微服务-19 使用Prometheus来作为Kubernetes集群的监控
Prometheus介绍
简介:
Prometheus 是一款基于时序数据库的开源监控告警系统,非常适合Kubernetes集群的监控。Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux系统信息(包括磁盘、内存、CPU、网络等等)。Promethus有以下特点
- 支持多维数据模型:由度量名和键值对组成的时间序列数据
- 内置时间序列数据库TSDB
- 支持PromQL查询语言,可以完成非常复杂的查询和分析,对图表展示和告警非常有意义
- 支持HTTP的Pull方式采集时间序列数据
- 支持PushGateway采集瞬时任务的数据
- 支持服务发现和静态配置两种方式发现目标
- 支持接入Grafana
架构图:
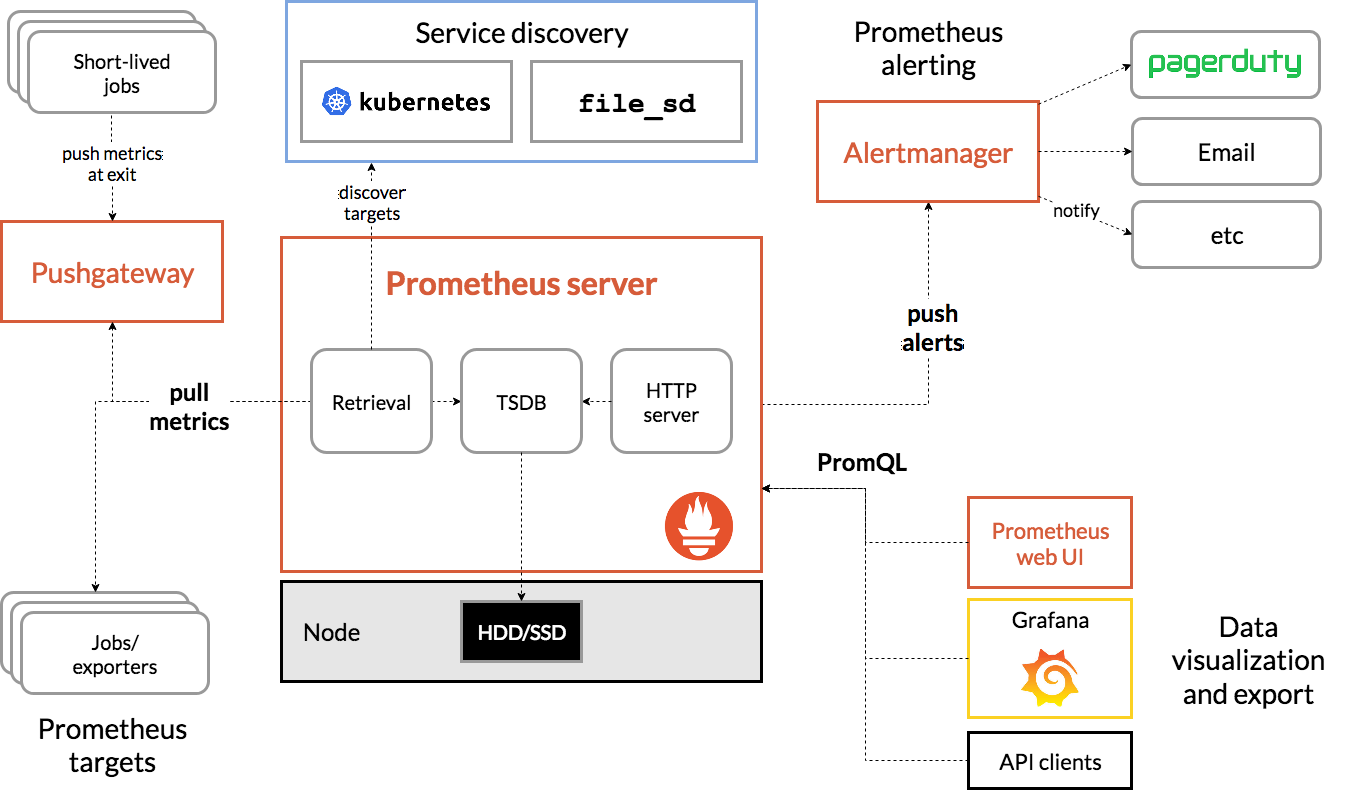
1. Prometheus Server
主要负责数据采集和存储,提供PromQL查询语言的支持。包含了三个组件:
- Retrieval: 获取监控数据
- TSDB: 时间序列数据库(Time Series Database),我们可以简单的理解为一个优化后用来处理时间序列数据的软件,并且数据中的数组是由时间进行索引的。具备以下特点:
- 大部分时间都是顺序写入操作,很少涉及修改数据
- 删除操作都是删除一段时间的数据,而不涉及到删除无规律数据
- 读操作一般都是升序或者降序
- HTTP Server: 为告警和出图提供查询接口
2. 指标采集
- Exporters: Prometheus的一类数据采集组件的总称。它负责从目标处搜集数据,并将其转化为Prometheus支持的格式。与传统的数据采集组件不同的是,它并不向中央服务器发送数据,而是等待中央服务器主动前来抓取
- Pushgateway: 支持临时性Job主动推送指标的中间网关
3. 服务发现
- Kubernetes_sd: 支持从Kubernetes中自动发现服务和采集信息。而Zabbix监控项原型就不适合Kubernets,因为随着Pod的重启或者升级,Pod的名称是会随机变化的。
- file_sd: 通过配置文件来实现服务的自动发现
4. 告警管理
通过相关的告警配置,对触发阈值的告警通过页面展示、短信和邮件通知的方式告知运维人员。
5. 图形化展示
通过ProQL语句查询指标信息,并在页面展示。虽然Prometheus自带UI界面,但是大部分都是使用Grafana出图。另外第三方也可以通过 API 接口来获取监控指标。
部署:
步骤一:部署 Prometheus Operator
-
添加 Prometheus Helm 存储库:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts helm repo update
-
安装 Prometheus Operator:
helm install prometheus prometheus-community/kube-prometheus-stack
步骤二:访问 Prometheus 和 Grafana Dashboard
-
查看 Prometheus 服务的 ClusterIP 地址和端口:
kubectl get svc prometheus-kube-prometheus-prometheus -n monitoring
2.查看 Grafana 服务的 ClusterIP 地址和端口:
kubectl get svc prometheus-grafana -n monitoring
3.通过浏览器访问 Prometheus 和 Grafana Dashboard。
步骤三:配置监控目标
Prometheus Operator 会自动发现 K8s 集群中的服务和资源,创建相应的监控目标配置。可以通过编辑 PrometheusRule、ServiceMonitor 等资源来自定义监控目标。
步骤四:Instrumen 你的代码
在应用程序中引入 Prometheus 客户端库,生成指标数据供 Prometheus 收集。以下是一个 Python Flask 应用的示例代码:
from prometheus_client import Counter
from flask import Flask
app = Flask(__name__)
c = Counter('requests_total', 'Total number of requests')
@app.route('/')
def hello():
c.inc()
return "Hello World!"
if __name__ == '__main__':
app.run()
步骤五:设置报警规则
通过 Prometheus 的 Alertmanager 组件设置报警规则,定义报警接收方式。可以编辑 PrometheusRule 资源来配置报警规则。
步骤六:集成 Grafana
- 登录 Grafana Dashboard。
- 添加 Prometheus 数据源,填写 Prometheus 服务的 URL。
- 创建仪表盘并可视化监控数据。
步骤七:验证监控效果
观察 Prometheus 中的指标数据是否在不同监控目标之间流动,以及是否能够成功触发报警规则。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号