方格图路径计数 dp 的反射路径优化
很拗口的名字,其情景是这样的:
我们有一个点 \(B(n,m)\),需要求原点 \(A\) 到这个点的路径条数(限制只能向右、上走)。
平凡的题目做法很简单,我们一共走 \(n+m\) 步,其中 \(n\) 步向右,方案数 \(\binom {n + m} n\)。
但是进阶版的题目会给出一些限制,比如给出两条直线,要求不能碰到这两条直线。
如下图:\(n=6,m=3\),不能碰到 \(l_1:y=x+1,l_2:y=x-4\)。那么我们的路径有以下可能,箭头表示方向。
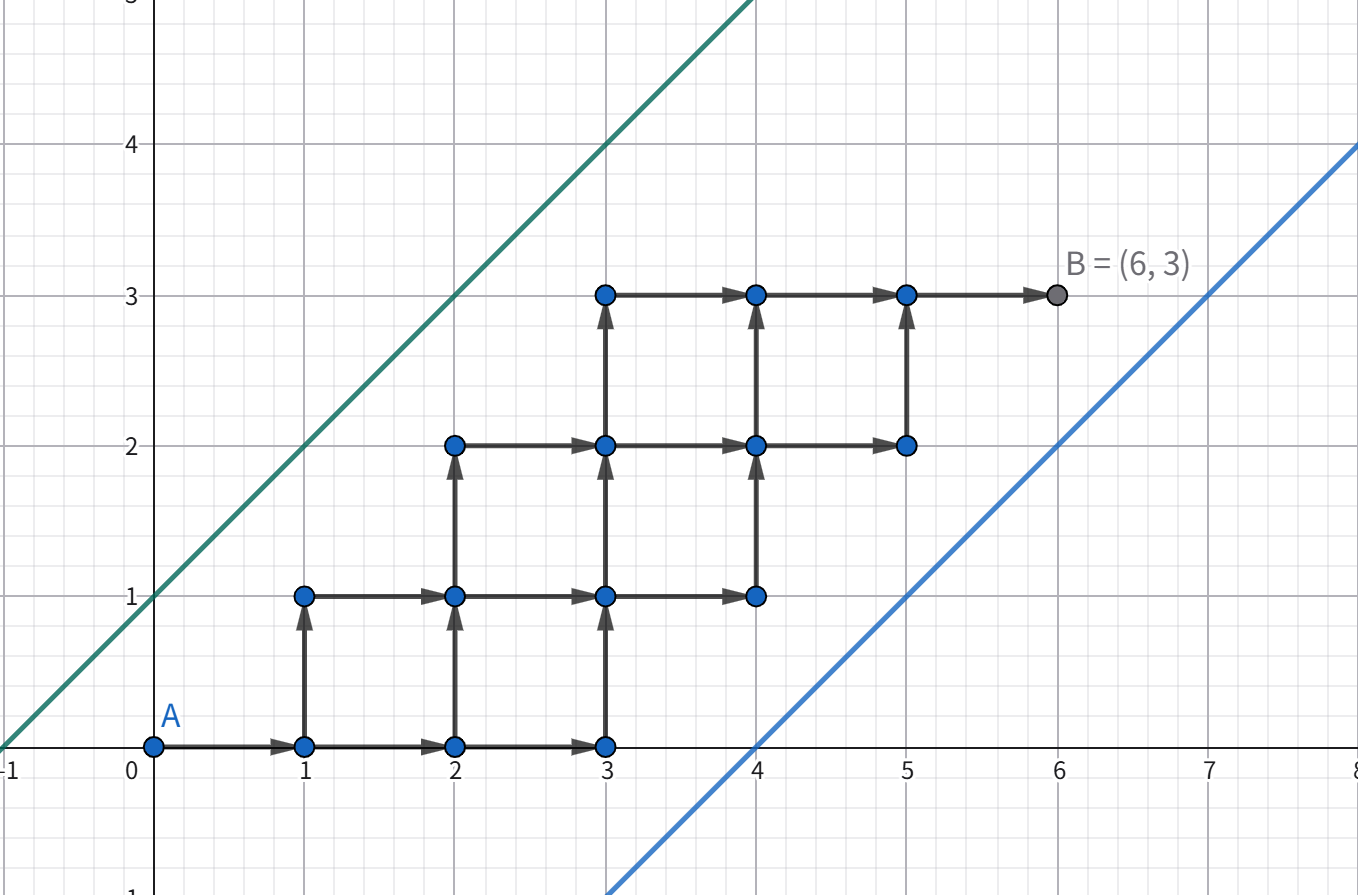
做法
Part 1
我们正难则反,考虑容斥,扔掉那些碰到 \(l_1, l_2\) 的路径,从简单入手,先考虑碰到 \(l_1\) 的直线,如图中黑色线:
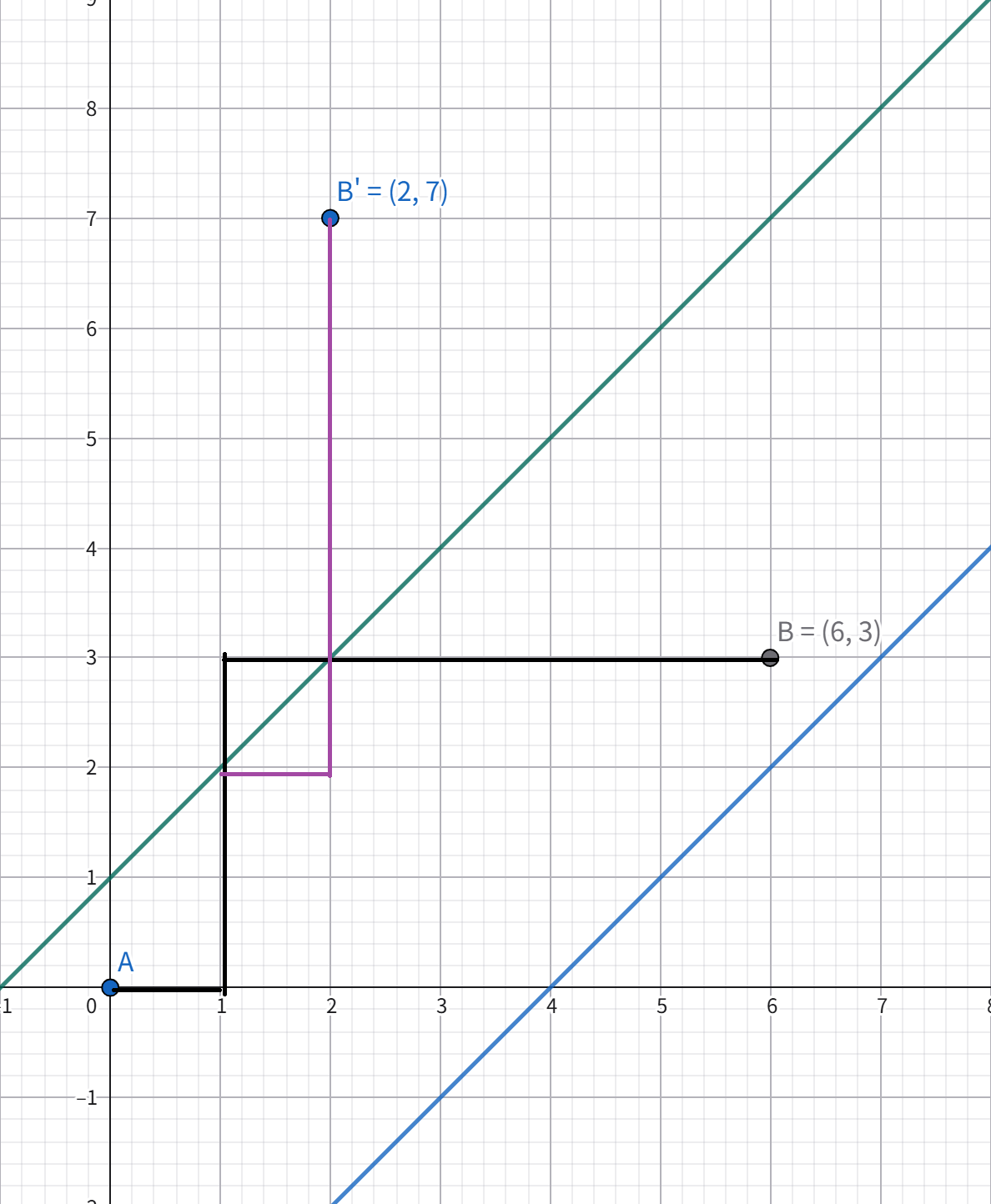
但这个碰到 \(l_1\) 太神秘了,而且原点和 \((n,m)\) 都在一侧,这让我们很难办,那我们如果有一个在 \(l_1\) 上方的点,此时,我们一条从原点到这个点的路线一定是经过 \(l_1\) 的。
我们考虑将碰到 \(l_1\) 的直线与这样的路径相对应,或者说用这种路径来生成所需路径。
我们发现,我们将原本路径从第一次碰到 \(l_1\)以后的部分都关于 \(l_1\) 做翻折(这个是否第一次不重要,只需要固定一个位置开始翻),形成图中紫色路径。那么,得到的路径终点为 \(B\) 关于 \(l_1\) 的对称点 \(B'\),我们发现这是一个一一映射,也就是只需要对原点到 \(B'\) 的路径计数即可,这同我们开始提到的平凡做法。
只碰到 \(l_2\) 直线同理,将 \(B\) 关于 \(l_2\) 对称得到 \(C\) 即可。
我们成功地分别算出了碰到 \(l_1\) 和 \(l_2\) 的方案数。
Part 2
我们定义一个序列,\(1212122211121 \cdots\) 表示路径碰到两条线的整个顺序。那么我们现在可以分别计算出序列中含有 \(1\)、含有 \(2\) 的个数了。同时,我们发现连续经过一条直线多次的情况已经被涵盖,那么下文讨论的序列都是将连续的 \(1\) 或 \(2\) 缩成一个之后的序列。
令 \(f(S)\) 碰线序列包含子串 \(S\) 的序列集合。答案应为:总情况数 - 碰到 \(l_1\) - 碰到 \(l_2\) + 既碰到 \(l_1\) 又碰到 \(l_2\)。即:
以此类推,每次拆开最后一项,那么最终得到:
也就是说我们需要算出所有的 \(f(s)\),其中 \(s\) 是一个 \(1\)、\(2\) 交替的序列。
Part 3
依旧从简单入手,我们考虑从 \(f(1,2)\) 开始算,并推广。
我们考虑刻画这种情形,如下图:
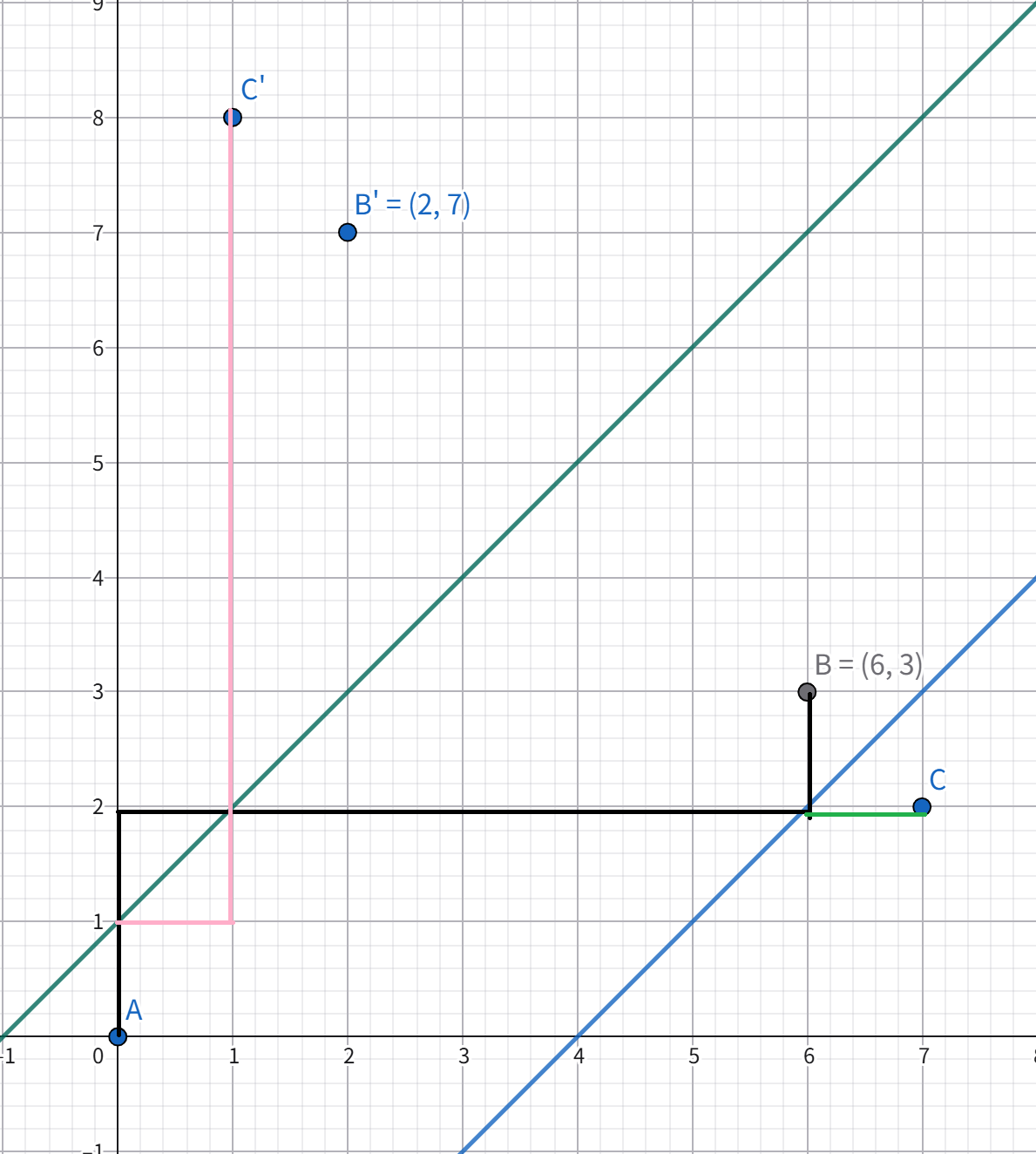
这是一个先经过 \(l_1\) 后经过 \(l_2\) 的路径,类似地,(但是注意要倒着来,可以解释为“生成”操作的逆)我们先将其对 \(l_2\) 对称(绿色),再对 \(l_1\) 对称(粉色),得到一个从原点到 \(C'\)(\(C'\) 为 \(C\) 关于 \(l_1\) 的对称点)的路径,这也是好算的。
那么可以推广出一个 \(f(s)\) 的算法,即我们倒序枚举 \(i\),将 \(B\) 关于 \(l_{s_i}\) 翻折。这样得到最后的点后用 \(\binom {x+y} x\) 即可算出。
Part 4
总结一下算法流程。
因为我们算 \(f(s)\) 要从后往前算,那么我们干脆直接从后往前来拆。
我们分两种情况,分别是 \(s\) 序列最后一位是 \(1\) 或 \(2\)。
对于最后一位是 \(1\) 的所有 \(s\):
-
我们将当前点按照 \(l_1\) 翻折,得到的点 \((x,y)\),将 \((x,y)\) 的贡献乘上系数 \(-1\) 加入答案。
-
我们再将其按照 \(l_2\) 翻折,得到的 \((x',y')\) 贡献,乘上系数 \(1\) 加入答案。
-
在 \((x,y)\) 不到第二、三、四象限的条件下重复以上步骤。
(系数是由 Part 2 的容斥式子中 \(|s|\) 决定的)
这样我们可以扫一遍算出所有最后一位是 \(1\) 的 \(s\) 的贡献。
那么对于最后一位是 \(2\) 的也类似,只是交换 \(l_1,l_2\) 的位置。
Part 5
分析一下复杂度,发现我们的复杂度由翻折的次数决定。
我们发现,每次翻折都至少使得 \(\min(x,y)\) 减少 \(1\),那么复杂度是 \(O(\min(x,y))\)。
例题
P3266 骗我呢
板子题。
题意
求满足以下条件的 \(n\) 行 \(m\) 列的矩阵的个数:
人话是每个元素有界,且比自己右侧,右上方的数都大。
做法
注意到关键点在于,一行 \(m\) 个数,但是只有 \(m + 1\) 种取值,且单调递增,这决定了只有一个值是取不到的。
我们考虑 dp,转移顺序是从上一行转移到下一行(上一行限制下一行)。
我们发现对于一行 \(i, 1 \lt i \le n\),记录 \(j\) 为第 \(i\) 行没有的数,\(k\) 为第 \(i - 1\) 行没有的数。
为了满足条件“每个值比右上角的值要大”,可以发现 \(k \le j + 1\),否则会有一个位置不满足。
比如若 \(k = j + 1\):
例,\(k = 4, j = 3\):
1 2 3 5 6 7 8
1 2 4 5 6 7 8
是满足的,但是若 \(k = j + 2\):
例,\(k = 5, j = 3\):
1 2 3 4 6 7 8
1 2 4 5 6 7 8
就不合法了。
也就是说需要记录每一行没有出现的数。
记 \(dp_{i,j}\) 为第 \(i\) 行 \(j\) 没有出现的方案数。
于是列出转移方程:
发现 \(j \leftarrow j + 1\) 时有贡献的 \(dp_{i - 1, ?}\) 只会多一个。
考虑去优化这个 dp,很像网格图的样子,那么我们把它画在网格图上:
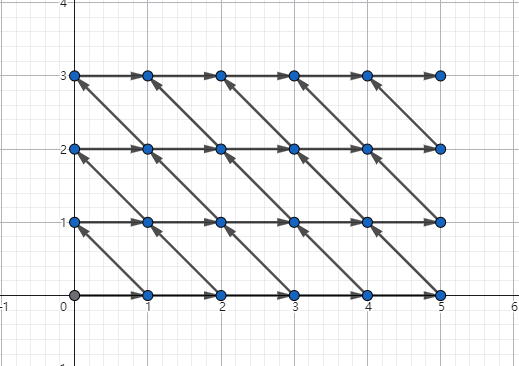
因为是斜着的,转换成这样:
(你会发现这是文章开头的图)
问题转换为走到 \((n + m + 1, n)\) 的路径个数,
然后有限制,转移时不能碰到两条直线 \(y = x + 1, y = x - (m + 2)\),那么就可以套用这个技巧了。
代码
const int N = 5e6 + 5;
const ll mod = 1e9 + 7;
int n, m;
ll fac[N], inv[N];
ll qpow(ll a, ll b){
ll res = 1;
while(b){
if(b & 1) res = res * a % mod;
a = 1ll * a * a % mod;
b >>= 1;
}
return res;
}
void init(int tot){
fac[0] = 1;
rep(i, 1, tot){
fac[i] = fac[i - 1] * i % mod;
}
inv[tot] = qpow(fac[tot], mod - 2);
per(i, tot - 1, 0){
inv[i] = inv[i + 1] * (i + 1) % mod;
}
}
ll C(int a, int b){
if(a < 0 || b < 0 || a < b) return 0;
return 1ll * fac[a] * inv[a - b] % mod * inv[b] % mod;
}
pair<int, int> rev(pair<int, int> pos, int b){
return {pos.second - b, pos.first + b};
}
void solve_test_case(){
n = read(), m = read();
init(5e6);
ll ans = C(2 * n + m + 1, n);
pair<int, int> pos = {n + m + 1, n};
while(pos.first >= 0 && pos.second >= 0){
pos = rev(pos, 1);
sub_mod(ans, C(pos.first + pos.second, pos.first), mod);
pos = rev(pos, -m - 2);
plus_mod(ans, C(pos.first + pos.second, pos.first), mod);
}
pos = {n + m + 1, n};
while(pos.first >= 0 && pos.second >= 0){
pos = rev(pos, -m - 2);
sub_mod(ans, C(pos.first + pos.second, pos.first), mod);
pos = rev(pos, 1);
plus_mod(ans, C(pos.first + pos.second, pos.first), mod);
}
write(ans);
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号