JIT即时编译浅谈
背景
因为最近看**流量调度发布预热**,要想弄清楚原理,JIT是绕不过的。
简介
JIT(just in time)即时编译编辑器。诞生也是为了提高java的执行速度。
java的**编译机制**是,javac将java源代码转换为java字节码,JVM会解释字节码再编译为本地机器码。
解释器用来识别字节码指令,并将字节码指令映射编译为机器指令之后调用操作系统来执行程序。这个编译过程是在程序运行期间完成的,边解释边执行,虽然实现了java跨平台的特性,弊端就是严重拖慢了程序执行的效率,所以诞生了**JIT即时编译**提高执行速度。
JIT编译过程
当JIT 编译启用时(默认是启用的), JVM 读入.class 文件解释后,将其发给 JIT 编译器。JIT编译器将字节码编译成本机机器代码。 工作原理如下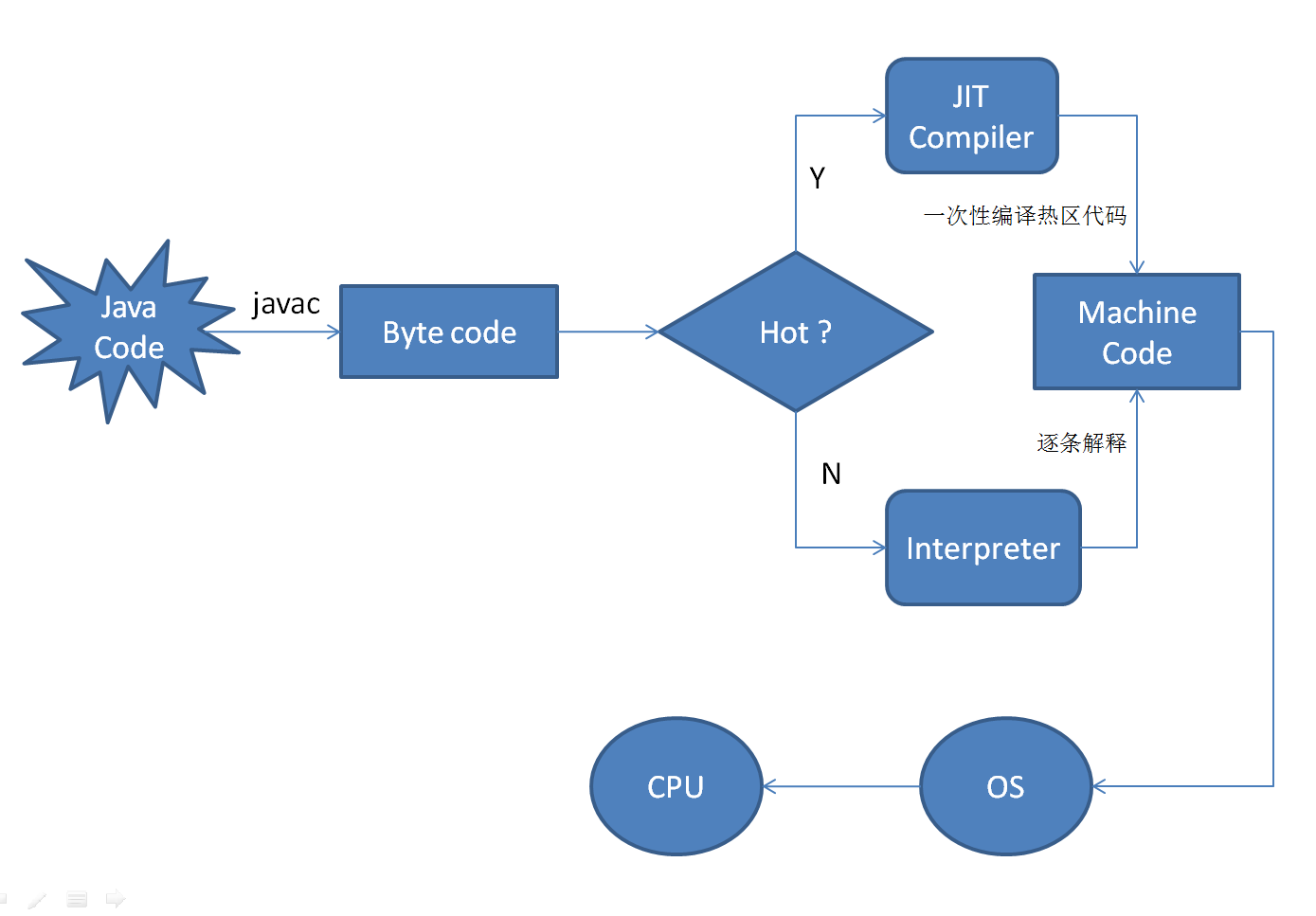
编译流程
解释器解释执行字节码,其真实操作的是内存中的方法栈与局部变量表。
java程序的执行伴随着栈帧的弹栈出栈(方法调用)以及pc寄存器的顺序执行及跳转。即时编译的第一步就是要探测热点代码,实质就是统计某段代码频繁调用的次数是否达到指定阈值,达到就会触发即时编译。(HOT SPOT 编译)
有两个热点代码探测方法
> 次数级别热点探测,jvm 通过统计 每个方法调用栈的栈顶 一个方法栈帧的弹出频率 来作为一个指标。有两种方法,第一使用精确的计数器进行精确计数,超过阈值触发编译。二是记录一段时间内方法调用次数(方法调用的频 率) 超过阈值触发编译。并存在热度衰减,超过一定时间范围没有继续调用 该方法则会 将其值减半。 二者各有优缺点,前者 精确计算开销大,后者不够严谨但适用大多数情况。**一旦超过阈值将触发方法级别的即时编译,以整个方法为编译对象。 **
>循环体级别的热点探测,适用回边计数器来进行计数,pc寄存器向后跳转一次记为 一个回边。 当每次跳转时,都会触发计数器加一,并将计数器的值与该循环体所在方法的频率计数器的值相加。其值超过阈值就会触发即时编译,若没超过阈值并不存在半衰,继续以解释形式执行代码。**循环体级别的探测,也是会将整个方法进行编译的。**
即时编译:
一旦判定代码段是热点代码,则解释器将发送一次请求编译器,进行编译,在编译成功之前 解释器仍旧运行着。 等编译完成后,直接将pc寄存器中方法的调用地址进行替换,替换为编译后的方法地址。
这一过程就是 栈上替换---OSR.
这个过程由java字节码执行引擎中的 两个编译器完成,C1与C2编辑器,一个用于客户端,一个用于服务器。 c1相比较与c2他的编译优化程度要低一些,c2将针对服务器进行一些激进的优化,以保证代码在服务器运行时性能更加突出。
编译模式
JVM何时编译,不同的JVM或者JVM不同的模式,编译的阈值不同,一般有以下几种编译模式:
- **纯编译执行** 使用-Xcomp启动参数,每段代码第一次运行就会被缓存编译后的机器码,弊端就是启动耗时非常长
- **client模式** c1编译器,此模式会使程序直接进入编译执行阶段,启动速度快但是后续的执行效率低
- **server模式** c2编译器,服务器模式是使程序运行后性能尽可能高。启动阶段会收集较多的代码运行信息,代码执行效率高,但是启动耗时长。
分层编译
在JVM使用参数-XX:+TieredCompilation参数开启。只能运行在服务器模式中。在启动初期使用客户端c1编译器缓存热点代码,系统稳定后使用服务器c2编译器继续优化性能。
>JDK7之后, JVM Server模式下将会开启分层编译(Tiered Compilation)策略, 由C1编译器和C2编译器相互协作共同来执行编译任务。分层编译策略将会根据编译器执行编译、优化的规模与耗时, 划分出不同的编译层次, 从而提高编译效率。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号