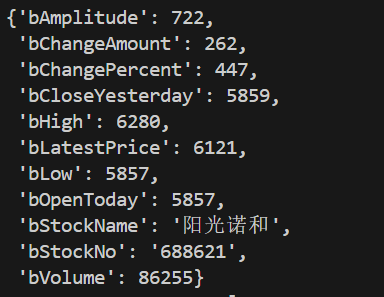
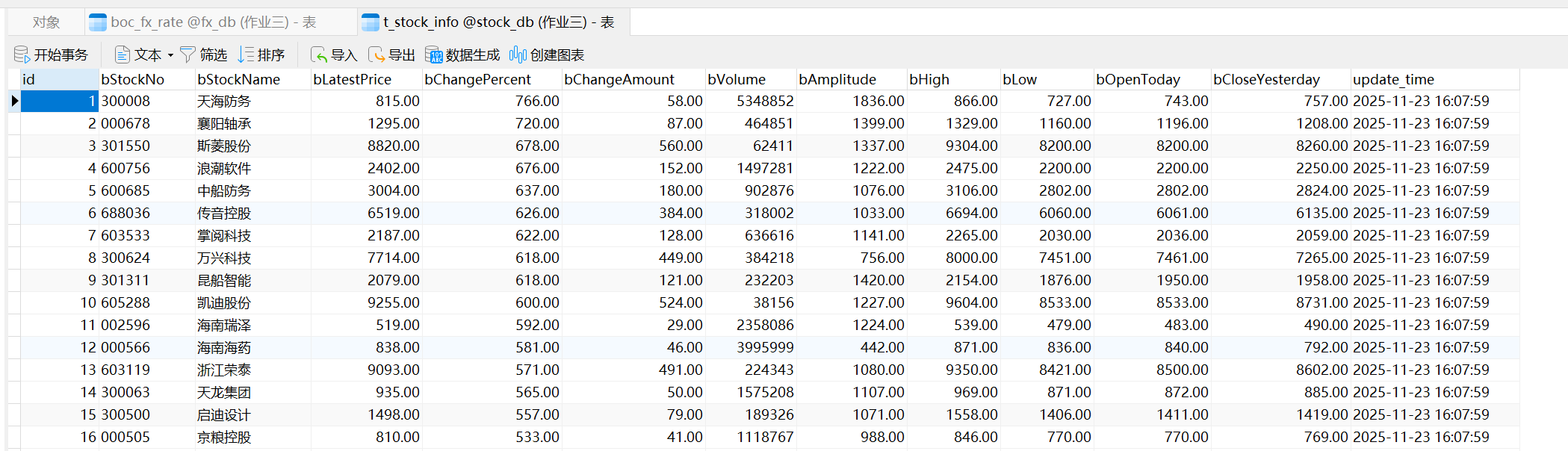
二、作业心得
这次作业主要是用 Scrapy 的 Spider 抓东方财富接口数据,用 Item 组织字段,再通过 Pipeline 写入 MySQL,把“数据从接口到数据库”的整条流程跑通,对 Scrapy 的基本用法有了整体印象。
三. 用 Scrapy + MySQL 爬取中国银行外汇牌价
这次作业的要求是:
- 用 Scrapy 框架,熟悉 Item、Pipeline 这套数据序列化输出;
- 使用 Scrapy + XPath + MySQL 的路线,从中国银行外汇牌价页面抓数据;
- 网站地址:中国银行外汇牌价;
- 把数据写到 MySQL 中,并给出输出结果和截图。
我用的是一个完整的 Scrapy 项目:
Spider 负责用 XPath 解析表格,Item 描述每一行外汇数据,Pipeline 管理 MySQL 插入。
一、实现过程和主要代码
1.1 页面结构分析和字段设计
目标页面打开后,主要是一个外汇牌价表格,表头大概是:
| 货币名称 | 现汇买入价 | 现钞买入价 | 现汇卖出价 | 现钞卖出价 | 中行折算价 | 发布日期 | 发布时间 |
按这个顺序,我在 Scrapy 里设计了一个 BocFxItem,字段尽量跟表头对应:
import scrapy
class BocFxItem(scrapy.Item):
"""中国银行外汇牌价 Item"""
currency_name = scrapy.Field() # 货币名称
cash_buy = scrapy.Field() # 现汇买入价
remittance_buy = scrapy.Field() # 现钞买入价
cash_sell = scrapy.Field() # 现汇卖出价
remittance_sell = scrapy.Field() # 现钞卖出价
mid_rate = scrapy.Field() # 中行折算价
pub_date = scrapy.Field() # 发布日期
pub_time = scrapy.Field() # 发布时间
MySQL 这边我建了一个库 fx_db,表名叫 boc_fx_rate,结构如下:
CREATE DATABASE IF NOT EXISTS fx_db DEFAULT CHARSET utf8mb4;
USE fx_db;
CREATE TABLE IF NOT EXISTS boc_fx_rate (
id INT PRIMARY KEY AUTO_INCREMENT, -- 序号
currency_name VARCHAR(64), -- 货币名称
cash_buy DECIMAL(10, 4), -- 现汇买入价
remittance_buy DECIMAL(10, 4), -- 现钞买入价
cash_sell DECIMAL(10, 4), -- 现汇卖出价
remittance_sell DECIMAL(10, 4), -- 现钞卖出价
mid_rate DECIMAL(10, 4), -- 中行折算价
pub_date VARCHAR(16), -- 发布日期
pub_time VARCHAR(16), -- 发布时间
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
Spider 用 XPath 从表格里把每一行抓出来,核心代码如下:
import scrapy
from boc_fx_spider.items import BocFxItem
class BocFxSpider(scrapy.Spider):
name = "boc_fx_spider"
allowed_domains = ["boc.cn"]
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
# 找表头第一列是“货币名称”的那张表
table = response.xpath(
'//table[.//th[1][contains(normalize-space(.),"货币名称")]]'
)
if not table:
self.logger.error("没有找到包含 '货币名称' 的表头,已保存页面 boc_fx_debug2.html")
with open("boc_fx_debug2.html", "wb") as f:
f.write(response.body)
return
rows = table.xpath("./tr")
self.logger.info("表格中共找到 %d 行(含表头)", len(rows))
for row in rows:
tds = row.xpath("./td/text()").getall()
tds = [t.strip() for t in tds if t.strip()]
if len(tds) < 8:
# 表头或者空行
continue
# 对应关系:
# 0: 货币名称
# 1: 现汇买入价
# 2: 现钞买入价
# 3: 现汇卖出价
# 4: 现钞卖出价
# 5: 中行折算价
# 6: 发布日期(源代码里是 "2025/11/23 10:50:50")
# 7: 发布时间("10:50:50")
currency_name = tds[0]
cash_buy = tds[1]
remittance_buy = tds[2]
cash_sell = tds[3]
remittance_sell = tds[4]
mid_rate = tds[5]
raw_pub = tds[6]
parts = raw_pub.split()
if len(parts) == 2:
pub_date, dt_from_pjrq = parts
else:
pub_date = raw_pub
dt_from_pjrq = ""
pub_time = tds[7] or dt_from_pjrq
item = BocFxItem()
item["currency_name"] = currency_name
item["cash_buy"] = cash_buy
item["remittance_buy"] = remittance_buy
item["cash_sell"] = cash_sell
item["remittance_sell"] = remittance_sell
item["mid_rate"] = mid_rate
item["pub_date"] = pub_date
item["pub_time"] = pub_time
self.logger.info(
"%s 现汇买入=%s 折算价=%s 日期=%s 时间=%s",
currency_name,
cash_buy,
mid_rate,
pub_date,
pub_time,
)
yield item
1.2 Pipeline 持久化到 MySQL
Pipeline 负责接收 Spider 传过来的 BocFxItem,做一下类型转换,然后插入到 MySQL 的 boc_fx_rate 表里。
import pymysql
from itemadapter import ItemAdapter
class MySQLFxPipeline:
"""把外汇牌价写入 MySQL"""
def __init__(self, host, port, db, user, password, charset):
self.host = host
self.port = port
self.db = db
self.user = user
self.password = password
self.charset = charset
@classmethod
def from_crawler(cls, crawler):
return cls(
host=crawler.settings.get("MYSQL_HOST", "127.0.0.1"),
port=crawler.settings.getint("MYSQL_PORT", 3306),
db=crawler.settings.get("MYSQL_DATABASE", "fx_db"),
user=crawler.settings.get("MYSQL_USER", "root"),
password=crawler.settings.get("MYSQL_PASSWORD", ""),
charset=crawler.settings.get("MYSQL_CHARSET", "utf8mb4"),
)
def open_spider(self, spider):
self.conn = pymysql.connect(
host=self.host,
port=self.port,
user=self.user,
password=self.password,
database=self.db,
charset=self.charset,
)
self.cursor = self.conn.cursor()
def close_spider(self, spider):
if hasattr(self, "cursor"):
self.cursor.close()
if hasattr(self, "conn"):
self.conn.close()
def process_item(self, item, spider):
adapter = ItemAdapter(item)
sql = """
INSERT INTO boc_fx_rate (
currency_name,
cash_buy,
remittance_buy,
cash_sell,
remittance_sell,
mid_rate,
pub_date,
pub_time
) VALUES (%s,%s,%s,%s,%s,%s,%s,%s)
"""
values = (
adapter.get("currency_name"),
self._to_float(adapter.get("cash_buy")),
self._to_float(adapter.get("remittance_buy")),
self._to_float(adapter.get("cash_sell")),
self._to_float(adapter.get("remittance_sell")),
self._to_float(adapter.get("mid_rate")),
adapter.get("pub_date"),
adapter.get("pub_time"),
)
try:
self.cursor.execute(sql, values)
self.conn.commit()
except Exception as e:
spider.logger.error("MySQL 插入失败: %s", e)
self.conn.rollback()
return item
def _to_float(self, value):
try:
if value in (None, ""):
return None
return float(str(value).replace(",", ""))
except Exception:
return None
在 settings.py 里开启这个 Pipeline,并配置好 MySQL:
BOT_NAME = "boc_fx_spider"
SPIDER_MODULES = ["boc_fx_spider.spiders"]
NEWSPIDER_MODULE = "boc_fx_spider.spiders"
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
"boc_fx_spider.pipelines.MySQLFxPipeline": 300,
}
# MySQL 配置
MYSQL_HOST = "127.0.0.1"
MYSQL_PORT = 3306
MYSQL_DATABASE = "fx_db"
MYSQL_USER = "root"
MYSQL_PASSWORD = "root"
MYSQL_CHARSET = "utf8mb4"
DEFAULT_REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)",
}
运行结果
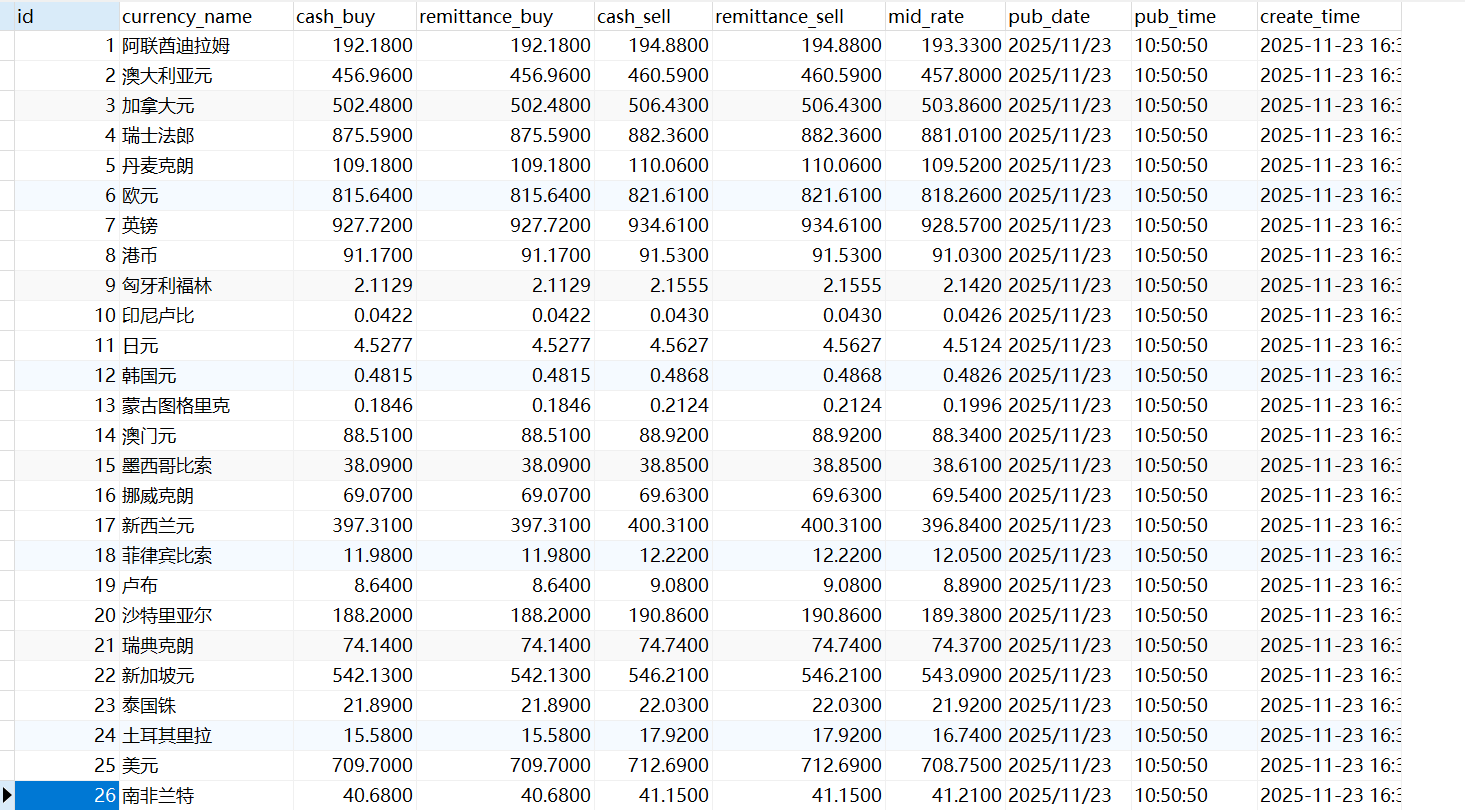
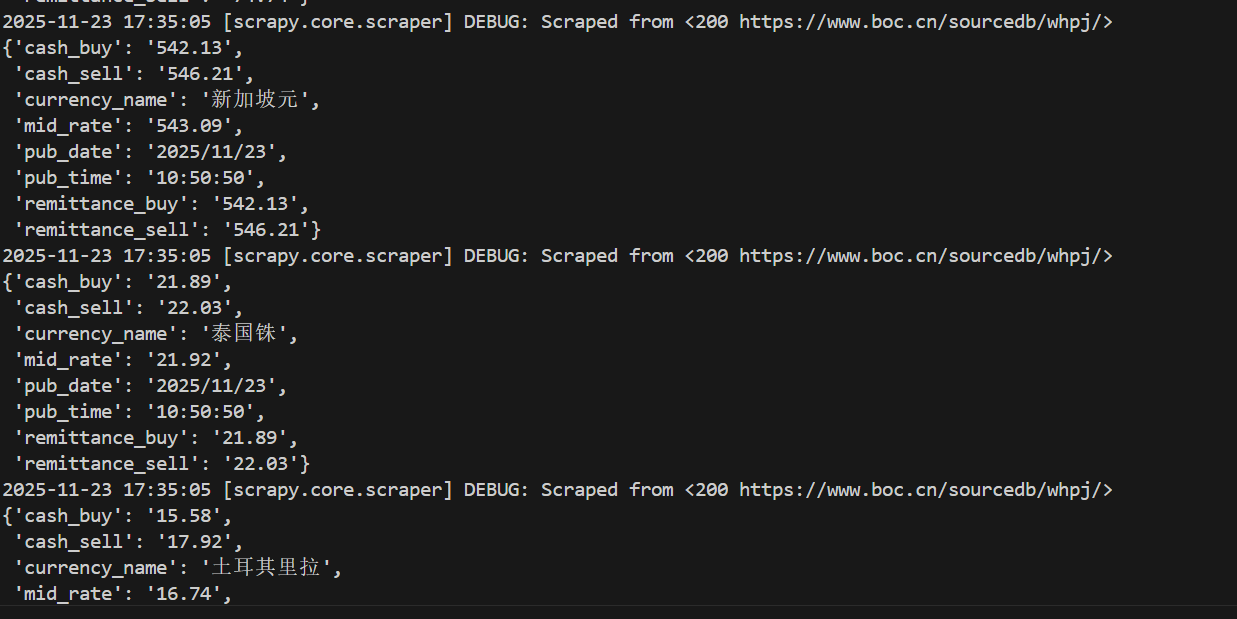
二、作业心得
这次作业就是用 Scrapy 把中国银行外汇牌价表用 XPath 抓下来,通过 Item 传给 Pipeline,再写入 MySQL,把“网页表格 → Item → 数据库”这条路跑通,对以后做别的网站有了个固定套路。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号