uvm_reg_file的作用
1.1 uvm_reg_file的作用
uvm_reg_field, uvm_reg与uvm_reg_block三者的组合已经能够组成一个可以使用的寄存器模型; uvm_reg_file的引入主要用于区分不同的hdl路径;
1.2 uvm_reg_file特点
(1) uvm_reg_file是一个纯虚类,不能直接使用,而必须使用其派生类;
(2) reg files可以包含任意数量的uvm_regs以及其他reg files;uvm_reg_file 是uvm_regs和 其他reg files的集合,用于创建规则的重复结构。
(3) uvm_reg_file在uvm_reg_block或其他uvm_reg_file的build函数内例化;
1.3 uvm_reg_file源码
virtual class uvm_reg_file extends uvm_object;
local uvm_reg_block parent;//parent表示此uvm_reg_file所在的uun_ reg_ block;
local uvm_reg_file m_rf;//m_rf示此uvm_reg_ file所在的uvn_reg_File
local string default_hdl_path = "RTL";//hdl_paths_poo1用于记录路径信息:
local uvm_object_string_pool #(uvm_queue #(string)) hdl_paths_pool;
extern function new (string name="");
extern function void configure (uvm_reg_block blk_parent,
uvm_reg_file regfile_parent,
string hdl_path = "");
extern virtual function string get_full_name();
extern virtual function uvm_reg_block get_parent ();
extern virtual function uvm_reg_block get_block ();
extern virtual function uvm_reg_file get_regfile ();
extern function void clear_hdl_path (string kind = "RTL");
extern function void add_hdl_path (string path, string kind = "RTL");
extern function bit has_hdl_path (string kind = "");
extern function void get_hdl_path (ref string paths[$], input string kind = "");
...
endclass
1.4 uvm_reg_file的使用
1.4.1 使用方法一(参考uvm_user_guide)
(1) 实现一个虚的build函数;
(2) 实现一个虚的map函数;
class reg_slave_SESSION extends uvm_reg_file;
rand reg_slave_SOCKET SRC; //是一个uvm_reg型的类,class reg_slave_SOCKET extends uvm_reg;
rand reg_slave_SOCKET DST;
function new(string name = "slave_SESSION");
super.new(name);
endfunction: new
virtual function void build();
this.SRC = reg_slave_SOCKET::type_id::create("SRC");
this.DST = reg_slave_SOCKET::type_id::create("DST");
this.SRC.configure(get_block(), this, "SRC");
this.DST.configure(get_block(), this, "DST");
this.SRC.build();
this.DST.build();
endfunction
virtual function void map(uvm_reg_map mp,
uvm_reg_addr_t offset);
mp.add_reg(SRC, offset+'h00);
mp.add_reg(DST, offset+'h08);
endfunction
virtual function void set_offset(uvm_reg_map mp,
uvm_reg_addr_t offset);
SRC.set_offset(mp, offset+'h00);
DST.set_offset(mp, offset+'h08);
endfunction
`uvm_object_utils(reg_slave_SESSION)
endclass
1.4.2 使用方法二之区分hdl路径
一些环境中只是把一些寄存器加入到uvm_reg_block中,然后在最后的env中例化此reg_block。在现实应用中,一般的会把个uvm_reg_block再加入到一个uvm_reg_block中上,然后在env中例化后者。从逻辑关系上看,呈现出的是两级的register model,如图所示:
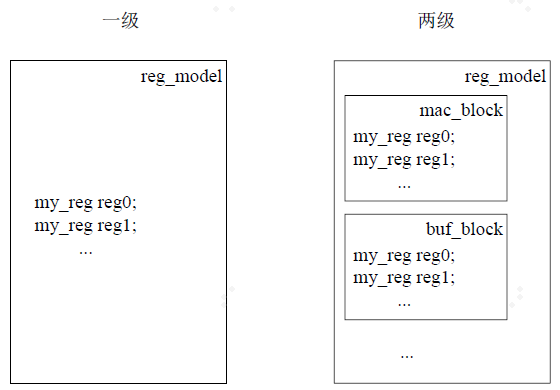
层次化的register model
一般的,只会在第一级的uvm_reg_block中加入寄存器,而第二级的uvm_reg_block通常只添加uvm_reg_block。这样从整体上来说呈现出一个比较清晰的结构。
假如一个DUT分了三个子模块:用于缓存数据的buf模块,用于接收发送以太网帧的mac模块,buf部分的寄存器地址为0x1000~0x1FFF,mac部分的为0x2000~0x2FFF,另外全局寄存器地址为0x0000~0x0FFF.
那么可以如下定义register model:
class global_blk extends uvm_reg_block;
…
endclass
class buf_blk extends uvm_reg_block;
…
endclass
class mac_blk extends uvm_reg_block;
…
endclass
class register_model extends uvm_reg_block;
global_blk gb_ins;
buf_blk bb_ins;
mac_blk mb_ins;
function void build();
default_map = create_map("default_map", 0, 2, UVM_LITTLE_ENDIAN, 0);
gb_ins = global_blk::type_id::create("gb_ins", , get_full_name()); //实例化
gb_ins.configure(this, "global_reg"); //调用子reg_block的configure函数
gb_ins.build(); //调用子reg_block的build函数
gb_ins.lock_model(); //调用子reg_block的lock_model函数
default_map.add_submap(gb_ins.default_map, 16'h0);
bb_ins = buf_blk::type_id::create(“bb_ins”, , get_full_name()); //实例化
bb_ins.configure(this, “buf_reg”); //调用子reg_block的configure函数
bb_ins.build(); //调用子reg_block的build函数
bb_ins.lock_model(); //调用子reg_block的lock_model函数
default_map.add_submap(bb_ins.default_map, 16’h1000);
mb_ins = mac_blk::type_id::create(“mb_ins”, , get_full_name()); //实例化
mb_ins.configure(this, “mac_reg”); //调用子reg_block的configure函数
mb_ins.build(); //调用子reg_block的build函数
mb_ins.lock_model(); //调用子reg_block的lock_model函数
default_map.add_submap(mb_ins.default_map, 16’h2000);
endfunction
…
endclass
要把一个子reg_block加入到父reg_block中,第一步是先实例化子reg_block; 第二步是调用子reg_block的configure函数,在这个函数中要说明这个子reg_block的路径,这个路径不是绝对路径,而是相对于父reg_block来说的路径; 第三步是调用子reg_block的build函数; 第四步是调用子reg_block的lock_model函数; 第五步则是把子reg_block的default_map以子map的形式加入到父reg_block的default_map中。这是可以理解的,因为一般在子reg_block中定义寄存器的时候,我们给定的都是寄存器的偏移地址,其实际物理地址还要再加上一个基地址。前面说过,寄存器的FRONTDOOR的读写操作最终都要通过default_map来完成。很显然,子reg_block的default_map是不知道寄存器的基地址的,它只知道寄存器的偏移地址,只有把它加入到父reg_block的default_map,同时在加入的时候告诉这个子map的偏移地址,这样父reg_block的default_map就可以完成FRONTDOOR操作。
一般的把具有同一基地址的寄存器作为整体加入到一个uvm_reg_block中,而不同的基地址对应不同的uvm_reg_block。每个uvm_reg_block一般都有与其对应的物理地址空间。对于本节的所说的子reg_block,其里面还可以加入小的reg_block,这相当于是把地址空间再次细化。
而引入vm_reg_file的概念主要是用于区分不同的hdl路径。
假设有两个寄存器regA和regB,它们的hdl路径为top_tb.mac_reg.fileA.regA,top_tb.mac_inst.fileB.regB,设top_tb.mac_reg下面所有寄存器的基地址为0x2000,这样在第二级的reg_block中,加入mac模块的时候,其hdl路径要写成:
mb_ins.configure(this, “mac_reg”);
相应的,在mac_blk的build中,要通过如下方式把regA和regB的路径告知register model:
regA.configure(this, null, "fileA.regA");
…
regB.configure(this, null, "fileB.regB");
假如fileA中有几十个寄存器时,那么很显然,fileA.*会几十次的出现在这几十个寄存器的configure函数里。假如有一天,fileA的名字忽然变为了filea_inst,那么就需要把这几十行中所有fileA替换成filea_inst,这个过程很容易出错。
为了适应这种情况,UVM的register model中引入了uvm_reg_file的概念。uvm_reg_file同uvm_reg一样是一个纯虚类,不能直接使用,必须使用其派生类:
class regfile extends uvm_reg_file;
function new(input string name="unnamed_regfile");
super.new(name);
endfunction
`uvm_object_utils(regfile)
endclass
class mac_blk extends uvm_reg_block;
rand regfile file_a;
rand regfile file_b;
rand my_reg regA;
rand my_reg regB;
function void build();
…
file_a = regfile::type_id::create(“file_a”, , get_full_name());
file_a.configure(this, null, “fileA”);
file_b = regfile::type_id::create(“file_b”, , get_full_name());
file_b.configure(this, null, “fileA”);
…
regA.configure(this, file_a, “regA”);
…
regB.configure(this, file_b, “regB”);
…
endfunction
endclass
如上所示:
(1)先从uvm_reg_file派生一个类user_defined_uvm_reg_file(regfile);
(2)然后在mac_blk中实例化此类,在uvm_reg_block的build函数中例化user_defined_uvm_reg_file(regfile);
(3)在mac_blk的build函数中调用(regfile)configure函数,在uvm_reg_block的build函数中调用user_defined_uvm_reg_file的configure函数;
注: uvm_reg_file configure函数参数的含义:
参数1含义:uvm_reg_file所在reg_block的指针;
参数2含义:假设此reg_file是另外一个reg_file的parent,那么这里就填写该reg_file的父reg_file指针,uvm_reg_file的父reg_file指针,该处只有一级reg_file,因此填写null;
参数3含义:此reg_file的hdl路径,uvm_reg_file的hdl path;
当把reg_file定义好了后,在调用uvm_reg的configure函数时,就可以把其第二个参数设为reg_file的指针。
注: 加入uvm_reg_file的概念后,当uvm_reg regA的hdl层次由fileA变为filea_inst时,只需要修改uvm_reg_file file_a的configure参数,其他不需要做任何改变,大大减小了出错的概率;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号