Elasticsearch (三)进阶检索及整合 spring boot
五、进阶检索
* 批量导入es官方提供的数据
es官方批量数据地址,导入数据:
POST /bank/account/_bulk
{"index":{"_id":"1"}}
{"account_number":1,"balance":39225,"firstname":"Amber","lastname":"Duke","age":32,"gender":"M","address":"880 Holmes Lane","employer":"Pyrami","email":"amberduke@pyrami.com","city":"Brogan","state":"IL"}
{"index":{"_id":"6"}}
{"account_number":6,"balance":5686,"firstname":"Hattie","lastname":"Bond","age":36,"gender":"M","address":"671 Bristol Street","employer":"Netagy","email":"hattiebond@netagy.com","city":"Dante","state":"TN"}
{"index":{"_id":"13"}}
.....全部的数据导入
进阶搜索,主要参考 官方文档
5.1、SearchAPI
ES支持两种基本方式的检索:
- 通过使用
REST request URI发送搜索参数( uri + 检索参数 ) - 通过使用
REST request body发送搜索参数( uri + 请求体 )
5.1.1 检索信息
-
一切检索从
_search开始GET/bank/account/_search检索 bank 下所有信息,包括type和docs -
uri + 请求参数进行检索
GET/bank/account/_search?q=*&account_number:asc请求参数解析:
请求参数 含义 q=*查询所有 account_number:asc查询到的所有数据,根据账号进行升序排列 返回值参数解析: 参考API文档
返回参数 含义 tookElasticsearch 执行搜索的时间(ms) time_out搜索是否超时 _shards多少分片被搜索了,以及统计 成功 / 失败 的搜索分片 hits搜索结果 hits.total搜索结果的总数 hits.hits实际的搜索结果数组(默认为前10个文档) sort结果的排序 key(键) 没有则按 score 排序 score、max_score相关性得分和最高得分(全文检索用) -
uri + 请求体进行检索
Query DSLGET/bank/_search{ # 查询条件 "query": { "match_all": {} # 请求全部 }, # 排序规则 排序规则为一个数组,如果有多个,则依次添加上即可 "sort": [ { "account_number": "asc" } ] }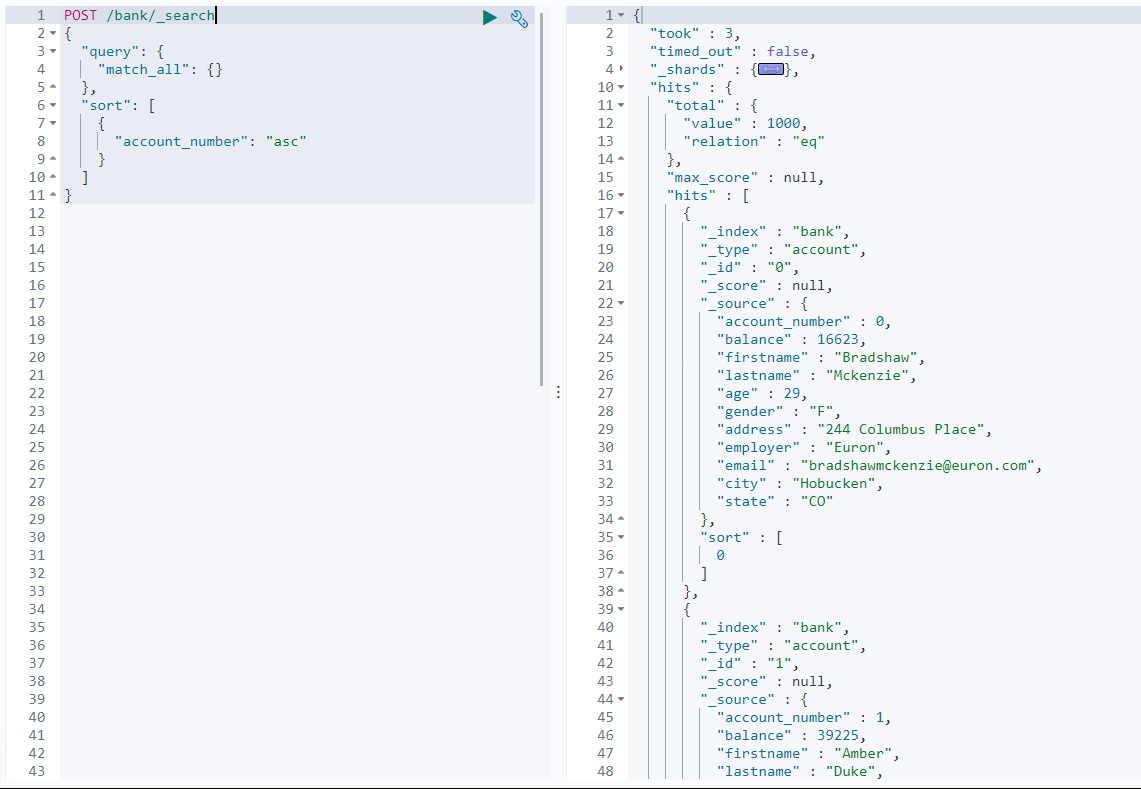
5.1.2 Query DSL
5.1.2.1 基本语法
Elasticsearch 提供提供了一个可以执行查询的 JSON 风格的 DSL (domain-specific language 领域特定语言)。被称为 Query DSL。该查询语言非常全面,并且刚开始的时候有点复杂,可以通过几个简单示例去理解他
-
一个查询语句的典型结构
{ QUERY_NAME: { # 如: query,sort, from, fitter。。。。 ARGUMENT: VALUE, ARGUMENT: VALUE, .... } } -
如果是针对某个字段的查询,可以是这样的
{ QUERY_NAME: { # 如: query,sort, from, fitter。。。。 FIELD_NAME: { # 字段名 ARGUMENT: VALUE, ARGUMENT: VALUE, .... } } } -
示例:按金额字段降序,查询
bank索引下的 5-10 条数据POST/bank/_search{ "query": { "match_all": {} }, "sort": [ # 这里可以简写为 "balance": "desc" { "balance" : { "order": "desc" } } ], "from": 5, # 从第5个文档开始 "size": 5 # 取5个文档 } -
详细可参考 官方API文档
5.1.2.2 返回部分字段 _source
Elasticsearch 默认返回的是文档的全部字段,但是可以通过 _source 去指定返回的字段,
如:按金额字段降序,查询 bank 索引下的 5-10 条数据,只返回账号和金额字段
POST /bank/_search
{
"query": {
"match_all": {}
},
"sort": [
{ "balance" : "desc" }
],
"from": 5,
"size": 5,
"_source": ["balance","account_number"]
}
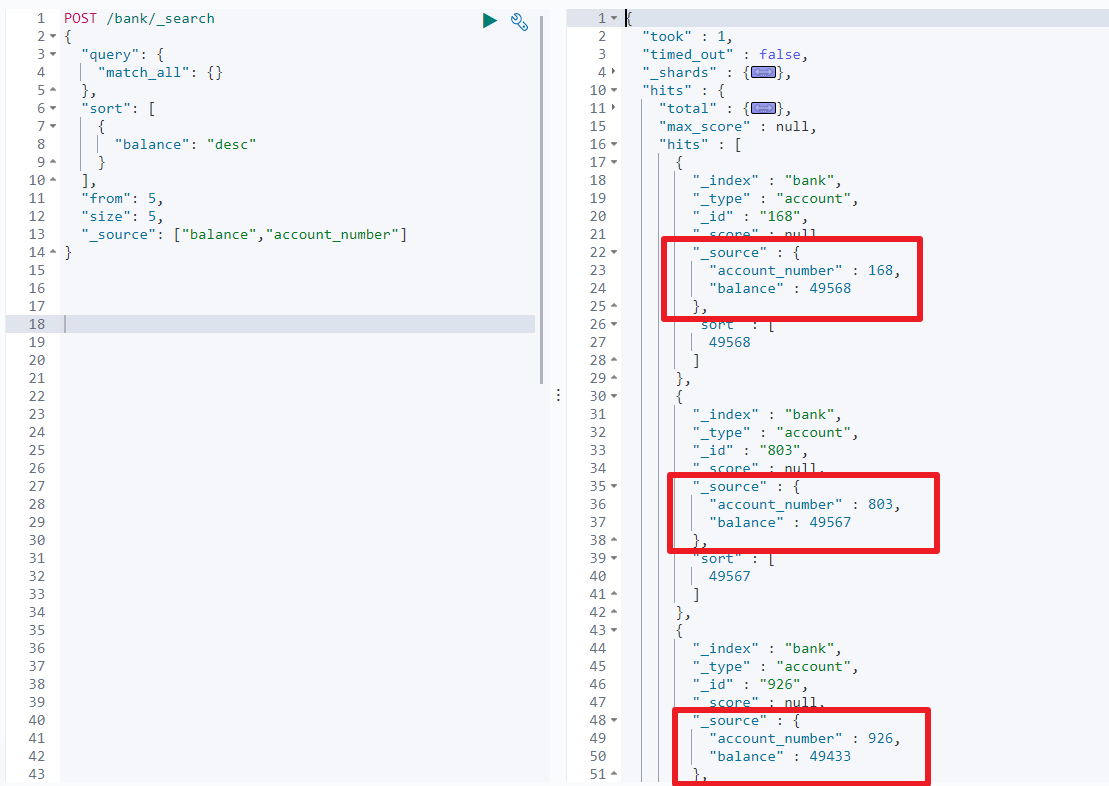
5.1.2.3 全文检索 match
match 对非字符串字段为精准查询,对字符串字段为 全文检索 , 返回的结果,按照评分从大到小进行排序。全文检索会对检索条件进行分词匹配
如: 查询金额为 20 的文档
GET /bank/_search
{
"query": {
"match": {
"account_number": 20
}
}
}

此时的返回结果中多 了一个字段
max_score即为返回的所有文档的最大得分
又如: 在address 中全文检索 mill road
GET /bank/_search
{
"query": {
"match": {
"address": "mill road"
}
}
}
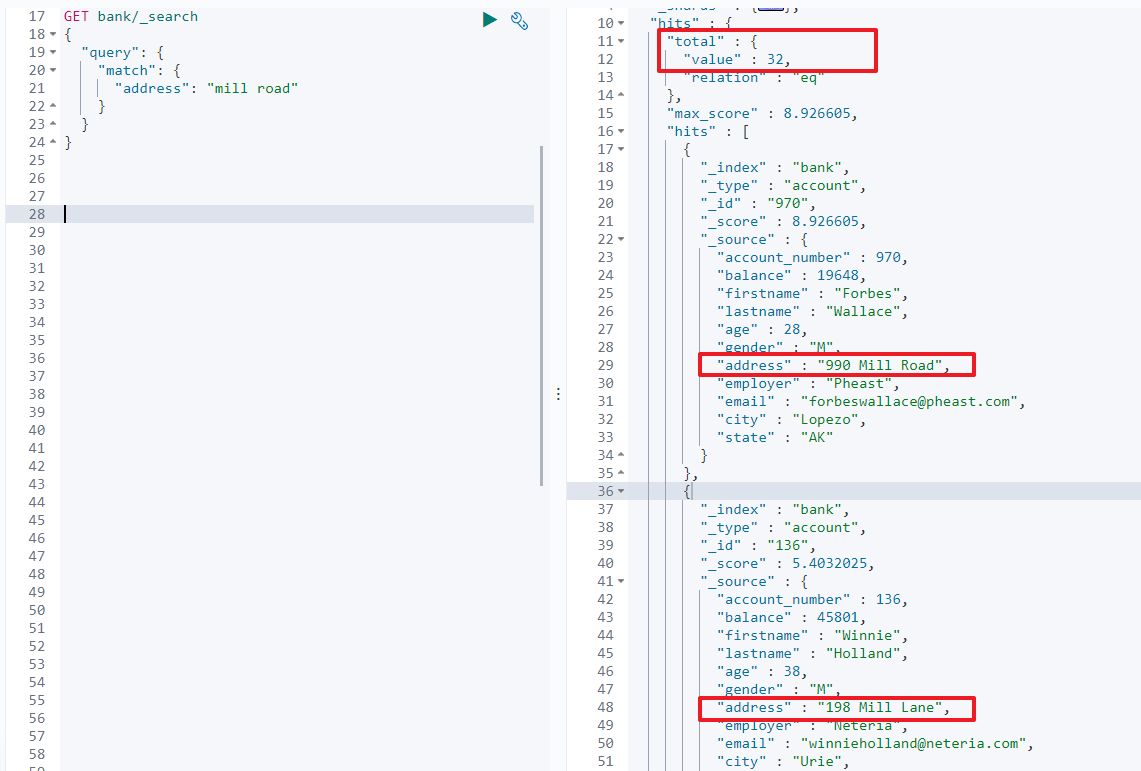
最终可以查询出32条记录,即 address 中包含 mill 或者 road 或者 mill road 的所有记录,并按相关性得分从大到小排序
5.1.2.4 短语匹配 match_phrase
根据5.1.2.3可知,使用 match 进行全文检索的时候,会将短语进行分词,然后进行匹配,最终按评分的大小进行排序返回。但是有时候,我们并不想让他进行分词搜索,即需要将匹配的值当成一个整体的单词。
如:查询地址中 包含 mill road 的文档
GET /bank/_search
{
"query": {
"match_phrase": {
"address": "mill road"
}
}
}
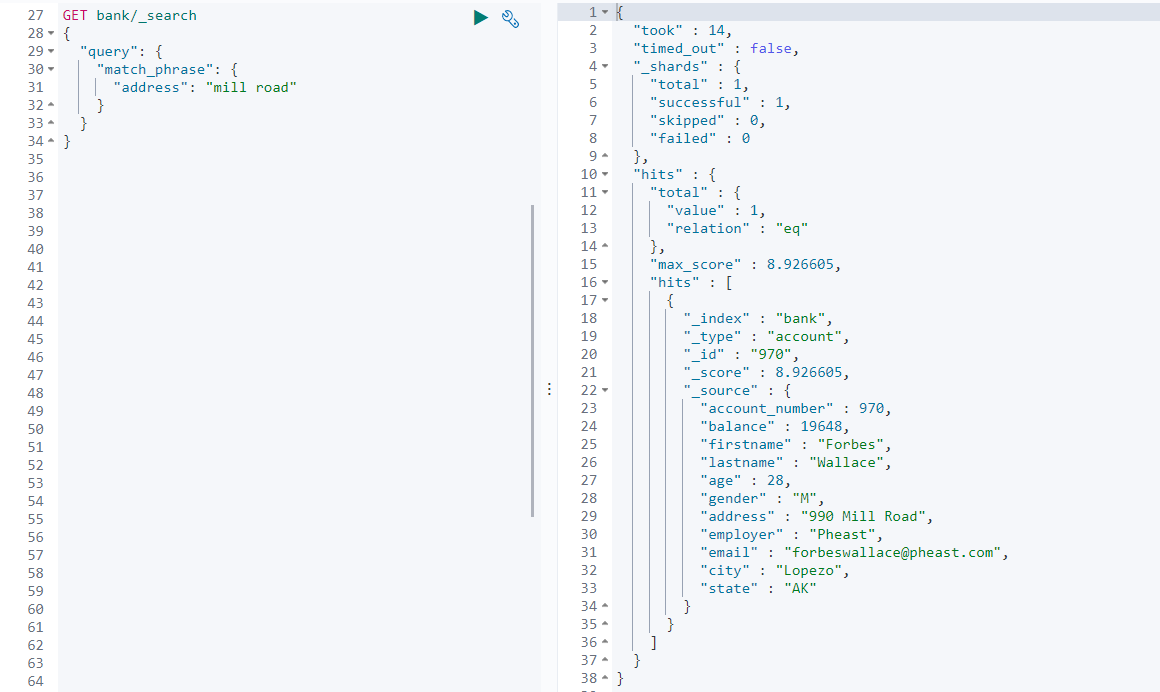
跟5.1.2.3 的第二个例子比较可以看出,使用 match_phrase 查询,不会进行分词匹配。当然 在使用 match 进行查询的时候,也可以不进行分词,因为,每个文本字段都有一个 .keyword ,当使用 match 进行查询的时候, 就可以使用 .keyword 进行匹配。如
{
"query": {
"match": {
"address.keyword": "mill road"
}
}
}
不过,该方法与 match_phrase 进行匹配的有所不同,当使用这个方法进行查询的时候,就要求 address 字段的值 必须跟 后面的查询的值是完全一样的才会被查询出来,即为精确查询
5.1.2.5 多字段匹配 multi_match
如同字面意思,有时候的查询,我们可能不止匹配一个字段,需要进行多个字段的查询,故使用 multi_match 可以对字段进行查询。且在查询的过程中,会进行分词。
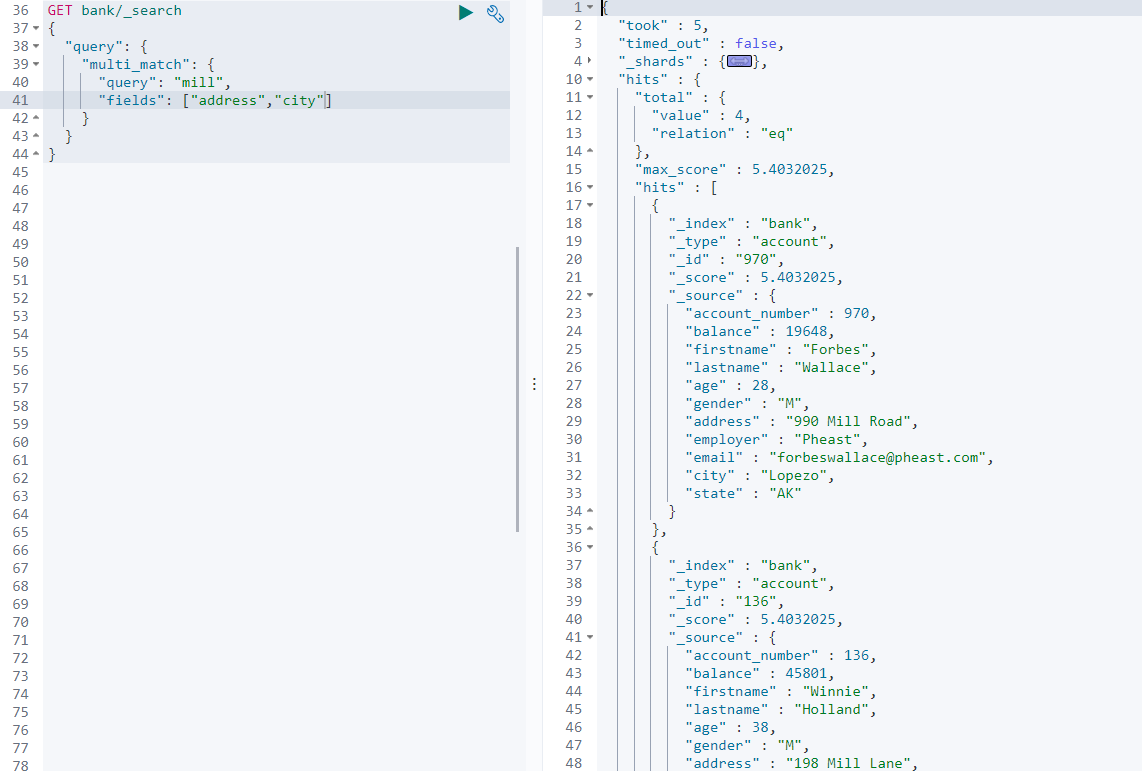
如:查询 address 或 cit 包含 mill 的文档
GET /bank/_search
{
"query": {
"multi_match": {
"query": "mill",
"fields": ["address","city"]
}
}
}
5.1.2.6 复合查询 bool
bool 是用来做复合查询,复合查询可以合并 任何 其他查询语句,包括复合语句,这就意味着,复合语句之间可以相互的嵌套,可以表达非常复杂的逻辑。
-
must:必须达到must列举的所有条件
如: 查询address中包含mill且gender为F的文档
GET/bank/_search{ "query": { "bool": { "must": [ { "match": { "gender": "F" } }, { "match": { "address": "mill" } } ] } } }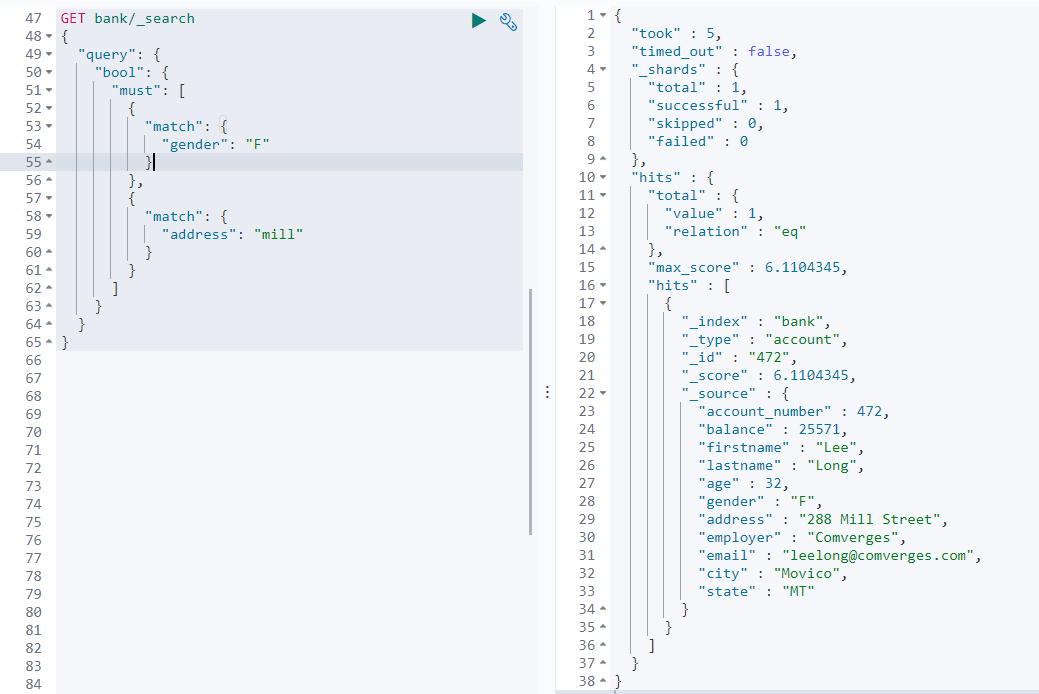
-
must_not:must_not里包含的条件必须都不满足如: 查询
address中包含mill且gender为M的文档, 且age不为 38 的文档GET/bank/_search{ "query": { "bool": { "must": [ { "match": { "gender": "M" } }, { "match": { "address": "mill" } } ], "must_not": [ { "match": { "age": 38 } } ] } } }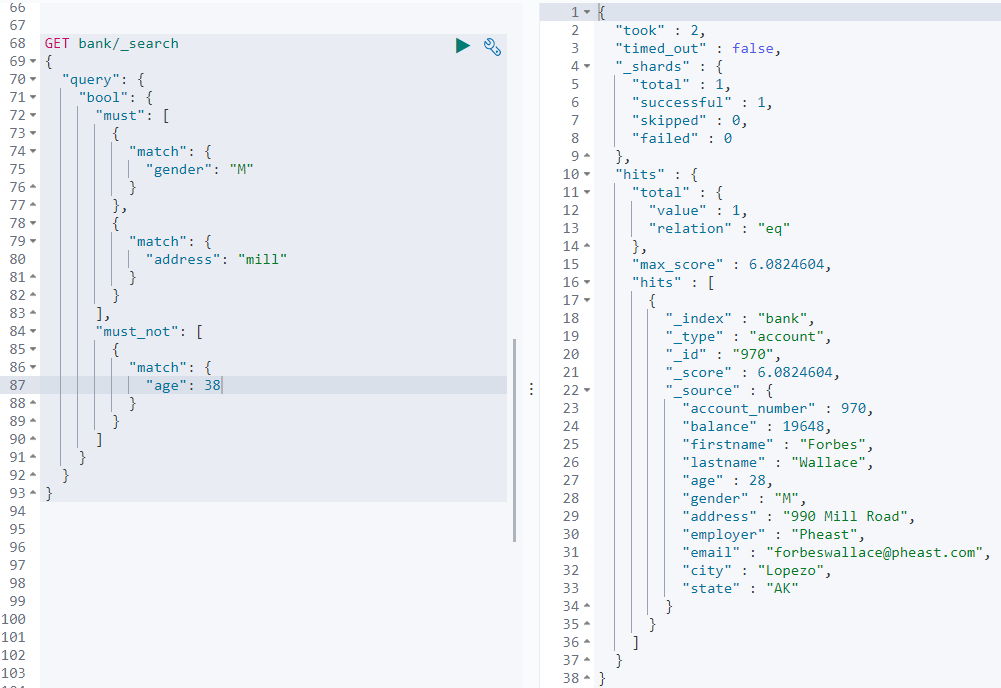
-
should: 应该达到should列举的条件,如果达到会增加相关文档的评分,并不会改变查询的结果。 如果query中只有should且只有一种匹配规则,那么should的条件就会被作为默认匹配条件而去改变查询结果如:查询
address中包含mill且gender为M的文档, 且age不为 28,且lastname最好是Holland的文档GET/bank/_search{ "query": { "bool": { "must": [ { "match": { "gender": "M" } }, { "match": { "address": "mill" } } ], "must_not": [ { "match": { "age": 28 } } ], "should": [ { "match": { "lastname": "Holland" } } ] } } }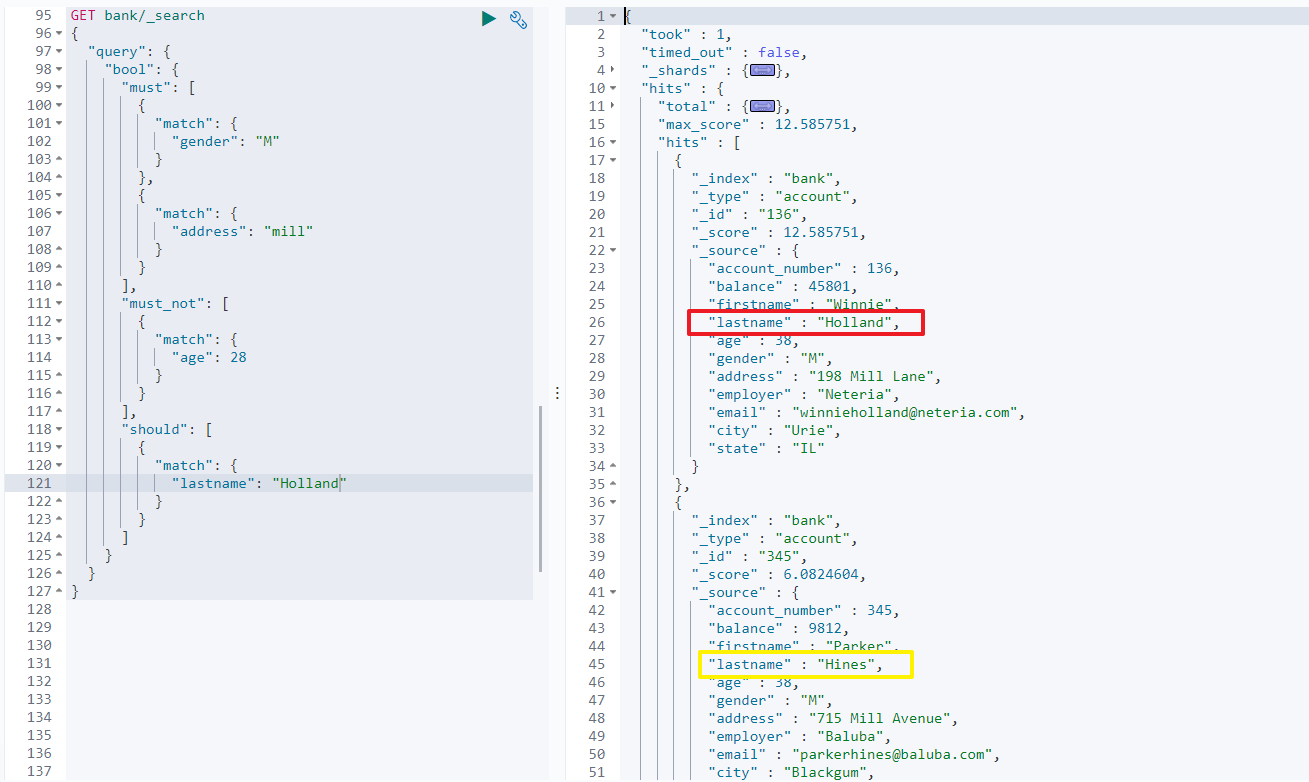
通过查询的结果可以看出,
lastname不为Holland的也可以查询出来。
5.1.2.7 结果过滤 filter
官方文档中,有如下一段话:
Each
must,should, andmust notelement in a Boolean query is referred to as a query clause. How well a document meets the criteria in eachmustorshouldclause contributes to the document’s relevance score。The ciriteria in amust_notclause is treated as afilter. It affects whether or not the document is included in the results, but does not contribute to how documents are scored.
即 在使用 must, should, must not,特别是 must, should的时候,如果满足条件的文档,那么就会提升相关文档的相关性得分。而当使用 must_not 的时候,它会被当做一个 filter ,从而不会贡献文档的得分。
filter : 结果过滤。 在查询中,并不是所有的查询都需要产生分数,特别是那些仅用filtering(过滤)的文档,为了不计算分数, Elasticsearch 会自动检查场景并且优化查询的执行
如:查询 age 在 18 到 30 之间 的文档
-
方法一 : 使用普通查询, 此时会增加出相关性得分
GET/bank/_search{ "query": { "bool": { "must": [ { "range": { "age": { "gte": 18, "lte": 30 } } } ] } } }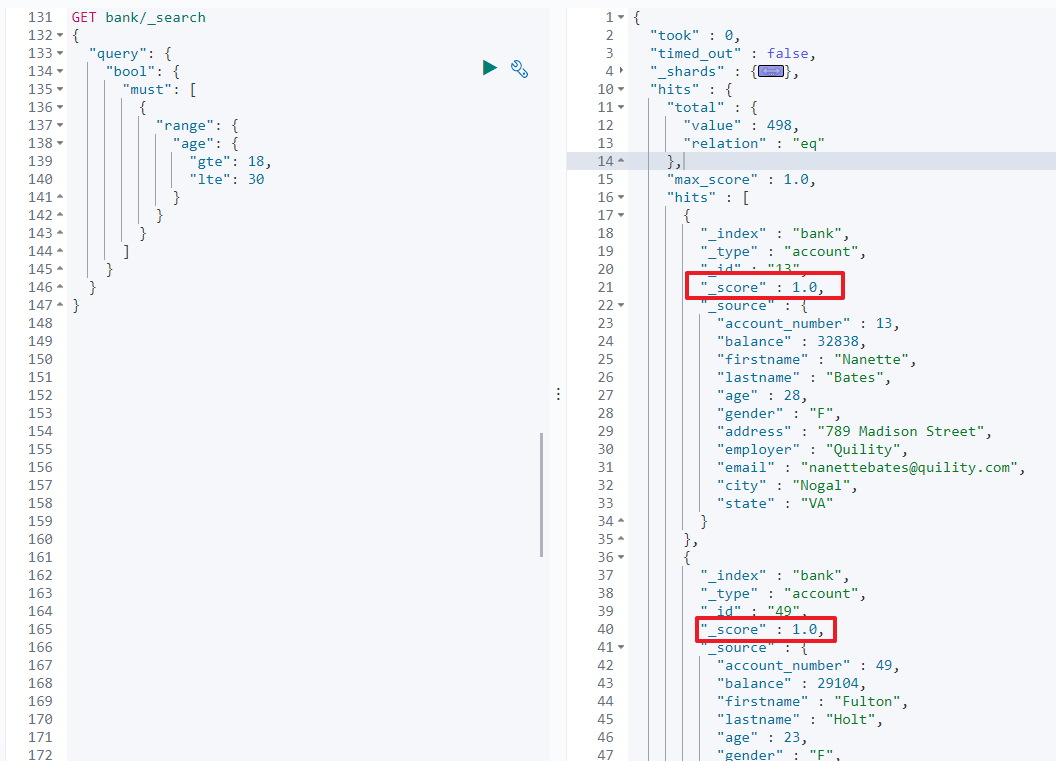
-
方法二: 使用
filter过滤,对相关性得分不影响
GET/bank/_search{ "query": { "bool": { "filter": { "range": { "age": { "gte": 10, "lte": 20 } } } } } }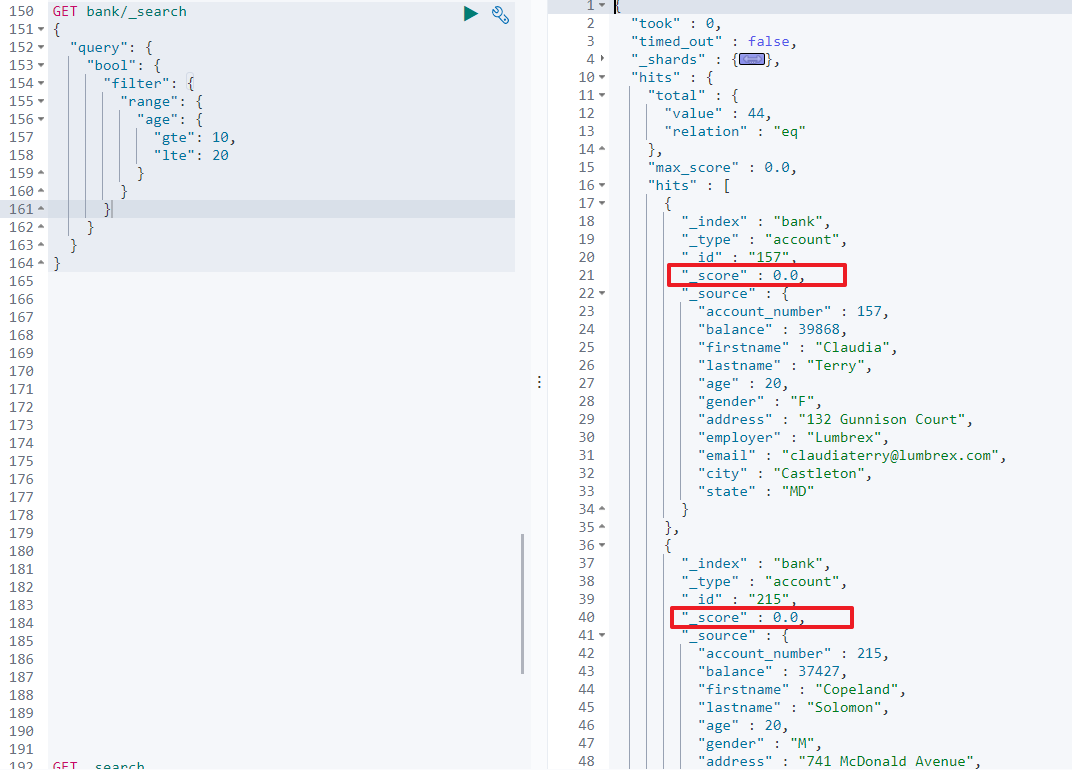
5.1.2.8 非text匹配 term
和 match 一样,用于匹配某个属性的值。全文检索字段用 match ,其他非 text 字段匹配用 term。
如:查询 age 为 28 的文档
GET /bank/_search
{
"query": {
"term": {
"age": 28
}
}
}
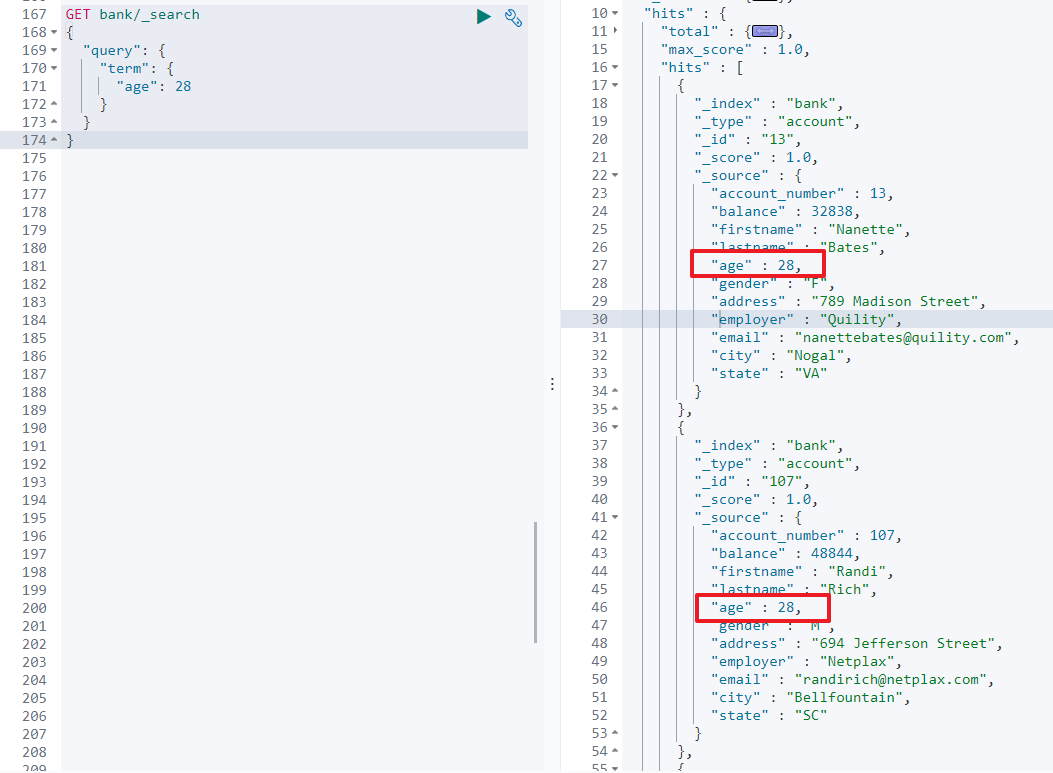
5.1.2.9 聚合 aggregations
聚合提供了从数据中分组和提取数据的能力。最简单的聚合方法大致等于 MySQL中的 GROUP BY和 SQL 聚合函数。在 Elasticsearch中,您有执行搜索返回 hits (命中结果),并且同时返回聚合结果,把一一个响应中的所有hits (命中结果)分隔开的能力。这是非常强大且有效的,您可以执行查询和多个聚合,并且在一次使用中得到各自的(任何一个的)返回结果,使用一次简洁和简化的API来避免网络往返。 官方文档
-
搜索
address中包含mill的所有人的年龄分布。
GET/bank/_search{ "query": { "match": { "address": "mill" } }, "aggs": { "ageAgg": { "terms": { # 看聚合的字段有多少中可能 "field": "age", "size": 10 # 只取出前10种可能 } } } }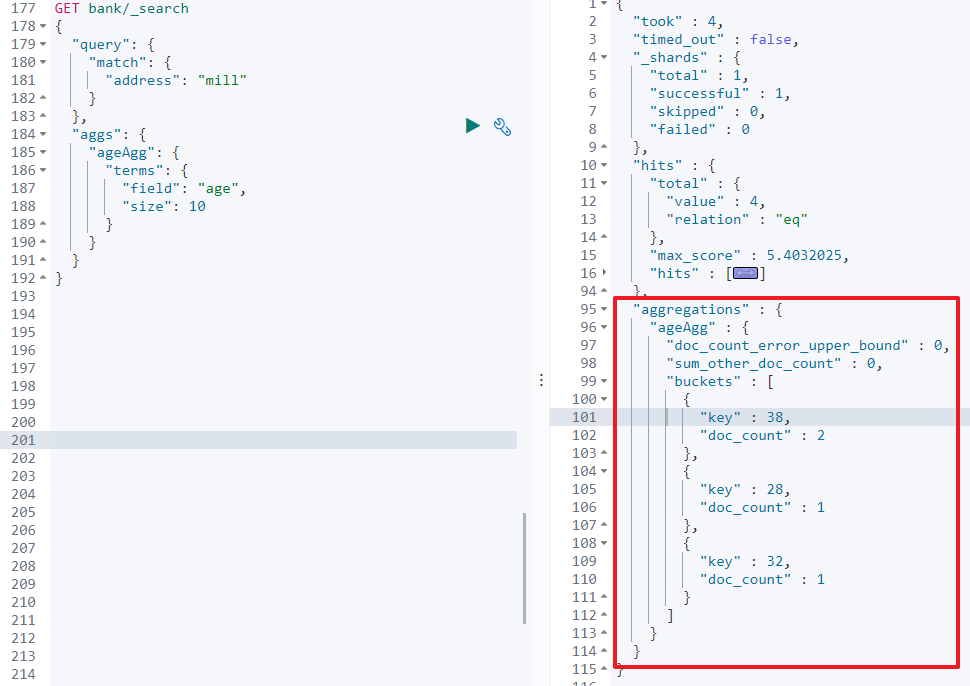
通过返回的结果可以看出,除了返回结果的
hits,还多返回了一个字段aggregations, 里面就是聚合的结果 -
搜索
address中包含mill的所有人的年龄分布及平均年龄。
GET/bank/_search{ "query": { "match": { "address": "mill" } }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 10 } }, "ageAvgAgg": { "avg": { "field": "age" } } } }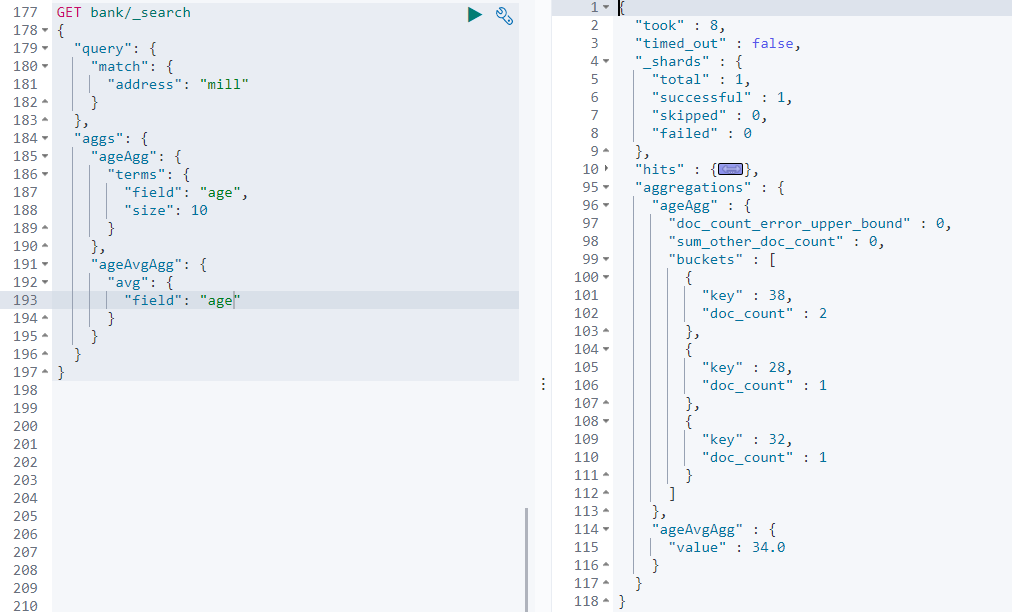
-
复杂聚合:聚合的聚合 如: 按照年龄聚合,并且查询出每个年龄段的平均薪资。
GET/bank/_search{ "query": { "match": { "address": "mill" } }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 10 }, "aggs": { "avuAgg": { "avg": { "field": "balance" } } } } } }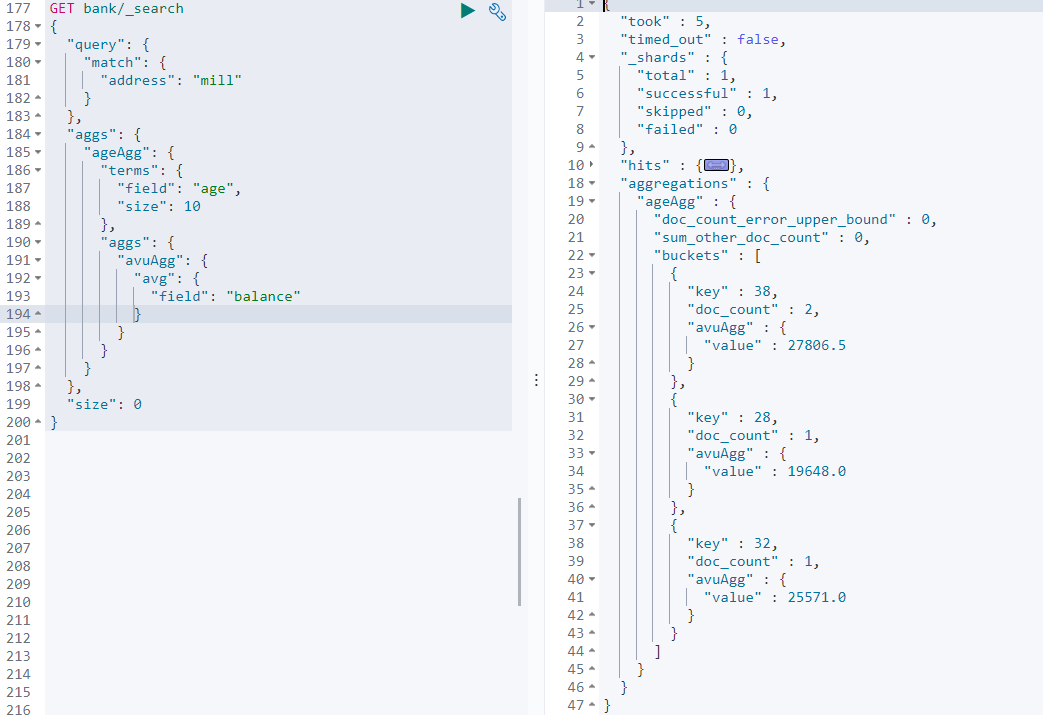
可以看出,在
ageAgg的聚合里面,还多了一个avuAgg,即在原来的聚合的结果中,再次进行数据的分析聚合。同理,Elaticsearch可以进行多层的子聚合。
5.1.3 映射 mapping
官方文档
映射是用来定义一个文档如何被处理的,即,每一个属性字段是如何进行存储和将被如何索引的。如,可以使用映射来定义:
- 哪些
String字段应视为全文字段。 - 哪些字段包含数字,日期或地理位置。
- 日期值的格式。
- 自定义规则来控制动态添加字段的映射。
5.1.3.1 字段类型
在 Elaticsearch 中,有非常多的映射类型:
-
核心类型
-
字符串(String)
text,keyword -
数字类型(Numeric)
long,integer,short,byte,double,float,half_float,scaled_ float -
日期类型(Date)
date -
布尔类型(Boolean)
boolean -
二进制类型 (binary)
binary
-
-
聚合类型
- 数组类型 (array)
Array支持不针对特性的类型 - 对象类型 (Object)
object用于单 JSON 的对象 - 嵌套类型 (Nested)
nested用于JSON对象数组
- 数组类型 (array)
-
地理类型 (Geo)
-
地理坐标(Geo-points)
geo_poiint用于描述 经纬度坐标 -
地理图形(Geo-Shape)
geo_shape用于描述复杂性质, 如多边形
-
-
特定类型
-
IP类型
ip用于描述ipv4和ipv6地址 -
补全类型 (Completion)
completion提供自动完成提示 -
令牌计数类型 (Token count)
token_count用于统计字符串中词条数量 -
附件类型 (attachment)
参考mapper-attachements插件, 支持将附件如Microsoft Office格式,ePub,HTML等等索引为attachment数据类型 -
抽取类型 (Percolator)
抽取特定领域查询语言(query-dsl)的查询
-
-
多字段
- 通常用于为 不同目的用不同方法索引同一个字段。 例如,
string字段可以映射为一个test字段用于全文检索,同样可以映射为一个keyword字段用于排序和聚合。另外, 你可以使用standard analyzer,english analyzer,french analyzer来索引一个text字段 - 这就是
muti-fields的目的。大多数的数据类型通过 fields 参数来支持muti-fields
- 通常用于为 不同目的用不同方法索引同一个字段。 例如,
Elaticsearch 会在第一次存储数据的时候,自动猜测数据的类型。
5.1.3.2 新版本的改变
在 Elaticsearch7 及以上移除了type的概念。
- 关系型数据库中两个数据表示是独立的,即使他们里面有相同名称的列也不影响使用,但
ES中不是这样的。elasticsearch是基于Lucene开发的搜索引擎,而ES中不同type下名称相同的filed最终在Lucene中的处理方式是一样的。- 两个不同
type下的两个user_ name, 在ES同一个索引下其实被认为是同一个filed,你必须在两个不同的type中定义相同的filed射。否则,不同type中的相同字段名称就会在处理中出现冲突的情况,导致Lucene处理效率下降。 - 去掉
type就是为了提高ES处理数据的效率。
- 两个不同
Elasticsearch 7.x
- URL 中的type参数为可选。比如,索引一个文档不再要求提供文档类型。
Elasticsearch 8.x
- 不再支持URL中的type参数。
解决:
1)、将索引从多类型迁移到单类型,每种类型文档一个独立索引
2)、将已存在的索引下的类型数据,全部迁移到指定位置即可。详见数据迁移
5.1.3.3 创建映射
PUT /my_index // 由于取消了 type ,所以就不再用 type了
{
"mappings": {
"properties": {
"age": {"type": "integer"},
"email": {"type": "keyword"},
"name": {"type": "text"}
}
}
}

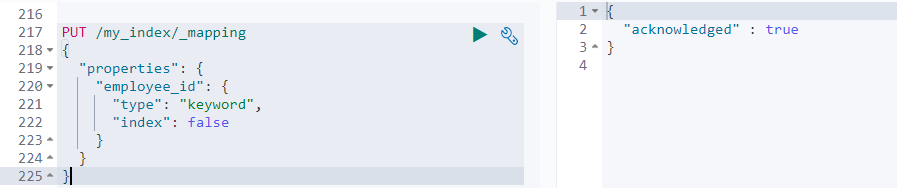
5.1.3.4 添加新的字段
PUT /my_index/_mapping
{
"properties": {
"employee_id": {
"type": "keyword",
"index": false # 设置为不被索引,默认为 true
}
}
}
5.1.3.5 更新映射
对于已经存在的映射字段,不能够更新。 更新必须创建新的索引进行数据迁移
5.1.3.6 数据迁移
先创建新的索引,创建新的映射规则,然后使用如下方法进行数据迁移 官方文档
PUT _reindex 【固定写法】
{
"source": {
"index": "bank" # 旧索引
},
"dest": {
"index": "new_bank" # 新索引
}
}
将旧索引的 type 下的数据进行迁移, 新旧版本的替换
PUT _reindex 【固定写法】
{
"source": {
"index": "bank", # 旧索引
"type": "accownt" # 旧索引的类型
},
"dest": {
"index": "new_bank" # 新索引
}
}
5.2 分词
一个tokenizer (分词器)接收一个字符流,将之分割为独立的tokens (词元,通常是独立的单词),然后输出tokens流。例如,whitespace tokenizer遇到空白字符时分割文本。它会将文本"Quick brown fox!"分割为[Quick, brown, fox!]。该tokenizer (分词器)还负责记录各个term (词条)的顺序或position位置(用于phrase短语和word proximity词近邻查询),以及term (词条)所代表的原始word (单词)的start(起始)和end (结束)的characteroffsets (字符偏移量) (用于 高亮显示搜索的内容)。Elasticsearch提供了很多内置的分词器,可以用来构建custom analyzers (自定义分词器)。 官方文档
5.2.1 标准分词器 standard
POST _analyze
{
"analyzer": "standard",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
[ the, 2, quick, brown, foxes, jumped, over, the, lazy, dog's, bone ]
不过,Elasticsearch 自带的分词器只能完成英文的分词,如果需要中文的分词,就需要安装额外的分词器,下面就安装一个常见的中文分词器 ik 分词器
5.2.1 安装 IK 分词器
注意: 不能用默认 elaticsearch-plugin install xxx.zip 进行安装
5.2.1.1 下载 IK 分词器
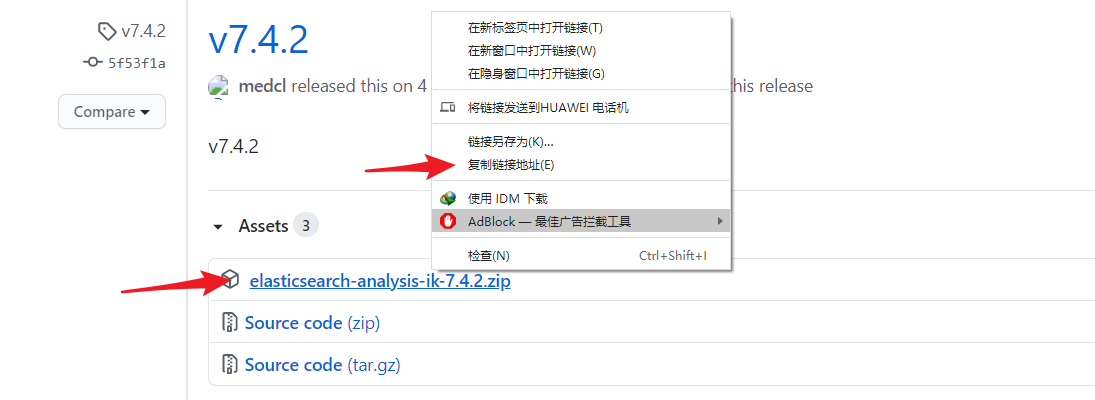
IK分词器 GitHub 地址 IK分词器 releases 版本下载地址
进入 IK分词器 releases 版本 下载地址,选择对应的 Elasticsearch 版本,复制下载链接地址。
使用 docker 的交互命令,进入容器的内部:
[root@localhost ~]# docker exec -it elasticsearch /bin/bash
[root@7a0299da8e79 elasticsearch]#
进入 plugins 路径,使用 wget 命令进行下载
[root@7a0299da8e79 elasticsearch]# cd plugins
[root@7a0299da8e79 plugins]# wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip
不过一般情况下, docker容器的内部是不会安装wget 命令,但是由于我们在启动的时候,已经将这个 plugins 目录映射到了我们本地路径下,所以在我们下载到我们本地的 plugins 路径也是一样的。
[root@7a0299da8e79 elasticsearch]# exit
[root@localhost ~]# cd /mydata/elasticsearch/plugins
[root@localhost plugins]# wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip
如果本地环境也没有
wget命令的话,可以使用如下命令进行安装yum install wget
5.2.1.2 安裝
下载完成后, 可以在 plugins 路径下得到一个压缩包 elasticsearch-analysis-ik-7.4.2.zip, 但是 linux 环境下,默认是无法解压 zip 格式的压缩包的,所以需要先安装一个工具 unzip
yum install -y unzip zip
安装完后,使用命令,解压文件, 并删除原有安装包
unzip -oq elasticsearch-analysis-ik-7.4.2.zip -d ik
rm -rf elasticsearch-analysis-ik-7.4.2.zip
重启 elasticsearch 即可
docker restart elasticsearch
如果虚拟机系统无法联网,或者嫌下载解压麻烦的话,也可以在本机上下载完成后,解压好,然后使用类似于
xftp的软件将解压好的文件夹,放入对应的目录下即可
5.2.1.3 使用 ik 分词器
IK 分词器有两个常用的分词:
-
ik_smartGET _analyze { "analyzer": "ik_smart", "text": "我是中国人" } -
ik_max_wordGET _analyze { "analyzer": "ik_max_word", "text": "我是中国人" }
通过查看结果,可见,不同的分词器,分词的结果是不同的,并且,只能识别一些常见的词语,一些新的词汇,网络用语,人名等等,都是无法识别的,所以还需要一个自定义的词库。
5.2.1.4 自定义拓展词库
只需要修改 ik 分词器的配置文件 /usr/share/elasticsearch/plugins/ik/config 目录下的 IKAnalyzer.cfg.xml 文件即可,在配置文件中,指定一个远程的词库,让 ik 分词器向远程词库发送请求,获取新的词汇。解决方案:
- 创建一个项目,让 ik 分词器向该项目发起请求,获取新的词汇
- 安装
Nginx,并将词库放于Nginx中,让 ik 分词器向Nginx发送请求,获取新的词汇
这里介绍第二种解决方案:
Docker安装
Nginx:
随便启动一个
Nginx实例,只是为了复制出原有的配置。docker run -p 80:80 --name nginx -d nginx:1.10将容器内的配置文件拷贝到当前目录(注意结尾有个 点)
docker container cp nginx:/etc/nginx .修改文件夹的名称为
conf,并移动到/mydata/nginx下mv nginx conf mkdir /mydata/nginx mv conf nginx/停止并删除原有
Nginx容器docker stop nginx docker rm nginx创建新的
Nginx容器docker run -p 80:80 --name nginx \ -v /mydata/nginx/html:/usr/share/nginx/html \ -v /mydata/nginx/logs:/var/log/nginx \ -v /mydata/nginx/conf:/etc/nginx \ -d nginx访问
http:// ip:80即可访问到nginx的欢迎页面此时,在
nginx的html目录下面存放的所有资源都是可以直接访问的
在 Nginx 的 html 目录下,新建一个 es 目录,并创建 fenci.txt 文件
# 在 /mydata/nginx 下
cd /html
mkdir es
cd es
vi fenci.txt
在fenci.txt文件里面写入新的词汇,一行一个,如:乔碧萝,欧力给,保存后,即可通过链接 http:// ip:80/es/fenci.txt进行访问。词库创建好后,需要配置 ik 分词器的配置文件
cd /mydata/elasticsearch/plugins/ik/config
vi IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://ip:80/es/fenci.txt</entry> # 在这里填入刚刚的分词地址
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
保存之后,重启 es 即可
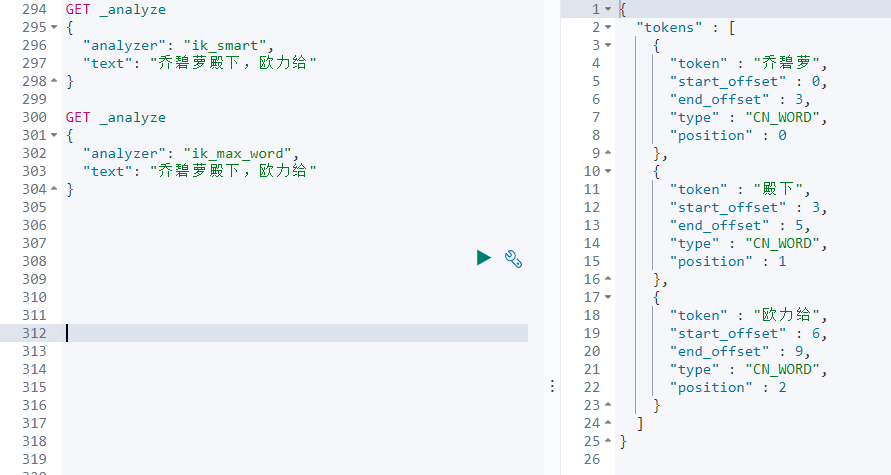
GET _analyze
{
"analyzer": "ik_smart",
"text": "乔碧萝殿下,欧力给"
}
GET _analyze
{
"analyzer": "ik_max_word",
"text": "乔碧萝殿下,欧力给"
}
六、Spring Boot 整合 Elasticsearch —— Elasticsearch-Rest-Client
虽然说,前端也可以直接调用 es 的接口,不过,一般不会这么做,正常来说,都会由前端请求后端的一个接口,再让 java 去请求 es,获取数据,那么,java 操作 es 有两种方法:
- 请求 9300 端口 , TCP
spring-data-elasticsearch:transport-api.jarspringboot版本不同,transport-api.jar不同,不能适配 es 版本- 7.x 的版本已经不建议使用, 8 以后的版本就要废弃了
- 请求 9200 端口,HTTP
JestClient: 非官方,更新慢RestTemplate:模拟发送HTTP请求,ES很多操作需要自己封装,麻烦HttpClient:模拟发送HTTP请求,ES很多操作需要自己封装,麻烦- Elasticsearch-Rest-Client : 官方
RestClient, 封装了 ES 操作, API 层次分明,上手简单
所以,一般情况下,会选择使用 Elasticsearch-Rest-Client 来进行整合。Elasticsearch-Rest-Client 又分为两个版本,Java Low Level REST Client 和 Java High Level REST Client ,后者是对前者的进一步封装,就犹如 jdbc 和 Mybatis 的关系一样,所以这里选择 elasticsearch-rest-high-level-client 高阶版本 高阶官方文档
6.1 导入maven 依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.8.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<properties>
<java.version>1.8</java.version>
# 由于spring boot 也管理了 elasticsearch ,那么就会导致下面导入的elasticsearch与 api 版本不一致,所以需要在这里接管 elasticsearch 版本号
<elasticsearch.version>7.4.2</elasticsearch.version>
</properties>
<dependencies>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.4.2</version>
</dependency>
</dependencies>
</project>
6.2 配置 Elasticsearch
package com.search.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 给容器中注入一个 RestHighLevelClient
* @description: elasticsearch 配置类
*/
@Configuration
public class ElasticsearchConfig {
/**
* 请求设置项,配置统一的请求设置,详细配置参考官方文档
* https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.5/java-rest-high-getting-started-request-options.html
*/
public static final RequestOptions COMMON_OPTIONS;
static {
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
//builder.addHeader("Authorization", "Bearer " + TOKEN);
//builder.setHttpAsyncResponseConsumerFactory(
// new HttpAsyncResponseConsumerFactory
// .HeapBufferedResponseConsumerFactory(30 * 1024 * 1024 * 1024));
COMMON_OPTIONS = builder.build();
}
/**
* 参加官方文档
* https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.5/java-rest-high-getting-started-initialization.html
*/
@Bean
public RestHighLevelClient esRestClient() {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("192.168.10.3", 9200, "http"))); // 集群的情况下,只需要在这里写入多个HttpHost即可,对应上IP,端口号,协议名
return client;
}
}
6.3 测试
package com.search;
import com.alibaba.fastjson.JSON;
import com.search.config.ElasticsearchConfig;
import lombok.Data;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.io.IOException;
@RunWith(SpringRunner.class)
@SpringBootTest
public class GulimallSearchApplicationTests {
@Autowired
private RestHighLevelClient client;
@Test
public void contextLoads() {
System.out.println(client);
}
/**
* 测试加载数据到es
*/
@Test
public void indexData() throws IOException {
IndexRequest indexRequest = new IndexRequest("users");
indexRequest.id("1");
User user = new User();
user.setUserName("张三");
user.setAge(1);
user.setGender("女");
String s = JSON.toJSONString(user);
indexRequest.source(s, XContentType.JSON);
// 执行操作
IndexResponse index = client.index(indexRequest, ElasticsearchConfig.COMMON_OPTIONS);
// 提取有用的响应数据
System.out.println(index);
}
/**
* 测试复杂检索
*/
@Test
public void searchData() throws Exception {
// 检索请求
SearchRequest searchRequest = new SearchRequest();
// 指定索引
searchRequest.indices("bank");
// 指定SDL,检索条件 SearchSourceBuilder
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("address", "mill"));
searchSourceBuilder.from(0);
searchSourceBuilder.size(20);
searchSourceBuilder.aggregation(AggregationBuilders.terms("ageAgg").field("age").size(10));
System.out.println(searchSourceBuilder.toString());
searchRequest.source(searchSourceBuilder);
//执行检索
SearchResponse search = client.search(searchRequest, ElasticsearchConfig.COMMON_OPTIONS);
// 分析结果
System.out.println(search.toString());
}
@Data
class User{
private String userName;
private String gender;
private Integer age;
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号