03-2 数据库设计过程
以新奥尔良 (New Orleans) 方法为基础,基于 ER 模型和关系模式,采用计算机辅助进行数据库设计。
- 概念设计:基于 ER 模型
- 逻辑设计:基于关系模式设计
- 计算机辅助设计工具:PowerDesigner(SYBASE)
需求分析
数据字典
数据字典是数据库的元数据,包括:
- 数据项
- 数据项描述=
- 数据结构
- 数据结构描述={数据结构名,含义说明,组成:{数据项或数据结构}}
- 数据流
- 数据流描述={数据流名,说明,数据流来源,数据流去向,组成:{数据结构},平均流量,高峰期流量}
- 数据流图中以数据流为单位传输
- 数据流描述={数据流名,说明,数据流来源,数据流去向,组成:{数据结构},平均流量,高峰期流量}
- 数据存储
- 数据存储描述={数据存储名,说明,编号,输入的数据流,输出的数据流,组成:数据结构},数据量,存取频度,存取方式}
- 保存数据的地方
- 数据存储描述={数据存储名,说明,编号,输入的数据流,输出的数据流,组成:数据结构},数据量,存取频度,存取方式}
- 处理过程
- 处理过程描述={处理过程名,说明,输入:{数据流},输出:{数据流},处理:{简要说明}}
参考书:“系统分析与设计”或“软件工程”
概念设计
概念设计侧重于数据内容的分析和抽象,以用户的观点描述应用中的实体以及实体间的联系
- 独立于 DBMS、数据库逻辑结构
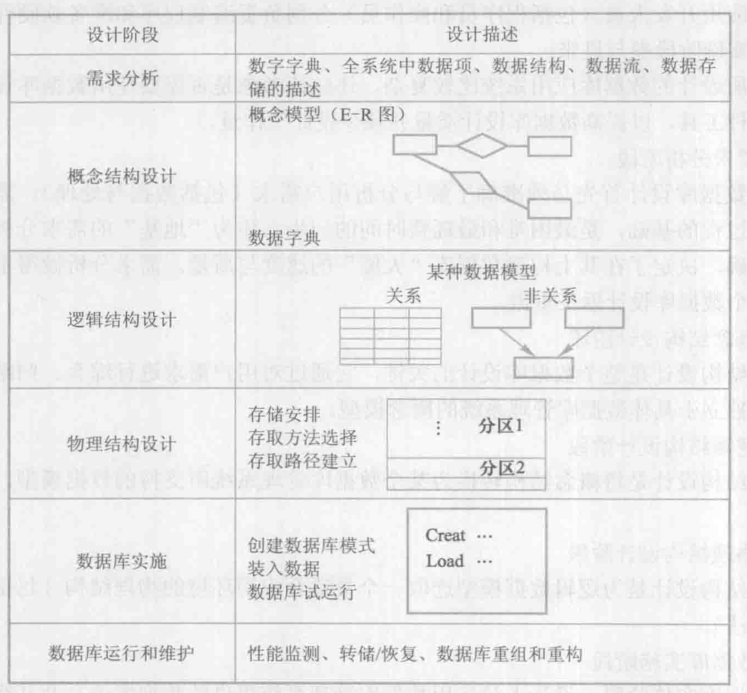
ER 模型概念
- 实体,包含实体属性
- 联系
- 类型
- 1 对 1
- 1 对多
- 多对多
- 类型
符号:
设计步骤
自顶向下进行需求分析,自底向上进行分 ER 设计
分 ER 模型设计
设计原则
- 实体要尽可能得少
- 现实世界中的事物若能作为属性就尽量作为属性对待
确定实体
实体是一个属性的集合
需求分析阶段产生的数据字典中的数据存储、数据流和数据结构一般可以确定为实体
确定实体属性
- 只能考虑系统范围内的属性
- 确定实体的码
- 属性应有域
- 设计原则:
- 属性不需要再描述
- 属性不能与其他实体具有联系
属性如果有属性就应改为实体
属性如果有联系就应改为实体
确定联系和联系属性
- 数据项描述
- 联系的基数
- 0 个或 1 个(国家和总统:1 个国家可以有 0 个或 1 个总统)
- 0 个或 1 个或多个(学院和系)
- 1 个或多个(班级和学生)
- 1 个(公司和法人)
- 确定的 k 个(候选人和推荐人:一个候选人必须有 3 个候选人)
ER 模型集成
- 确定公共实体
- 合并分 ER 图
- 消除冲突
- 属性:类型冲突、值冲突
- 结构:实体属性集不同、联系类型不同、同一对象在不同应用中的抽象不同
- 命名:同名异义、异名同义
ER 模型优化
目标:实体个数要少,属性要少,联系尽量无冗余
- 合并实体
- 1:1联系的两个实体可以合并
- 两个实体经常一块使用就合并
- 消除冗余属性:分 ER 图中一般不存在冗余属性,但集成后可能产生冗余属性
- 冗余属性的几种情形
- 同一非码属性出现在几个实体中
- 一个属性值可从其它属性值中导出
- 冗余属性的几种情形
- 消除冗余联系:
ER 模型扩展
传统的 ER 模型无法表达一些特殊的语义
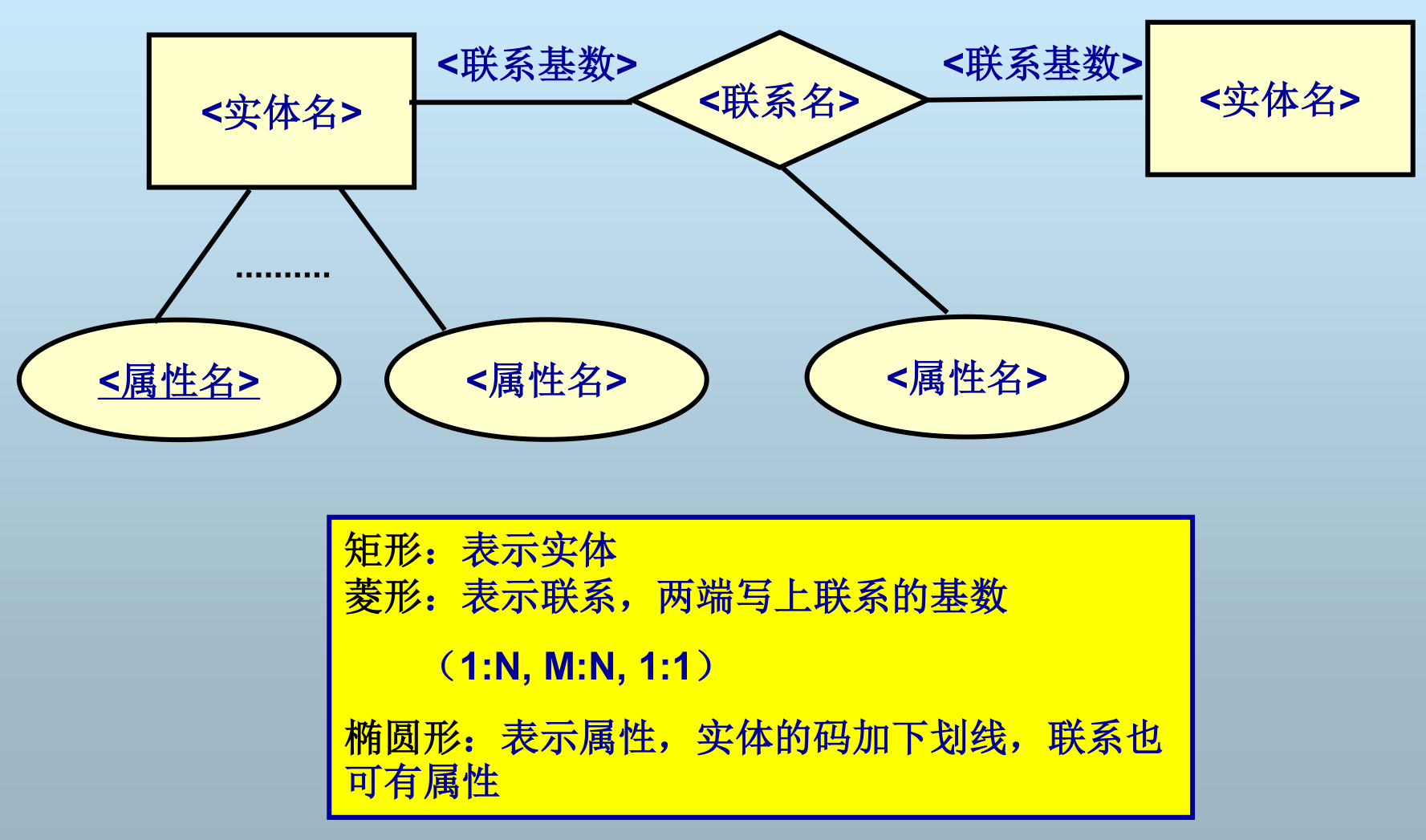
弱实体
- 一个弱实体的存在必须以另一实体的存在为前提
- 弱实体用双线矩形表示,存在依赖联系用双线菱形表示

子类
- ISA 表示子类与超类关系
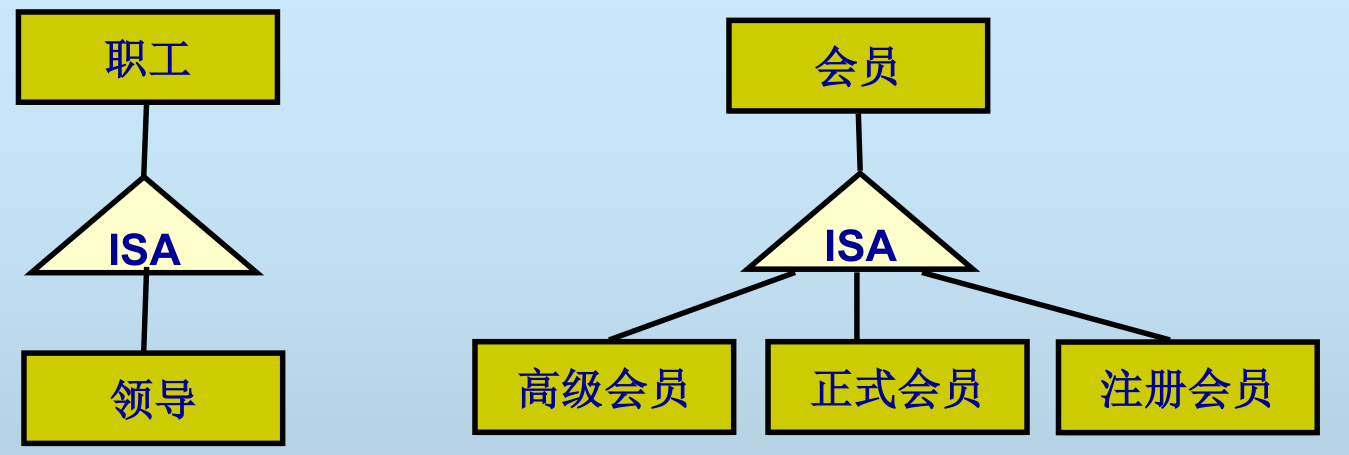
逻辑设计
主要工作:
- ER 模型向关系模型的转换
- 关系模型优化
- 关系模型修正
ER 模型转化为关系数据库模式
基本 ER 模型转化
- 实体 \(\rightarrow\) 关系模式
- 实体的属性为关系模式的属性
- 实体的标识成为关系模式的主码
- 联系转化
- 1:1
- 将任一端的实体的标识和联系属性加入另一实体所对应的关系模式中
- 两模式的主码保持不变
- 1:N
- 将 1 端实体的标识和联系属性加入 N 端实体所对应的关系模式中
- 两模式的主码不变
- M:N
- 新建一个关系模式,该模式的属性为两端实体的标识以及联系属性
- 主码为两端关系模式的主码的组合
- 1:1
扩展 ER 模型转化
- 弱实体
- 弱实体转化为一个关系模式,并加入所依赖的强实体的标识
- 关系模式的主码为弱实体的标识加上强实体的标识
- 子类
- 子类转化为关系模式,并加入父类的主码。
- 子类关系模式的主码设为父类的主码
关系数据库模式规范化
- 确定目标范式级别
- 确定现有的范式级别
- 根据实际需要确定需要达到的范式级别
- 范式越高,连接运算越多,效率越低。
- 如果没有更新,只有查询,则非 BCNF 范式也不会带来实际影响
- 如果应用对数据更新操作较频繁,则要考虑高一级范式以避免数据不一致
- 实际使用中一般以 3NF 为最高范式
- 规范化处理
- 分解模式,达到目标范式级别
模式评价
- 功能评价:否支持用户所有的功能要求
- 性能评价:检查查询响应时间是否满足规定的需求
模式修正
- 功能不满足,则加关系模式或属性
- 性能不满足,则
逆规范化
- 合并模式,增加冗余属性
分库分表
- 80/20 原则:一个关系经常被使用的数据只占20%
- 将 20%热数据单独划分为一个模式,使得大部分的查询都可以在较小规模的数据集上执行
- 把关系模式按属性集垂直分解为多个模式
- 将这些经常访问的列单独拿出组成一个关系模式
- 某几个属性的值重复较多,并且值较大,可考虑将这些属性单独组成关系模式,以降低存储空间
使用存储过程
使用存储过程
- 在程序中使用 SQL
- 客户机计算任务多
- 网络传输重
- 在程序中使用存储过程 (执行一个预先编写好并存储在服务器上的存储过程)
- 可以完成一些 SQL 不能完成的复杂计算,并且封装处理逻辑
- 服务器计算任务重
- 网络传输少
缓存加速
使用 Key-Value 数据库构建缓存层进行查询加速
设计用户子模式(视图)
- 使用更符合用户习惯的别名
- ER 图集成时要消除命名冲突,但是在子模式设计时可以重新定义这些名称
- 给不同级别的用户定义不同的子模式
- 简化用户程序对系统的使用
- 将某些复杂查询设计为子模式以方便使用
物理设计
存取方法
- 索引存取方法
- 聚簇存取方法
- 散列存取方法
可以使用什么样的存取方法依赖于具体的 DBMS
存储结构
- 确定数据的存放位置
- 确定系统配置
实施

维护


 浙公网安备 33010602011771号
浙公网安备 33010602011771号