
AI成你的追剧“嘴替”?一键生成专属弹幕!
大模型生成个性化剧集评论
嘿,你知道吗?新剧一出,评论区总是热火朝天!但你知道吗,这些热评可能都是大模型的杰作哦!我们利用先进的大模型技术,通过提取视频关键信息,为你量身定制个性化剧评。无论是剧情分析还是演员表现,都能轻松应对。从此,你不再是追剧的旁观者,而是评论区的主角!快来试试吧,让你的剧评也火起来!
实现方案
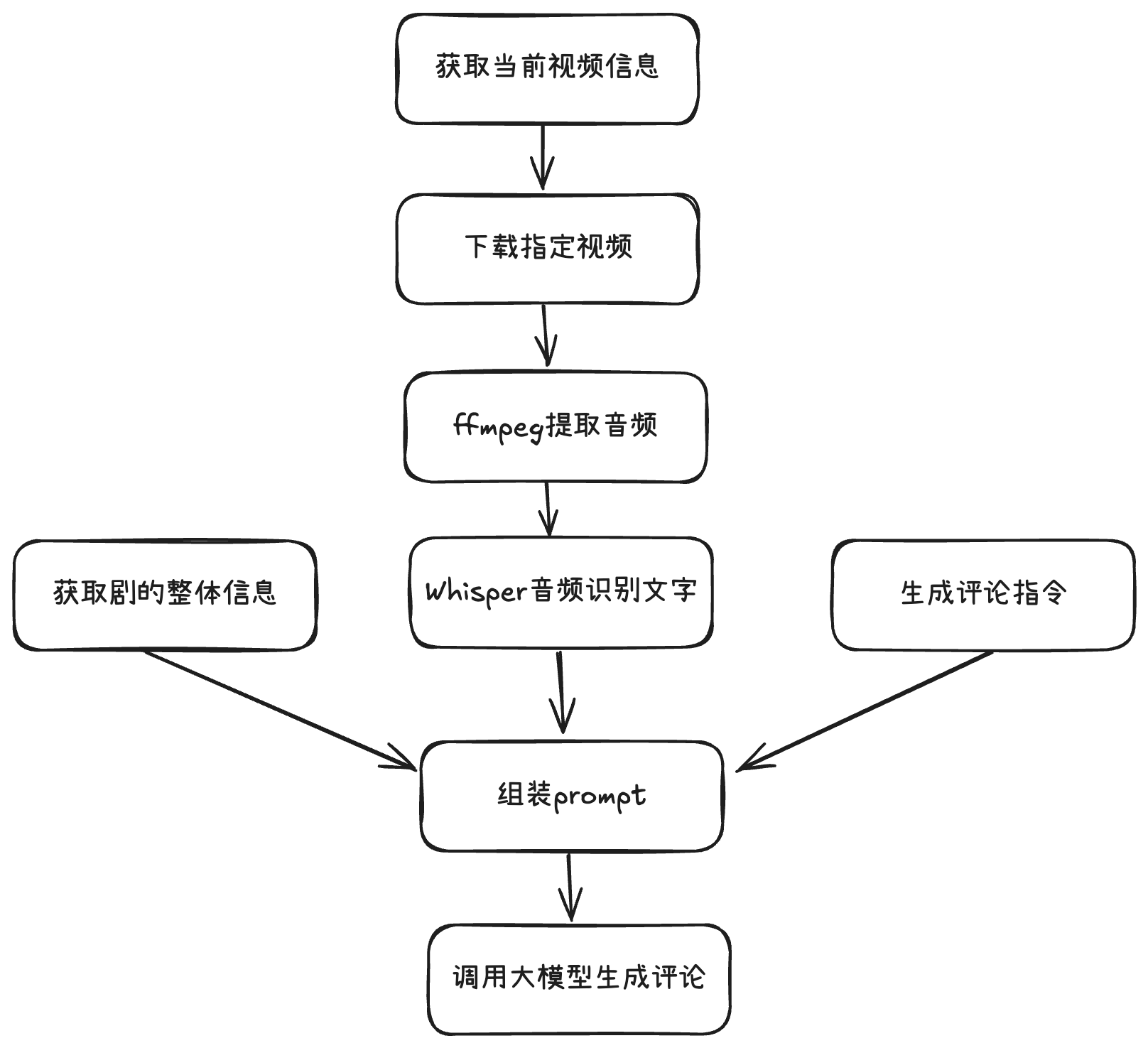
总体上,我们考虑利用大语言模型对指定视频来生成评论。
逆向推导
首先,我们先聚焦目标,以终为始,逆向推导实现方案。
- 首先,大模型接收文字prompt信息,可以按指令生成评论数据
- 再考虑,文字prompt需要包含指定视频的关键信息,给大模型来提供情境
- 再考虑,视频关键信息提取,我们可以得到连续剧整体的简介信息,包含剧情、演员等
- 再考虑,每一集的信息也需要包含,有两种方式
- 方式一:提取当集视频的人物对白语言,识别出台词文本,当做关键信息
- 方式二:视频内容识别,识别视频语意,输出为文字,当做关键信息
- 将视频的【所在剧整体信息】+【当前集信息】+【生成评论指令】组装成prompt,调用大模型生成评论
实现流程
正向整理一下,实现流程
视频信息,我们采用获取人物对白方式实现(适合有对白的剧哦),不采用难度更大的视频内容识别方案。
实现效果
组装的prompt
你是一名短剧观众评论生成器,现在需要你根据给定的短剧信息和当集台词,生成一批有趣、生动的评论数据。
#### 短剧信息
短剧名:短剧example
短剧简介:海外M国姜氏集团的千金姜思凝遭姜家养女姜思雪陷害,和M国赌王秦深一夜温存、失去双亲、险些丧命。六年后,姜思雪成为秦深妻子,姜思凝便化身荷官袁浅潜入秦深的赌场,意图色诱秦深并使得姜思雪失去一切。渐渐地,六年前的真相浮出水面,秦深袁浅的感情也发生了变化。
#### 当前集信息
- 集数:14
- 总集数:60
- 当集台词(节选):
大家都以为我和思念很恩爱大家都是假象不过是他在人前做出的样子吧这才是真相我从小没了爸妈又没能力胡可只能靠他养活所以才听他的话是没有他打吧一起说我不想他不是说他不屌所以这和我有什么关系吗我全本以为师爷你会心疼不然你回来了刚刚还在这块不知道去哪了谁也还在忙吗嗯一直没出来了你凭什么决斗或心疼你休息我们现在亲密无情共处于是你还没有把我推开将自己知道吧你处星期日的接近他原来打的是他老公的出去会让他知道吗老公元在书房
#### 评论生成要求
1. 生成的评论要 **有趣、生动、贴近剧情**,可包含惊讶、吐槽、心疼、磕CP、期待后续等情绪。
2. 评论要简短(1-2 句话),避免跑题。
3. 评论格式为 JSON 数组,每条评论包含:
- id:评论唯一编号(从1开始递增)
- parentid:若为顶层评论则为0,若为回复则为对应父评论id
- content:评论内容
4. 回复(盖楼)层级为 1-5 层,适当随机生成。
5. 输出只需返回 JSON,不要额外解释。
#### 输出示例
[
{
"id": 1,
"parentid": 0,
"content": "这段剧情太虐了,思凝好可怜!"
},
{
"id": 2,
"parentid": 1,
"content": "对啊,看得我都想哭了"
},
]
llm返回的内容
[
{
"id": 1,
"parentid": 0,
"content": "这集信息量好大!原来秦深和姜思雪的恩爱都是演出来的?豪门水太深了"
},
{
"id": 2,
"parentid": 1,
"content": "回复楼上:而且姜思雪说自己靠秦深养活才听话,细思极恐啊,这婚姻根本就是交易吧"
},
{
"id": 3,
"parentid": 0,
"content": "袁浅听到这些心里肯定很复杂,既恨秦深又忍不住心疼?这感情线太带感了"
},
{
"id": 4,
"parentid": 3,
"content": "确实!她本来是想报复的,现在发现仇人可能也是受害者,这反转绝了"
},
{
"id": 5,
"parentid": 0,
"content": "最后那句'老公元在书房'是不是在暗示什么?感觉下集要有大事发生"
}
]
代码实现
利用ffmpeg提取音频、Whisper实现语音文字提取
import os
import requests
import subprocess
import tempfile
import time
def download_video(video_url, save_path):
"""Downloads a video from the given URL to the specified local path."""
save_dir = os.path.dirname(save_path)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
try:
response = requests.get(video_url, stream=True)
response.raise_for_status()
with open(save_path, 'wb') as file:
for chunk in response.iter_content(chunk_size=8192):
file.write(chunk)
print(f"Video downloaded successfully: {save_path}")
return True
except requests.exceptions.RequestException as e:
print(f"Failed to download video: {e}")
return False
def extract_audio_fast(video_path, audio_path):
"""快速提取音频,优化参数以提高处理速度"""
try:
# 使用更快的编码参数
cmd = [
'ffmpeg', '-y', '-i', video_path,
'-vn', '-acodec', 'pcm_s16le',
'-ar', '16000', # 16kHz是语音识别的最佳频率
'-ac', '1', # 单声道
'-threads', '4', # 使用多线程加速
audio_path
]
subprocess.run(cmd, check=True, capture_output=True, timeout=300) # 设置超时时间
print(f"Extracted audio to {audio_path}")
return True
except subprocess.CalledProcessError as e:
print(f"FFmpeg error: {e.stderr.decode()}")
return False
except subprocess.TimeoutExpired:
print("FFmpeg process timed out")
return False
except Exception as e:
print(f"Error extracting audio: {e}")
return False
def recognize_with_whisper(audio_path, model_size="small"):
"""
使用Whisper进行语音识别
参数:
audio_path: 音频文件路径
model_size: Whisper模型大小,可选"tiny", "base", "small", "medium", "large"
"""
try:
import whisper
# 记录开始时间
start_time = time.time()
# 加载模型
print(f"Loading Whisper {model_size} model...")
model = whisper.load_model(model_size)
print(f"Model loaded in {time.time() - start_time:.2f} seconds")
# 转录音频
print("Transcribing audio...")
result = model.transcribe(
audio_path,
language="zh",
fp16=False # 不使用FP16加速,兼容性更好
)
print(f"Transcription completed in {time.time() - start_time:.2f} seconds")
return result["text"]
except ImportError:
print("Whisper not installed. Install with: pip install openai-whisper")
return None
except Exception as e:
print(f"Whisper recognition error: {e}")
return None
def enhance_audio(audio_path):
"""增强音频质量以提高识别率"""
enhanced_path = audio_path + ".enhanced.wav"
try:
# 使用ffmpeg增强音频
cmd = [
'ffmpeg', '-y', '-i', audio_path,
'-af', 'highpass=f=200,lowpass=f=3000,afftdn=nf=-25',
'-ar', '16000',
'-ac', '1',
enhanced_path
]
subprocess.run(cmd, check=True, capture_output=True, timeout=60)
return enhanced_path
except Exception as e:
print(f"Audio enhancement failed: {e}")
return audio_path # 如果增强失败,返回原始音频
def parse_video_words_fast(video_path, whisper_model="small"):
"""快速解析视频中的语音"""
start_time = time.time()
# 创建临时音频文件
with tempfile.NamedTemporaryFile(suffix='.wav', delete=False) as temp_audio:
temp_audio_path = temp_audio.name
try:
# 提取音频
print("Extracting audio from video...")
if not extract_audio_fast(video_path, temp_audio_path):
return None
# 增强音频质量
print("Enhancing audio quality...")
enhanced_audio_path = enhance_audio(temp_audio_path)
# 识别语音
print("Starting speech recognition...")
result = recognize_with_whisper(enhanced_audio_path, model_size=whisper_model)
# 计算处理时间
end_time = time.time()
print(f"Processing completed in {end_time - start_time:.2f} seconds")
return result
finally:
# 清理临时文件
try:
os.unlink(temp_audio_path)
if os.path.exists(enhanced_audio_path) and enhanced_audio_path != temp_audio_path:
os.unlink(enhanced_audio_path)
except:
pass
# 如果已经有音频文件,可以直接使用这个函数
def recognize_audio_file(audio_path, whisper_model="small"):
"""直接识别音频文件"""
return recognize_with_whisper(audio_path, model_size=whisper_model)
if __name__ == '__main__':
# 测试代码
video_url = "https://vdept3.bdstatic.com/mda-qmi0r105nea78y1j/cae_h264/1734568349688083721/mda-qmi0r105nea78y1j.mp4?v_from_s=hkapp-haokan-nanjing&auth_key=1758003682-0-0-9803f157b3c7387bae1c64ccd9782b3f&bcevod_channel=searchbox_feed&pd=1&cr=0&cd=0&pt=3&logid=1282299422&vid=11024655518102530142&klogid=1282299422&abtest="
path = "./example.mp4"
download_video(video_url, path)
result = parse_video_words_fast(path, whisper_model="small")
if result:
print("识别结果:", result)
else:
print("未能识别出语音内容")
代码运行输出
识别结果: 接下來呢 給大家帶來一個棚刻搖滾這首歌的名叫做快樂打工人不希望你們在早上聽到我們的聲音突然間逐漸被時間偷走了三年Let me go當我離開出走偷偷離開門口一段不早的路上去散滿的白日夢於思考為一般的人從未感到孤獨失蹤不討厭學生是大流家的老賤變成一位出了社會社會會對我好點No no no no家人們一個大陸成長後的魔戀變成了面對面的欺騙純雜荒的不紅點被不把你一字放進去Oh 每一遍放著那圈跟著我念 發動再見忘記了 到夜上也忘記了時間轉過的空氣帶我回家失靈突然間我回到那個熟悉的房間突然間逐漸被時間偷走了三年Let me go當我離開出走偷偷到你家門口請請別說一亂打工人永遠的聲音各位去唱唱好嗎Come onShake itShake it說再見合一情過去的Oh 每一遍放著那圈跟著我念 發動再見忘記了 到夜上也忘記了時間轉過的空氣帶我回家失靈合一情過去的說抱歉我沒有想起的說再見和自己操演的說抱歉和曾經相愛過的人謝謝

 浙公网安备 33010602011771号
浙公网安备 33010602011771号