MySQl数据库
MySQL
命令里面的[]是可选的代码
数据库:CRUD程序员 CV程序员 API程序员
在数据库中设置int类型的字段长度的时候,修改的是它的显示的最大宽度,和存储的长度无关
1. 数据库里面的字段属性
- Unsigned: 奇怪的知识增加了,使用Unsigned去定义字段的属性的时候,其他的属性(not null, comment)都要放在这儿属性之后,不然会报错
- 无符号的整数
- 声明该列不能为负数
- zerofill
- 插入的数据长度不足就会用0填充
- 自增 AUTO_INCREMENT
- 在上调记录的基础上 +1 (默认)
- 通常用来设置主键自增,必须是整数类型
- 可以自定义主键自增的起步值和步长
- 非空 NULL not NULL
- 插入数据时不能为空
- NULL,如果不填写值默认就为空
- 默认值 default // 在建表定义字段属性的时候使用,在关键字后面加入想要的默认值或者注释即可
- 注释 comment
MySQL基础语句
退出连接:exit; //退出后mysql会拒绝访问,目前我只会重启服务解决
创建数据库: create database 数据库名;
删除数据库: DROP DATABASE 数据库名;
查询表: select *from 表名 where ?;
建立表:
CREATE TABLE table_name (column_name column_type);插入数据:
INSERT INTO table_name ( field1, field2,...fieldN ) VALUES ( value1, value2,...valueN );查询语句: // select * 这里的*是需要打的,它代表的是需要返回的字段
SELECT column_name,column_name FROM table_name [WHERE Clause] [LIMIT N][ OFFSET M] 查询语句中你可以使用一个或者多个表,表之间使用逗号(,)分割,并使用WHERE语句来设定查询条件。 SELECT 命令可以读取一条或者多条记录。 你可以使用星号(*)来代替其他字段,SELECT语句会返回表的所有字段数据 你可以使用 WHERE 语句来包含任何条件。 你可以使用 LIMIT 属性来设定返回的记录数。 你可以通过OFFSET指定SELECT语句开始查询的数据偏移量。默认情况下偏移量为0。显示表的结构:desc table_name;
查询表的创建语句:show create table table_name;
多表查询:
select test.name,test1.* from test,test1 where ;修改表的字段:alter
- add,添加,drop删除,
- change用来重命名字段,不能修改字段的类型和约束
- modify不用来字段重命名,只能修改字段的类型和约束
清空表数据truncate: truncate table_name;
- 自增列的计数器会归零
- 利用delete清除表记录,不会影响自增,自增的记录会从上次的基础上增加
2.外键(FK_)
FK_:约束名 ;
删除具有引用关系的表时,需要先删除引用的表,然后在删除被引用的表
一下这个是表建立成功后,修改表添加的外键 // 还没使用成功
alter table table1_name
add constraint 'FK_ xxx' foreign key ('xxx') refrnces 'table2_name'('xxxx');
3.DQL查询数据库最核心的操作
select:
-
查询的时候可以给字段,表起别名 as,查询出来的结果会用别名替换
-
函数Concat(a,b)拼接字符串:例如:
select concat('id是:' ,id) ,name as '名字',age from test;
-
去重(distinct),去除select查询出来的结果的重复数据,可以用来去除一列的重复数据:例如:
select distinct name from test; -
分页显示:limit a b ,显示的起始位置,b显示多少条
select *from test limit 5,5; -
模糊查询:
-
%”是 MySQL 中最常用的通配符,它能代表任何长度的字符串,字符串的长度可以为 0。例如,
a%b表示以字母 a 开头,以字母 b 结尾的任意长度的字符串。该字符串可以代表 ab、acb、accb、accrb 等字符串。

-
例如:
select * from test where name like '%o%'; select * from test where id between 5 and 7; select * from test where id in(1,4,5);
4.JDBC(重点)
- 数据库驱动: 程序需要通过驱动连接数据库
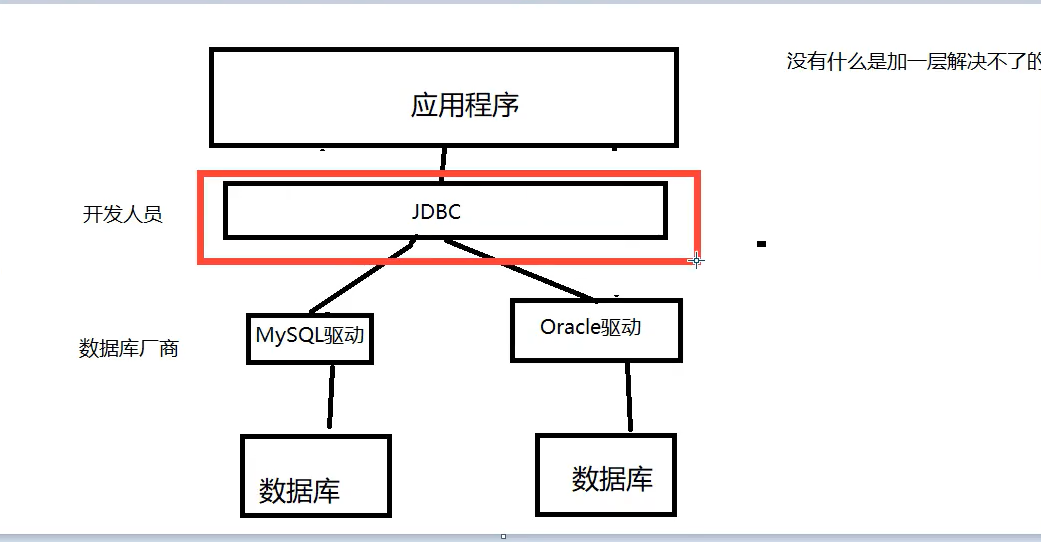
)
-
java.sql // java自带
-
javax.sql
-
还需要导入一个数据库驱动包 connector
需要在当前项目的目录下创建lib目录加入connector 的jar包,
并且还要把创建的文件加载进项目才能使用
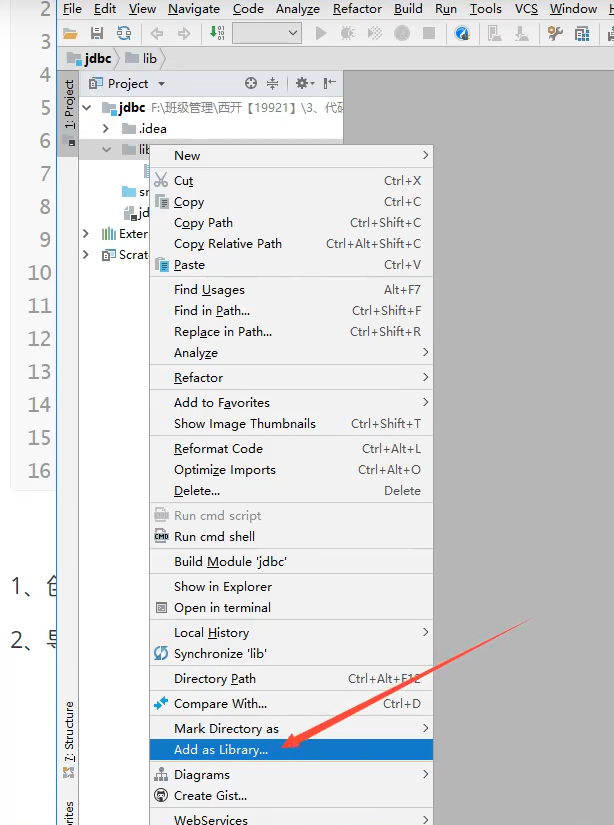
)
第一个JDBC连接数据库的查询代码
-
加载驱动
-
编写url 和用户信息
-
DriverManager连接数据库,并返回一个Connection对象,表示数据库
-
4.创建sql语句的执行对象Statement
-
用statement对象执行sql语句,可能有返回的结果集(链表的形式)
-
释放连接,关闭资源
// 编写的第一个JDBC程序
public class FirstJDBC {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
// 1.加载驱动
Class.forName("com.mysql.jdbc.Driver"); // 固定写法,加载驱动对象
// 2.编写url 和用户信息
// useUnicode运用Unicode编码,characterEncoding=utf8字符集为UTF-8,useSSl:运用安全连接
// localhost是本机的,可以改成远程的ip
String url = "jdbc:mysql://localhost:3306/test?" +
"useUnicode=true&characterEncoding=utf8&useSSL=true";
String username = "root";
String password = "password";
// 3. DriverManager连接数据库,并返回一个Connection对象,表示数据库
Connection connection = DriverManager.getConnection(url, username, password);
// 4.创建sql语句的执行对象Statement
Statement statement = connection.createStatement();
// 5.用statement对象执行sql语句,可能有返回的结果集(链表的形式)
// 执行查询语句用executeQuery(),执行插入、删除、修改用executeUpdate()
// execute(),增删改查的sql都能执行,有判断效率会低点
ResultSet resultSet = statement.executeQuery("select *from test");
while (resultSet.next()){
System.out.print(resultSet.getInt("id")+"\t"); //在不知道类型的情况下可以用getObject()获取
System.out.print(resultSet.getObject("name")+"\t");// 里面的参数要和数据库一一对应
System.out.println(resultSet.getObject("age")+"\t");
}
// 6.释放连接,关闭资源
resultSet.close();
statement.close();
connection.close();
}
}
优化:把重复的资源利用properties存储
// 连接数据库的JDBC工具类
// 把每次使用JDBC重复写的代码资源提取出来
public class JdbcUnit {
private static String driver = null;
private static String url = null;
private static String username = null;
private static String password = null;
static{
// 用当前这个类去加载载入资源文件
InputStream resourceAsStream = JdbcUnit.class.getClassLoader().getResourceAsStream("resouses.properties");
// 定义的工具类properties载入并读取properties文件
Properties properties = new Properties();
try {
properties.load(resourceAsStream);
} catch (IOException e) {
e.printStackTrace();
}
driver = properties.getProperty("driver");
url = properties.getProperty("url");
username = properties.getProperty("username");
password = properties.getProperty("password");
}
public static Connection getConnection() throws ClassNotFoundException, SQLException {
Class.forName(driver);
return DriverManager.getConnection(url,username,password);
}
public static void closeResource(Connection conn, Statement sta, ResultSet res) throws SQLException {
conn.close();
sta.close();
res.close();
}
}
// properties存储的资源
driver = com.mysql.jdbc.Driver
url = jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf8&useSSL=true
username=root
password=password
JDBC里面比较重要的类Statement
用statement对象执行sql语句,可能有返回的结果集(链表的形式)
执行查询语句用executeQuery(),执行插入、删除、修改用executeUpdate()
execute(),增删改查的sql都能执行,有判断效率会低点
SQL注入的问题
在查询等操作进行判断的时候,用户非法的利用or非法拼接把判断结果变为true;
PrepareStatement和Statement的区别
利用占位符代替参数
PrepareStatement更安全,可以避免sql注入
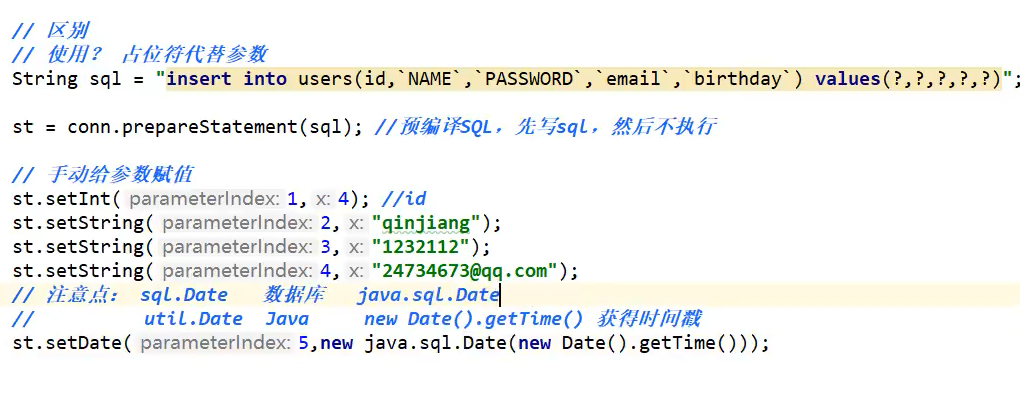
)
idea链接数据库问题:
错误: Driver class 'com.mysql.cj.jdbc.Driver' not found.
// 貌似需要把JDBC的驱动程序在项目中加载好,把驱动的bin程序放在tomcat的lib目录下,在测试连接上面弹出的缺少驱动文件那儿点击下载就连上了
事务
事务:被事务修饰的一系列的操作看成‘一个操作’,这些操作要么同时成功,要么同时失败。
mysql jdbc:默认是自动提交的,每个sql操作执行成功都会自动提交,而在有些情况下我们需要两个或多个sql执行时是同时成功和同时失败的,所以需要把自动提交关闭,把多个sql语句放在一个事务中。
事务的四大特征(这个很重要)
1.原子性:事务是不可分割的最小操作单元,要么同时成功,要么同时失败。
2.持久性:事务一旦回滚/提交后会持久的改变(无论是电脑关机等……都不会改变)
3.隔离性:多个事务之间,互相独立,减少影响。
4.一致性:事务执行前后,数据总量不变。eg:上面赚钱的例子,不管怎么赚钱,二者的钱数总量是不变的。
在我看来实现同时成功和同时失败的原因是因为两个sql的事务(一个事务)是由connection.commit(),一同提交到数据库的,所以在事务提交之前出现了异常导致两个sql无法提交成功实现的。
// 新学代码
//在关闭了数据库的自动提交后,此处会默认开启事务
connection.setAutoCommit(false);
// 提交事务
connection.commit();
public static void main(String[] args) throws ClassNotFoundException, SQLException {
// 1.加载驱动
Class.forName("com.mysql.jdbc.Driver"); // 固定写法,加载驱动对象
// 2.编写url 和用户信息
// useUnicode运用Unicode编码,characterEncoding=utf8字符集为UTF-8,useSSl:运用安全连接
String url = "jdbc:mysql://localhost:3306/test?" +
"useUnicode=true&characterEncoding=utf8&useSSL=true";
String username = "root";
String password = "password";
Connection connection = DriverManager.getConnection(url, username, password);
// 在关闭了数据库的自动提交后,此处会默认开启事务
connection.setAutoCommit(false);
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
String sql1 ="insert into test () values()";
String sql2 = "select *from test";
preparedStatement = connection.prepareStatement(sql1);
preparedStatement.executeUpdate();
//出错,全错,不会提交
int x = 10/0;
preparedStatement = connection.prepareStatement(sql2);
resultSet = preparedStatement.executeQuery();
// 提交事务
connection.commit();
while (resultSet.next()){
System.out.print(resultSet.getInt("id")+"\t"); //在不知道类型的情况下可以用getObject()获取
System.out.print(resultSet.getObject("name")+"\t");// 里面的参数要和数据库一一对应
System.out.println(resultSet.getObject("age")+"\t");
}
System.out.println("执行成功");
} catch (SQLException throwables) {
// 若失败就回滚
try {
connection.rollback();// 回滚事务
}catch (Exception e){
}
throwables.printStackTrace();
} finally {
// 6.释放连接,关闭资源
resultSet.close();
preparedStatement.close();
connection.close();
}
}
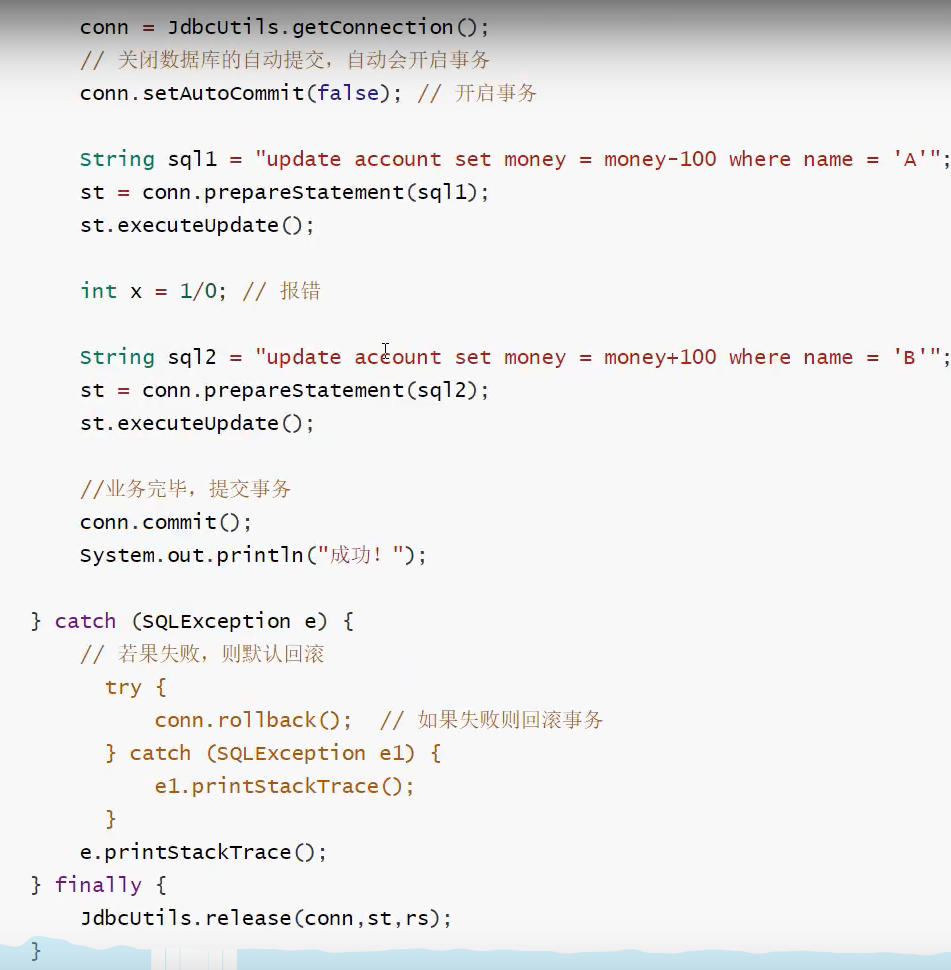
)
数据库连接池
由于数据库的连接的创建和释放十分的浪费资源(实际上我运行出来释放是不占时间的,创建链接耗费的时间较长)
有开源的实现的数据库连接池的操作
- DBCP
- C3P0
- Druid 这个是阿里巴巴的
使用这些数据库连接池之后,编码过程中就不需要编写连接数据库的代码了
每个不同的连接池需要导入不同的包
-
DBCP
-
commons-dpcp-1.4.jar
-
commons-pool-1.6.jar
-
有固定的配置文件,就是url,username,password之类的数据源(创建在src目录下)
-
同样也是放入在项目里面的新建lib目录下
使用:
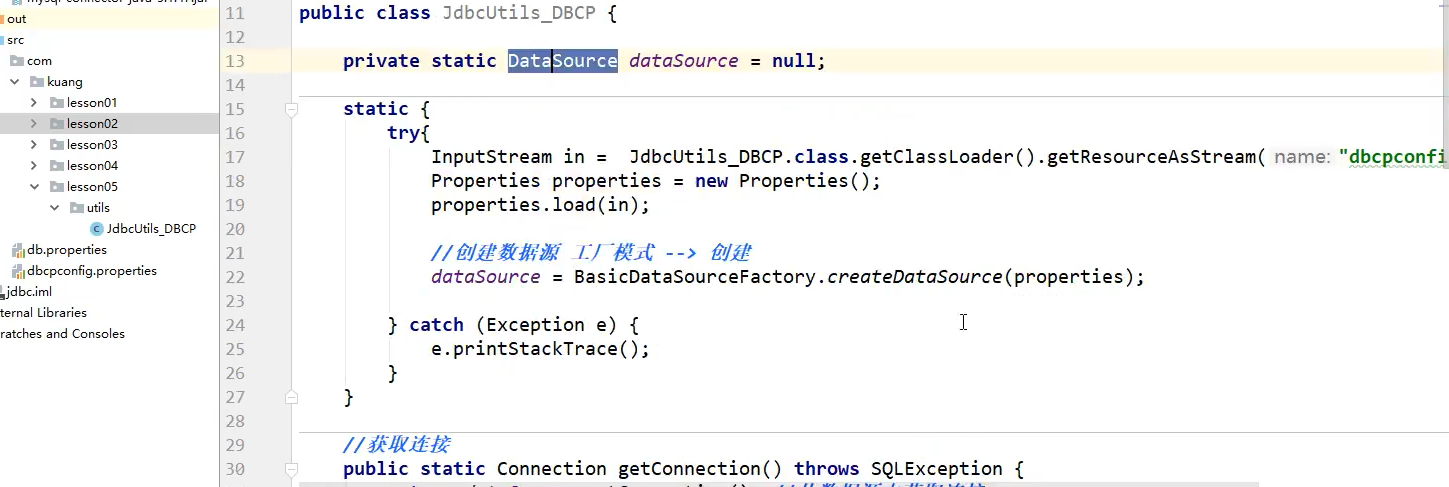
-
-
C3P0: 大同小异:这个的配置文件是.xml,xml程序运行的时候会自动读取,就不需要load读取了
![image-20210821234452291]
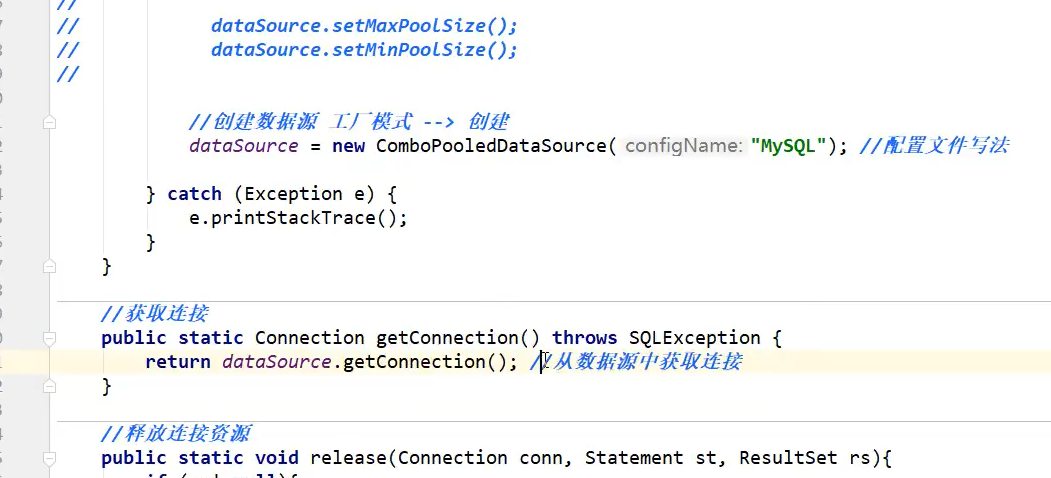
)
- Druid
数据库连接池相只是相对于在读取配置文件,数据源的创建改变了,对于连接数据库的连接和释放接口都是一样的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号