
pytorch中nn.Embedding()的用法
记得在代码的开始引入
import torch
import torch.nn as nn
举个常用的例子
#以下代码为pytorch的python代码
embedding = nn.Embedding(10, 3)
print(embedding.weight)
input = torch.LongTensor([[0, 2, 0, 5]])
print(input)
print(embedding(input))
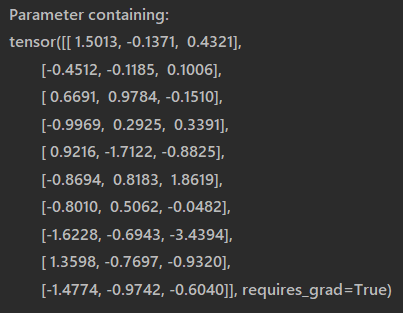
embedding的参数为
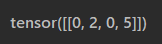
input的内容为
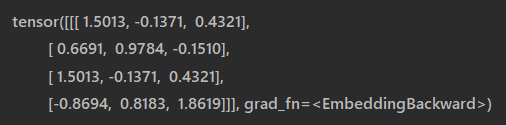
输出的结果为
对以上的代码和输出的解释
embedding相当于创建一个能翻译10个单词的工具,其中这10个单词为0~9,每个单词对应一个长度为3的向量
input就是一个单词,它由0, 2, 0, 5四个单词组成的
当代码做词嵌入的时候,就相当于把0, 2, 0, 5作为下标,到embedding里面找对应下标的向量。
比如在embedding里面,下标为0的3维度向量为[ 1.5013, -0.1371, 0.4321],所以最后的输出会把0替换成[ 1.5013, -0.1371, 0.4321]
依次类推
2会替换成[ 0.6691, 0.9784, -0.1510]
5会替换成[-0.8694, 0.8183, 1.8619]
最后的结果就是
[
[ 1.5013, -0.1371, 0.4321],
[ 0.6691, 0.9784, -0.1510],
[ 1.5013, -0.1371, 0.4321],
[-0.8694, 0.8183, 1.8619]
]
padding_idx的用法(mask)
padding的意思是“填充”
写法
embed = nn.Embedding(10,3,padding_idx=0)
意思就是说当单词为0的时候,进行词嵌入的时候的输出为[0,0,0]
embed = nn.Embedding(10,3,padding_idx=3)
意思就是说当单词为3的时候,进行词嵌入的时候的输出为[0,0,0]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号