mysql、PikaDB的使用方法和优化策略
Mysql
字段选择
- 尽量选用INT,BIGINT,4字节8字节的消耗小于varchar。字符串选择VARCHAR增加拓展性。
- 时间应使用时间戳BIGINT存储,不使用DATETIME。
- 不使用BLOB字段,如有需要,应以主键为Key写入KV数据库。
- 不存储长文本进行查询,如有需要,考虑使用ES。
分表
应控制住表的行数,主要考虑垂直拆分和水平拆分。原则是:属性不同的表垂直拆,拆了如果还是大表,再按时间、UID前缀等进行拆分。
垂直拆分:按业务维度分离(用户表 vs 订单表)。水平拆分:Sharding策略(范围、哈希、时间)
- 无限递增的大表应配备清理机制。如聊天记录表。
- 多考虑使用日期进行分表,简单且有效。用户表考虑使用UID前缀。
索引和查询优化
索引在读多写少场景使用索引,能极大提高查询效率。索引文件的本质是B+树,我们可以从二叉树的原理分析查询语句性能。
- 应结合高频sql语句,选用查询频率高,且差异大的字段为索引。如:UID,创建时间。
举例,这是一张订单表,忽略了分表细节。
create table t_order
(
order_id bigint unsigned not null primary key COMMENT '主键。公司订单号',
platform varchar(32) not null default '' COMMENT '平台名称',
channel varchar(32) not null default '' COMMENT '渠道',
price bigint not null default 0 COMMENT '价格',
payment integer not null default 0 COMMENT '支付类型',
third_party_order_id varchar(256) default null COMMENT '第三方订单号',
pay_channel varchar(256) not null default '' COMMENT '支付渠道',
game_uid varchar(256) not null default '' COMMENT '业务方UID',
product_id varchar(256) not null default '' COMMENT '商品PID',
order_status integer not null default 0 COMMENT '订单状态',
item_id varchar(256) not null default 0 COMMENT '道具id',
created_at bigint not null default 0 COMMENT '创建时间',
updated_at bigint not null default 0 COMMENT '更新时间',
deleted_at bigint default 0 COMMENT '删除时间',
KEY `idx_uid` (`game_uid`) USING BTREE,
KEY `idx_third_order_id` (`third_party_order_id`) USING BTREE
)ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT 'order';
常用sql语句为:
按订单号:order_id = ?
丢失订单号时,按按uid+第三方订单号:product_id = ? AND game_uid = ? AND platform = ? AND order_status = ?
检查该订单是否已经被核销过:third_party_order_id = ?
三条语句分别命中了三个索引。最常用的根据主键查询订单,以及命中game_uid和third_party_order_id。
- 语句应触发索引,避免锁表。也要注意避免索引失效,编写完成后应使用EXPLAIN检查sql语句。
常见的索引失效场景:
- 联合索引中,跳过1直接使用2,3号索引。
- 使用左模糊查询:LIKE'%abc',会导致索引失效
- 不要对索引列进行计算:WHERE YEAR(create_time) = 2023。应在程序中提前计算好2023年的范围。
- 对字符串类索引要加单引号,避免自动类型转换导致索引失效。
- 使用“OR”时,如果有任一条件不是索引,则索引失效。
EXPLAIN可进行sql分析,重点关注type字段。 - key:触发了哪个索引
- rows:扫描行的数量。
- type:ALL(全表扫描)→ index(只遍历索引树) → range(范围查询) → ref(非唯一索引) → eq_ref → const(唯一索引)
- Extra:Using filesort(需优化)、Using index(覆盖索引)
- 如有字符串索引匹配需求,考虑使用ES或本地存储库。
一个性能优秀的本地存储,项目上用于对玩家昵称进行模糊搜索:github.com/blevesearch/bleve/v2
加缓存
当实在无法优化时,对于读多写少的表考虑使用缓存。介绍几种常见的场景:
- 内存缓存
当数据实时性不重要时,将上一次读表的结果缓存,并设置一定时间后数据过期,能极大减少读表频率。 - 读Redis写Mysql
是移动互联网刚兴起时非常流行的架构。写Mysql,通过中间件捕获binlog直接写kafka,服务只需消费kafka并写入Redis。
性能介于直接使用mysql和使用Pika之间。老项目若mysql无法迁移可以选用,新项目可以考虑直接使用Pika存储。
Pika是一个性能优秀的KV持久化数据:https://github.com/OpenAtomFoundation/pikiwidb/wiki/pika-介绍
mysql观测
开启慢查询日志
SET GLOBAL slow_query_log = ON;
SET GLOBAL long_query_time = 1; -- 超过1秒的记录
查看当前sql
SHOW processlist;
查看索引使用统计
-- 查看未使用的索引
SELECT * FROM sys.schema_unused_indexes;
RocksDB系存储
KV系存储的核心是数据结构,结构选对了,性能就优化上来了。RocksDB只有KV一种数据结构,Pika对RocksDB的底层KV数据结构进行封装,所以上层结构就很显而易见了。
下面介绍Pika和Redis的数据结构:
| string | list | hash | zset | set | |
|---|---|---|---|---|---|
| Pika | KV | 分开存,记录首尾 | 分开存,使用统一前缀 | 分开存,利用RocksDB的按序扫描特性 | 分开存,依赖RocksDB的键唯一性实现去重 |
| Redis | 数字或字符串 | 压缩列表、双链表 | 压缩列表、散列表 | 跳表、散列表 | 整数集、哈希表 |
所以Pika更适合使用string、hash对proto进行序列化后存储,因为数据会落磁盘,成本比Redis更低。Pika单点支持20W QPS,性能比mysql更好。
list常用于消息队列建议使用kafka。set可用Redis进行去重,Pika会前缀匹配所有Block性能很差不要用。zset常用于排行榜使用Redis,Pika同样会扫描所有Block不要用。
RocksDB架构
RocksDB将数据分为多个block,多个数据块组合成一个SST文件。每个SST的被放置在其中一层。每次进行Compact,会使用LRU算法将不常用的SST落到更低的层级。
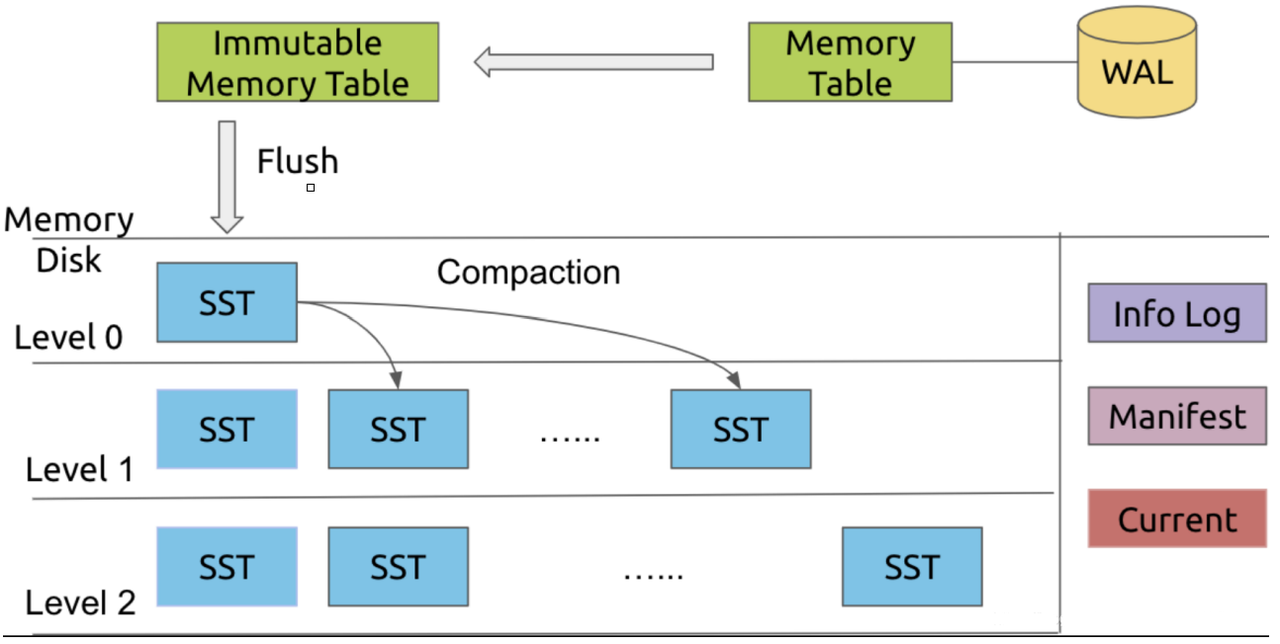
- 数据会先被写入到MemTable,这是一个跳表实现的内存结构。写满后转为只读状态,等待刷盘成SST文件。
- SST文件是磁盘上的不可变有序文件,由以下成员组成:
- Data Blocks:实际存储,按Key进行排序
- Index Block:记录每个Data Block的起始Key和偏移量。
- Footer:元数据(索引、过滤器位置等)。
- Block是SST文件中的最小存储单元,由以下成员组成:
- Key-Value Entries:有序键值对。
- Restart Points:每隔若干Key记录一次绝对位置,加速二分查找。
- Trailer:包含压缩类型和CRC校验码。
Leveled Compaction
将高层SST文件刷到低层的过程。还会合并旧文件以减少查询需要访问的文件数。
查找
通过Index Block定位目标Data Block,再从磁盘或缓存中加载Data Block,在Block中通过二分查找定位Key。
概述协作流程为:
Client->>MemTable: 写入数据(Put)
MemTable->>SST: MemTable写满后Flush为SST文件
SST->>Block: SST文件按Block存储数据
Client->>Block: 读取时通过Index定位Block
写放大
由于MemTable的数据会被刷到磁盘,SST文件会被刷到低层,所以会存在数据被写多次。
读放大
由于会分为多个SST文件,所以查询时可能会读多个SST文件。
空间放大
一个Key可能会存在于多个SST文件中。
过期时间
对RocksDB使用过期时间不是个好决定。因为SST中的数据是不能删除的,所以Pika只是通过字段标记其过期时间,过期后数据仍然会占用存储空间。对于临时数据,使用Redis是更好的选择。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号