gpdb删除segment上残余的session和sql
转载请注明出处:gpdb删除segment上残余的session和sql
最近公司的gpdb的变卡,导致线上系统查询队列阻塞,用户一点数据都查不出来。
每天早上我和同事都得用我们自家做的gpdb运维平台去杀掉生产的sql,让消费sql能跑起来
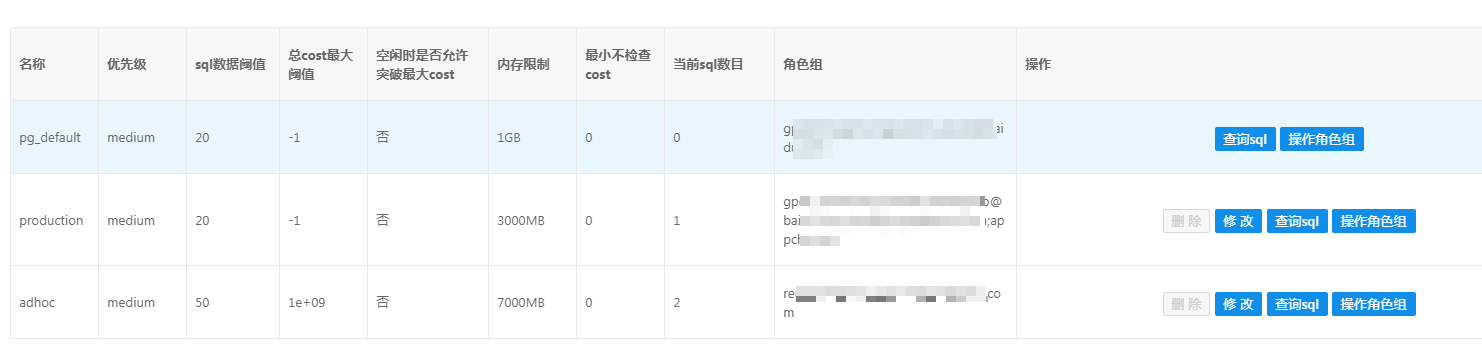
但每天这么杀sql也不是事,而且平常生产sql是执行很快的,但不知道为什么gpdb启动时间变长后,修改sql就变慢了(运维平台上显示正在运行很久),重启gpdb后,sql会变得很快
遇到这种系统运行时间久,系统变慢的问题,我们第一反应是gpdb有内存泄漏问题。组长看过gpdb的很多ppt,说可能是segment上残余进程(session、sql)引起的,这些会占用锁和内存。

于是和另一个同事研究这个问题,最终搞定了这个问题
首先用建立一张外部网络表用utility模式查询segment上的所有session
CREATE EXTERNAL WEB TABLE get_segment_mpp_session_info (segment_id integer, mpp_session_id integer, start_time bigint)
EXECUTE 'PGOPTIONS="-c gp_session_role=utility" psql -tA -p $GP_SEG_PORT -d da_common -c "select distinct $GP_SEGMENT_ID, mppsessionid, extract(epoch from backend_start)::int from pg_locks left join pg_stat_activity on pg_locks.pid=pg_stat_activity.procpid"'
FORMAT 'TEXT' (DELIMITER '|');
然后join过滤出segment有而master没有的查询, 注意where条件过滤时间可以排除此条sql
with
segment_sql_info as (select * from get_segment_mpp_session_info),
distinct_segment_session_id as (select distinct mpp_session_id from segment_sql_info),
distinct_master_session_id as (select distinct mppsessionid from pg_locks)
select segment_sql_info.*
from
(
select mpp_session_id
from distinct_segment_session_id
left join distinct_master_session_id
on mpp_session_id = mppsessionid
where mppsessionid is null
) loss_id
join segment_sql_info
on loss_id.mpp_session_id = segment_sql_info.mpp_session_id
where start_time < extract(epoch from now())::int
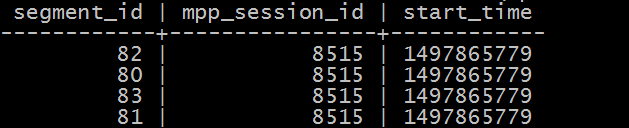
最后稍微改改上面的sql,用utility模式去各个segment杀session就行
with segment_sql_info AS
(SELECT * FROM get_segment_mpp_session_info), distinct_segment_session_id AS
(SELECT DISTINCT mpp_session_id FROM segment_sql_info), distinct_master_session_id AS
(SELECT DISTINCT mppsessionid FROM pg_locks)
SELECT 'PGOPTIONS=''-c gp_session_role=utility'' psql -tA -h ' || address || ' -p '|| port || ' -d da_common -c "select pid, pg_terminate_backend(pid), current_query from pg_locks pgl left join pg_stat_activity pgsa ON pgl.pid = pgsa.procpid WHERE mppsessionId=' || mpp_session_id || ' group by pid, current_query"'
FROM
(SELECT segment_sql_info.*
FROM
(SELECT mpp_session_id
FROM distinct_segment_session_id
LEFT JOIN distinct_master_session_id
ON mpp_session_id = mppsessionid
WHERE mppsessionid is NULL ) loss_id
JOIN segment_sql_info
ON loss_id.mpp_session_id = segment_sql_info.mpp_session_id
WHERE start_time < extract(epoch
FROM now())::int ) info
LEFT JOIN gp_segment_configuration
ON segment_id = dbid
后来在变卡的时候,跑一跑上面的sql,生成shell命令去每个segment去杀session,生产sql直接就变快了。我们写成contab去定时杀,这样就不用人工清理了。
需要注意的
- 上面的sql查出的残余session,可能只是短时间残余,过几秒后自己会被gpdb自己清掉
- 使用pg_terminate_backend函数可能杀不掉MPP查询进程,这时需要去segment去执行kill -9
回顾一下gpdb变慢的过程
- 线上提交了一条DML sql,打开了写锁
- 可能超时、网络不好、内存不足等原因,这条sql查询失败
- gpdb尝试删除这条sql在master和segment上的相关信息,但是可能由于网络等原因没有清掉某些segment的信息(进程、session事务、锁)
- 提交消费sql,gpdb在master看不到相关的锁信息,于是让生产sql在master上分配一个读锁,并尝试在segment上分配读锁
- 在某些含有残余session的segment上,由于之前的写锁未释放,所以读锁也获取不了,虽然查询在master上认为已经运行了,但实际上segment上的读操作会被一直阻塞
最后吐槽一下gpdb,session残余的问题都没处理好╭∩╮(︶︿︶)╭∩╮

 浙公网安备 33010602011771号
浙公网安备 33010602011771号