

洛谷P4915 帕秋莉的魔导书
题目背景
帕秋莉有一个巨大的图书馆,里面有数以万计的书,其中大部分为魔导书。

题目描述
魔导书是一种需要钥匙才能看得懂的书,然而只有和书写者同等或更高熟练度的人才能看得见钥匙。因此,每本魔导书都有它自己的等级\(a_i\)
,同时它也有自己的知识程度为\(w_i\),现在我们想要知道,一个等级为\(b_i\)的生物(...),可以从这些魔导书中得到多少知识。
然而不幸的是,每个生物并不知道自己确切的等级,只有一个等级的大致范围,你需要计算出这个生物获得知识程度的期望值。
输入格式
第一行两个正整数\(n,m\)代表起始书的个数,以及操作的个数。
以下\(n\)行,每行两个正整数\(a_i\)和\(w_i\),代表每本书的等级以及知识程度。
接下来的\(m\)行,每行\(2\)或\(3\)个正整数。
操作 1:格式:1 x y。含义:求等级为 [x, y] 的生物能获得的期望知识程度。
操作 2:格式:2 x y。含义:图书馆又收入了一本等级为\(x\),知识程度为\(y\)的魔导书。
输出格式
输出包含若干行实数,即为所有操作 1 的结果,答案保留四位小数。
说明/提示
对于\(30%\)的数据,保证\(1\leq\)所有输入的数字\(\leq 10^3\) 。
对于\(100%\)的数据,保证\(1\leq n,m \leq 10^5\),对于其他数字,保证在\(32\)位带符号整数范围内(保证运算中所有的数均在\(-2^{63}\)到\(2^{63}-1\)之间)。
思路
初步
首先我们考虑一种简单的情况,如果所有的等级都很小,我们可以对等级开一个数组 \(Lv\) ,遇到一本书,如果他的等级是\(a_i\),知识是\(w_i\)那么 Lv[a[i]]以及之后的元素+=\(w_i\),因为这本书对于所有
Lv更高的生物都有贡献。查询时,如果生物等级范围是[L,R],那么答案就是$$\frac{\sum_{i=L}^R Lv[i]}{R-L+1}$$可以看做每个等级的概率为\(\frac{1}{R-L+1}\),该等级所能获得的知识为Lv[i]。
我们只要维护分子部分,也就是区间加和区间查询,那么很明显可以用线段树解决。
进阶
让我们回到原题,原题给的等级范围是\(-2^{63}\)到\(2^{63}-1\),线段树空间爆炸,有没有什么机会呢,简单分析一下可以发现,由于书的数量和询问次数相对较少,那么这些数(等级)虽然很大,但分布很
稀疏,也就是说,存在大量元素,他们的信息是相同的,所以我们把相同信息的节点合并,并赋予其一个权值(区间长度),作为一个叶子,那么空间大大缩减。为了方便起见,我们把所有询问和书涉及到
的等级全部视为分割点(而不是只有书),因为这样不会让我们询问的时候出现端点在线段树叶子所代表的区间中间的情况。那么之前的思路几乎可以原封不动地套用上来。
我的算法钦定所有叶子代表的区间都是左开右闭的。(当然不一定要这么写)。
第一步:离散化。这里有一些细节,插入时询问左端点-1,右端点不变(因为s[R]-s[L-1]才是L~R的信息);还有,书的等级-1,看图理解。
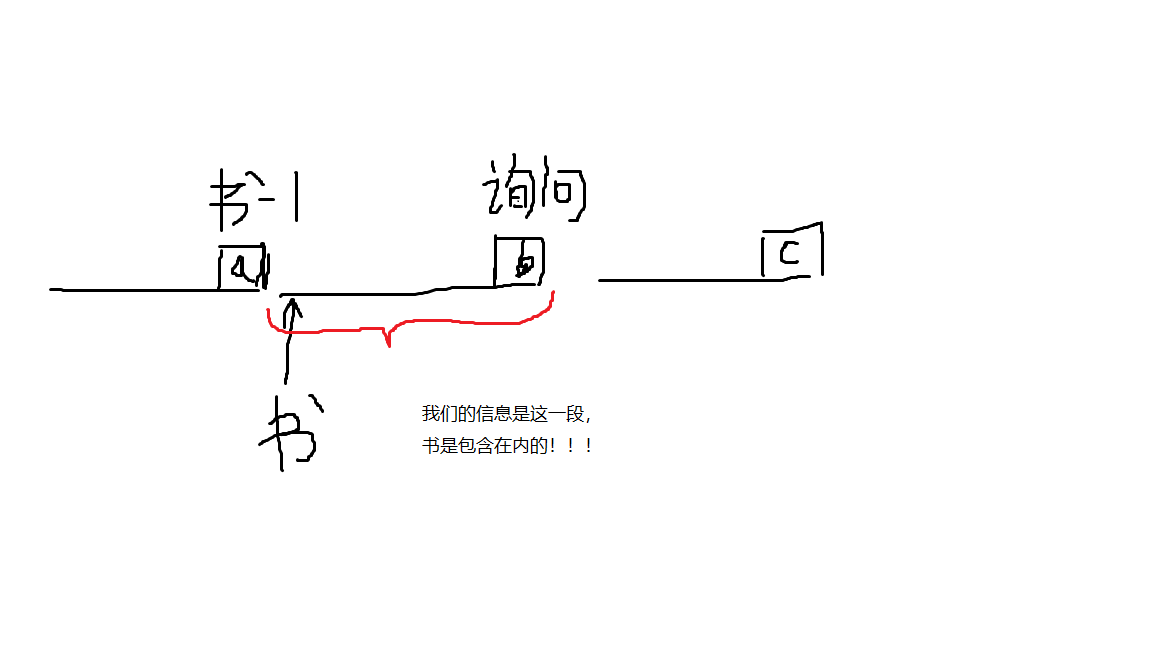
第二步:建树。每一个节点对应的权值为其区间长度。
剩下的就是线段树的常规操作了,大家自己去实现一下吧。以下是本蒟蒻的代码:
#include<cstdio>
#include<cstdlib>
#include<algorithm>
#define ll long long
#define maxn (int)1e6+10
using namespace std;
ll op[maxn][3],book[maxn][2];
ll data[maxn*3],d[maxn*3];
int cnt1=0,cnt2=0;
int id(ll x){
if(!x) return 0;
return lower_bound(d+1,d+cnt2+1,x)-d;
}
struct node{
int l,r;
ll tot,w,tag;
} tree[maxn<<4];
void update(int x){
tree[x].tot=tree[x<<1].tot+tree[x<<1|1].tot;
}
void pushdown(int x){
tree[x<<1].tot+=tree[x<<1].w*tree[x].tag;
tree[x<<1|1].tot+=tree[x<<1|1].w*tree[x].tag;
tree[x<<1].tag+=tree[x].tag;
tree[x<<1|1].tag+=tree[x].tag;
tree[x].tag=0;
}
void build(int x,int left,int right){
tree[x].l=left;tree[x].r=right;
if(left==right){
tree[x].w=d[left]-d[left-1];
tree[x].tag=tree[x].tot=0;
return;
}
int mid=left+right>>1;
build(x<<1,left,mid);
build(x<<1|1,mid+1,right);
tree[x].w=tree[x<<1].w+tree[x<<1|1].w;
return;
}
void modify(int x,int left,int right,ll key){
if(left>right) return;
if(tree[x].l>=left&&tree[x].r<=right){
tree[x].tot+=key*tree[x].w;
tree[x].tag+=key;
return;
}
pushdown(x);
int mid=tree[x].l+tree[x].r>>1;
if(left<=mid) modify(x<<1,left,right,key);
if(right>mid) modify(x<<1|1,left,right,key);
update(x);
return;
}
ll query(int x,int left,int right){
ll ans1=0,ans2=0;
if(left>right) return 0;
pushdown(x);
if(tree[x].l>=left&&tree[x].r<=right){
return tree[x].tot;
}
int mid=tree[x].l+tree[x].r>>1;
if(left<=mid) ans1=query(x<<1,left,right);
if(right>mid) ans2=query(x<<1|1,left,right);
update(x);
return ans1+ans2;
}
int main(){
int n,m,i;
double ans;
// freopen("in.txt","r",stdin);
// freopen("out.txt","w",stdout);
scanf("%d%d",&n,&m);
for(i=1;i<=n;i++){
scanf("%lld%lld",&book[i][0],&book[i][1]);
data[++cnt1]=book[i][0]-1;
}
for(i=1;i<=m;i++){
scanf("%d%lld%lld",&op[i][0],&op[i][1],&op[i][2]);
if(op[i][0]==1){
data[++cnt1]=op[i][1]-1;
data[++cnt1]=op[i][2];
}
else{
data[++cnt1]=op[i][1]-1;
}
}
sort(data+1,data+cnt1+1);
for(i=1;i<=cnt1;i++){
if(data[i]>data[i-1]) d[++cnt2]=data[i];
}
build(1,1,cnt2);
for(i=1;i<=n;i++){
modify(1,id(book[i][0]-1)+1,cnt2,book[i][1]);
}
for(i=1;i<=m;i++){
if(op[i][0]==1){
ans=query(1,1,id(op[i][2]))-query(1,1,id(op[i][1]-1));
ans=ans/((op[i][2]-op[i][1]+1)*1.0);
printf("%.4lf\n",ans);
}
else{
modify(1,id(op[i][1]-1)+1,cnt2,op[i][2]);
}
}
return 0;
}
 浙公网安备 33010602011771号
浙公网安备 33010602011771号