Linux命令
Linux命令
任何shell都会执行 exec 和 fork
而 ls会执行read
linux中/etc/profile 针对全局设置环境变量
而~/profile针对用户
1. 根据进程pid查端口:
lsof -i | grep pid
2. 根据端口port查进程(某次面试还考过):
lsof -i:port
3. 根据进程pid查端口:
netstat -nap | grep pid
4. 根据端口port查进程
netstat -nap | grep port
linux设置命令行快捷键
mac中我用ln -s 链接到usr/local/bin即可
linux中可以用打开~/.bashrc 然后通过alias别名 后面跟命令 例如:
alias zk='/usr/local/zookeeper/zookeeper-3.4/bin/zkServer.sh'
设置成功后通过 zk start启动zookeeper
linux高级
1.查看系统整机性能:top命令
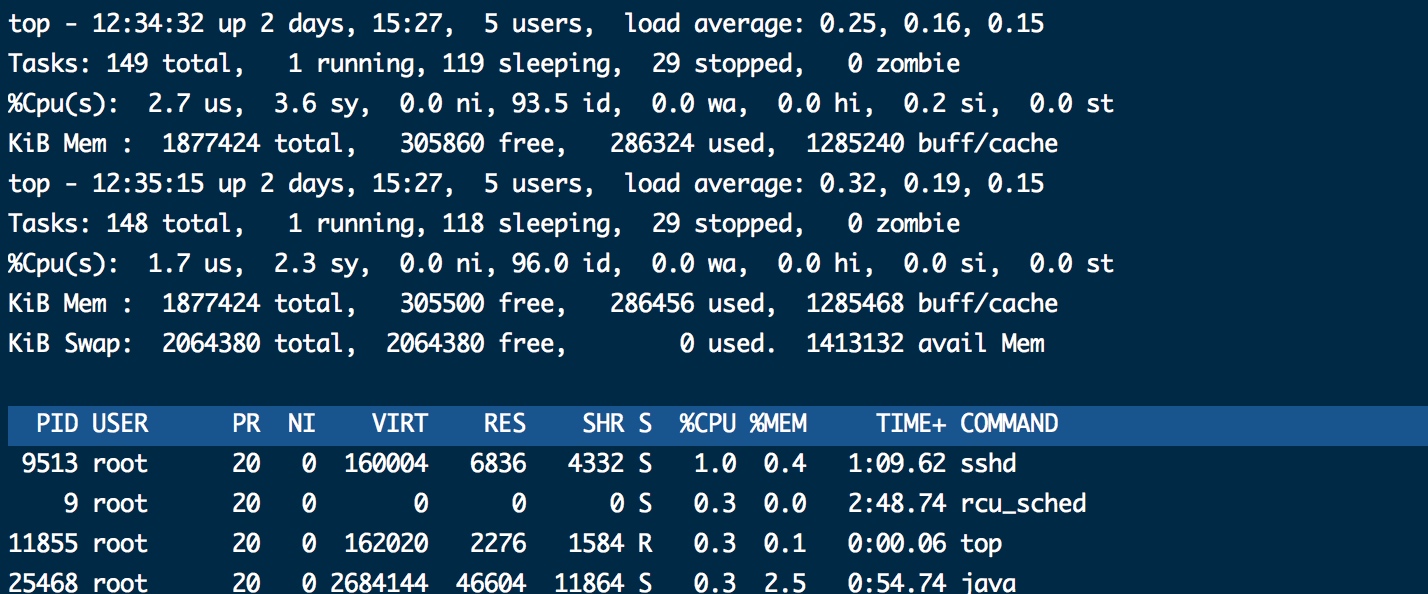
cpu %cpu(s)看几核处理器 有个参数id=idle cpu空闲率 越高越好
mem
load average x1,x2,x3 分别代表1分钟,5分钟,15分钟系统平均负载 三个值树的平均值>0.6 说明负载率高
uptime 乞丐版top 可以看load average
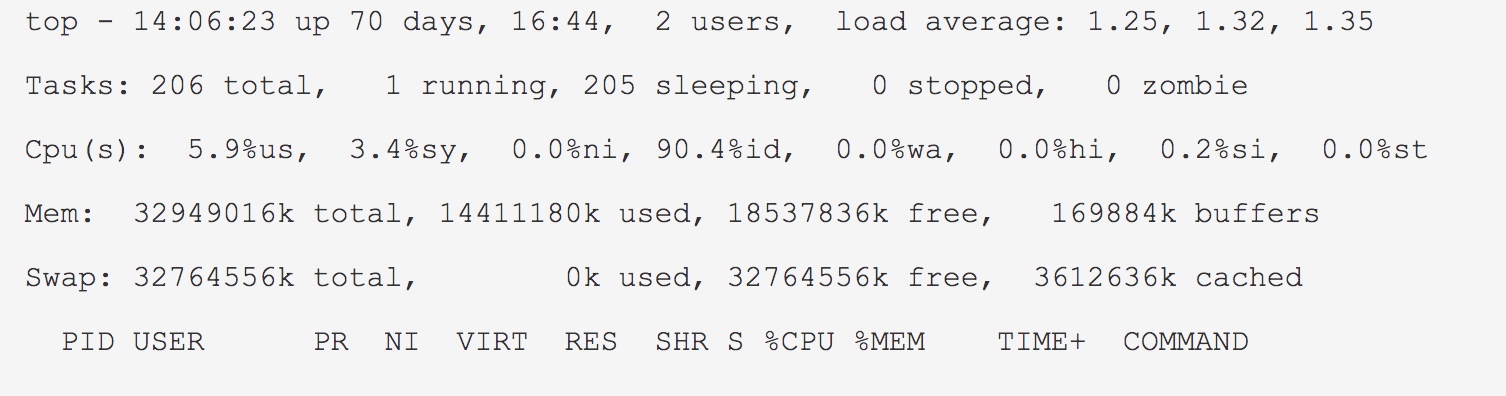
参数解释:
第一行,任务队列信息,同 uptime 命令的执行结果,具体参数说明情况如下:
14:06:23 — 当前系统时间
up 70 days, 16:44 — 系统已经运行了70天16小时44分钟(在这期间系统没有重启过的吆!)
2 users — 当前有2个用户登录系统
load average: 1.15, 1.42, 1.44 — load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。
load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。
第二行,Tasks — 任务(进程),具体信息说明如下:
系统现在共有206个进程,其中处于运行中的有1个,205个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸)的有0个。
第三行,cpu状态信息,具体属性说明如下:
5.9%us — 用户空间占用CPU的百分比。
3.4% sy — 内核空间占用CPU的百分比。
0.0% ni — 改变过优先级的进程占用CPU的百分比
90.4% id — 空闲CPU百分比
0.0% wa — IO等待占用CPU的百分比
0.0% hi — 硬中断(Hardware IRQ)占用CPU的百分比
0.2% si — 软中断(Software Interrupts)占用CPU的百分比
备注:在这里CPU的使用比率和windows概念不同,需要理解linux系统用户空间和内核空间的相关知识!
第四行,内存状态,具体信息如下:
32949016k total — 物理内存总量(32GB)
14411180k used — 使用中的内存总量(14GB)
18537836k free — 空闲内存总量(18GB)
169884k buffers — 缓存的内存量 (169M)
第五行,swap交换分区信息,具体信息说明如下:
32764556k total — 交换区总量(32GB)
0k used — 使用的交换区总量(0K)
32764556k free — 空闲交换区总量(32GB)
3612636k cached — 缓冲的交换区总量(3.6GB)
备注:
第四行中使用中的内存总量(used)指的是现在系统内核控制的内存数,空闲内存总量(free)是内核还未纳入其管控范围的数量。纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存交还到free中去,因此在linux上free内存会越来越少,但不用为此担心。
如果出于习惯去计算可用内存数,这里有个近似的计算公式:第四行的free + 第四行的buffers + 第五行的cached,按这个公式此台服务器的可用内存:18537836k +169884k +3612636k = 22GB左右。
对于内存监控,在top里我们要时刻监控第五行swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。
第六行,空行。
第七行以下:各进程(任务)的状态监控,项目列信息说明如下:
PID — 进程id
USER — 进程所有者
PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)
常用命令:
1.按键盘数字“1”,可监控每个逻辑CPU的状况
2.按b 高亮运行进程
按i 忽略闲置、僵尸进程,只查看运行进程
按m 切换显示内存信息
3.默认排序按 CPU%
按x高亮排序列
按P 根据CPU使用百分比大小进行排序
按shift+">" 切换排序列
4.top -c 显示完整command
5.top -p +pid 查看指定进程
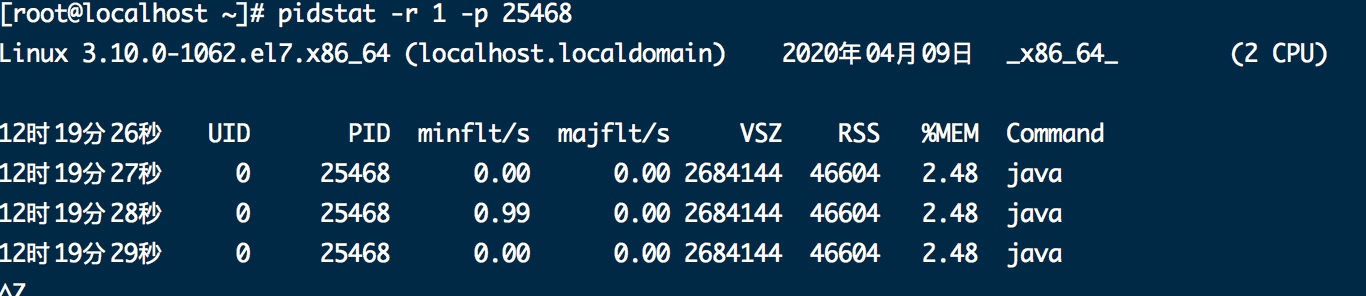
2.free 看内存
可用内存应该在20%-70%之间
free -m 看内存

pidstat -p +pid -r +采样间隔时间
3.df 看硬盘空间
-h 看硬盘还剩多少
4.磁盘io
看磁盘io:
1.用pidstat -d 采样间隔时间 -p +pid

2.iostat -xdk 采样间隔时间 采样数
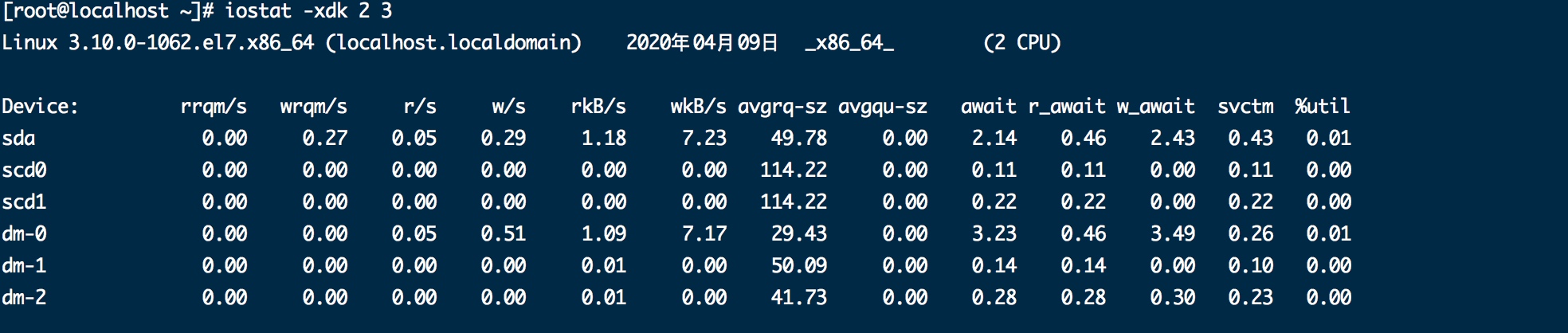
看w/s 每秒写 r/s 每秒读 %util 这些大 代表io次数高 多半是因为sql 需要sql调优
%util代表一秒钟里百分之几的时间用于io操作,接近100%,表示磁盘带宽跑满,需要优化
5.网络io
ifstat 采样间隔时间
6.vmstat 看cpu
vmstat -n x1 x2 x1每几秒刷新一次 取x2条记录
看procs列 r代表运行进程数 b代表阻塞的
看cpu列 us sy id us+sy>80%说明系统慢
附加:
1.mpstat -P ALL 2 每2s打印一下所有cpu信息
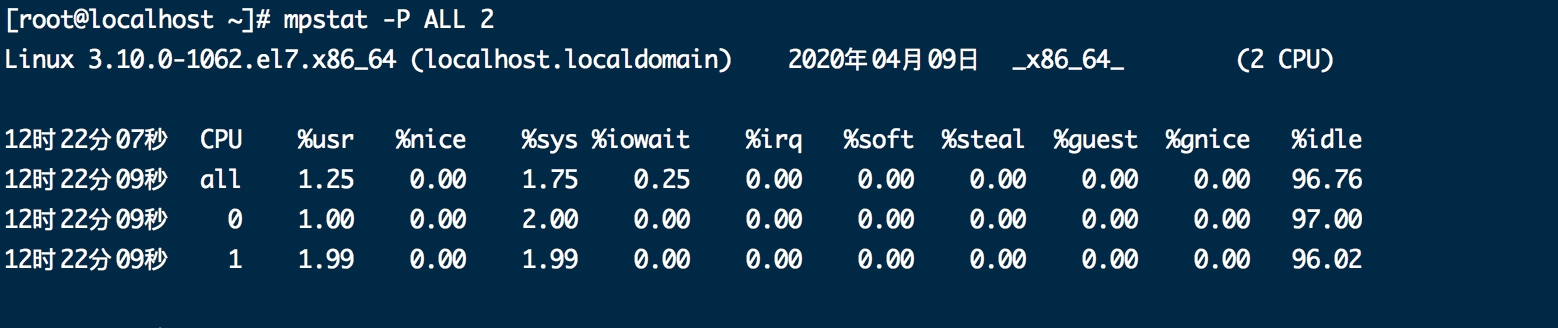
2.pidstat -u 1 -p +pid 隔1s打印该进程cpu占比

生产环境中,cpu占用过高排查

1.先用top找出占用cpu过高的进程pid
2.ps -ef或者jps进一步定位,得知是一个怎样的后台程序

3.定位到具体线程或代码
ps -mp 25468 -o THREAD,tid,time
参数解释:
-m 显示所有的线程
-p pid进程使用cpu的时间
-o 该参数是用户自定义格式
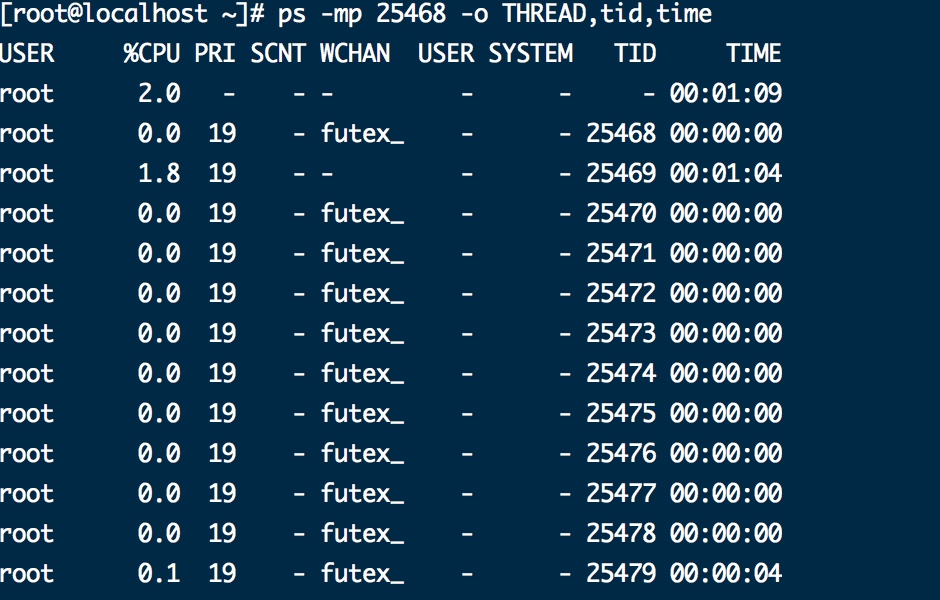
找不那个都是- 不正常的线程,上图即为Tid 25469
4.将Tid转换为16进制格式(英文小写)
上述25469 为637d
5.jstack pid |grep Tid -A60 打印前60行
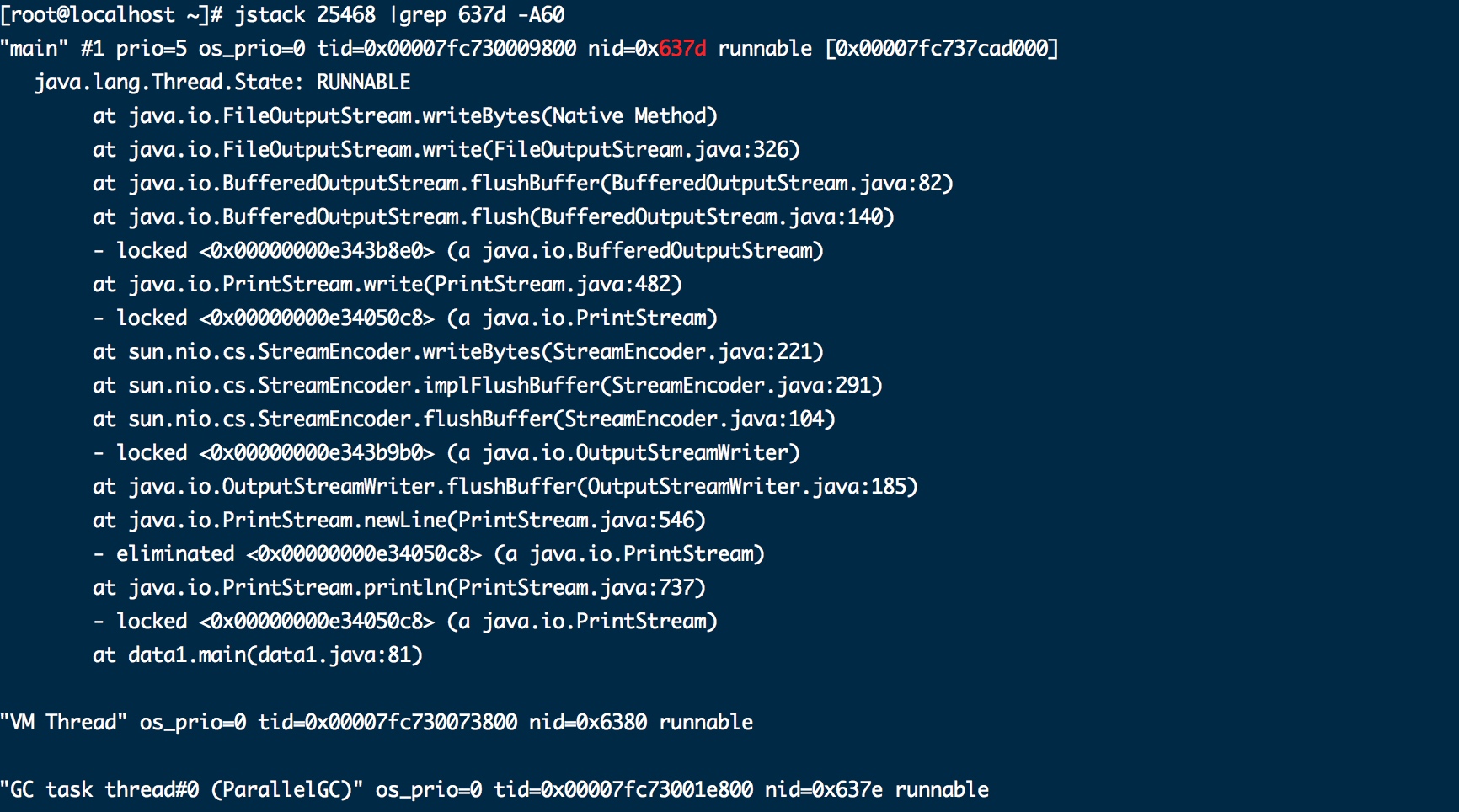
看报错信息,可以确定是第81行报错
netstat命令各个参数说明如下:
-t : 指明显示TCP端口
-u : 指明显示UDP端口
-l : 仅显示监听套接字(所谓套接字就是使应用程序能够读写与收发通讯协议(protocol)与资料的程序)
-p : 显示进程标识符和程序名称,每一个套接字/端口都属于一个程序。
-n : 不进行DNS轮询,显示IP(可以加速操作)
即可显示当前服务器上所有端口及进程服务,于grep结合可查看某个具体端口及服务情况··
netstat -ntlp //查看当前所有tcp端口·
netstat -ntulp |grep 80 //查看所有80端口使用情况·
netstat -an | grep 3306 //查看所有3306端口使用情况·
查看一台服务器上面哪些服务及端口
netstat -lanp
查看一个服务有几个端口。比如要查看mysqld
ps -ef |grep mysqld
查看某一端口的连接数量,比如3306端口
netstat -pnt |grep :3306 |wc
查看某一端口的连接客户端IP 比如3306端口
netstat -anp |grep 3306
netstat -an 查看网络端口
lsof -i :port,使用lsof -i :port就能看见所指定端口运行的程序,同时还有当前连接。
nmap 端口扫描
netstat -nupl (UDP类型的端口)
netstat -ntpl (TCP类型的端口)
netstat -anp 显示系统端口使用情况
SHEll:
执行脚本的命令:
1.bash helloworld.sh
2.sh helloworld.sh
1. ./helloworld.sh
变量:
$HOME
$PWD
$SHELL
$User
自定义:
$ A=1 =两边没有空格
$ unset A 取消变量A
$ readonly B=3 声明静态变量 不能unset
规则:数字、字母、下划线 不能数字开头 环境变量建议大写
$ C=1+1 默认字符串所以echo查看结果 1+1
太长可以加引号
全局变量: export $C 这样就成了全局变量
特殊变量:
$0代表脚本名称
$1-$9代表后面跟的相应参数
$# 参数个数 不包括脚本名
$* 获取所有参数 当成一个整体
$@ 获取所有参数 区别对待
例:
vim parameter.sh 输入
#!/bin/bash
echo $0 $1 $2
bash parametre.sh mm xx //结果为parameter.sh mm xx
$? 判断上次命令是否成功执行 0成功 非0失败
基本运算:
运算符两端必须有空格
加 +
减 -
乘 \*
除 /
例:expr `expr 2+3` \*4 //20
or $ s=$[(2+3)*4] //20
判断:
1.两个整数间比较
=字符串比较
-lt 小于 -le小于等于
-eq 等于 -ne 不等于
-gt 大于 -ge大于等于
2.判断文件权限
-r -w -x
3.文件判断
-f file
-d 目录
-e 存在否
例: $ [ 23 -ge 22 ]
echo $? //0 success
$ [ -w helloworld.sh]
echo $? //0 success
流程控制:
if语句:
if [ 表达式 ]
then
echo ”love“
elif[ 表达式 ]
then
echo ”you“
fi
case:
case $1 in
1)
echo "banzhang"
;;
2)
echo "test"
;;
*)
echo "renyao"
;;
esac
for:
第一种:
s=0
for ((i=1;i<=100;i++))
do
s=$[$s+$i]
done
echo $s
//5050
第二钟:
for i in $*
do
echo " $i "
done
while:
s=0
i=0
while [ $i -le 100]
do
s=$[$s+$i]
i=$[$i+1]
done
read://从控制台输入并赋值给变量
read -t 7 -p "enter name in 7 seconds" NAME
//七秒内输入并赋值给NAME
函数:
1.系统函数
basename 函数
basename ~/Lanvce/MM/base.txt
//结果base.txt
dirname 返回文件绝对路径 不包括文件名
2.自定义函数
#!/bin/bash
function sum()
{
s=0;
s=$[$1+$2]
echo $s
}
read -p "input your parameter1:" P1
read -p "input your parametre2:" P2
sum $P1 $P2
Shell工具:
1.cut
-f 列号 提取第几列
-d 分隔符 按照指定分隔符分割列
cut -d " " -f 1 cut.txt
//分隔符为空格 取第一列
cut cut.txt|grep aa|cut -d " " -f 1
//可以配合管道使用
cut $PATH|cut -d : -f 3-
//取系统变量第2个冒号后面的所有
2.sed
文件内容不改变
sed [参数] command filename
a 增加 d 删除
s 替换 g全局
-e直接在指令列模式上进行sed的动作编辑
//文件第二行后面加上meinv 只是在屏幕上显示出来 源文件不改变
sed ”2a mei nv“ sed.txt
//将包含wo的删除掉
sea "/wo/d" sed.txt
//将全局的wo替换成ni
sed "s/wo/ni/g" sed.txt
//删除第二行 将wo替换成ni
sed -e "2d" -e "s/wo/ni/g" sed.txt
3.awk 文本分析工具
-F 指定分隔符
-v 赋值一个同用户定义变量
内置变量
FILENAME 文件名称
NR 已读文件数
NF 浏览记录的域的个数(切割后列的个数)
//1.搜索password文件以root关键字开头的所有行 并输出第7列
awk -F : '/^root/{print $7}' password
//2.搜索password文件root开头的所有行 输出该行的第1,7列 中间以,分隔
awk -F : '/^root/{print $1","$7}' password
//3.只显示/etc/passwd 的第一列和第七列,逗号分割 且在所有行前面添加列名user, shell在最后一行添加”xxx“
awk -F : 'BEGIN{print "user,shell"} {print $1","$7}' END {print "xxx"}
//4.将passwd文件中的用户id增加数值1并输出
awk -v i=1 -F : '{print $3+i}' passwd
4.sort
-n 数值大小排序
-r 相反顺序
-t 是指排序分隔符
-k 指定需要排序的列
//按:分割后第三列按倒叙排
sort -t : -krn 3 sort.sh
真题:
1.使用linux命令查看file1中空行所在的行号
awk '/^$/{print NR} sed.txt
2.有文件cheng.txt 内容如下:
张三 40
李四 50
王五 50
top查看CPU占用
netst查看网络
free看内存
df是查看磁盘空间
type 判断类型 type ifconfig
file 查看文件 file/sbin/ifconfig
echo 类似print echo $$ 查看当前shell的pid
echo $LANG 语言选择
$变量 abc=“qwe” echo \$ abc 输出qwe
c=(1 2 3) echo ${c[1]} 输出1
help 内部命令帮助手册
man 外部命令帮助手册 manual
1 使用者在shell中可以操作的指令或可执行档
2 系統核心可呼叫的函数与工具等
3 一些常用的函数(function)与函数库(library),大部分是C的函数库(libc)
4 装置档案的说明,通常在/dev下的档案
5 设定档或者是某些档案的格式
6 游戏(games)
7 惯例与协定等,例如Linux档案系统、网络协定、ASCII code等等的說明
8 系統管理員可用的管理指令
9 跟kernel有关的文件
ps -ef 查看进程
fd文件描述符:0 标准输入
1 标准输出
2 错误输出
df -h 查看磁盘挂载情况
du -h 查看文件使用情况
ls -l 长列表查看 也可用 ll
ls -a 查看所有文件 包括隐藏文件
ls / /etc 可同时显示多个目录 按树形结构排序
文件类型:
d:目录
-:普通文件
b:block 块设备文件 可分割
c:chacter 字符设备文件 不可分割
l:link 符号链接文件
p:pipe 命令管道文件
s:socket 套接字文件
mkdir -p /x/y 创建多级目录
mkdir x/{aa,bb,cc} 在x目录下同时创建aa,bb,cc
cp -r 删除目录
mv 移动 重命名
ln 硬链接 可用ll -i查看序号 链接数量
ln -s 软链接 删除被指的文件后 链接会失效
stat 打印元数据 类似属性
touch 文件已存在会刷新文件的各种时间 不存在则会创建文件
cat 查看文件
more 分屏查看 按空格翻页 不可回看
less 可回看上下翻 会加载到内存中 按 b enter翻页
head/tail 默认前/后 10行内容 制定行数 head/tail -数字
tail -f sxt.log可用来监控文件末尾追加的文字并输出
| 管道 可把|前面的输出作为后面的输入 cat sxt.log|head -3
echo "/" |xargs ls -l xargs接收“/” 并且作为参数给ls命令
head -5 |tail -1 看第五行
vi打开文件
vi +3 profile 打开profile并定位到第三行
vi + profile 定位到最后一行
vi +/after 定位到after第一次出现的地方
关闭文件
w! 强制保存
wq或x 保存退出
zz 编辑模式下保存退出 不需要冒号
三种模式:
编辑模式->输入模式
a 光标的后面
i 光标的前面
o 光标的下面新建一行
O 光标的上面新建一行
I 光标行首
A 光标行尾
输入模式到编辑模式:esc
编辑模式到末行模式: :
末行模式到编辑模式:esc esc
编辑模式:
字符:
h j k l 上下左右
单词:
w 移动到下一个单词的词尾
e 下一个单词词首
b 前一个单词词首
行内:
0 移动到行首
$ 移动到行尾
^ 第一个非空字符
行间:
gg:文章开头
GG:文章末尾
3G:移动到第三行
翻页:
ctrl+f 向后翻
ctrl+b 向前翻
删除&替换字符:
x 删除单个字符
3x 删除光标开始的删除的3个字符
r 替换光标所在字符
dd:删除一行 剪切 5dd:删除5行
dw:删除一个单词 4dw:删除4个单词
dG:全删
复制:
yy:复制一行
yw:复制一个单词 3yw 复制三个单词
p:粘贴
u:撤销
ctrl+r 恢复
. 重复上一次的操作
末行模式:(shift+:)
设置权限:
set (no)readonly 设置不只读/只读
set nu 设置行号
查找:
/after 查找单词after定位到单词首部
n下一个 N上一个 ?向上查找
:/after 查找并定位到这个单词的行首部
!:不需要退出编辑器就能使用外部命令
! ls -l /usr/java
查找并替换:
/ @ # 边界字符 分割作用
g:一行内全部替换 ,否则只会替换行内第一个
i:忽略大小写
范围(要用,分割):
n 行号
. 当前光标行
+n 偏移n行
$ 末尾行
% 全文
%s/str1/str2/g 全文替换str1为str2
:s/old/new 将当前行中查找到的第一个字符“old” 串替换为“new”
:s/old/new/g 将当前行中查找到的所有字符串“old” 替换为“new”
:#,#s/old/new/g 在行号“#,#”范围内替换所有的字符串“old”为“new”
:%s/old/new/g 在整个文件范围内替换所有的字符串“old”为“new”
:s/old/new/c 在替换命令末尾加入c命令,将对每个替换动作提示用户进行确认
删除:
.,$d 删除当前光标到末尾
dG 全删
1,$-2d 删除第一行到倒数第二行
粘贴复制:
3,9y 复制3-9行
p:粘贴
grep -E 正则表达式 文本
\< 单词边界
grep .*\(god\).*\(good\).*\2.*\1 把god和good换位置了 类似 group
文本分析:
cut 显示切割的行数据 -d 后面跟分隔符
-f 展示文本中的第几列
-s 不展示没有分隔符的
cut -d “ ” -f1-3 a.txt 显示文本中空格分割的行的一到三列
sort 排序(默认是字典序)
-t 分隔符 sort -t‘ ’ -k2 a.txt 空格分割 按第二列排序
-n 数值序
-r 逆序
wc(wordcounter) -l显示行数,-w单词数,-c字节数
sed 行编辑器
-n 静默输出 不显示源文件 只显示要求的行
-i 直接修改源文件
-d删除 sed “3d“ 删除文件中的第三行 不会修改源文件 加-i才会
-p显示符合要求的行 sed “2p” 源文件中显示第二行
-a 在指定行的下一行追加 sed -a “2a/sxt“ 在第二行的下面追加sxt
-i 在指定行的上一行加 和-a相反
s/// 查找并替换 sed “s/sxt/hello/ hello替换为sxt
sed “/sxt/d/“ 删除sxt
awk 文本分析工具
awk -F ':' '{print $1}' password.txt 输出:分割后的文件第一列
awk -F ':' BEGIN{print "sxt\name"}'{print $1 "\t" $7}'END(print "sxt\name") password.txt 打印第1,7行 首位添加sxt,name两列
awk '/root print{$0}' password.txt 打印root这一整行
awk -F ':' '{print NR "\t" NF "\t" $0}' 打印行号 每行列数 整行
三种安装软件方式:
1.编译安装
./configure
make
make install
2.rpm安装
rpm -ivh filename 安装
rpm -qa 查询已经安装的包
rpm -qf /sbin/ifconfig 查询这个工具对应的包名
3.yum安装
yum repolist 包数量
/etc/yum.repos.d/里面存在镜像库
/mnt/repodata中为依赖关系 yum clean all 清除本地存在依赖关系 然后执行yum makecache下载依赖关系
也可从本地仓库下载 前提是有仓库 用file:// ftp://
中文显示:
yum grouplist
yum groupinstall “Chinese Support“
echo $LANG
LANG=zh_CN.UTF-8
增加epel的repo
打开阿里镜像站 查看帮助 然后weget
yum clean all
yum makecache
yum search man-pages
yum install man-pages-zh-CN
CentOS Linux添加普通用户和赋予root权限
Linux的普通用户在安装一些东西或者执行一些命令的时候,终端会提示权限不够。
1、添加用户,首先用adduser命令添加一个普通用户,命令如下:
#adduser tommy //添加一个名为tommy的用户
#passwd tommy //修改密码
Changing password for user tommy.
New UNIX password: //在这里输入新密码
Retype new UNIX password: //再次输入新密码
passwd: all authentication tokens updated successfully.
2、赋予root权限
方法一: 修改 /etc/sudoers 文件,找到%wheel一行,把前面的注释(#)去掉
## Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL
然后修改用户,使其属于root组(wheel),命令如下:
#usermod -g root tommy
修改完毕,现在可以用tommy帐号登录,然后用命令 sudo su - ,即可获得root权限进行操作。
方法二: 修改 /etc/sudoers 文件,找到root一行,在root下面添加一行,如下所示:
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
tommy ALL=(ALL) ALL
修改完毕,现在可以用tommy帐号登录,然后用命令 sudo su - ,即可获得root权限进行操作。
方法三: 修改 /etc/passwd 文件,找到如下行,把用户ID修改为 0 ,如下所示:
tommy:x:500:500:tommy:/home/tommy:/bin/bash
修改后如下
tommy:x:0:500:tommy:/home/tommy:/bin/bash
保存,用tommy账户登录后,直接获取的就是root帐号的权限。
建议使用方法二,不要轻易使用方法三。
脚本本质:
#!/bin/bash 启动子bash
bash是启动一个新bash
读取方式:
当前shell:source 或者. 执行
新建shell:1.bash sh01.sh 是子bash中执行
2.或者把文件前面加#!/bin/bash(不写的话默认也会开启一 个子bash) 然后chmod +x变成可执行文件 然后./执行 , 也是在子bash中执行
重定向:不是命令
程序都有I/O
0:标准输入
1:标准输出
2:错误输出
覆盖重定向:ls /usr 1>aaa.txt
追加重定向:ls /usr 1>>aaa.txt
输出错误重定向:
ls / /aabb 1>bbb 2>&1 没有aabb目录 bbb中先是错误输出,然后是标准输出
ls / /aabb >& bbb 特殊写法 和上面等价
ls / /aabb &> bbb 同上
输入重定向:
1.read aaa<<<"hello sxt" 字符串输入到文本中
2.read aaa<<AABB
>fsfs
>fasfw
>okss
>AABB
会显示第一个换行符之前的东西 即aaa中会是fsfs
3.cat 0</etc/inittab 会输出这个文件内容
文件描述符访问网站:
cd/proc/$$/fd
exec 8<> /dev/tcp/www.baidu.com/80 创建socket连接
echo -e "GET / HTTP/1.0\n" 1>&8 将请求头传会文件描述符传 给8
cat 0<&8 将8的响应信息打印出来
函数:
sxt(){
local ccc="jnj" // 局部变量
echo &ccc
}
sxt(){
echo $1
echo $2
}
sxt a b 会打印出a,b
位置变量:
在sh03文件中写入
echo $1
echo $2
然后执行source sh03 a b 就会打印出a b
$# 位置参数
$* 参数列表,双引号引用为一个字符串
$@ 参数列表,双引号为单独的字符串
$$ 当前shell的pid :接受者
$BASHPID :真是pid
$? 上一个命令的执行状态
在管道中会继承子bash的值,但是在文件中不会,必须要使用export导出才行
a=2;
a=22|echo $a; //结果a=2,a=22执行后bash消失
在文件中写入:echo $c
然后bash中c=111;
变为可执行文件 然后export c再执行文件就会打印出111
vi /etc/sysconfig/network-scripts/ifcfg-eth0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号