Scrapy——Spider Middleware
爬虫中间件(Spider Middleware)
爬虫中间件的用法与下载器中间件非常相似,只是它们的作用对象不同。下载器中间件的作用对象是请求request和返回response;爬虫中间件的作用对象是爬虫,更具体地来说,就是写在spiders文件夹下面的各个文件。它们的关系,在Scrapy的数据流图上可以很好地区分开来,如下图所示。
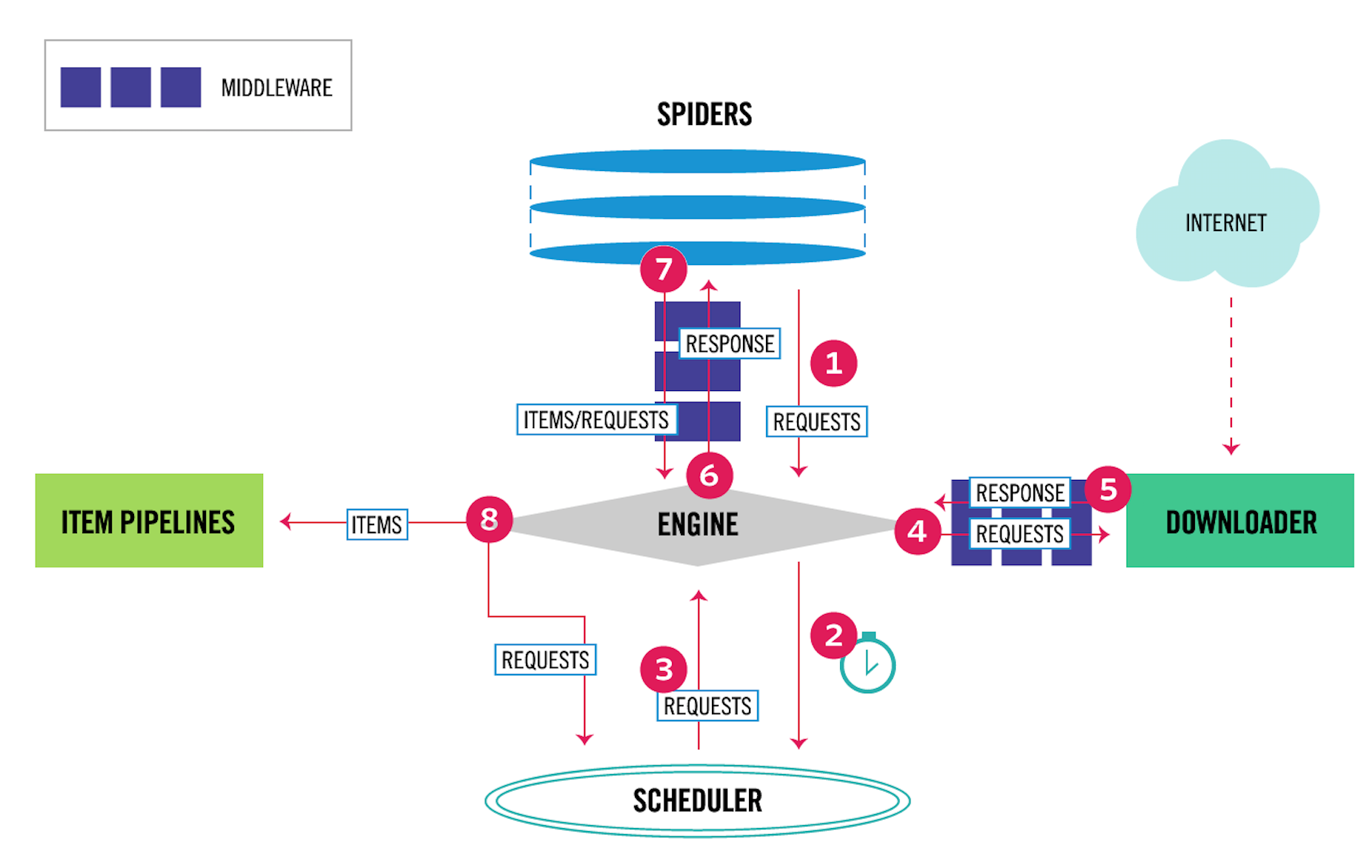
其中,4、5表示下载器中间件,6、7表示爬虫中间件。爬虫中间件会在以下几种情况被调用。
- 当运行到
yield scrapy.Request()或者yield item的时候,爬虫中间件的process_spider_output()方法被调用。 - 当爬虫本身的代码出现了
Exception的时候,爬虫中间件的process_spider_exception()方法被调用。 - 当爬虫里面的某一个回调函数
parse_xxx()被调用之前,爬虫中间件的process_spider_input()方法被调用。 - 当运行到
start_requests()的时候,爬虫中间件的process_start_requests()方法被调用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号