07 索引结构
顺序文件上的索引
在顺序文件上:
- 记录按查找键排序
密集索引
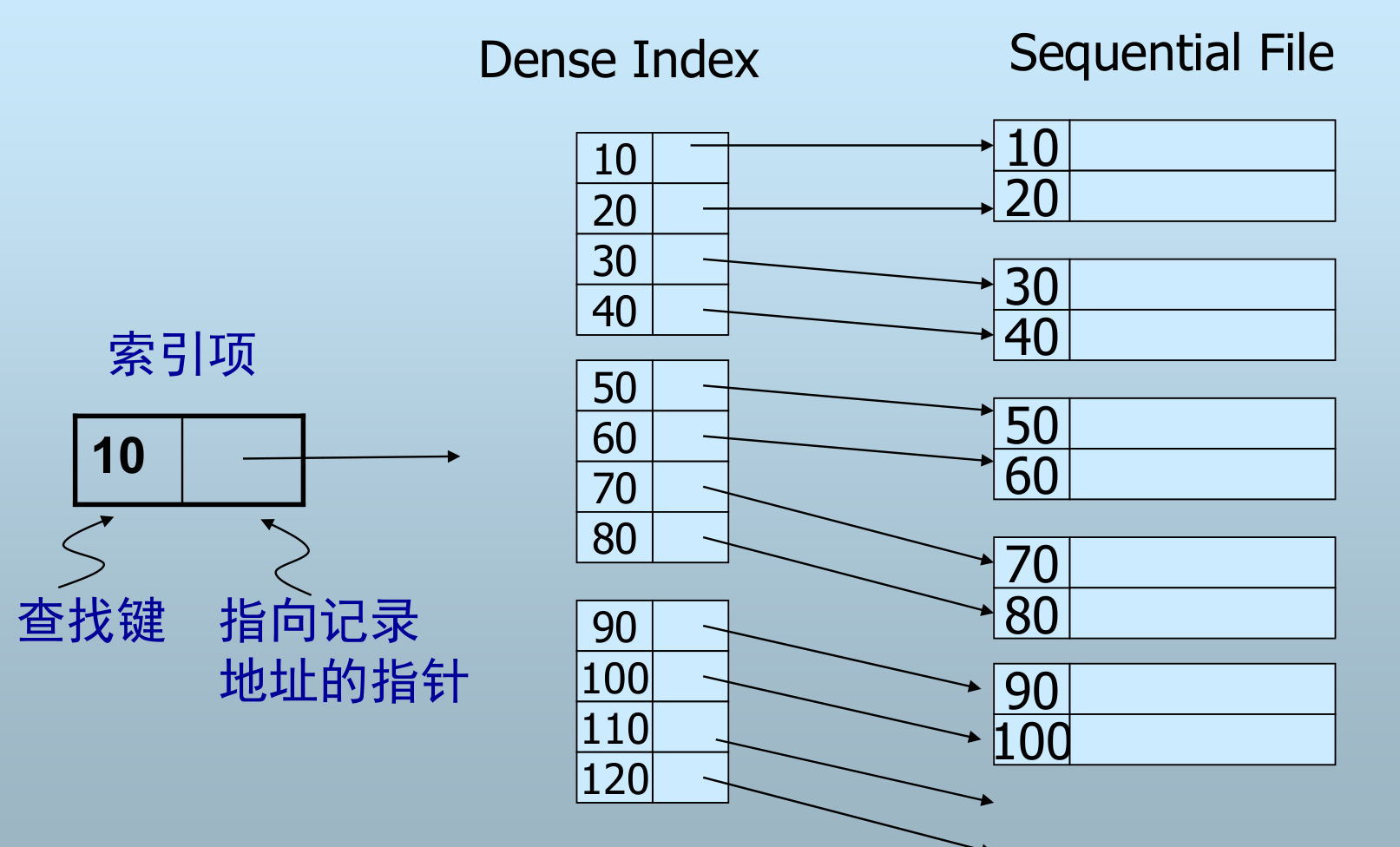
- 每个记录都有一个索引项
- 索引项按查找键排序
优点:
- 记录通常比索引项要大
- 索引可以常驻内存
- 要查找键值为 K 的记录是否存在,不需要访问磁盘数据块
缺点:
- 索引占用空间大
稀疏索引
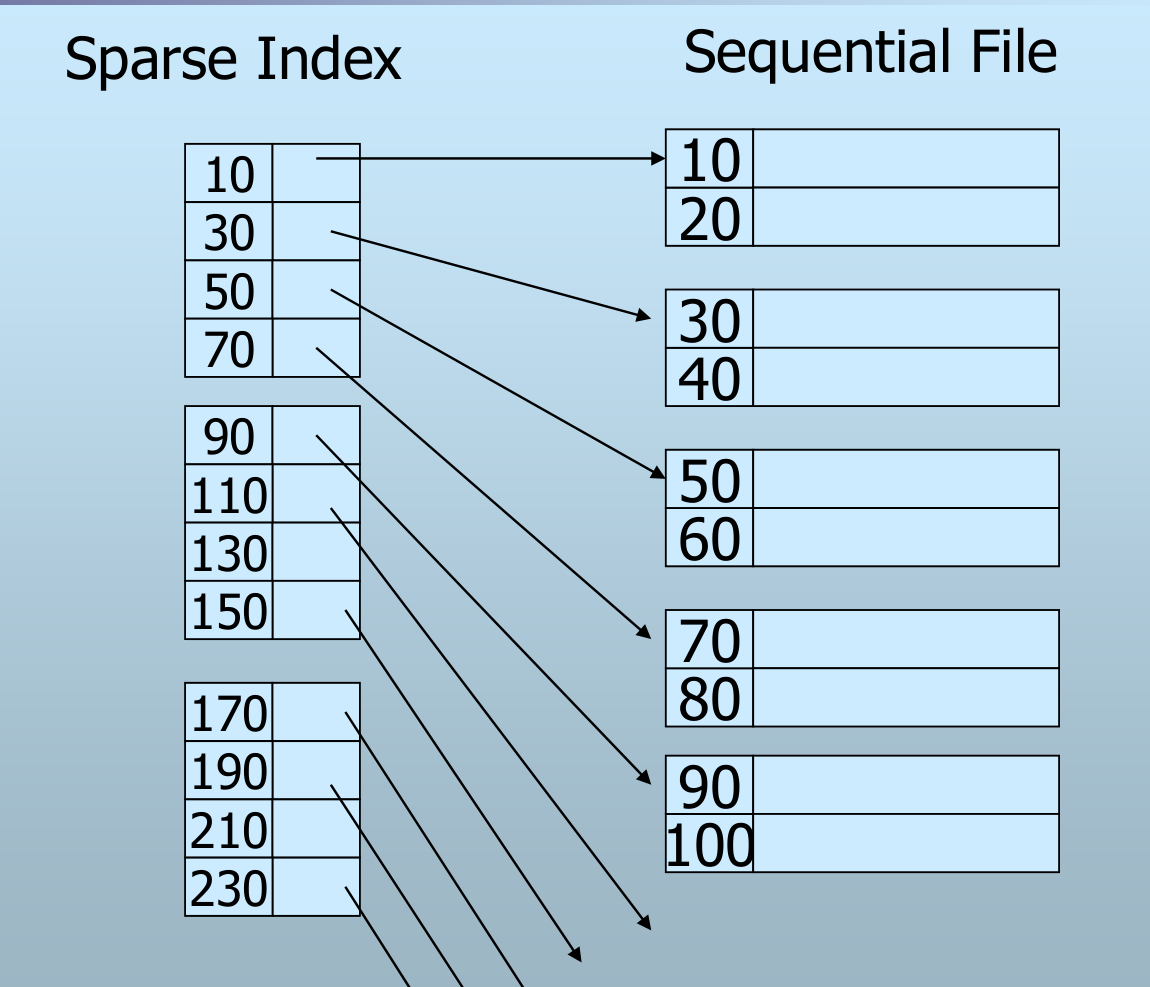
- 仅部分记录有索引项
- 一般情况:为每个数据块的第一个记录建立索引
优点:
- 节省了索引空间
- 对同样的记录,稀疏索引可以使用更少的索引项
缺点:
- 对于 “是否存在键值为 K 的记录?”,需要访问磁盘数据块
多级索引
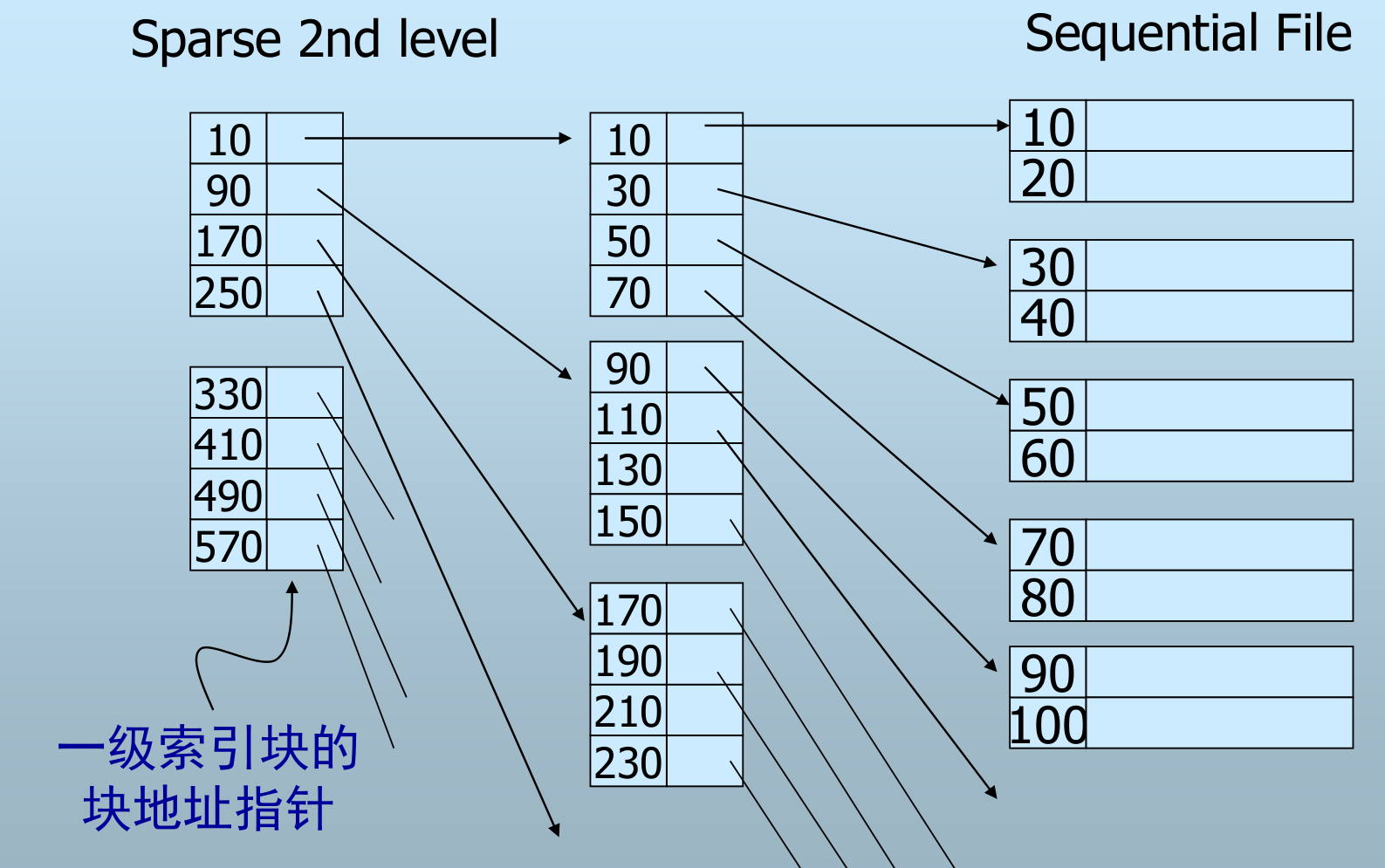
优点:
- 一级索引可能还太大而不能常驻内存
- 二级索引更小,可以常驻内存
- 减少磁盘 I/O 次数
- 二级索引仅可用稀疏索引
二级密集索引有用吗?
密集索引对于二级索引可以有所帮助,但它们不能提供太多优势。
- 密集索引可以降低索引项在磁盘中的碎片,使得索引项更容易被加载到内存中。
- 但是,它并不能提供太多的查询性能的改善,因为二级索引的查询操作不是非常频繁的,而且数据量也不会太大。
例:一块= 4KB。一级索引 10,000 个块,每个块可存 100 个索引项,共 40MB。二级稀疏索引 100 个块,共 400KB。
按一级索引查找 (二分查找):平均 lg10000≈13 次 I/O 定位索引块,加一次数据块 I/O,共约 14 次 I/O
按二级索引查找:定位二级索引块 0 次 I/O,读入一级索引块 1 次 I/O,读入数据块 1 次 I/O,共 2 次 I/O
一般不考虑三级以上索引
辅助索引
主索引 (Primary Index)
- 顺序文件上的索引
- 记录按索引属性值有序
- 根据索引值可以确定记录的位置
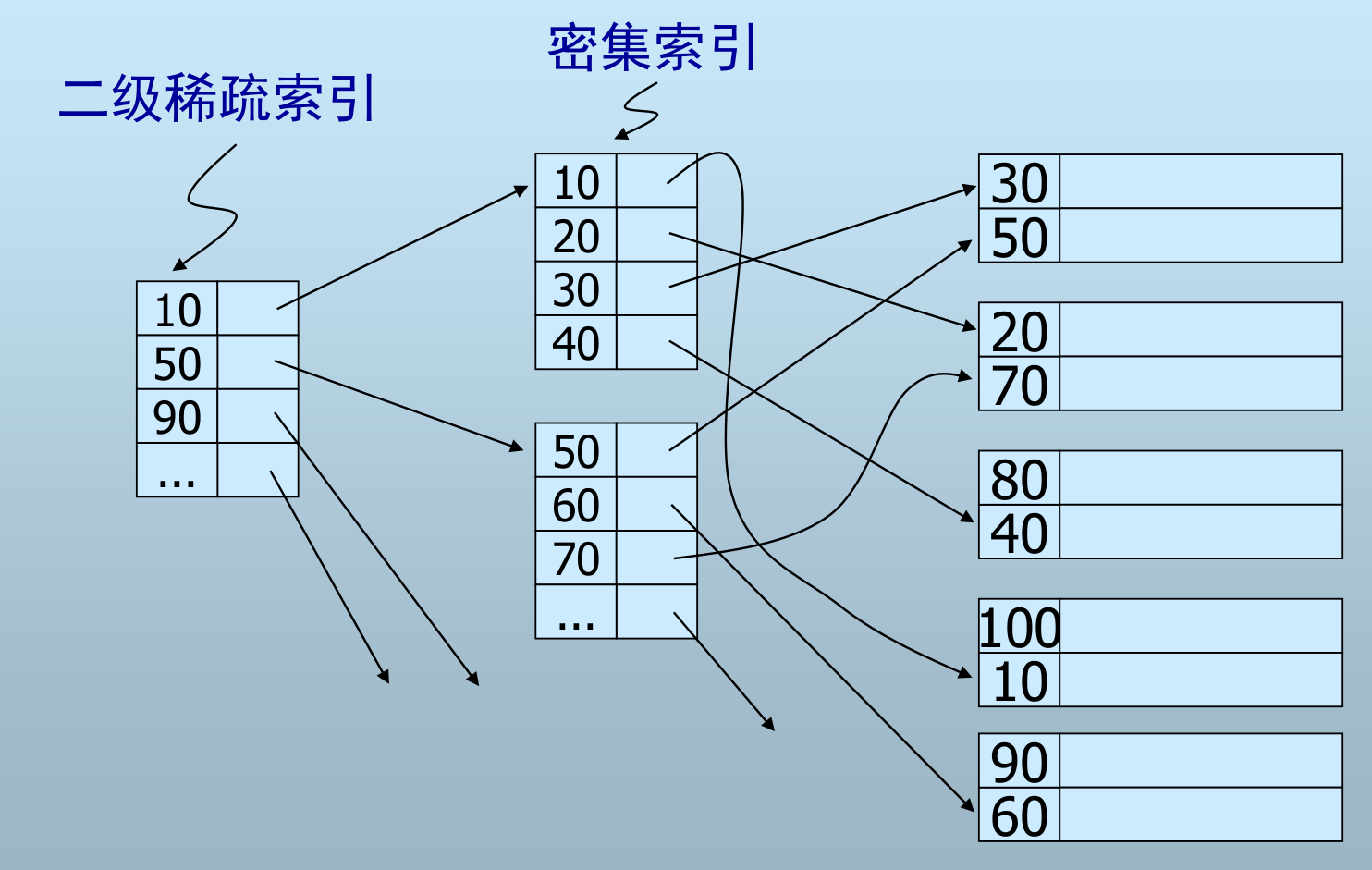
辅助索引(Secondary Index)
- 数据文件不需要按查找键有序
- 根据索引值不能确定记录在文件中的顺序
- 辅助索引只能是密集索引
- 稀疏的辅助索引没有意义
```sql
MovieStar(name char(10) PRIMARY KEY, address char(20))
Create Index adIndex On MovieStar(address)
```
- Name 上创建了主索引,记录按 name 有序
- Address 上创建辅助索引
间接桶
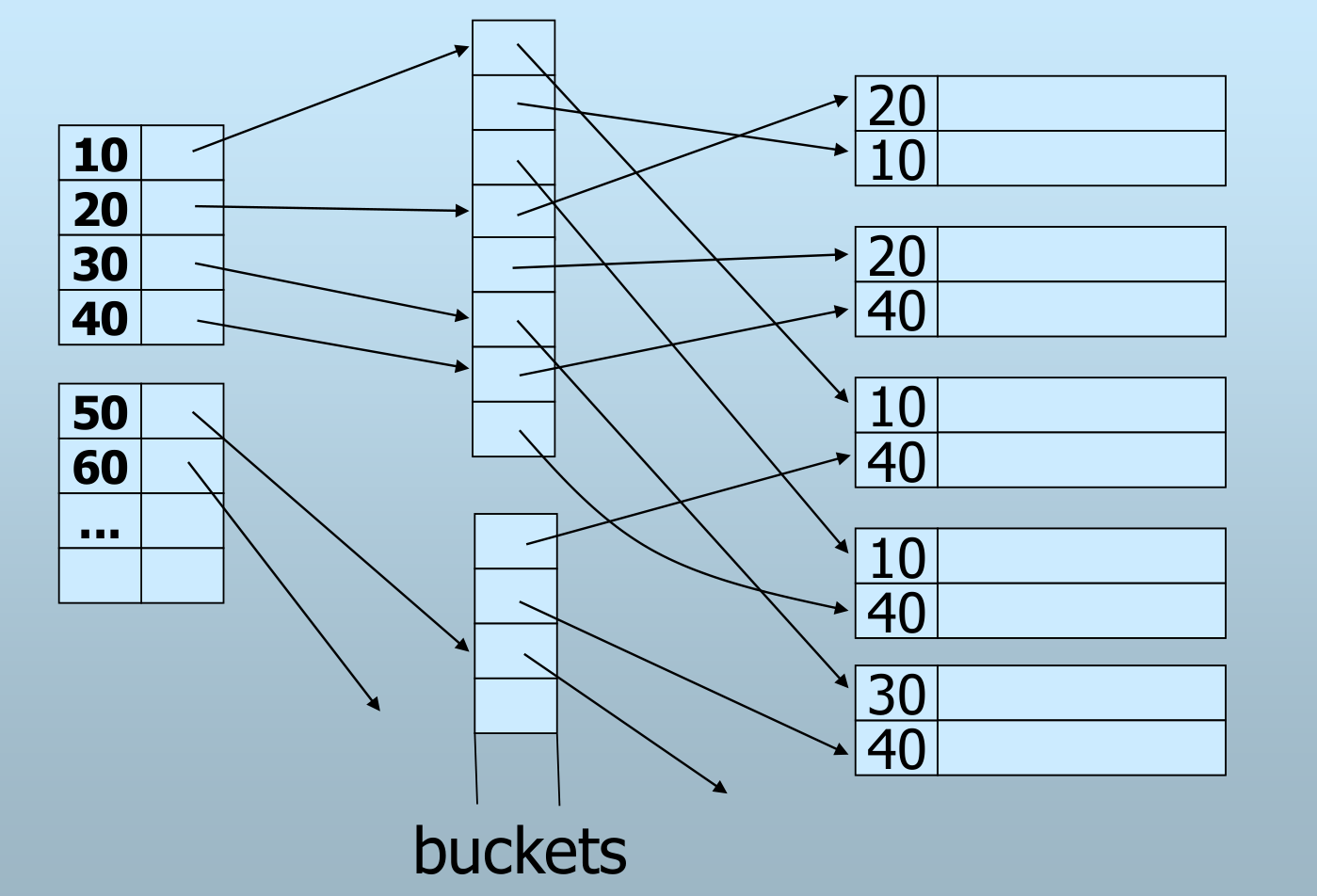
- 间接桶介于辅助索引和数据文件之间
- 可以用来处理辅助索引的重复键值问题
倒排索引
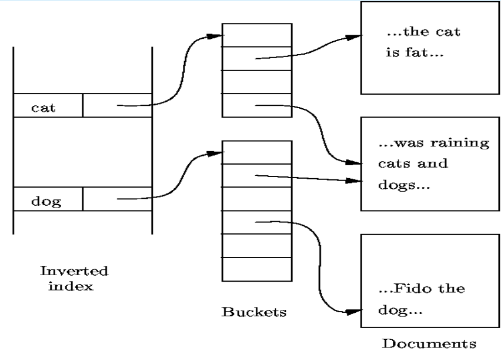
- 应用于文档检索,与辅助索引思想类似
- 不同之处
- 记录 -> 文档
- 记录查找 -> 文档检索
- 查找键 -> 文档中的词
- 思想
- 为每个检索词建立间接桶
- 桶的指针指向检索词所出现的文档
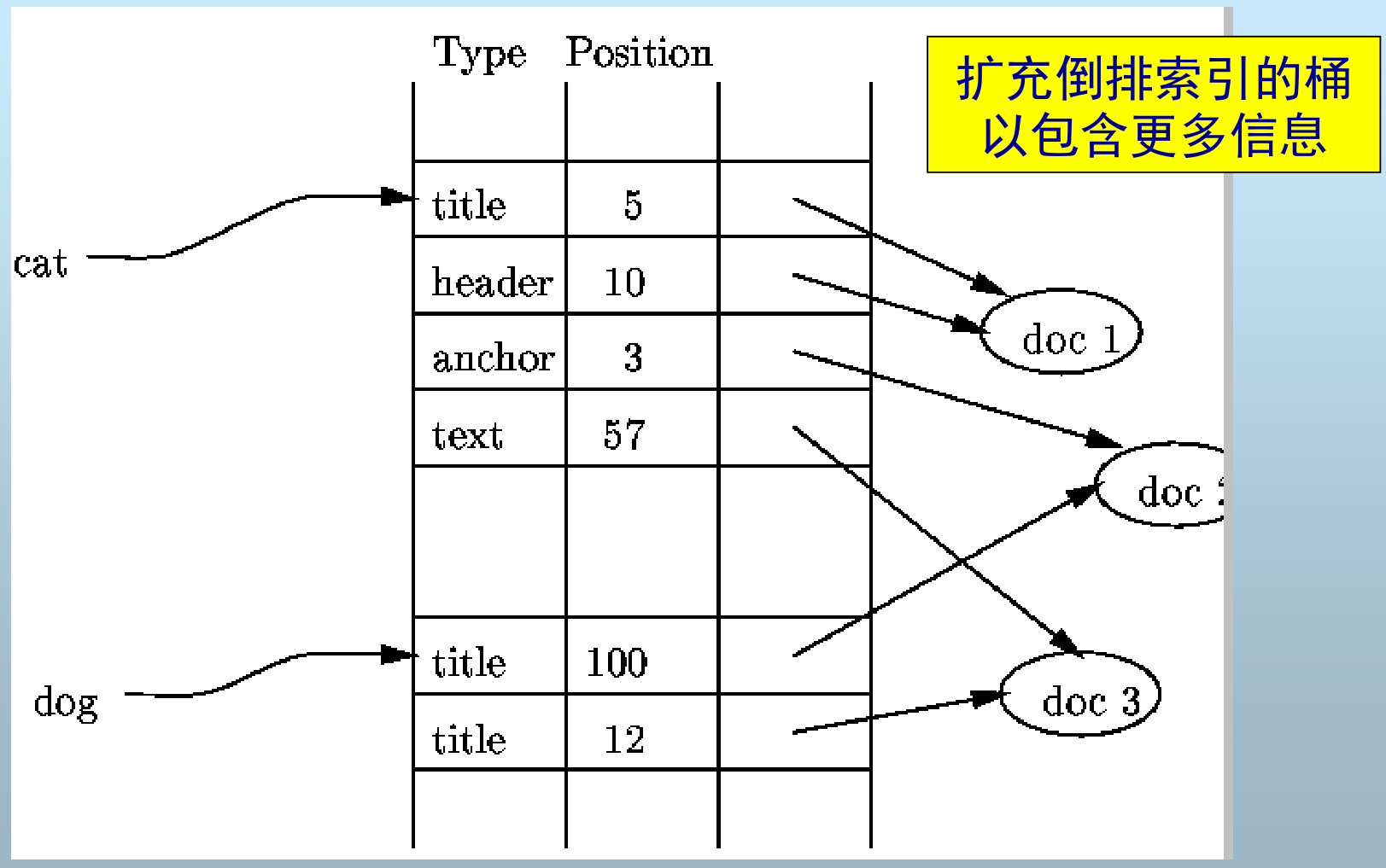
B+树⭐
- 一种树型的多级索引结构
- 树的层数与数据大小相关,通常为 3 层
- 所有结点格式相同: n 个值, n + 1 个指针
- 所有叶结点位于同一层
叶节点
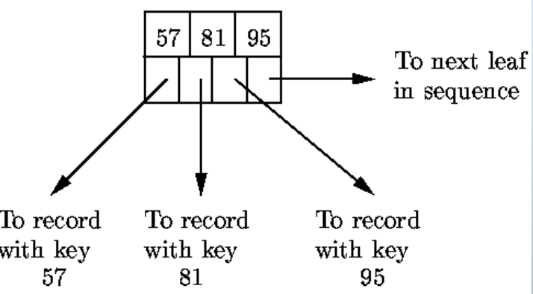
- 至少 \(\lfloor(n+1)/2\rfloor\) 个指针指向键值(\(\lfloor(n+1)/2\rfloor\) 个键值)
- 1 个指向相邻叶结点的指针
- N 对键-指针对
中间结点
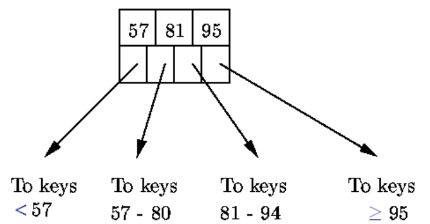
- n 个键值划分 n+1 个子树
- 第 i 个键值是第 i+1 个子树中的最小键值
- 至少 \(\lceil (n+1)/2\rceil\) 个指针指向子树(\(\lfloor(n+1)/2\rfloor\) 个键值)
- 根结点至少 2 个指针
查找
- 从根结点开始
- 沿指针向下,直到到达叶结点
- 在叶结点中顺序查找
插入
- 查找插入叶结点
- 若叶结点中有空闲位置(键),则插入
- 若没有空间,则分裂叶结点
- 叶结点的分裂可视作是父结点中插入一个子结点
- 递归向上分裂
- 分裂过程中需要对父结点中的键加以调整
- 例外:若根结点分裂,则需要创建一个新的根结点
删除
- 查找要删除的键值,并删除之
- 若结点的键值填充低于规定值,则调整
- 若相邻的叶结点中键填充高于规定值,则将其中一个键值移到该结点中
- 否则,合并该结点与相邻结点,删除父节点的一个键值
- 递归向上删除
- 若删除的是叶结点中的最小键值,则需对父结点的键值加以调整
效率
- 访问索引的 I/O 代价=树高( B+树不常驻内存)或者 0(常驻内存)
- 树高通常不超过 3 层,因此索引 I/O 代价不超过 3(总代价不超过 4)
- 通常情况下,根节点常驻内存,因此索引 I/O 代价不超过 2(总代价不超过 3)
\(h=\lceil log_m(n(m-1)+1)\rceil\)
散列表
散列函数 (Hash Functions)
-
h:查找键(散列键)->
[0,...,B-1] -
桶(Buckets):numbered 0,1,…,B-1
散列索引方法: -
给定一个查找键 K,对应的记录必定位于桶 h (K) 中
-
若一个桶中仅一块,则 IO 次数 = 1
-
否则由参数 B 决定,平均 = 总块数 / B
- 一个块可存储两个记录,一个桶占用一个块
- 一个键对应一个桶,一个桶可存储两个记录
- 多余的记录需要存储到溢出块中
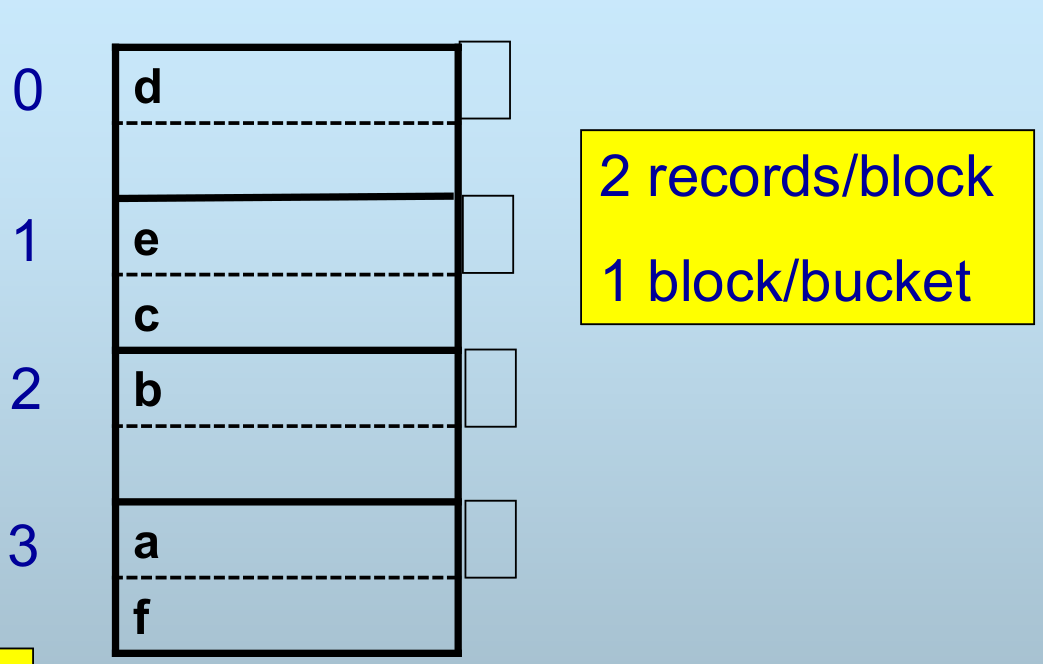
查找
- 对于给定散列键值 K,计算 h (K)
- 根据 h (K) 定位桶
- 查找桶总的块
插入
- 计算插入记录的 h (K),定位桶
- 若桶中有空间,则插入
- 否则创建一个溢出块并将记录置于溢出块中
删除
- 根据给定键值 K 计算 h (K),定位桶和记录
- 删除
空间利用
最好在 50%到 80%之间
文件增长
动态散列表解决
- 可扩展散列表:成倍增长
- 线性散列表:线性增长
可扩展散列表
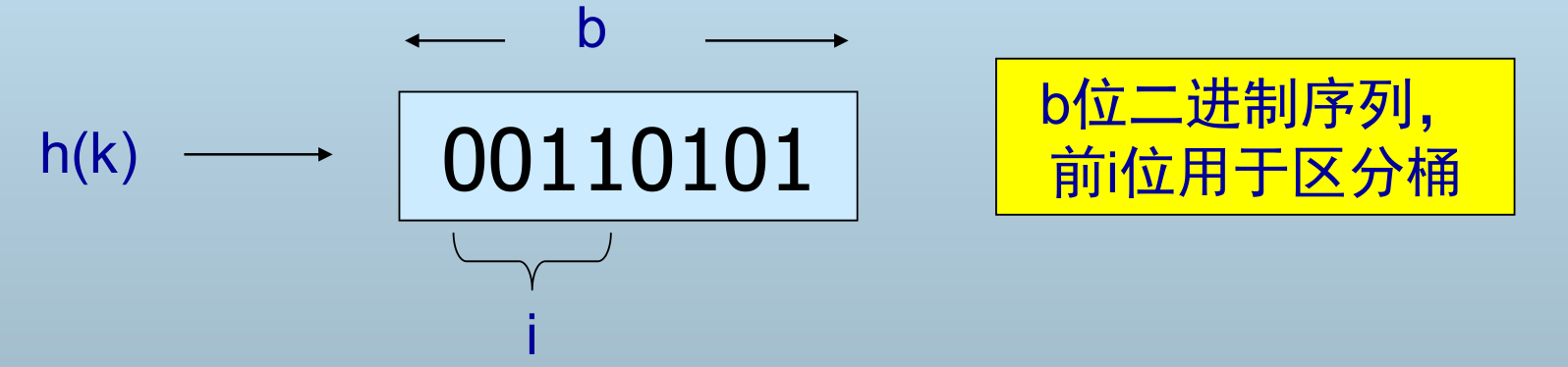
h(K) 是一个 b (足够大) 位二进制序列,前 i 位表示桶的数目
- 前 i 位表示桶的数目
- i 值随文件的增长而增大
- 散列表扩展时,i 值随之增大
- 前 i 位可以构成一个桶数组
- 在可扩展散列表中包括一个全局的 i 值,并且每个桶都有一个局部的 i 值
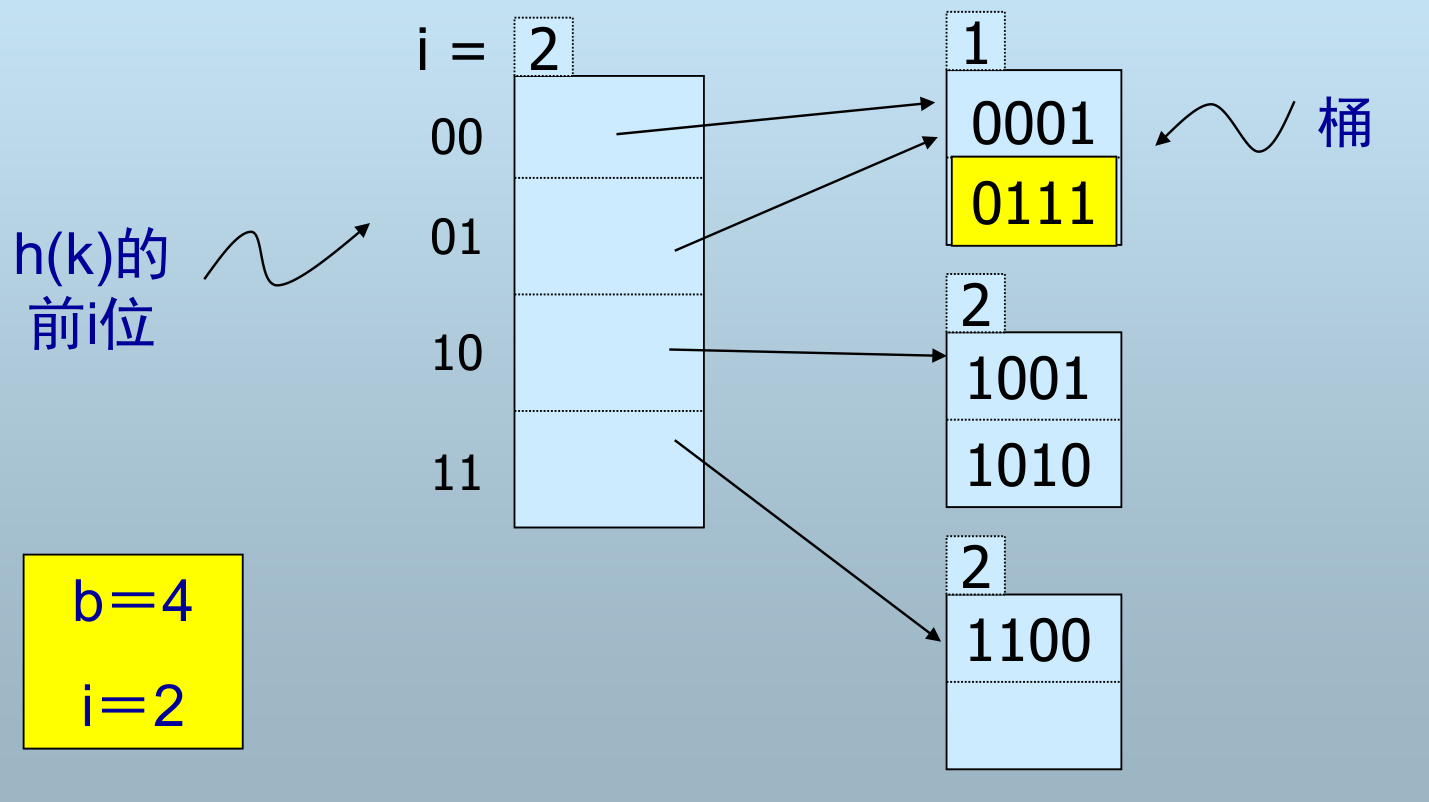
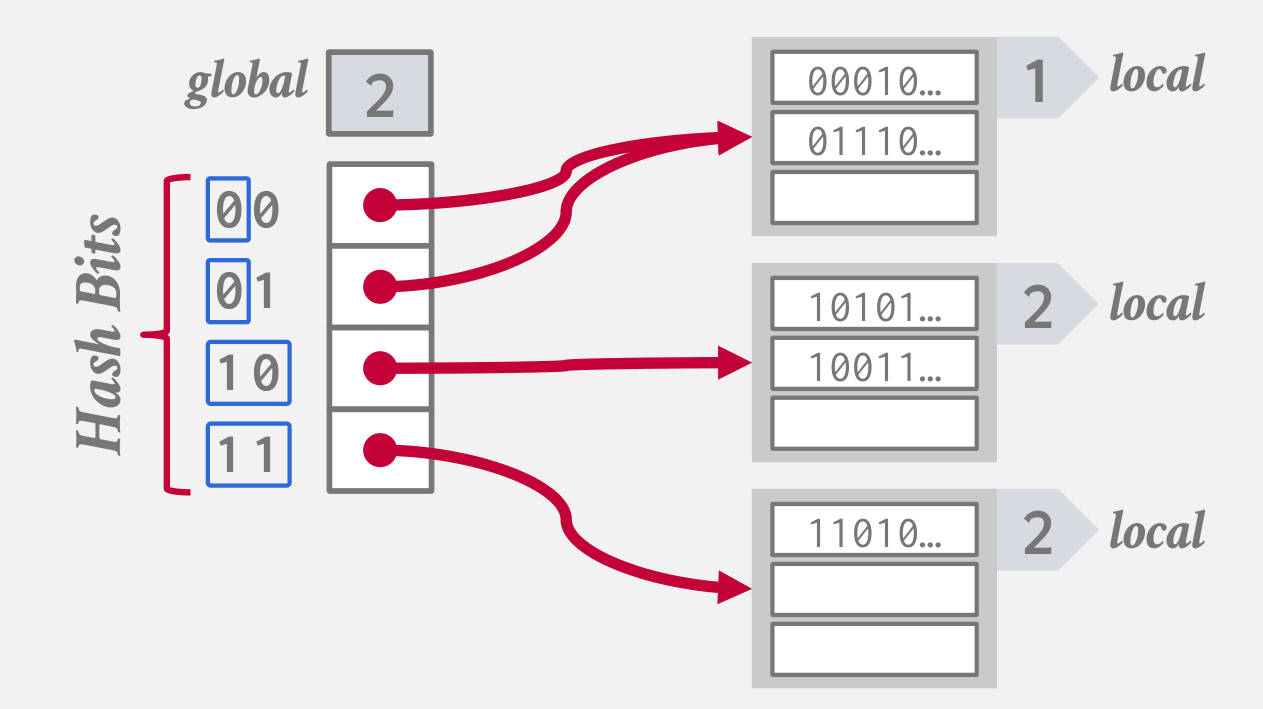
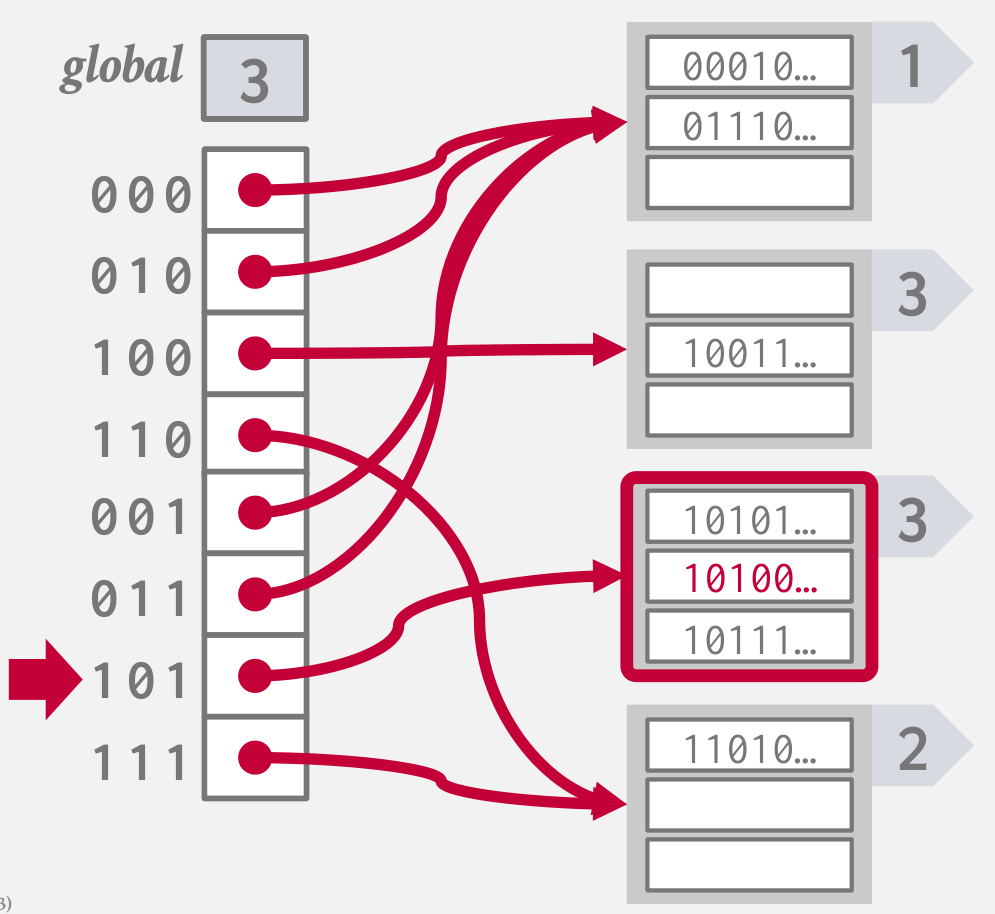
依次满足i=1,2,3,...的桶的索引要求:
- 桶数组中
0001第一位都是0,索引指向第一个桶 10指向第2个桶,11指向第3个桶
扩展
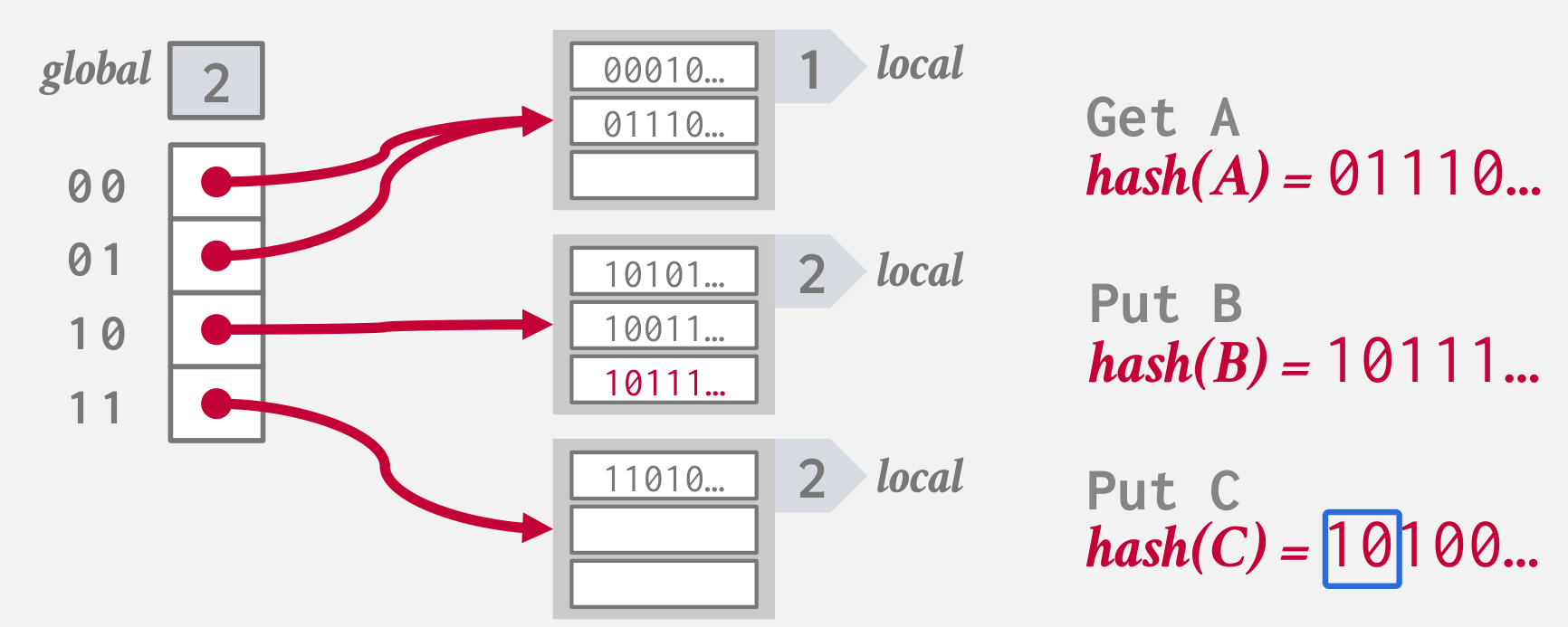
往可扩展散列表中插入 10100...,此时散列表需要扩展
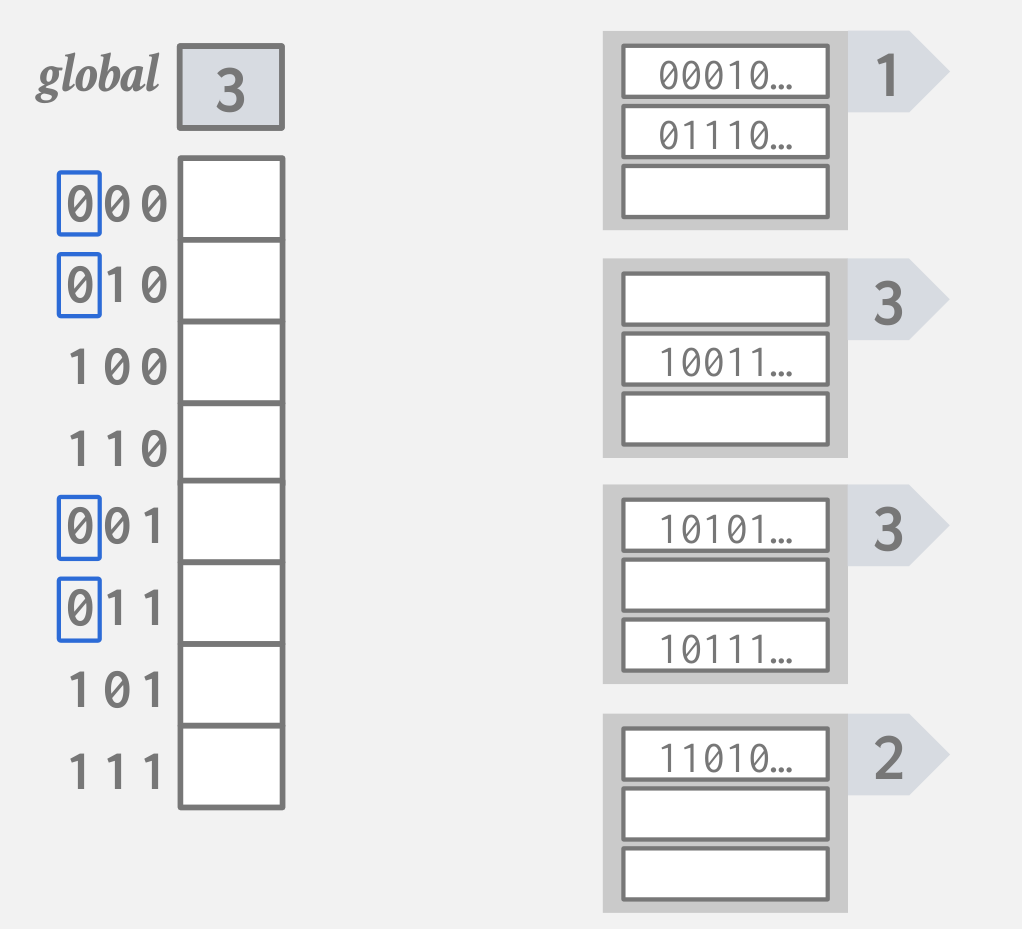
- 增加全局的i值
- 重新分配桶数组
- 将插入位置的桶扩展为两个i+1的桶
![]()
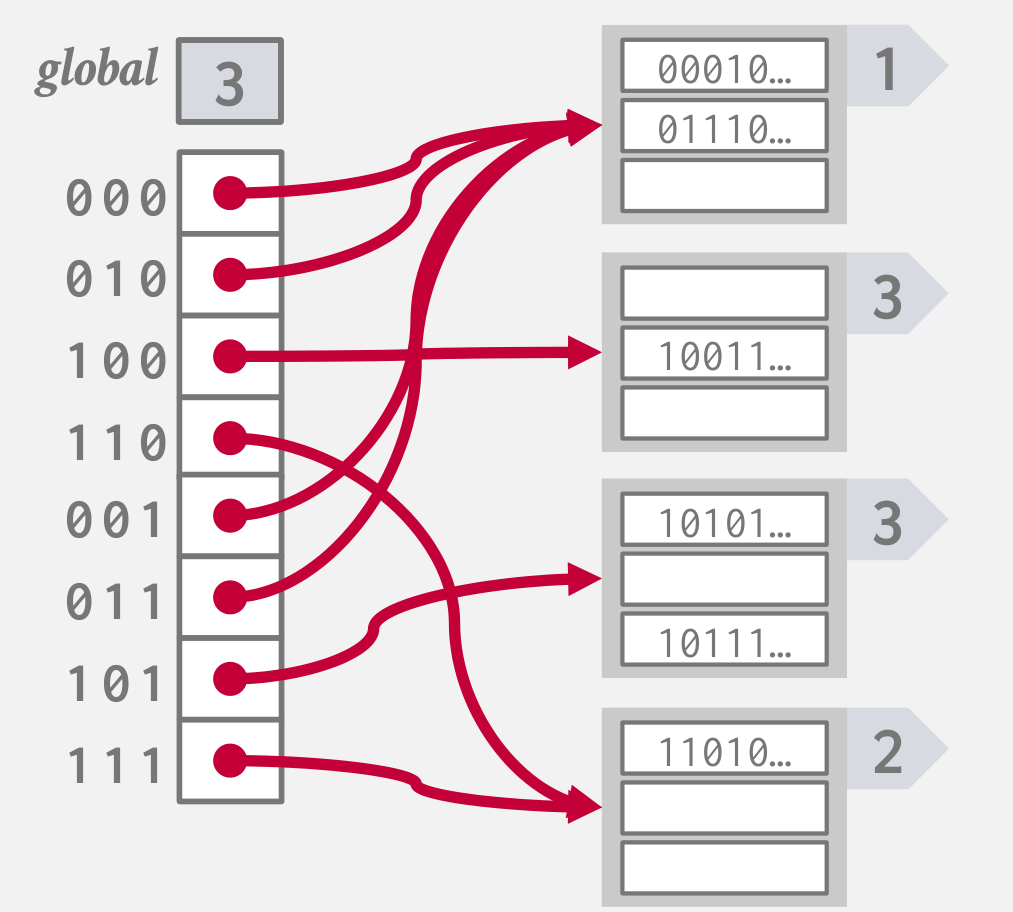
重新分配索引,依次分配i=1,2,3 的桶的索引:
![]()
最后再将数据插入
![]()
优缺点
优点:
- 大部分情况下不存在溢出块,因此当查找记录时,只需查找一个存储块
缺点: - 桶增长速度快
- 可能导致内存存放不下整个桶数组
- 影响其他保存在主存中的数据,波动较大
线性散列表
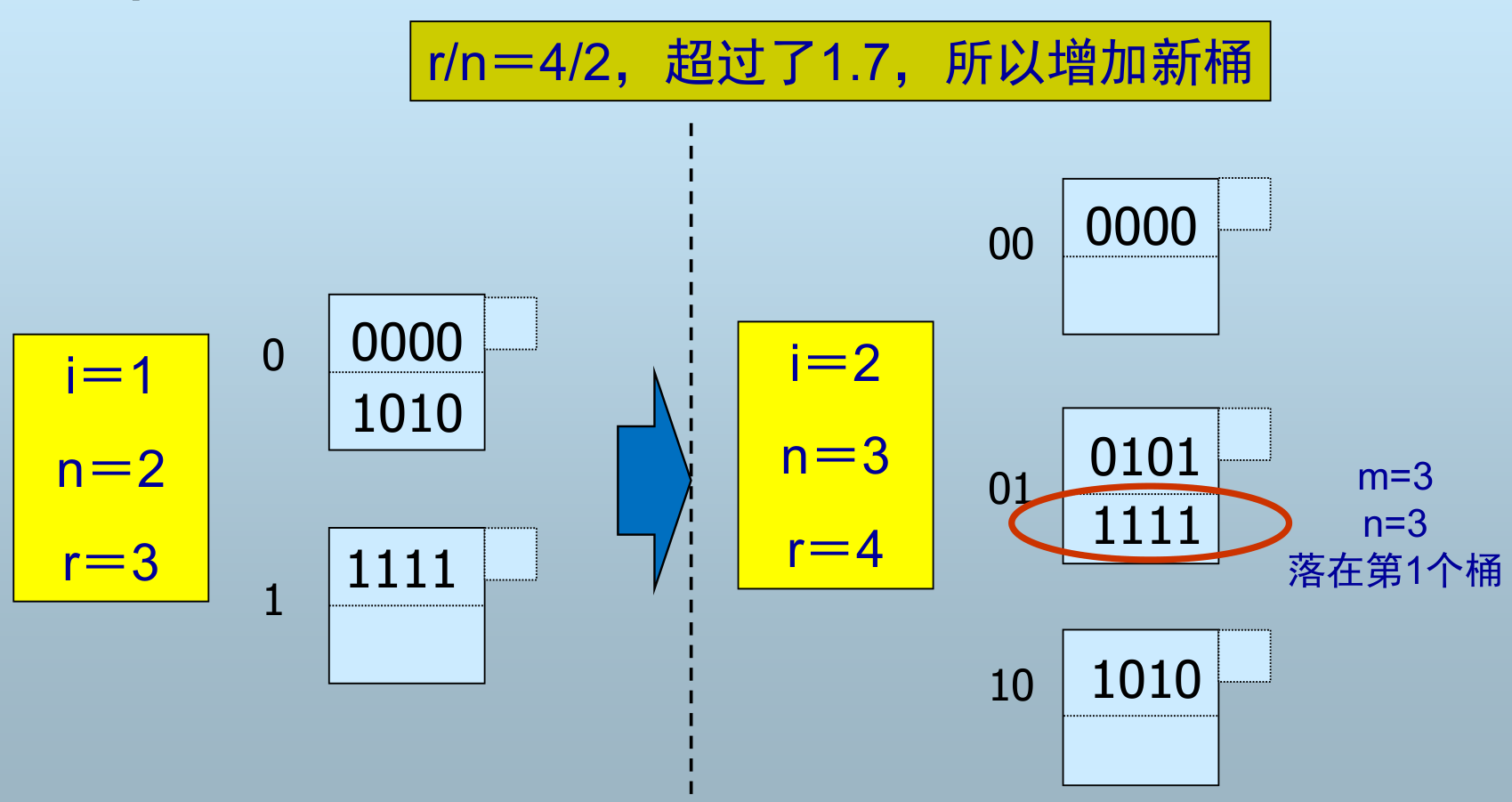
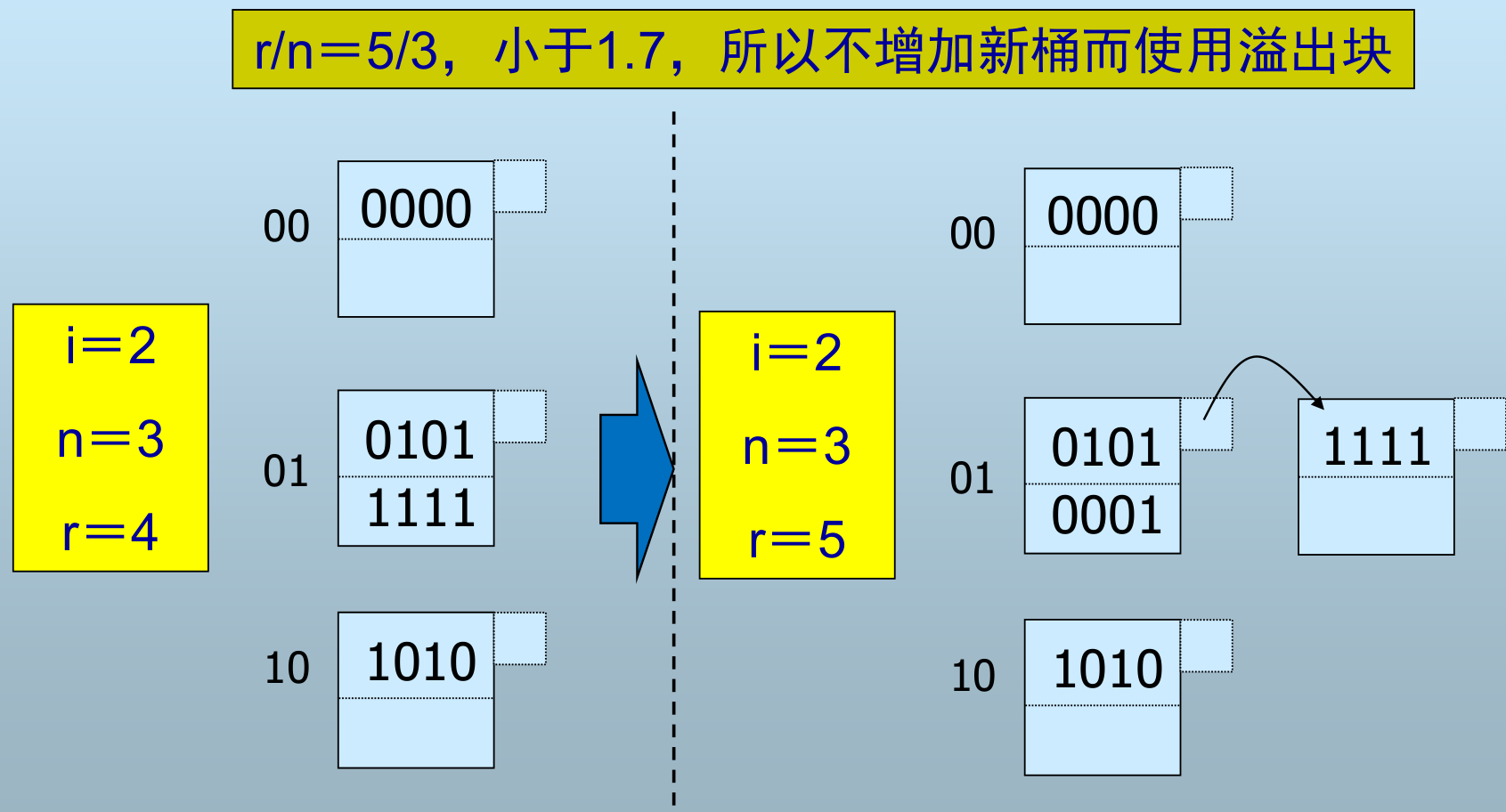
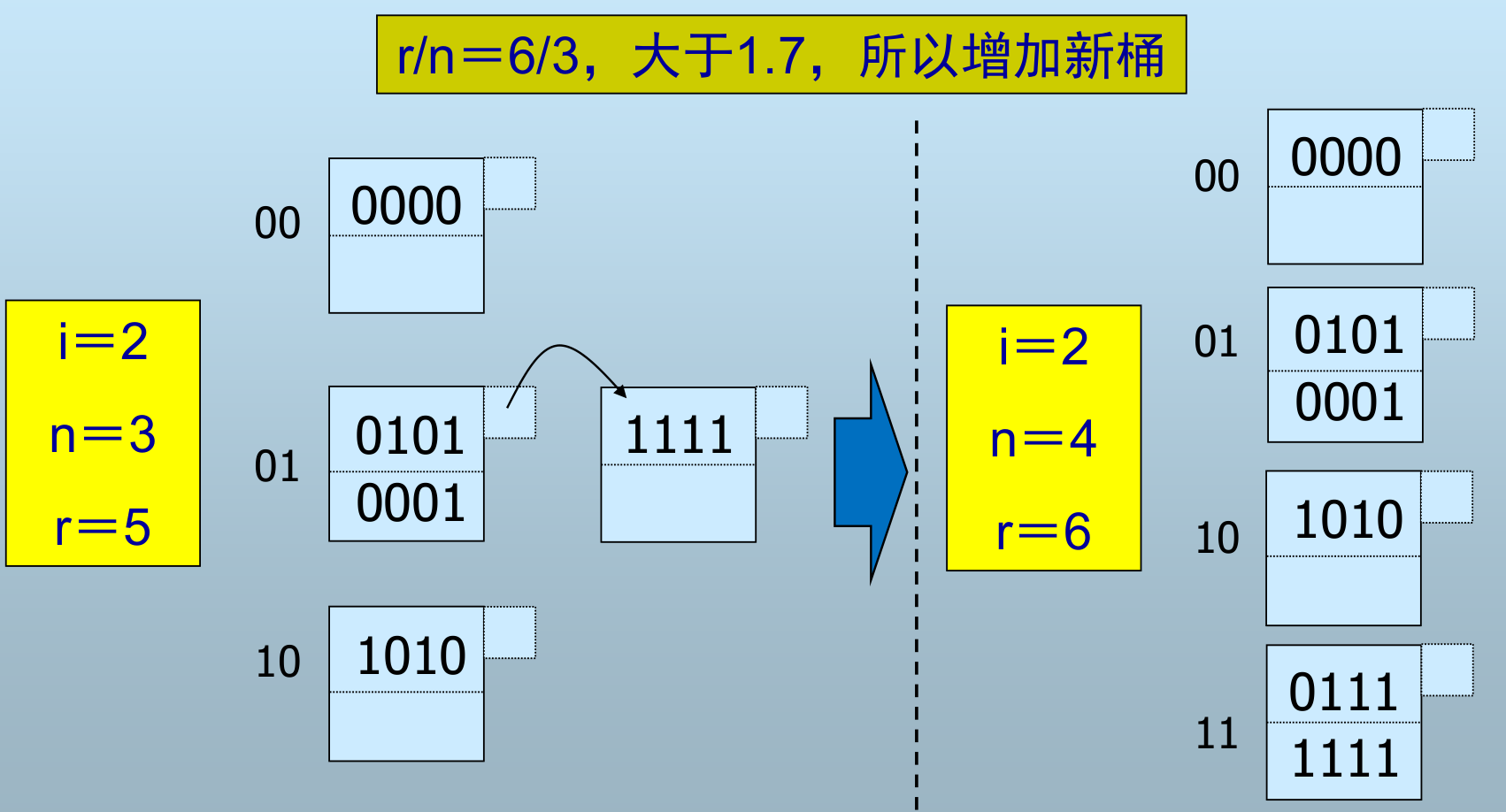
h(k) 仍是二进制位序列,但使用右边 (低) i 位区分桶(用除余运算确定)
- 桶数 = n,
h(k)的右 i 位 = m,当前存储的记录数=r - n 的选择:总是使 n 与 r 保存某个固定比例
插入记录:
-
当 \(n/r\) 大于某个值时,增加新桶;否则,如果桶不足以存放就使用溢出块
-
增加新桶后,需要重新分配所有的记录到对应位置的桶
- 若 m<n, 则记录位于第 m 个桶
- 若 \(n≤m<2^{i}\) , 则记录位于第 \(m−2^{i−1}\) 个桶
-
i:当前被使用的散列函数值的位数,从低位开始
-
n:当前的桶数
-
r:当前散列表中的记录总数
![]()
![]()
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号